




陆陆续续看过许多关于 Go 调度的文章了,有了一些模糊的认识,为了巩固梳理相关知识,写出来是一个很好的方式,遂有此文,将我对于 Go 调度目前的认识用自己的方式表述出来,算是一篇归纳型的笔记。
基本模型
G:Groutine
G 代表 groutine, 就是我们在写代码时使用 go func()
创建出来的并发功能模块,它在运行时中对应着 g
这样一个结构。g
被创建出来之后等待被调度,最终绑定到一个 m
上执行。
我们挑选 g
部分结构看下:
type g struct {
stack stack
stackguard0
stackguard1
m *m
sched gobuf
atomicstatus uint32
preempt bool
...
}
type stack struct {
lo uintptr
hi uintptr
}
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer
}
stack:stack记录了这个
g
栈空间的起止地址m:记录了执行当前
g
的msched:sched 记录了这个
g
执行中断时的寄存器状态,用于恢复现场atomicstatus:
g
的状态,比如_Gidle
、_Grunning
、_Gsyscall
、_Gwaiting
、_Gdead
等preempt:抢占标志(因运行太长,被申请执行抢占)
M:Machine
M 是具体执行 G 功能的执行体,它对应系统线程,持有计算资源,每个 M 对应一个操作系统线程。它在运行时中对应结构 m
:
type m struct {
g0 *g
curg *g
p puintptr
oldp puintptr
spinning bool
mcache *mcache
...
}
g0:g0是一个比较特殊的
g
,它跟我们用go func()
创建的不太一样,它是随着新 M 创建的时候,单独创建的一个g
,用于 M 在执行调度等运行时动作时使用其栈空间,g0
的栈空间也比一般的 G 的初始空间要大很多。当执行用户 G 的时候,就切到对应g
的栈空间上,当执行调度相关的逻辑时就切换到g0
这个栈空间上curg:绑定在 M 上正在执行的 G
p:M 绑定的 P,M 必须绑定 P 之后才能够运行 G
oldp:M 最近被剥夺的一个 P,主要用于系统调用阻塞发生的抢占调度中
mcache:本地内存对象,执行 G 所需要的内存优先先从这里分配(实际上指向锁绑定的 P 的 mcache)
P:Processor
P 代表处理器,但是这里是指虚拟的逻辑处理器,它并不负责执行程序。P 维护有一个本地的待处理 G 队列、本地的内存对象 mcache
等相关的执行资源,当与 M 绑定后,M 就可以执行 G 了。
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
runqhead uint32
runqtail uint32
runq [256]guintptr
gFree struct {
gList
n int32
}
m:与 P 绑定的 M,两者相互链接
runq:P 维护的本地 G 队列,这是一个环形队列,有
runqhead
和runqtail
记录队列首尾位置。之所以有本地 G 队列,是因为在 P 内的 G 是线程安全的,不用加锁,对它的操作会快很多,提高调度效率。与之对应还有一个全局的 G 队列,后文会介绍gFree:这里记录是一些已经运行完毕的 G,这是为了维护一个
g
对象的池,便于重用,减少内存分配和 GC 压力。需要新g
的时候会从这儿取出复用
M、P、G 模型是构成 Go 调度的基本单元,执行体 M 对应操作系统线程,它的数量被 Go 限制为最多 10000 个。G 是被执行体,代表轻量级的用户线程,它的数量无限制。而 M 和 G 之间的 P,是一个逻辑处理器,作用是实现对 M 和 G 的解耦,这样就能够实现任意数量的 G 在任意数量的 M 中的调度。
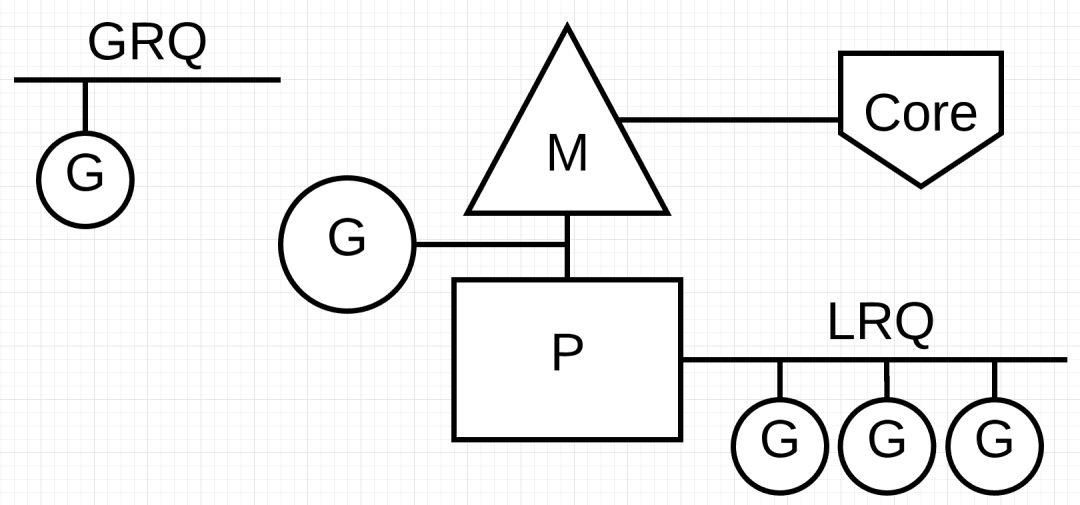
sched
除了 G、M、P 这几个基本模型外,还有一个记录调用器状态并维护一些全局资源的结构 sched
。
type schedt struct {
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
pidle puintptr // idle p's
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
runq gQueue
runqsize int32
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
}
sched
中记录了空闲M、空闲 P链表。以及一个全局的待运行 G 列表和可重用的 g
结构池,这和 P 的两个本地队列相对应。
另外还有一些全局的变量:
var (
allglen uintptr
allm *m
allp []*p // len(allp) == gomaxprocs; may change at safe points, otherwise immutable
allpLock mutex // Protects P-less reads of allp and all writes
gomaxprocs int32
ncpu int32
forcegc forcegcstate
sched schedt
newprocs int32
...
}
调度流程
schedule
schedule 是一个不断轮回的调度循环,它的任务就是寻找一个可运行 G ,最后 execute
执行这个 G。它寻找 G 的策略和过程是 schedule 的一个核心:
首先尝试从 P 的本地 G 队列去取 G,但是为了保证全局 G 队列里的 G 有机会调度,每调度 61 次,调度器会优先从全局 G 队列拿 G;
如果没有,则开始更仔细的
findrunnable
流程去获取 G;findrunnable
会依次从 P 的本地 G 队列、全局 G 队列以及netpoll
中寻找 G。如果依然没找到,则开启饥饿的runqsteal
,尝试从其他 P 偷一些 G 来运行;随机顺序遍历其他 P,如果其他 P 的本地 G 队列中有 G,则尝试偷一半到自己的队列,并开始执行偷到的 G;
如果经过上面的步骤还是找不到可运行的 G,则尝试最后再去全局队列看一看,实在没有的话,则解除与 P 的绑定,并将 P 放入空闲列表;
虽然已经解除 P 了,但是还是不死心,再次去检查是否有正忙的 P,有的话立即要来一个空闲 P 绑上,并重新开始上述寻找 G 过程,尝试工作;
经过这么丧心病狂的寻找之后,实在无事可做,则 M 进入休眠。
为了工作,可以说是不择手段、丧心病狂。
sysmon
sysmon 是一个独立于调度循环体系外的一个监察员,sysmon 在系统初始化时被创建,单独绑定一个 M,并且不需要绑定 P 就可以运行。
sysmon 也是一个类似于 schedule 的不断循环的流程,初期每 20μs 运行一次,后面间隔时间逐渐翻倍,最终每 10ms 运行一次。
sysmon 一次执行大概会做这些事情:去长时间未轮询的 netpoller 中 poll 一次,执行 retake 相关的抢占调度,需要强制 GC 时执行 GC。
其中抢占调度有两种场景。
第一种:长时间阻塞在 syscall 。如果 sysmon 在理性检查过程中,发现某个 P 有段时间了还在 syscall 未返回,那么为了不浪费 P 资源,应该考虑是否抢占 P 去做别的事情。
判断条件有三条:
P 的本地队列里是否还有待运行的 G;
其他 P 都很忙
系统调用超过了 10ms
一旦任何一个条件满足,则 handoffp(_p_)
,将 P 与当前 M 解绑。这样 M 继续系统调用,P 则去绑定其他的 M 完成其他工作,提高系统效率。
其实在执行系统调用之初,M 已经与 P 做了预解绑,但是 P 没有被重新分配(并且被记录到了 M 的 oldp
字段,一旦系统调用返回,M 会优先尝试从 oldp
中拿回之前绑定的 P)。所以这里只是对 P 重新分配,绑定其他 M。
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
...
handoffp(_p_)
}
第二种:长时间运行的 G:如果一个 G 运行了太长时间(10ms),那么 sysmon 就要发起抢占调度,但并不是现在就停止 G 运行,而是发起一个抢占申请 -- 将 G 的抢占调度标志 preempt
设为 true
,同时修改 stackguard0
为一个极大值 stackPreempt
。这样当 G 再次执行函数时,检测到这个变化,就会处理抢占申请,退出执行,发起新的调度。
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
sysretake = true
}
}
参考资料
Head First of Golang Scheduler
Scheduling In Go : Part II - Go Scheduler
