




总体架构图
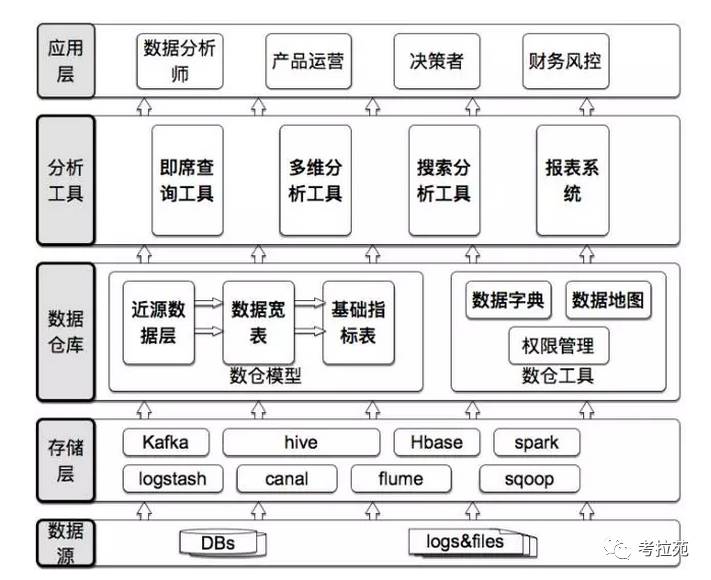
存储层:主要解决ETL的问题,如何正确埋点,数据稳定正确的传输,提供可靠的存储计算环境等等。
数据仓库层 :提供数据模型和数据工具两个内容:数据模型解决数据可用的问题;数据工具解决数据易用的问题;
数据分析 :主要解决各种角色如何使用数据仓库的问题。
数据仓库
近数据源层
主要的来源DB(RDBMS和Nosql及NewSql等)和文件(类似log、file等),一般都会通过logstash 、canal、flume、sqoop等工具收集到kafka【常在数据量对时效性要求高些的需求】、hvie、hbase等在通过spark、hadoop等完成一些数据清洗的过程;进而完成ETL过程。
在数据仓库中第一层是近数据源层【该层一般会保留和数据源保持一致的数据结构,减轻ETL过程,快速有效的同步数据,减少不必要的损耗】
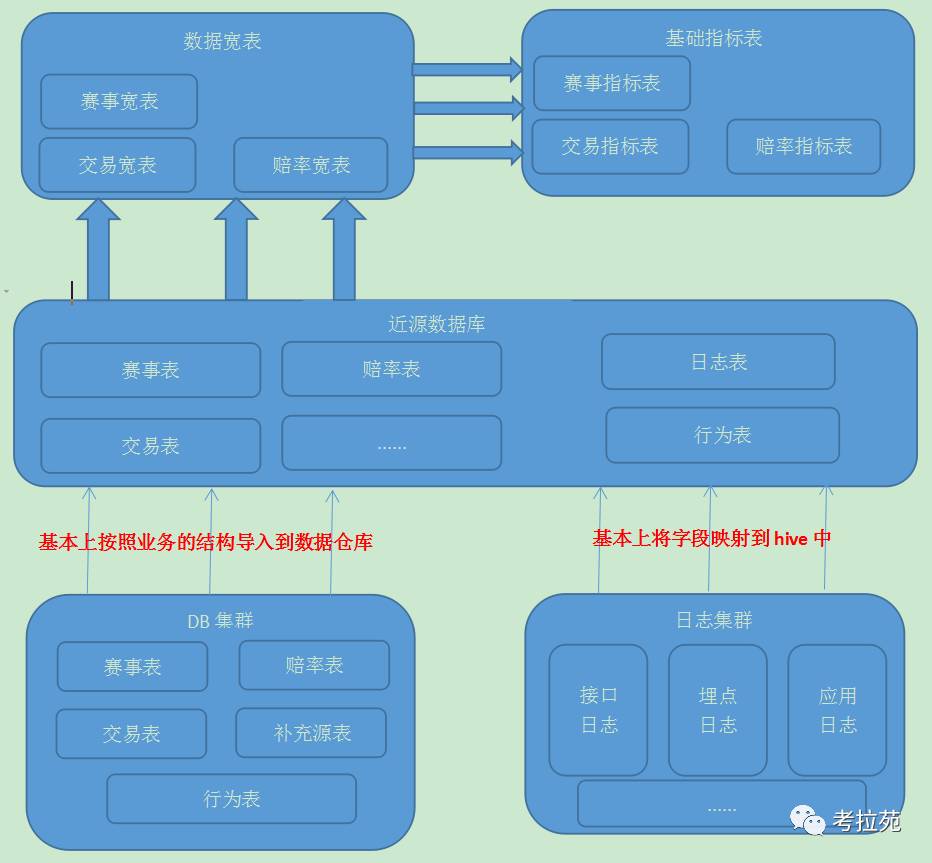
该层主要用来缓解业务层面临的问题:当业务设计涉及到数十张基础表,同时又涉及n多关联表,缓解业务层自身不足以及防止对业务造成不必要的影响。【业务优先】
需要做的事情主要下面几件
1、将物理分片的分布式DB映射成一个hive表
2、根据表的内容选择合适的hive分区键
3、对于缓慢变化维进行处理,让数据表反映出变化
4、对日志进行基本的处理映射成hive表
不需要处理的事情如下
1、脏数据处理
2、数据表间一致性处理
3、不同业务表的合并
正如上述所看到的近源数据层定位仅限于快速构建基础数据平台,不做任何业务相关的处理,进而保证数据架构的正确性和稳定性。
中间层【并不是必须的层】
在我们拥有了近数据源层基本就可以开始数据分析工作,不过为了“简化操作、快速执行、屏蔽错误、统一口径” ,这里需要引入“中间层”。
需要处理的事情如下
1、合并不同业务为统一过程;虽然业务数据有不同市场或者版本,不同客户或用户,但是他们的工作过程是一样的,在一定程度是可以进行合并的
2、屏蔽脏数据
3、冗余数据(比如经常使用join操作)
中间层在架构设计中并不是必须出现的,主要在于近数据源层的数据分析的常用度,比如球队所在地区…… 中间层是数据仓库最重要的一层。直接决定了数据仓库的性能。
1)数据汇总。将底层数据按维度进行小颗粒度汇总
2)信息聚合。将多张表的信息聚合在一个表中。这样的好处,是避免使用表关联,提高查询性能。
也算是分层设计原则中的一个:比如接口层、中间汇总层和应用层
宽表设计
首先在此要说明的地方:一般业务数据表主要构成: 基础数据表 + 聚类分析表(基于基础数据统计分析的结果) + 维度统计分析(一般是结合基础数据及其关联的业务的统计分析的结果),这样通过数据的主键即可获取该数据相关所有内容。宽表的设计在一定程度上满足我们实际应用的绝大数的数据分析的问题:
1、数据口径:一般宽表在实际的计算中会根据不同的业务需求产生很多冗余字段,在设计单表的时候针对一个需求或模型增加一个字段来完成,这样整体的统计口径都会一致,同样脏数据的问题也能通过该方式解决。
2、多表的join:首先在互联网公司大家对大数据的量级有着清楚的认知,但是不同的关联数据不可避免join,通过采用宽表聚合常用字段,能够满足大部分的数据分析需求,加上合理的分区设计,基本上查询速度要比我们直接使用join操作快的多。
3、针对近数据源层的数据并不是所有的都需要封装“中间层”,这里有一个分割点:当前的数据是否常用,宽表的设计需要做一个折中. 一方面设计完备的数据仓库是不现实的, 另一方面宽表的前提是足够常用, 对于不常用的数据我们的数据平台是支持直接操作的.
基础指标表
一般来说基础指标表反映了对一个实体的基础衡量,也是BI分析的基础。比如我们可以在赛事宽表的基础上提取出比赛指标表、球队指标表、球员指标表、实况指标表,比如我们使用球队指标表针对球队的近期状态、进攻、防守、战绩甚至历史同期等做基本统计分析,这样的应用就可以非常便于筛选合适的球队或者购买的球队
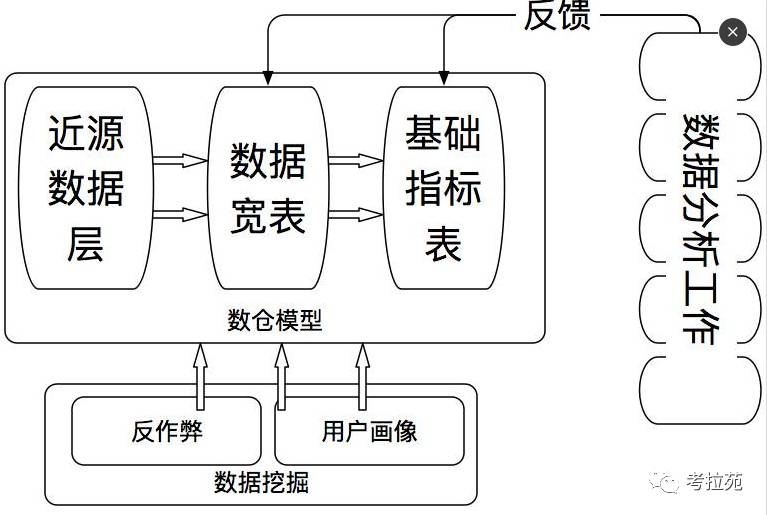
这样从近数据源层到指标层 层次的增加易用性越强,层次越低灵活性却越强;这样也就保证了紧急分析的快速响应,同时稳定的数据在高层次数据模型中得到高质量的保证。
数据仓库建模
建模方法论
模型设计始终遵循”自顶而下、逐步求精”的设计原则
分为三阶段
1、概念模型
一般是基于业务的范围和使用,从高度上进行抽象的概括,也就是划分主题。
比如基于赛事划分的主题域:
赛事分类、洲际、国家、赛事、赛事阶段、联赛、赛季、比赛、球队、教练、球员
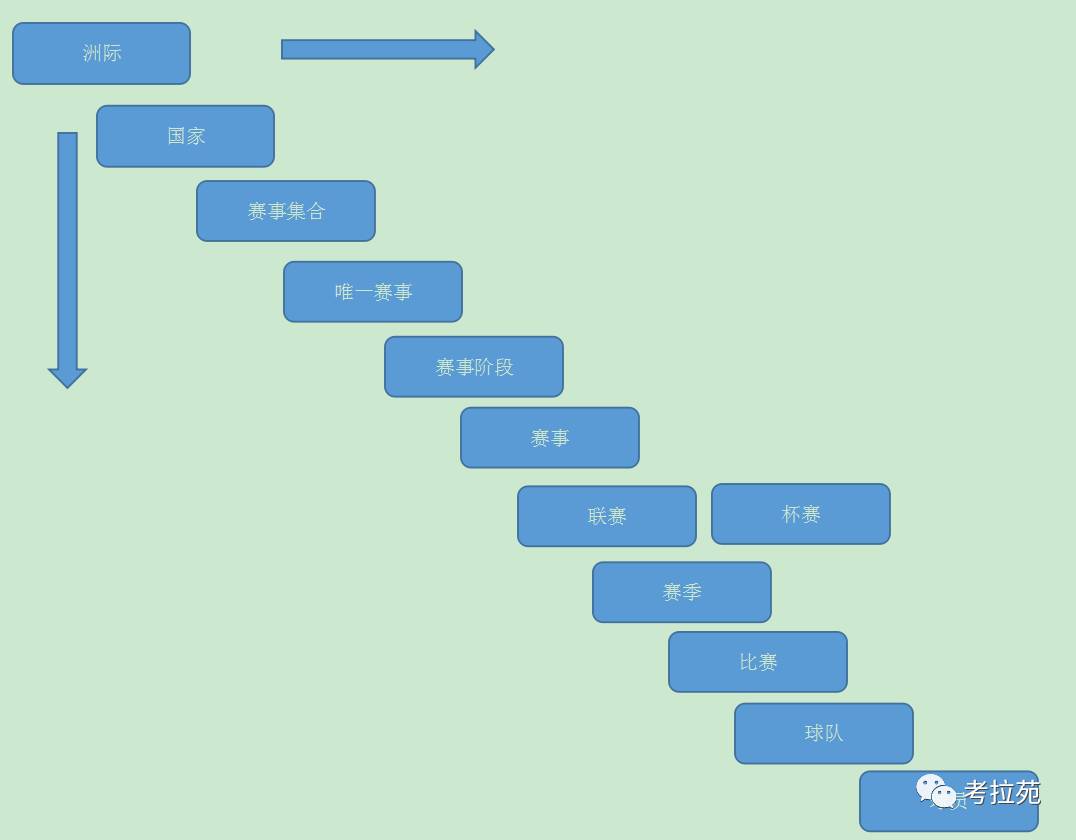
为嘛要划分主题域呢
划分主题域主要是根据业务的应用和需要来划分的,是用来达到数据与业务紧耦合的目的。
2、逻辑模型
主要起到对概念模型中的主题进行细化,定义实体与实体之间的关系,和实体的属性。也即是定义具体的表,表与表的约束,表字段,形成ER图。
该阶段可以说是完全面对业务的,设计都是基于业务规则,也称之为“业务驱动建模”
具体的ER图就不在此处罗列出来。
3、物理模型
主要依照逻辑模型,在db中建表、索引等。在互联网领域,为了满足性能的需求,可以增加冗余、隐藏表之间的约束等会做出反第三范式操作。该阶段面对的主要是数据库、硬件、性能等。
建模模型
常用的模型:星型模型和雪花模型
1、相同点
两种模型都是由一个事实表 + 一组维度表组成【星型也称为维度建模】
2、异同点
a、星型模型:维度表直接事实表连接,类似星星般【维度预处理:预先进行分类、排序等处理】
b、雪花模型:一些维度表不直接与事实表相连,而是通过维度表中转。类似雪花般。
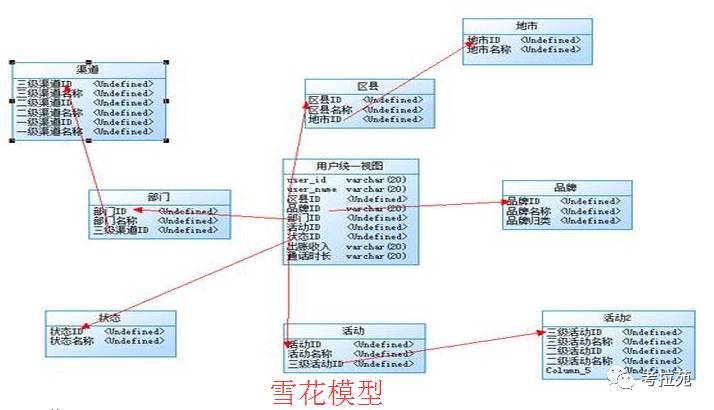
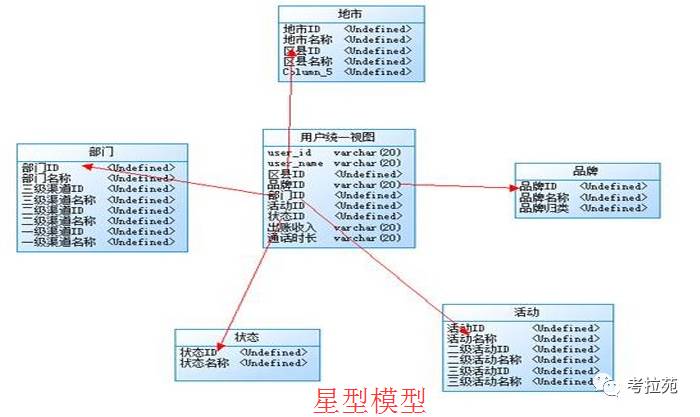
c、从性能上 星型模型性能更好些【往往为了提升性能,会做出违反第三范式的操作,适当的冗余、隐藏表间的约束】
维度建模
在实际的应用中,面临将商业维度融合到数据模型中,将同一维度的不同层次的维度冗余到事实宽表。维度模型也是星型模型。主要强调对维度进行预处理。

主题域设计方法
分层设计,是横向的设计原则,那么主题分域是纵向的处理方法。具体做法就是从业务上,高度的抽象和归纳,将数据划分为不同的主题域。分域后的好处:业务紧耦合、便于数据拓展、便于使用。域是要具有明显的表命名规则。
数据仓库工具(目前暂时省略)
其中有些地方并没有将实际的建模模型放上【原因各位懂得】,同时细节也没有详尽的阐述,只是给出大致的结构和简单的构思。数据仓库的构建并非简简单单,从分析到建模再到最终落地的方方面面需要考虑种种,有兴趣的可以私信交流。
最后打个广告:招聘java软件工程师、前端工程师、DBA、运维工程师、微服务相关人员。联系方式:hr@jiangduoduo.com
