




【此为"一森咖记"公众号——第120篇文章】
读完需要
速读仅需10分钟
【引言】
最近应一些朋友要求,让说明下Oracle的体系结构,这段时间有意要写下;其实考试过OCM的亲都知道,最权威的Oracle体系介绍是Oracle的官方文档,但无奈很多亲一看请问就头痛,看过的也反应内容太多不好整合、消化、吸收。
今天恰巧碰到一篇文章,很适合上面亲的需求,故转载之。本文简单明了的讲述Oracle大致的体系架构,通过业务用户session发起和sql执行过程来讲述了Oracle的内在执行过程;文章结构和讲解思路简洁明了,有内在逻辑性,是一篇很不错的Oracle启蒙性文章。
本文转载文章链接如下,根据个人理解做了内容语句的调整。
https://www.cnblogs.com/augus007/articles/7999586.html
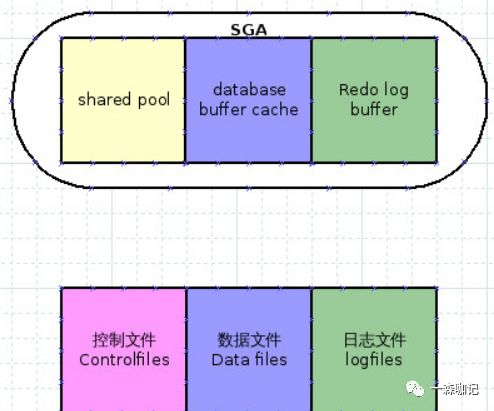
1 数据库文件Oracle 数据库文件大概可分为3种,分别为:
控制文件(control files): 存放数据库本身物理结构信息
数据文件(data files): 存放数据库数据
日志文件(log files): 包括重做日志文件和归档日志文件,记录数据库数据的变化
如下图:

2 数据库实例
此时,用户和应用程序是无法直接访问数据库文件的数据的;如果要连接Oracle服务器,服务器端会启动1(或多个. . RAC集群)个实例,用户可以通过连接这个实例来访问数据库的数据。
实例有两个组成部分,分别是:
系统全局内存区(SGA):服务器专门划分给Oracle实例使用的内存块
Oracle进程: 包括服务器进程和后台进程,后面会解析
2.1 系统全局内存区(SGA)SGA可以分成6大块,分别是 Java pool, shared pool, database buffer cache,large pool, streams pool, Redo log buffer。
注意:可用 v$sga这个视图去查看sga各大块大小。
SYS@ethanDB> select * from v$sga;
NAME VALUE CON_ID
-------------------- ---------- ----------
Fixed Size 29874920 0
Variable Size 1.2751E+10 0
Database Buffers 5.5700E+10 0
Redo Buffers 238559232 0
sql语句的执行流程涉及3块缓存区:
共享缓冲区(shared pool)
数据库缓冲高速缓存(database buffer cache)
重做日志缓冲区(redo log buffer)
如下图:
2.2 服务器进程
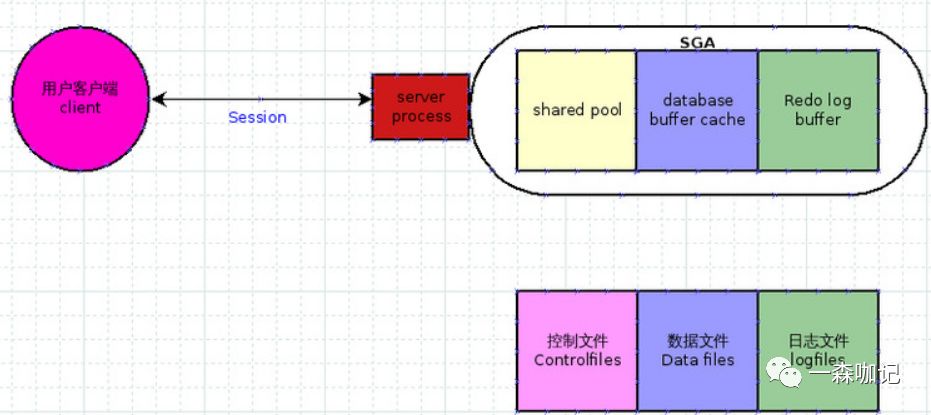
当用户(客户端)要连接Oracle数据库时,Oracle就会创建1个session(会话),并且在服务器上创建1个专门处理这个session的进程,即服务器进程。
如下图
注意:
每当1个新用户创建1个新的连接到数据库,Oracle都会对应创建1条服务器进程。
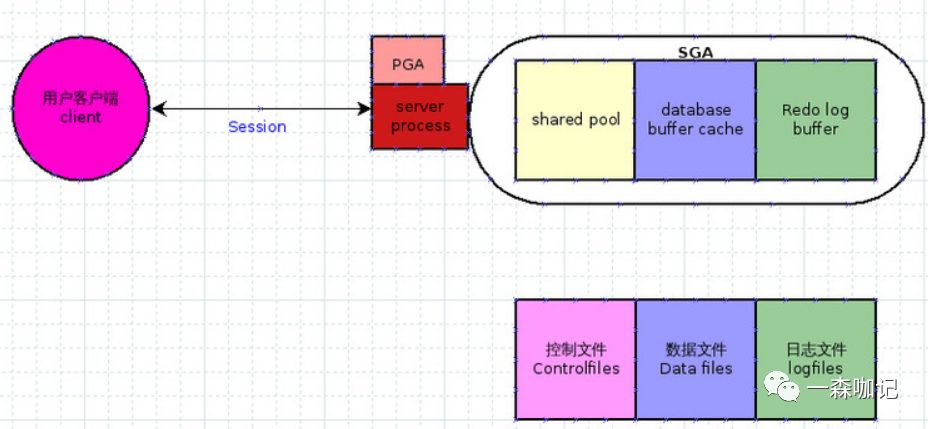
2. 3 PGA(Program Global Area)
对应上面的Server Process, Oracle会在服务器上对每一条Server Process分配一定大小的内存,就是PGA, 注意有几个session就会有几个对应的PGA块,所以服务器对内存需求很大。可以用 select sum(pga_userd_mem) from v$process,语句来查看当前使用的总PGA大小。
如图:
3. 客户端与服务器的SQL语句传输
用户在客户端输入若干条SQL语句,如1个存储过程,有读和写的动作. 这条语句通过什么来传输?答案就是session,服务器上用什么来接受这个sql语句呢,答案就是Server Process。
如图:
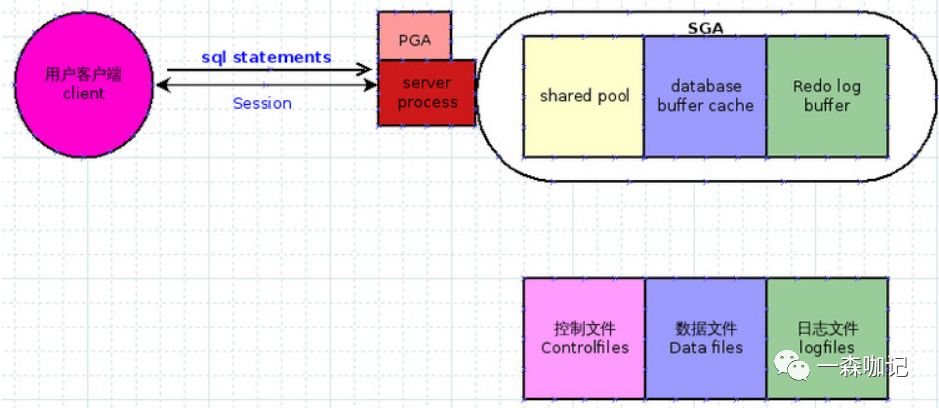
server process会判断sql语句是否合法(语法,权限),如sql语法有错,或对应的表或视图或Procedure没有权限,就会直接返回错误信息。
server process根据sql语句生成执行计划(execute plan)Oracle是无法直接执行sql语句的,必须先依据统计信息生成执行计划,然后Oracle就会根据较优的执行计划去执行SQL。而生成执行计划要访问许多数据库对象,是1个比较消耗服务器资源(CPU,IO,Memory)的动作。关于统计信息和执行计划的个人公众好推文,可点击如下进行了解。
且因为同一条sql语句可能会有多个用户多次重复的执行, 那么是否每次都要生成一次执行计划吗?这时SGA里面的Shared pool就发挥作用了,它会缓存sql的执行计划。 所以server process会首先从Shared pool里面查找有无现成的执行计划,如果有就直接采用,这叫软解析。如果无,就自己生成1个,然后看情况把这个执行计划放入shared pool,这就是硬解析。
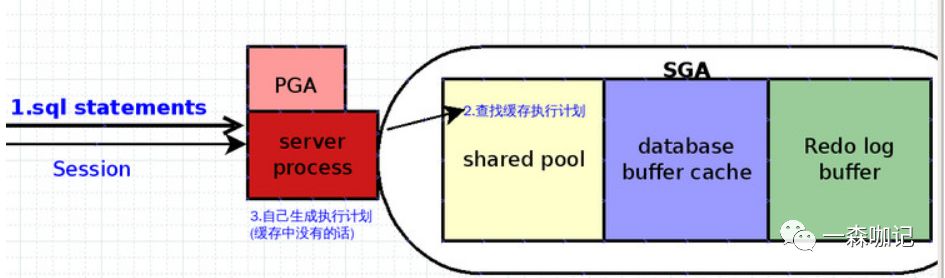
server process根据执行计划去取(写)数据. 当server process得到执行计划后就可以去取数据了。Oracle的数据放在哪里呢?放在数据文件。
但是server process是不是就直接去访问数据文件呢?因为计算机的时间消耗主要都在物理IO,所以要尽量避免物理读写,SGA里面的database buffer cache起作用。即,database buffer cache就是用来缓冲Data files里的数据。可避免对数据文件的读写(物理读)。
server process得到执行计划后,第一步是首先去database buffer cache去找有没有现成的数据。如果有最好,无或者缓存中数据不全的话就只能去访问data files。 从data files获得数据后,也不是直接发给用户客户端,而是根据情况放入database buffer cache,以便当前或其他用户使用。
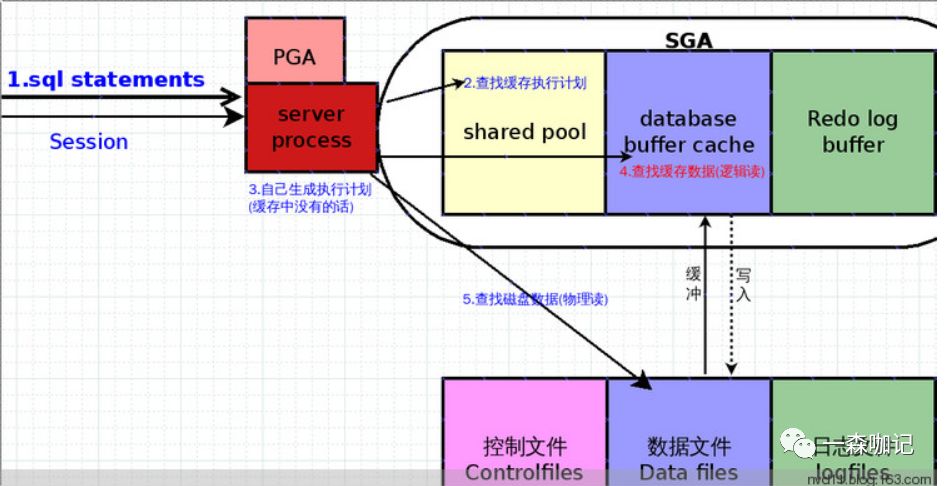
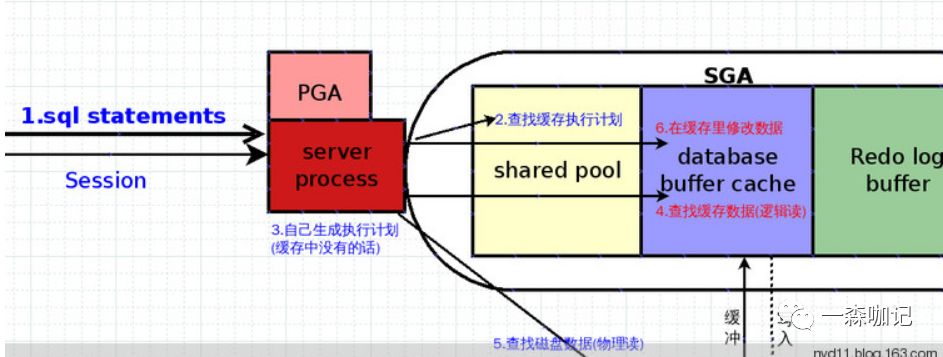
6. 逻辑读,物理读与缓存命中率. 由上图得知,所谓逻辑读,就是从缓存(一般是内存)里读取数据。而物理读,也就是从磁盘(数据文件)里读取数据。 至于缓存命中率,就是取出数据的过程中逻辑读次数/ (逻辑读次数+物理读次数) 这个比率. 当然这个比率越接近1越好, 因为物理读相当费时间,机械硬盘瓶颈,除非有服务器用SSD做硬盘。当然命中率并不是数据库健康的唯一指标,因当逻辑读十分巨大时,即使物理读很大,比率也会接近1,所以也需要关心每秒物理读(tps);可在linux下使用iostat命令来查看当前磁盘的每秒物理读。7. 在缓存中修改数据server process拿出数据放入缓存中,接下来就对数据进行修改。因修改数据会产生大量缓冲数据,所以这个动作在Database buffer cache里完成。
8. 修改数据会产生重做日志上面提到,日志可用来记录数据库的数据变化,对数据改动产生一定量的日志数据。这些日志是不是直接就写到日志文件中?写日志文件也是物理读,所以SGA就有个Redo log buffer,就是日志缓存,专门实时存放产生的日志数据。
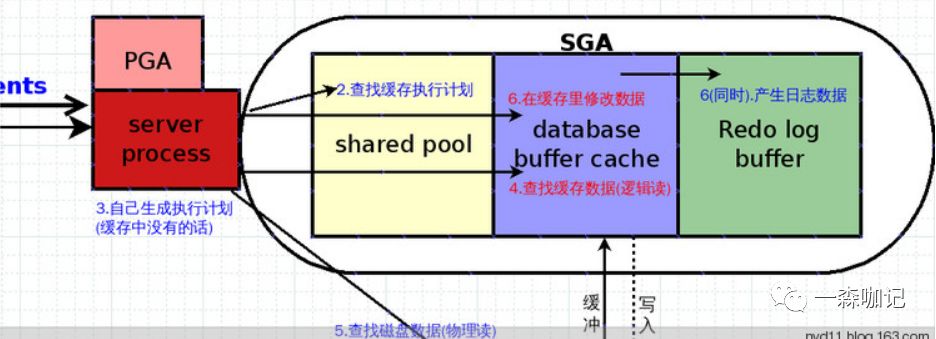
9. 最终Server Process把返回数据或信息通过session传回给用客户端Server Process 做完读取和修改数据的动作后,就会将结果返给用户了。
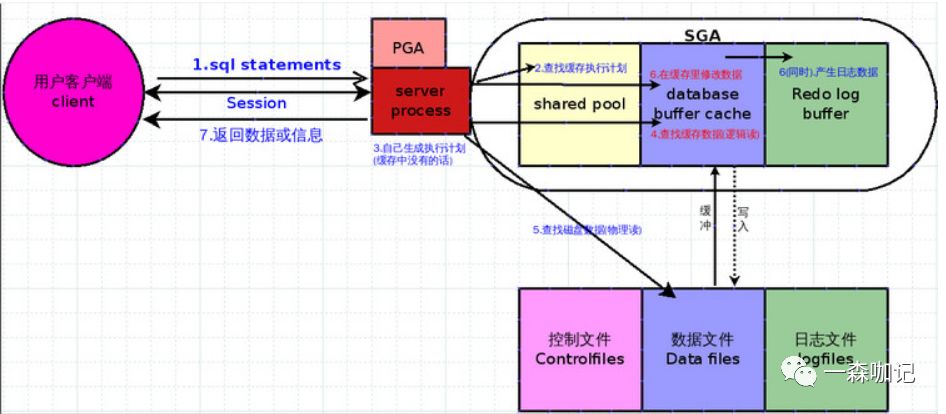
10. 将数据缓存和日志缓存写入磁盘 截止目前, 整个sql语句执行流程已经完成。问:Server process修改的数据和产生的日志还在SGA里面,还需要被被写入磁盘否?
答案:肯定需要, 但是这些动作已经不是sql执行流程之内,且这些动作也不是server process负责,分别由DBWR 和 LGWR 这个两个进程负责。
如图:
DBWR: Database writer,后台进程之一,负责将Database buffer cache里被修改的数据写入数据文件LGWR: Log writer,后台进程之一,负责将Redo log buffer里的日志数据写入到日志文件
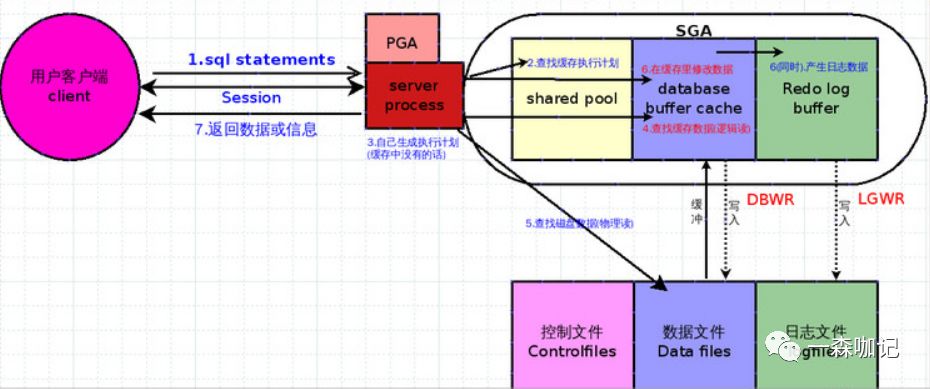
11. 为什么Oracle要将server process 和后台进程分开?
如上图,为什么写入数据文件和日志文件要交给后台进程去完成?根据上述流程,服务器与用户打交道只有1个进程:Server Process, server Process的速度直接影响了用户的响应感受,无论后台进程多么繁忙,只要server process响应迅捷,用户觉得数据库很快。相反,后台进程空闲,服务器CPU很空闲,但server process反应慢,用户就觉得数据库很慢。
故,尽量精简server process动作和提升其响应速度; 后台进程DBWR 和 LGWR负责数据和日志的落盘。
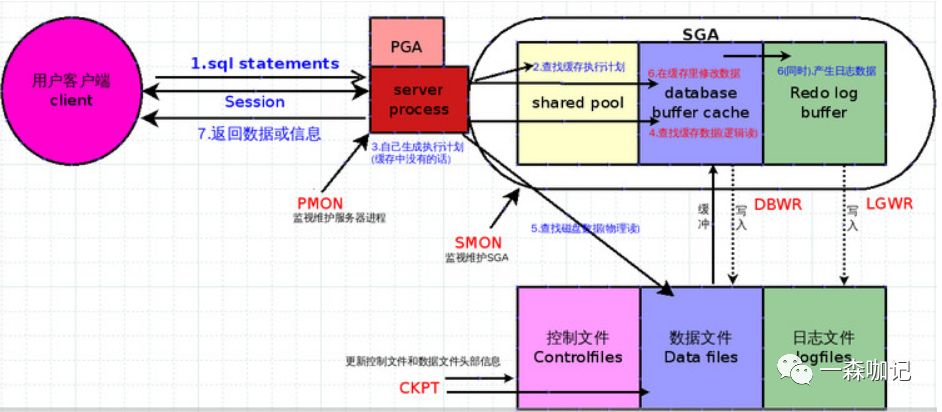
12. 顺便介绍其余3大系统进程CKPT,SMON,PMONOracle有SGA6大池 3大数据库文件, 5大系统进程。其中DBWR 和 LGWR上面已经介绍过了。
其他3大进程介绍:
CKPT : Checkpoint 检查点进程,负责更新控制文件和数据文件的头部信息, 控件文件在这篇blog开头就已经介绍过,至于数据文件的头部信息是指当前数据块的状态信息
SMON : system monitor 系统监视器,负责监视维护SGA和后台进程,例如合并SGA里面的碎片
PMON : process monitor 进程监视器,主要指服务器进程,如一个用户突然断开连接,但该server process还在服务器端,Pmon会隔一段时间把该进程清理掉并且释放PGA。
【视频参考】
http://www. jiagulun. com/thread-2674-1-1. html
转文至此。

以下为个人公众号“一森咖记”,欢迎关注。

近期热文
你可能也会对以下话题感兴趣。点击链接便可查看。
