





概述
openshift 3.11默认安装了prometheus,但是默认的监控项是没有包含etcd的,所以这次实施需要将etcd也包含在,按照官方文档的步骤实施没啥问题,但是在我3.11.98的版本中遇到了两个bug,1. prometheus需要对etcd的证书ca进行信任,这个步骤中就需要prometheus加载按照文档中生成的证书,但是prometheus没有加载成功。2. 在解决第一个bug后成功监控到了etcd,但是prometheus一直报EtcdHighNumberOfFailedGRPCRequests,altermanager一直发送邮件,按照prometheus的rule中的监控表达式去查询了另个没有报错的etcd集群,两个etcd集群的结果一模一样,但是其中一个集群就是不断告警。
监控etcd
这里步骤就大致写一下,按照官方文档即可,不过在多个master的情况下,只有其中一台机器有/etc/etcd/ca/ca.crt 和 etc/etcd/ca/ca.key文件。
编辑cluster-monitoring-config configmap
oc -n openshift-monitoring edit configmap cluster-monitoring-config
添加etcd参数
...
data:
config.yaml: |+
...
etcd:
targets:
selector:
openshift.io/component: etcd
openshift.io/control-plane: "true"
验证etcd servicemonitor是否出现
$ oc -n openshift-monitoring get servicemonitor
NAME AGE
alertmanager 35m
etcd 1m
kube-apiserver 36m
kube-controllers 36m
kube-state-metrics 34m
kubelet 36m
node-exporter 34m
prometheus 36m
prometheus-operator 37m
访问prometheus的target能够看到etcd是down的状态,因为证书信任的问题。

拷贝master节点的/etc/etcd/ca/ca.crt 和 etc/etcd/ca/ca.key文件至一个临时创建的目录待用。
创建openssl.cnf
[ req ]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[ req_distinguished_name ]
[ v3_req ]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, keyEncipherment, digitalSignature
extendedKeyUsage=serverAuth, clientAuth
签发相关证书的步骤
openssl genrsa -out etcd.key 2048
openssl req -new -key etcd.key -out etcd.csr -subj "/CN=etcd" -config openssl.cnf
openssl x509 -req -in etcd.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out etcd.crt -days 365 -extensions v3_req -extfile openssl.cnf
生成secret的yaml文件
cat <<-EOF > etcd-cert-secret.yaml
apiVersion: v1
data:
etcd-client-ca.crt: "$(cat ca.crt | base64 --wrap=0)"
etcd-client.crt: "$(cat etcd.crt | base64 --wrap=0)"
etcd-client.key: "$(cat etcd.key | base64 --wrap=0)"
kind: Secret
metadata:
name: kube-etcd-client-certs
namespace: openshift-monitoring
type: Opaque
EOF
创建secret
oc apply -f etcd-cert-secret.yaml
理论上这时候能看到etcd已经up了。
第一个bug
prometheus无法对etcd的证书进行信任,正常情况下prometheus应该是加载了我们创建的相关证书文件,我们去查看prometheus的pod,无法看到有相关的kube-etcd-client-certs secret volume被挂载,我猜测是prometheus operator没有管理到pod,进一步查看prometheus的statefulset配置,也没有相关secret信息,既prometheus operator没有管理到prometheus的statefulset,所以我手动的将kube-etcd-client-certs secret 挂载进prometheus的statefulset里面:
# oc get sts prometheus-k8s --export -oyaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
................
containers:
.................
name: prometheus
volumeMounts:
...................................................
- mountPath: /etc/prometheus/secrets/kube-etcd-client-certs
name: secret-kube-etcd-client-certs
readOnly: true
...................................................
volumes:
...................................................
- name: secret-kube-etcd-client-certs
secret:
defaultMode: 420
secretName: kube-etcd-client-certs
....................................................................
这时候prometheus的pod就会自动更新,等一会去prometheus的target就能看到etcd已经up了

2
第二个bug
etcd监控项中一直出现 EtcdHighNumberOfFailedGRPCRequests 报错
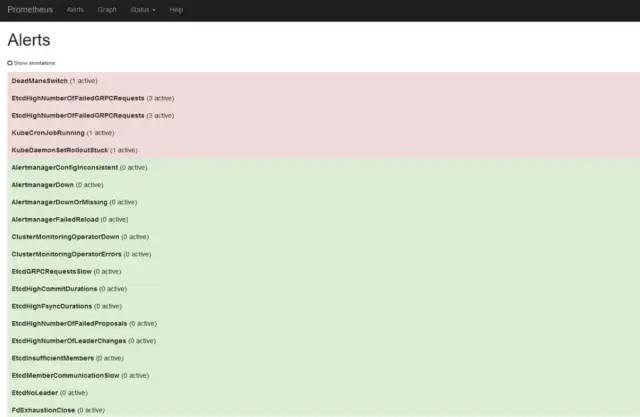
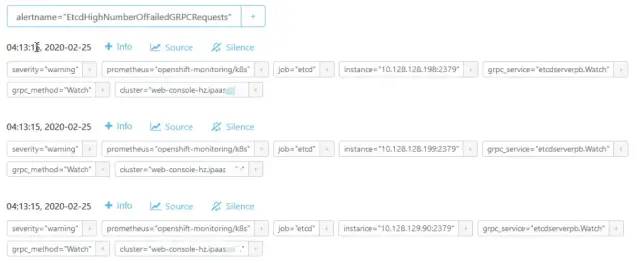
将监控表达式中的拿到prometheus查询,结果是100,拿该表达式去另一个正常的集群中查询也是100。
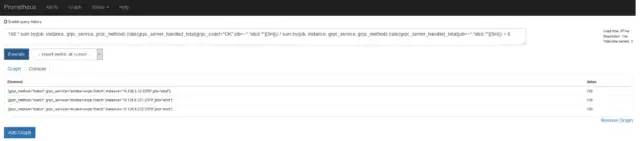
查询了相关资料,可以确认是个bug:
https://github.com/openshift/cluster-monitoring-operator/issues/248
https://access.redhat.com/solutions/3358691这个bug要升级openshift才行,这个操作就很大了,所以只能找个workaround的方法,直接将该告警进行silence忽略。
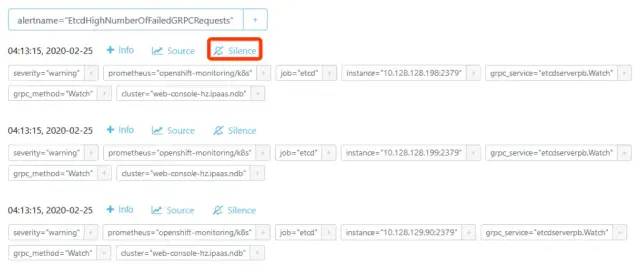
将silence时间修改为10年,因为我有三个etcd节点,所以要删除instance和告警级别,使用其他匹配项就能匹配到三个etcd节点了。
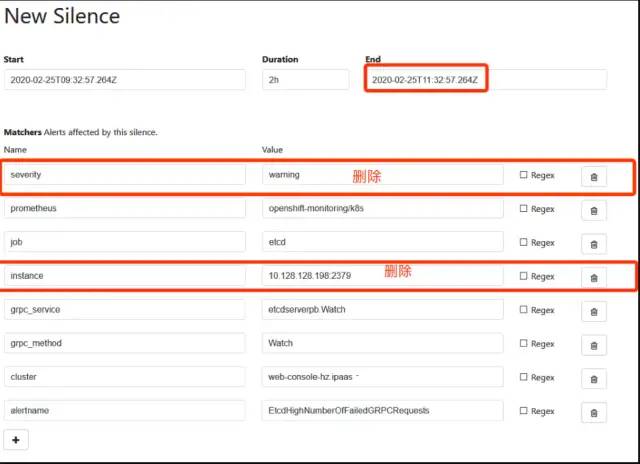
查看配置好的silence信息,匹配到了6个etcd告警信息,这下三个节点的etcd就不会告警了。
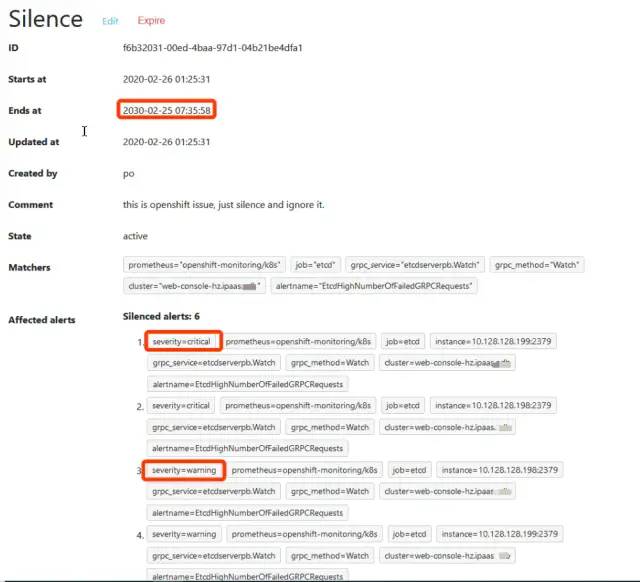
prometheus关于etcd的rules会在自动创建好etcd servicemonitor后生成,并且EtcdHighNumberOfFailedGRPCRequests有两个级别的告警,区别在于监控持续的时间不一样。
注意项
openshift的使用operator来管理prometheus,一些默认已存在的规则是无法被修改的,比如修改名为prometheus-k8s-rules的prometheusrules,一会儿后就会被还原,只能自己新增rules
altermanager告警通知配置
创建并编辑alertmanager.yaml
global:
smtp_auth_password: 111111
smtp_auth_username: 22222
smtp_from: 333333
smtp_smarthost: 44444
resolve_timeout: 5m
route:
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: ragpo
routes:
- match:
alertname: DeadMansSwitch
repeat_interval: 12h
receiver: deadmansswitch
receivers:
- name: '5555'
email_configs:
- to: 55555555
- name: deadmansswitch
- name: '66666'
email_configs:
- to: 66666666
生成base64加密
cat alertmanager.yaml | base64 --wrap=0
替换
4.删除altermanager的pod
oc delete pods --selector=app=alertmanager -n openshift-monitoring
参考链接
https://docs.openshift.com/container-platform/3.11/install_config/prometheus_cluster_monitoring.html#configuring-etcd-monitoring_prometheus-cluster-monitoring
