




引言
书接上文,前面我们主要讲了 Kubernetes 的实践过程,这一篇文章中,我们着重介绍 Kubernetes 的实现原理。
Kubernetes 实现原理
现在我们已经知道了大多数可以部署到 Kubernetes 的资源,现在是时候了解下它们是怎么被实现的了。我们知道 Kubernetes 有两种节点,控制节点和工作节点。控制平面负责控制并使得整个集群正常运转,包括 etcd,API 服务器,调度器,控制器管理器,这些组件用来存储、 管理集群状态,但它们不是运行应用的容器。工作节点包括 kubelet,kube-proxy,容器运行时(docker|rkt)。除了这些之外,还有 DNS 服务器,Dashboard 服务,Ingress 控制器,容器网络插件,容器集群监控等。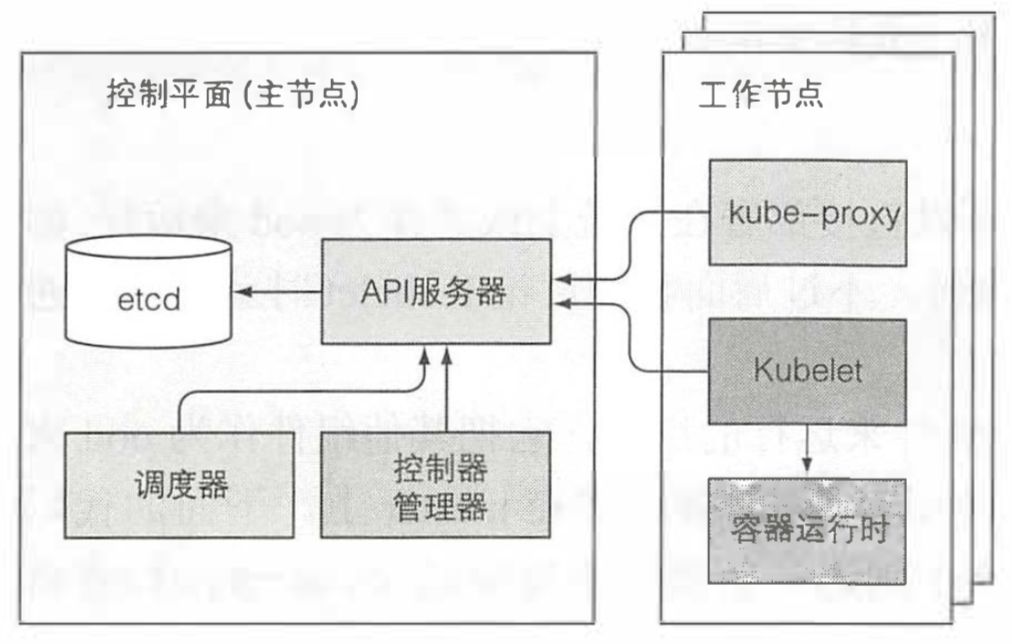 Kubernetes 系统组件间只能通过 API 服务器通信,它们之间不会直接通信。API 服务器是和 etcd 通信的唯一组件。其他组件不会直接和 etcd 通信,而是通过 API 服务器来修改集群状态。API 服务器和其他组件的连接基本都是由组件发起的,如图上所示。但是,当你使用 kubectl 获取日志、使用 kubectl attach 连接到一个运行中的容器或运行 kubectl port-forward 命令时,API 服务器会向 Kubelet 发起连接。
Kubernetes 系统组件间只能通过 API 服务器通信,它们之间不会直接通信。API 服务器是和 etcd 通信的唯一组件。其他组件不会直接和 etcd 通信,而是通过 API 服务器来修改集群状态。API 服务器和其他组件的连接基本都是由组件发起的,如图上所示。但是,当你使用 kubectl 获取日志、使用 kubectl attach 连接到一个运行中的容器或运行 kubectl port-forward 命令时,API 服务器会向 Kubelet 发起连接。
尽管工作节点上的组件都需要运行在同一个节点上,控制平面的组件可以被简单地分割在多台服务器上。为了保证高可用性,控制平面的每个组件可以有多个实例。etcd 和 API 服务器的多个实例可以同时并行工作,但是,调度器和控制器管理器在同一时刻只有一个实例起作用,其他都处于待命状态。
说出来你可能不相信,控制面板的组件以及 kube-proxy 可以直接部署在系统上或者作为 pod 来运行,kubelet 是唯一一直作为常规系统组件来运行的组件,它把其他组件作为 pod 来运行,就比如控制面板的 api 服务器,调度器,控制器管理器都是作为 pod 运行的,只不过这些 pod 都是静态 pod,kubelet 在启动后会检查一个存储静态 pod 的目录,然后将其中的 pod 启动。
etcd 是一个响应快、分布式、一致的 key-value 存储。因为它是分布式的,故可以运行多个 etcd 实例来获取高可用性和更好的性能。
唯一能直接和 etcd 通信的是 Kubernetes 的 API 服务器。所有其他组件通过 API 服务器间接地读取、写入数据到 etcd。这带来一些好处,其中之一就是增强乐观锁系统、验证系统的健壮性;并且,通过把实际存储机制从其他组件抽离,未来替换起来也更容易。值得强调的是,etcd 是 Kubernetes 存储集群状态和元数据的唯一的地方。
乐观并发控制(有时候指乐观锁)是指一段数据包含一个版本数字,而不是锁住该段数据并阻止读写操作。每当更新数据,版本数就会增加。当更新数据时,就会检查版本值是否在客户端读取数据时间和提交时间之间被增加过。如果增加过,那么更新会被拒绝,客户端必须重新读取新数据,重新尝试更新。
Kubernetes API 服务器作为中心组件, 其 他组件或者客户端(如 kubectl)都 会去调用它。以 RESTful API 的形式提供了可以查询、修改集群状态的 CRUD(Create、Read、Update、Delete)接口。它将状态存储到 etcd 中。
首先,API 服务器需要认证发送请求的客户端。这是通过配置在 API 服务器上的一个或多个认证插件来实现的。API 服务器会轮流调用这些插件,直到有一个能确认是谁发送了该请求。除了认证插件,API 服务器还可以配置使用一个或多个授权插件。它们的作用是决定认证的用户是否可以对请求资源执行请求操作。如果请求尝试创建、修改或者删除一个资源,请求需要经过准入控制插件的验证。同理,服务器会配置多个准入控制插件。这些插件会因为各种原因修改资源,可能会初始化资源定义中漏配的字段为默认值甚至重写它们。插件甚至会去修改并不在请求中的相关资源,同时也会因为某些原因拒绝一个请求。资源需要经过所有准入控制插件的验证。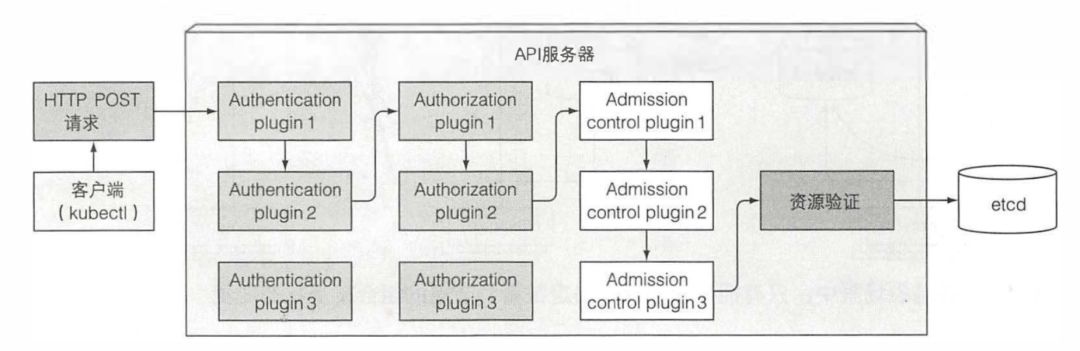 除了前面讨论的,API 服务器没有做其他额外的工作。例如,当你创建一个 ReplicaSet 资源时,它不会去创建 pod, 同时它不会去管理服务的端点。那是控制器管理器的工作。其他组件通过建立和 API 服务器的连接来监听元数据的变化,当 API server 将元数据变化的事件发送到客户端后,客户端会自动做相应的工作。
除了前面讨论的,API 服务器没有做其他额外的工作。例如,当你创建一个 ReplicaSet 资源时,它不会去创建 pod, 同时它不会去管理服务的端点。那是控制器管理器的工作。其他组件通过建立和 API 服务器的连接来监听元数据的变化,当 API server 将元数据变化的事件发送到客户端后,客户端会自动做相应的工作。
调度器
前面已经学习过,我们通常不会去指定 pod 应该运行在哪个集群节点上,这项工作交给调度器。宏观来看,调度器的操作比较简单。就是利用 API 服务器的监听机制等待新创建的 pod, 然后给每个新的、没有节点集的 pod 分配节点。
调度器不会命令选中的节点(或者节点上运行的 Kubelet) 去运行 pod。调度器做的就是通过 API 服务器更新 pod 的定义。然后 API 服务器再去通知 Kubelet(同样,通过之前描述的监听机制)该 pod 已经被调度过。当目标节点上的 Kubelet 发现该 pod 被调度到本节点,它就会创建并且运行 pod 的容器。
我们可以使用自定义的调度器,比如基于机器学习来感知业务高峰,从而自动进行扩容,当然,默认的调度算法还是比较简单的,它的工作流程如下:
过滤所有节点,找出能分配给 pod 的可用节点列表。
节点是否能满足 pod 对硬件资源的请求。
节点是否耗尽资源。
pod 是否要求被调度到指定节点
节点是否有和 pod 规格定义里的节点选择器一致的标签
如果 pod 要求绑定指定的主机端口那么这个节点上的这个端口是否已经被占用?
如果 pod 要求有特定类型的卷,该节点是否能为此 pod 加载此卷,或者说该节点上是否已经有 pod 在使用该卷了
pod 是否能够容忍节点的污点。
pod 是否定义了节点、pod 的亲缘性以及非亲缘性规则?如果是,那么调度节点给该 pod 是否会违反规则?
所有这些测试都必须通过,节点才有资格调度给 pod。在对每个节点做过这些检查后,调度器得到节点集的一个子集。任何这些节点都可以运行 pod, 因为它们都有足够的可用资源,也确认过满足 pod 定义的所有要求。
对可用节点按优先级排序,找出最优节点。如果多个节点都有最高的优先级分数,那么则循环分配,确保平均分配给 pod。
控制器管理器
如前面提到的,API 服务器只做了存储资源到 etcd 和通知客户端有变更的工作。调度器则只是给 pod 分配节点,所以需要有活跃的组件确保系统真实状态朝 API 服务器定义的期望的状态收敛。这个工作由控制器管理器里的控制器来实现。控制器包括:
Replication 管理器
ReplicaSet、DaemonSet 以及 Job 控制器
Deployment 控制器
StatefulSet 控制器
Node 控制器
Service 控制器
Endpoints 控制器
Namespace 控制器
PersistentVolume 控制器
其他
总的来说,控制器执行一个“调和“循环,将实际状态调整为期望状态(在资源 spec 部分定义),然后将新的实际状态写入资源的 status 部分。
Replication
ReplicationController 的操作可以理解为一个无限循环,每次循环,控制器都会查找符合其 pod 选择器定义的 pod 的数量,并且将该数值和期望的复制集 (replica) 数量做比较。控制器不会每次循环去轮询 pod, 而是通过监听机制订阅可能影响期望的复制集 (replica) 数量或者符合条件 pod 数量的变更事件。任何该类型的变化,将触发控制器重新检查期望的以及实际的复制集数量,然后做出相应操作。当运行的 pod 实例太少时,ReplicationController 会运行额外的实例,但它自己实际上不会去运行 pod。它会创建新的 pod 清单,发布到 API 服务器,让调度器以及 Kubelet 来做调度工作并运行 pod。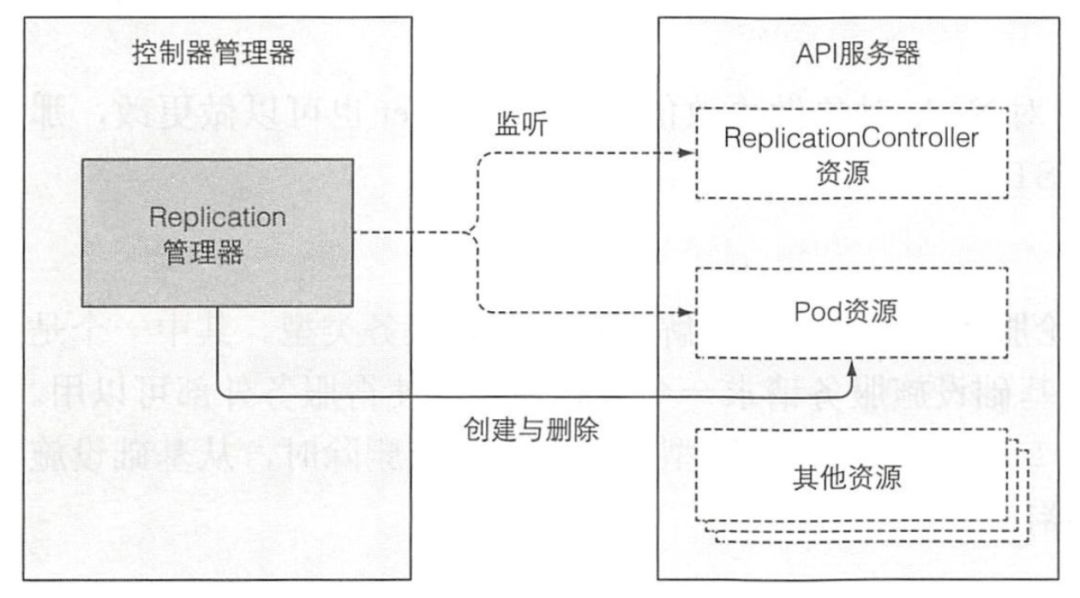 ReplicaSet 控制器基本上做了和前面描述的 Replication 管理器一样的事情,所以这里不再赘述。DaemonSet 以及 Job 控制器比较相似,从它们各自资源集中定义的 pod 模板创建 pod 资源。
ReplicaSet 控制器基本上做了和前面描述的 Replication 管理器一样的事情,所以这里不再赘述。DaemonSet 以及 Job 控制器比较相似,从它们各自资源集中定义的 pod 模板创建 pod 资源。
Deployment
Deployment 控制器负责使 deployment 的实际状态与对应 Deployment API 对象的期望状态同步。
每次 Deployment 对象修改后(如果修改会影响到部署的 pod), Deployment 控制器都会滚动升级到新的版本。通过创建一个 ReplicaSet,然后按照 Deployment 中定义的策略同时伸缩新、旧 ReplicaSet,直到旧 pod 被新的代替。并不会直接创建任何 pod。
StatefulSet
StatefulSet 控制器,类似于 ReplicaSet 控制器以及其他相关控制器,根据 StatefulSet 资源定义创建、管理、删除 pod。其他的控制器只管理 pod,而 StatefulSet 控制器会初始化并管理每个 pod 实例的持久卷声明字段。
Node
Node 控制器管理 Node 资源,描述了集群工作节点。其中,Node 控制器使节点对象列表与集群中实际运行的机器列表保持同步。同时监控每个节点的健康状态,删除不可达节点的 pod。
Service 控制器
Service 控制器就是用来在 LoadBalancer 类型服务被创建或删除时,从基础设施服务请求、释放负载均衡器的。
Endpoint
您可能还记得,Service 不会直接连接到 pod,而是包含一个端点列表 (Ip 和端口),列表要么是手动,要么是根据 Service 定义的 pod 选择器自动创建、更新。
当 Service 被添加、修改,或者 pod 被添加、修改或删除时,控制器会选中匹配 Service 的 pod 选择器的 pod, 将其 ip 和端口添加到 Endpoint 资源中。请记住,Endpoint 对象是个独立的对象,所以当需要的时候控制器会创建它。同样地,当删除 Service 时,Endpoint 对象也会被删除。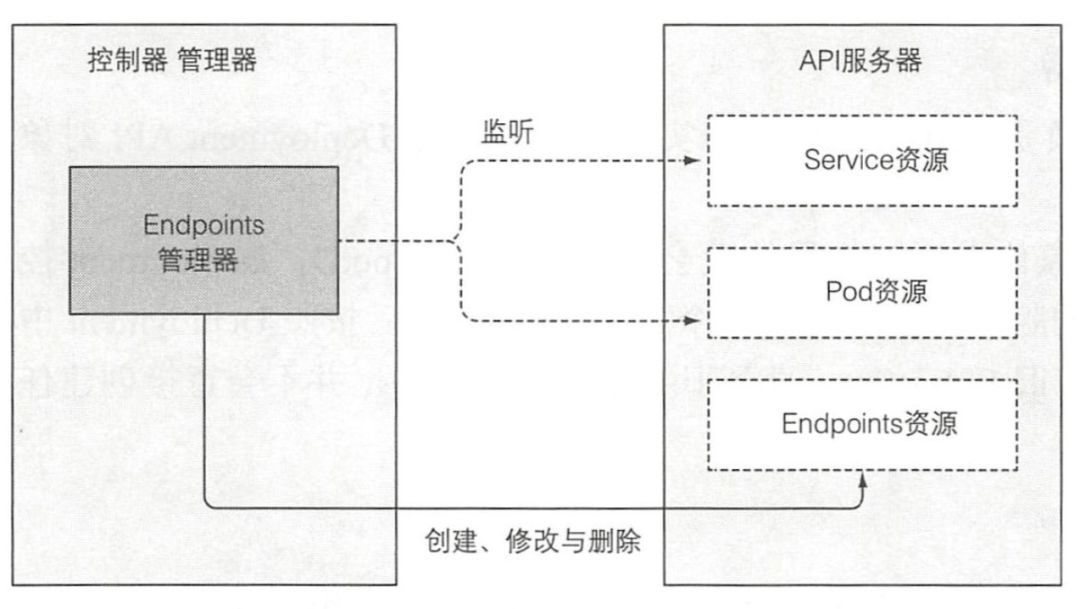
Namespace
当删除一个 Namespace 资源时,该命名空间里的所有资源都会被删除。这就是 Namespace 控制器做的事情。
PersistentVolume
一旦用户创建了一个持久卷声明,Kubernetes 必须找到一个合适的持久卷同时将其和声明绑定。这些由持久卷控制器实现。对于一个持久卷声明,控制器为声明查找最佳匹配项,通过选择匹配声明中的访问模式,并且声明的容量大于需求的容量的最小持久卷。
当用户删除持久卷声明时,会解绑卷,然后根据卷的回收策略进行回收(原样保留、删除或清空)。
控制器协作
下面,我会以一个 Deployment 资源的创建为例,介绍控制器之间的协作: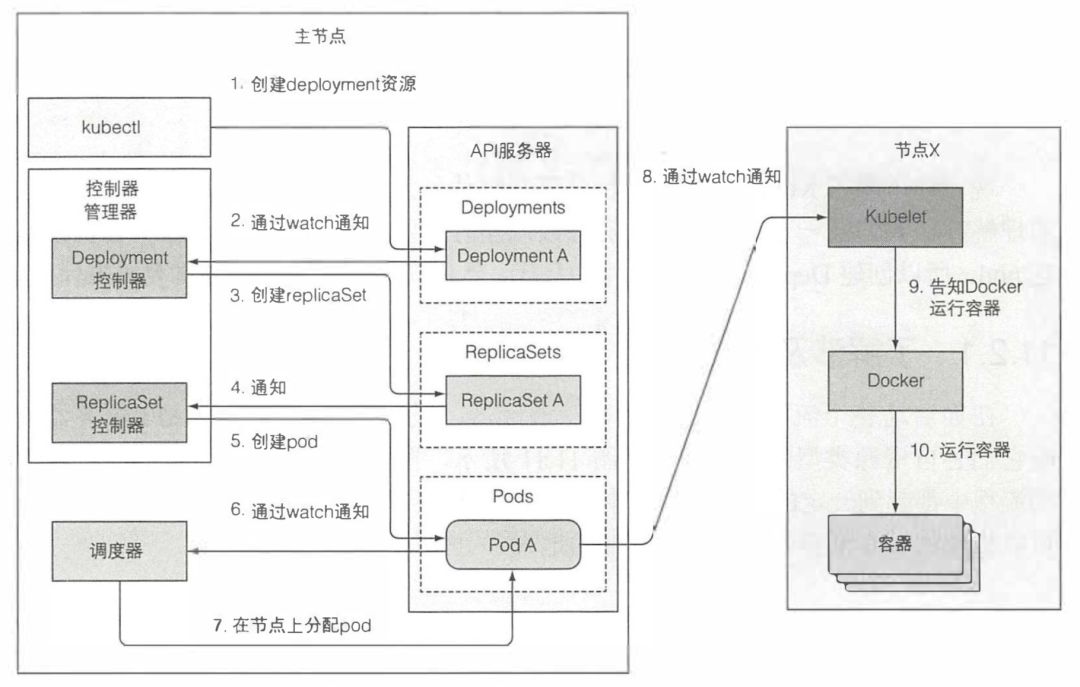
kubelet
简单地说,Kubelet 就是负责所有运行在工作节点上内容的组件。它第一个任务就是在 API 服务器中创建一个 Node 资源来注册该节点。然后需要持续监控 API 服务器是否把该节点分配给 pod,然后启动 pod 容器。
Kubelet 也是运行容器存活探针的组件,当探针报错时它会重启容器。最后一点,当 pod 从 API 服务器删除时,Kubelet 终止容器,并通知服务器 pod 己经被终止了。
尽管 Kubelet 一般会和 API 服务器通信并从中获取 pod 清单,它也可以基于本地指定目录下的 pod 清单来运行 pod,这就是前面说的静态 pod。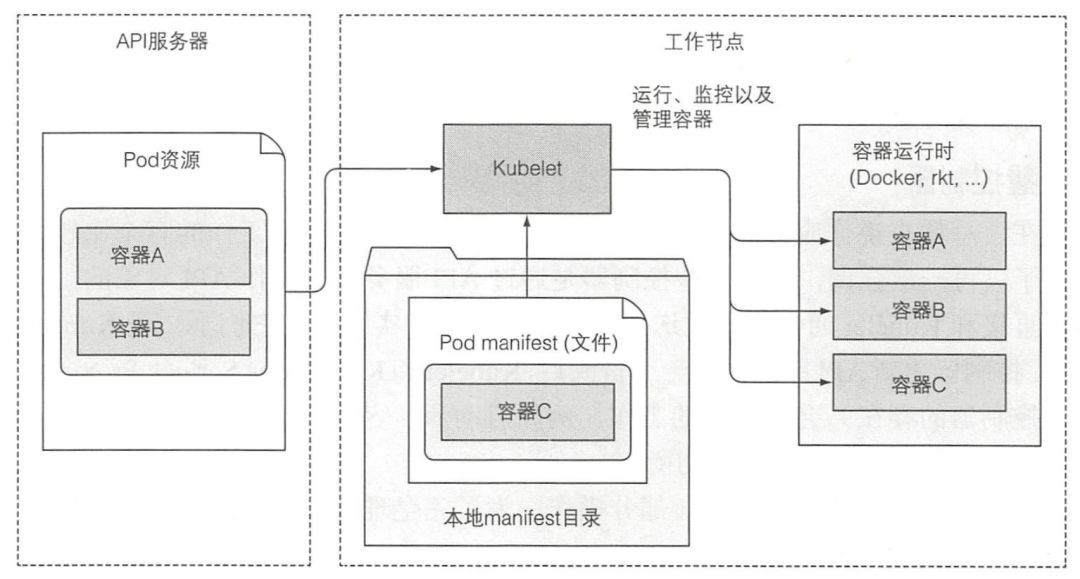
kube-proxy
除了 Kubelet,每个工作节点还会运行 kube-proxy,用于确保客户端可以通过 Kubernetes API 连接到你定义的服务。kube-proxy 确保对服务 IP 和端口的连接最终能到达支持服务(或者其他,非 pod 服务终端)的某个 pod 处。如果有多个 pod 支 撑一个服务,那么代理会发挥对 pod 的负载均衡作用。
现在默认的 kube-proxy 实现是通过配置 iptables 直接通过重定向到满足条件的 pod 中。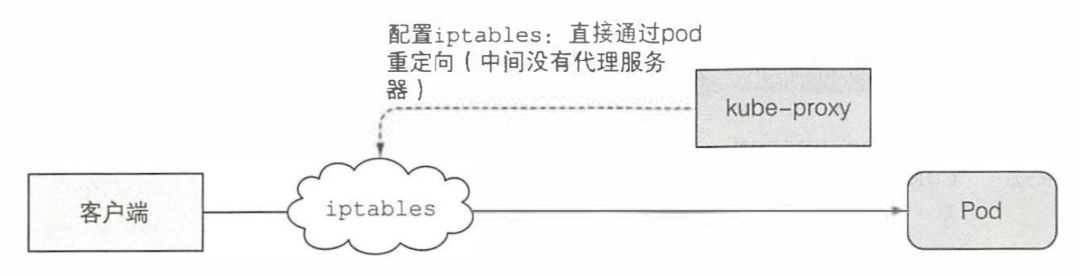
插件
我们已经讨论了 Kubernetes 集群正常工作所需要的一些核心组件。但是除了这些核心组件之外,还有一些可有可无的插件。这些插件用于启用 Kubernetes 服务的 DNS 查询,通过单个外部 IP 暴露多个 HTTP 服务,Kubernetes 仪表盘等。
DNS
集群中的所有 pod 默认配置使用集群内部 DNS 服务器。这使得 pod 能够轻松地通过名称查询到服务,甚至是无头服务 pod 的 IP 地址。kube-dns pod 利用 API 服务器的监控机制来订阅 Service 和 Endpoint 的变动,以及 DNS 记录的变更,使得其客户端(相对地)总是能够获取到最新的 DNS 信息。
Ingress
Ingress 控制器运行一个反向代理服务器(例如,类似 Nginx), 根据集群中定义的 Ingress、Service 以及 Endpoint 资源来配置该控制器。所以需要订阅这些资源(通过监听机制),然后每次其中一个发生变化则更新代理服务器的配置。
Pod
前面我们介绍过 pod 是什么,这里我们再简单地说一下,当你创建一个 pod 时实际运行的是 Docker。但是它不是简单运行一个 docker 镜像,在启动真正的镜像之前,它会先启动一个附加容器,这个容器没有做任何事,容器命令是 pause。该容器将一个 pod 所有的容器收纳到一起。还记得一个 pod 的所有容器是如何共享同一个网络和 Linux 命名空间的吗?暂停的容器是一个基础容器,它的唯一目的就是保存所有的命名空间。所有 pod 的其他用户定义容器使用 pod 的该基础容器的命名空间。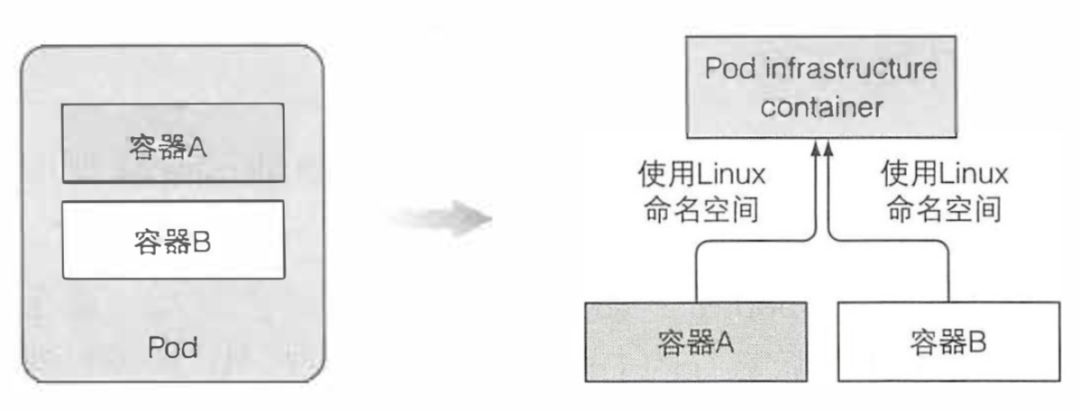 实际的应用容器可能会挂掉并重启。当容器重启,容器需要处于与之前相同的 Linux 命名空间中。基础容器使这成为可能,因为它的生命周期和 pod 绑定,基础容器 pod 被调度直到被删除一直会运行。如果基础 pod 在这期间被关闭,Kubelet 会重新创建它,并且会重建 pod 的所有容器。
实际的应用容器可能会挂掉并重启。当容器重启,容器需要处于与之前相同的 Linux 命名空间中。基础容器使这成为可能,因为它的生命周期和 pod 绑定,基础容器 pod 被调度直到被删除一直会运行。如果基础 pod 在这期间被关闭,Kubelet 会重新创建它,并且会重建 pod 的所有容器。
网络原理
作为拓展,这里我们以 flannel 为例展开介绍一下 Kubernetes 内网络通讯的实现。在介绍之前,我们得先明确 Kubernetes 中的三种网络的概念:
node network:承载 kubernetes 集群中各个“物理”Node(master 和 worker)通信的网络
service network:由 kubernetes 集群中的 Services 所组成的“网络”,它的范围在启动集群的时候进行了配置
flannel network:即 Pod 网络,集群中承载各个 Pod 相互通信的网络,它的范围在启动集群和启动网络插件的时候进行了配置
node network 自不必多说,node 间通过其局域网(无论是物理的还是虚拟的)通信。
Pod 网络
pod 网络即 flannel network 是我们要理解的重点,cluster 中各个 Pod 要实现相互通信,必须走这个网络,无论是在同一 node 上的 Pod 还是跨 node 的 Pod。这里以我的集群为例,介绍 flannel 的网络结构。
默认情况下,每个节点会从 PodSubnet 中注册一个掩码长度为 24 的子网,然后该节点的所有 pod ip 地址都会从该子网中分配。当 flannel 启动成功后,会在宿主机上生成一个描述子网环境的文件,该文件中记录了所有 pod 的子网范围(FLANNEL_NETWORK)以及本机 pod 的子网范围(FLANNEL_SUBNET):
cat run/flannel/subnet.env# 文件内容如下#FLANNEL_NETWORK=192.168.128.0/18#FLANNEL_SUBNET=192.168.132.1/24#FLANNEL_MTU=1450#FLANNEL_IPMASQ=true
当集群内的每个机器分配好属于自己的 pod subnet 域后,会在自己的网络设备中新增一个名为 flannel.1
的类型为 vxlan 的网络设备:
ip -d link show#eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000# link/ether fa:16:3f:56:85:66 brd ff:ff:ff:ff:ff:ff promiscuity 0 addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535#flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default# link/ether 86:4f:51:1e:bb:38 brd ff:ff:ff:ff:ff:ff promiscuity 0# vxlan id 1 local 10.231.209.117 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535#cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000# link/ether 4e:a6:bb:c7:b9:d7 brd ff:ff:ff:ff:ff:ff promiscuity 0# bridge forward_delay 1500 hello_time 200 max_age 2000 ageing_time 30000 stp_state 0 priority 32768 vlan_filtering 0 vlan_protocol 802.1Q bridge_id 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 root_port 0 root_path_cost 0 topology_change 0 topology_change_detected 0 hello_timer 0.00 tcn_timer 0.00 topology_change_timer 0.00 gc_timer 121.78 vlan_default_pvid 1 vlan_stats_enabled 0 group_fwd_mask 0 group_address 01:80:c2:00:00:00 mcast_snooping 1 mcast_router 1 mcast_query_use_ifaddr 0 mcast_querier 0 mcast_hash_elasticity 4 mcast_hash_max 512 mcast_last_member_count 2 mcast_startup_query_count 2 mcast_last_member_interval 100 mcast_membership_interval 26000 mcast_querier_interval 25500 mcast_query_interval 12500 mcast_query_response_interval 1000 mcast_startup_query_interval 3125 mcast_stats_enabled 0 mcast_igmp_version 2 mcast_mld_version 1 nf_call_iptables 0 nf_call_ip6tables 0 nf_call_arptables 0 addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535#veth65d142e7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default# link/ether 3e:86:a0:c8:f7:ca brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1# veth# bridge_slave state forwarding priority 32 cost 2 hairpin on guard off root_block off fastleave off learning on flood on port_id 0x8001 port_no 0x1 designated_port 32769 designated_cost 0 designated_bridge 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
从 flannel.1 的设备信息来看,它似乎与 eth0 存在着某种 bind 关系,而 eth0 则是宿主机上的原始网络。这是在其他 bridge、veth 设备描述信息中所没有的。此外我们还可以看出 veth 设备是 cni0 的 bridge_slave。然后我们着重看一下 Kubernetes 各个网卡的 ip。
ip -d addr show#flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default# link/ether 86:4f:51:1e:bb:38 brd ff:ff:ff:ff:ff:ff promiscuity 0# vxlan id 1 local 10.231.209.117 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535# inet 192.168.132.0/32 scope global flannel.1# valid_lft forever preferred_lft forever#cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000# link/ether 4e:a6:bb:c7:b9:d7 brd ff:ff:ff:ff:ff:ff promiscuity 0# bridge forward_delay 1500 hello_time 200 max_age 2000 ageing_time 30000 stp_state 0 priority 32768 vlan_filtering 0 vlan_protocol 802.1Q bridge_id 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 root_port 0 root_path_cost 0 topology_change 0 topology_change_detected 0 hello_timer 0.00 tcn_timer 0.00 topology_change_timer 0.00 gc_timer 226.02 vlan_default_pvid 1 vlan_stats_enabled 0 group_fwd_mask 0 group_address 01:80:c2:00:00:00 mcast_snooping 1 mcast_router 1 mcast_query_use_ifaddr 0 mcast_querier 0 mcast_hash_elasticity 4 mcast_hash_max 512 mcast_last_member_count 2 mcast_startup_query_count 2 mcast_last_member_interval 100 mcast_membership_interval 26000 mcast_querier_interval 25500 mcast_query_interval 12500 mcast_query_response_interval 1000 mcast_startup_query_interval 3125 mcast_stats_enabled 0 mcast_igmp_version 2 mcast_mld_version 1 nf_call_iptables 0 nf_call_ip6tables 0 nf_call_arptables 0 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535# inet 192.168.132.1/24 scope global cni0# valid_lft forever preferred_lft forever#veth65d142e7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default# link/ether 3e:86:a0:c8:f7:ca brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1# veth# bridge_slave state forwarding priority 32 cost 2 hairpin on guard off root_block off fastleave off learning on flood on port_id 0x8001 port_no 0x1 designated_port 32769 designated_cost 0 designated_bridge 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
可以看到 flannel.1 和 cni0 的 ip 和该宿主机被分配的 FLANNEL_SUBNET 的 ip 范围一致。然后,我们再看一看该主机上的路由表:
ip route#default via <local network gateway> dev eth0 metric 10#<local subnet> dev eth0 proto kernel scope link src <local ip>#192.168.128.0/24 via 192.168.128.0 dev flannel.1 onlink#192.168.129.0/24 via 192.168.129.0 dev flannel.1 onlink#192.168.130.0/24 via 192.168.130.0 dev flannel.1 onlink#192.168.131.0/24 via 192.168.131.0 dev flannel.1 onlink#192.168.132.0/24 dev cni0 proto kernel scope link src 192.168.132.1#192.168.133.0/24 via 192.168.133.0 dev flannel.1 onlink
路由表显示,当要发送给自己的 pod 子网时(192.168.132.0/24),会通过 cni0 网卡,而当要发送其他宿主机的 pod 时,会通过 flannel.1 网卡。到这里,我们总结一下已经得到的情报,Kubernetes 目前通过 flannel.1 和 cni0 两个网卡来完成 pod 子网的通讯,flannel.1 负责本机 Pod 与其他宿主机 Pod 之间的通讯,cni0 负责本机内 Pod 间的通讯。那么还有两个疑问:1. cni0 又是怎么连通 docker 内容器的?2. flannel.1 是怎么连通其他宿主机的?我们知道 Pod 内的进程都是跑在 Docker 容器里的,为了探究 cni0 的工作原理,我们就得深入调查一下 Docker 容器使用的网络结构。
# e1adc507e8bc 是 kubia 服务的容器docker exec -it e1adc507e8bc ip route#default via 192.168.132.1 dev eth0#192.168.128.0/18 via 192.168.132.1 dev eth0#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.73docker exec -it e1adc507e8bc ip -d link show#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity 0#3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default# link/ether 3e:43:3e:1f:48:a1 brd ff:ff:ff:ff:ff:ff promiscuity 0# vethdocker exec -it e1adc507e8bc ip -d addr show#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00# inet 127.0.0.1/8 scope host lo# valid_lft forever preferred_lft forever# inet6 ::1/128 scope host# valid_lft forever preferred_lft forever#3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default# link/ether 3e:43:3e:1f:48:a1 brd ff:ff:ff:ff:ff:ff# inet 192.168.132.73/24 scope global eth0# valid_lft forever preferred_lft forever# inet6 fe80::3c43:3eff:fe1f:48a1/64 scope link# valid_lft forever preferred_lft forever
我们在 kubia 服务的 docker 容器中,可以看到 docker 内部的网络也已经是宿主机分配的 pod 子网 192.168.132.0/24,它的 ip 是 192.168.132.73,mac 地址是 3e:43:3e:1f:48:a1,而且所有 pod 网段的数据包都是通过 eth0 网卡发送的。那么 docker 容器内的 eth0 网卡的数据是怎么发送到宿主机的呢?我们不妨来看一下该 Pod 的 pause 容器配置,因为网络的设置都在 pause 中完成,其他 pod 内容器都是复用 pause 容器的网络。
# 12e3a9c720d7 是 kubia pod 的 pause 容器docker inspect 12e3a9c720d7# 从 NetworkSettings 中我们可以获得如下信息#"NetworkID": "33fd5df9316947f37e388d49b121d47c589d7a2510b7bf055d6d55e0e57c75c8"#"EndpointID": "106924f59a8d74db3f8045ac40feb9c9aa5b0ad0b320fadd344496eec39ff107"
然后我们再看一下 docker 中如何定义网络 33fd5df93。
docker network inspect 33fd5df93
很奇怪,在该网络的描述中并没有像 docker0 网桥那样显式地声明自己是网桥类型("Driver": "bridge")。
[{"Name": "bridge","Id": "2cb95162f702d9f36620f95d61cba76055eeedc3791761209329eab37ef90235","Created": "2019-09-25T20:04:07.55834704+09:00","Scope": "local","Driver": "bridge","EnableIPv6": false,"IPAM": {"Driver": "default","Options": null,"Config": [{"Subnet": "172.17.0.0/16","Gateway": "172.17.0.1"}]},"Internal": false,"Attachable": false,"Containers": {},"Options": {"com.docker.network.bridge.default_bridge": "true","com.docker.network.bridge.enable_icc": "true","com.docker.network.bridge.enable_ip_masquerade": "true","com.docker.network.bridge.host_binding_ipv4": "0.0.0.0","com.docker.network.bridge.name": "docker0","com.docker.network.driver.mtu": "1500"},"Labels": {}}]
相反的,这里 Kubernetes 使用了 null 驱动("Driver": "null")。
[{"Name": "none","Id": "33fd5df9316947f37e388d49b121d47c589d7a2510b7bf055d6d55e0e57c75c8","Created": "2019-09-25T15:56:05.76660028+09:00","Scope": "local","Driver": "null","EnableIPv6": false,"IPAM": {"Driver": "default","Options": null,"Config": []},"Internal": false,"Attachable": false,"Containers": {"12e3a9c720d72a41e829aeaa3e310436e1b9e33e1a7f8578b065506b64cb9b49": {"Name": "k8s_POD_kubia-24hmb_default_3586fce7-a27c-4955-9c74-8bd1bb2b9171_0","EndpointID": "106924f59a8d74db3f8045ac40feb9c9aa5b0ad0b320fadd344496eec39ff107","MacAddress": "","IPv4Address": "","IPv6Address": ""},"598b6a4eeba4ae11ecfb2f07603bda106ade78acfea6776bb1aad624edc2d850": {"Name": "k8s_POD_kubia-rpr99_default_a628f355-75c4-4d4b-a637-a81e3b30a156_0","EndpointID": "dfe139b8af4391507ed411d813200adbe7a3d9f30ab78e4682025e24afa30fec","MacAddress": "","IPv4Address": "","IPv6Address": ""},"e7e15a5df3880d22a2ca4b254f959346d487c5b8869af0448989a73f518cb553": {"Name": "k8s_POD_coredns-5644d7b6d9-v56sk_kube-system_53751e33-88d8-4ab0-a831-a4fdf04c3fae_0","EndpointID": "5232bea08ee84f86ed5b6489743061377766d495139ff9e42b7e21d110d23d65","MacAddress": "","IPv4Address": "","IPv6Address": ""}},"Options": {},"Labels": {}}]
bridge 驱动,默认模式,即 docker0 网桥模式。此驱动为 docker 的默认设置,使用这个驱动的时候,libnetwork 将创建出的 Docker 容器连接到 Docker 网桥上。作为最常规的模式,bridge 模式已经可以满足 Docker 容器最基本的使用需求了。然而其与外界通信使用 NAT,增加了通信的复杂性,在复杂场景下使用会有诸多限制。null 驱动使用这种驱动的时候,Docker 容器拥有自己的 network namespace,但是并不需要 Docker 容器进行任何网络配置。也就是说,这个 Docker 容器除了 network namespace 自带的 loopback 网卡外,没有其他任何网卡、IP、路由等信息,需要用户为 Docker 容器添加网卡、配置 IP 等。这种模式如果不进行特定的配置是无法正常使用的,但是优点也非常明显,给了用户最大的自由度来自定义容器的网络环境。
这么看来,每个 pod 中的网络空间应该是独立的,Kubernetes 创建好容器后手动向 docker 容器的 network 命名空间中加网卡,进而连通到宿主机的 cni0 网桥的。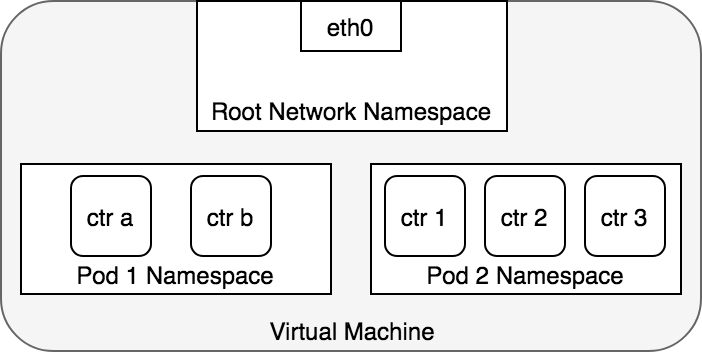 那么它又是怎么做到的呢?为了复现 Kubernetes 管理容器网络的方案,我创建了一个新的容器,并且同样使用前面用到的 kubia 镜像。同时,我们也使用 Kubernetes 的 null Driver 网络。
那么它又是怎么做到的呢?为了复现 Kubernetes 管理容器网络的方案,我创建了一个新的容器,并且同样使用前面用到的 kubia 镜像。同时,我们也使用 Kubernetes 的 null Driver 网络。
docker create --network 33fd5df931694 beikejiedeliulangmao/kubia# 确认一下容器内的网卡情况,发现确实只有 loopbackdocker exec -it 8ef9475b6d6e ip a#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00# inet 127.0.0.1/8 scope host lo# valid_lft forever preferred_lft forever# inet6 ::1/128 scope host# valid_lft forever preferred_lft forever
然后,我们使用 Kubernetes 的 cni0 网桥,连通容器和宿主机,具体怎么做呢?第一步,我们先将容器内的网络空间共享出来,让宿主机可以操作。
# 查看容器的 piddocker inspect 8ef9475b6d6e|grep Pid# "Pid": 68791# 创建网络命名空间目录,后面操作网络空间时都会基于此目录存储的内容mkdir var/run/netns# 根据 pid 得到容器的网络空间,然后通过软连接的方式共享到宿主机空间ln -s proc/68791/ns/net var/run/netns/8ef9475b6d6e# 确认网络空间是否出现ip netns list# 然后查看网络空间的内容ip netns exec 8ef9475b6d6e ip a#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00# inet 127.0.0.1/8 scope host lo# valid_lft forever preferred_lft forever# inet6 ::1/128 scope host# valid_lft forever preferred_lft forever
到这为止,我们就可以在宿主机中,看到 docker 容器的网络空间内容了,接下来是第二步,基于 Kubernetes 的 cni0 网桥连通宿主机和新建的容器。
# 我们先看一下网桥的名字brctl show#bridge name bridge id STP enabled interfaces#cni0 8000.4ea6bbc7b9d7 no veth0bcd3dfd# veth65d142e7# veth9e1cec0c# 如果您想自己创建一个新的网桥的话可以通过如下命令:#brctl addbr newBridge#ip addr add x.x.x.x/x dev newBridge#ip link set dev newBridge up# 这里我们直接使用 Kubernetes 的 cni0 网桥,然后创建一个连接对端 peerip link add veth123 type veth peer name veth456# 将 veth123 插到宿主机的 cni0 网桥上brctl addif cni0 veth123ip link set veth123 upbrctl show#bridge name bridge id STP enabled interfaces#cni0 8000.4ea6bbc7b9d7 no veth0bcd3dfd# veth65d142e7# veth9e1cec0c# veth123# 将 veth456 放入容器的网络空间后,容器中就能看到该网络设备,而宿主机中就看不到了ip link set veth456 netns 8ef9475b6d6eip netns exec 8ef9475b6d6e ip a#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00# inet 127.0.0.1/8 scope host lo# valid_lft forever preferred_lft forever# inet6 ::1/128 scope host# valid_lft forever preferred_lft forever#13: veth456@if14: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000# link/ether ae:17:f4:64:63:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0# 我们也将容器中的网卡重命名为 eth0,启动后再为其分配一个 ip 地址ip netns exec 8ef9475b6d6e ip link set veth456 name eth0ip netns exec 8ef9475b6d6e ip link set eth0 upip netns exec 8ef9475b6d6e ip addr add 192.168.132.150/24 dev eth0ip netns exec 8ef9475b6d6e ip a#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00# inet 127.0.0.1/8 scope host lo# valid_lft forever preferred_lft forever# inet6 ::1/128 scope host# valid_lft forever preferred_lft forever#13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000# link/ether ae:17:f4:64:63:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0# inet 192.168.132.150/24 scope global eth0# valid_lft forever preferred_lft forever# inet6 fe80::ac17:f4ff:fe64:6305/64 scope link# valid_lft forever preferred_lft forever# 是不是网络设备的信息已经和 Kubernetes 的容器内网络信息一样了ip netns exec 8ef9475b6d6e ip route#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150# 然后我们在宿主机 ping 一下该主机ping 192.168.132.150#PING 192.168.132.150 (192.168.132.150) 56(84) bytes of data.#64 bytes from 192.168.132.150: icmp_seq=1 ttl=64 time=0.210 ms#64 bytes from 192.168.132.150: icmp_seq=2 ttl=64 time=0.094 ms
现在,我们新建的容器已经能和宿主机连通了,但是还不能 ping 通其他网络设备,所以我们给其加一个默认路由,就像 Pod 容器中一样。
ip netns exec 8ef9475b6d6e ip route add default via 192.168.132.1ip netns exec 8ef9475b6d6e ip route add 192.168.128.0/18 via 192.168.132.1ip netns exec 8ef9475b6d6e ip route#ip netns exec 8ef9475b6d6e ip route#default via 192.168.132.1 dev eth0#192.168.128.0/18 via 192.168.132.1 dev eth0#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150ip netns exec 8ef9475b6d6e ping 192.168.132.73ip netns exec 8ef9475b6d6e curl 192.168.132.73:8080ip netns exec 8ef9475b6d6e ping 172.17.0.2ip netns exec 8ef9475b6d6e curl google.comip netns exec 8ef9475b6d6e ping google.com
现在我们的容器网络不光能连通 pod 的网络,还能连通其他段(172.17.0.1)的网络啦。这里大家可能会有一个疑问,为什么我能 curl 连通 google.com,但是 ping 却不行呢?因为在宿主机上对 tcp 做了 SNAT,而 ping 使用的 icmp 则没有做 SNAT,这就导致从我们建立的网络中发出去的 icmp 包有去无回。
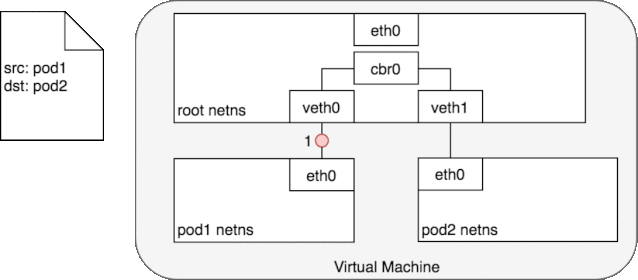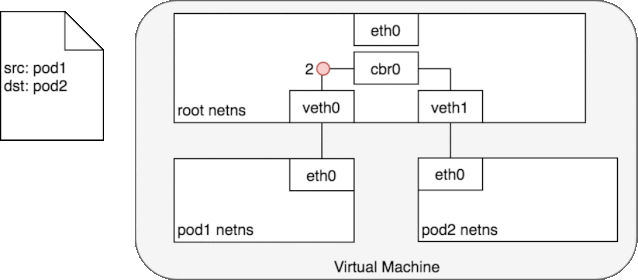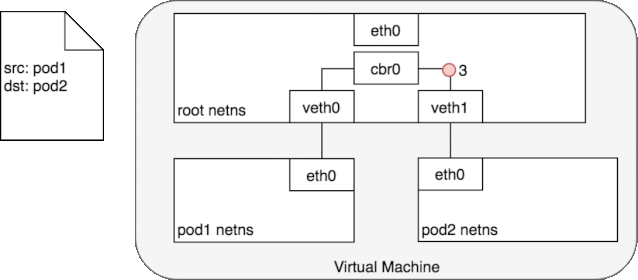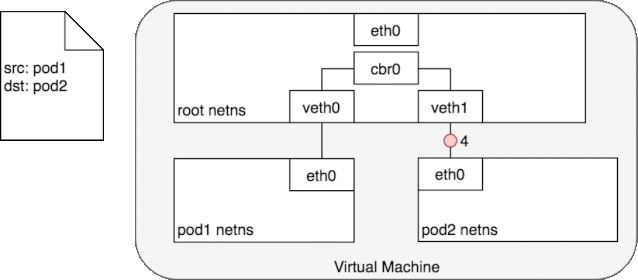
图中的 cbr0 实际上就是 cni0 网桥的别名。在 Kubernetes 的 cni 中默认将网络命名为 cbr0,您可以在
/var/lib/cni/networks/cbr0
中看到 Kubernetes 分配的所有地址,以及每个地址对应的容器 id(ip 地址作为文件名),而在/var/lib/cni/cache/results
中存储了每个容器对应的网桥和插在网桥上的对端网络设备。
好了,我们终于解决了第一个问题:cni0 设备是如何连通 docker 容器,并让容器间的网络互通的。不同容器间的通讯是通过直联网络,实质上 cni0 在网络中的第二层(数据链路层)运转,这里以我们新建的容器和 pod 容器之间的通讯为例。当我们在新建的容器中 ping pod 容器,根据路由表,将匹配到 192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150
,即无需 gateway 转发便可以直接将数据包送达。ARP 查询后(要么从 arp cache 中找到,要么在 cni0 这个二层交换机中泛洪查询)获得 192.168.132.73 的 mac 地址。ip 包的目的 ip 填写 192.168.132.73,二层数据帧封包将目的 mac 填写为刚刚查到的 mac 地址,通过 eth0(192.168.132.150)发送出去。eth0 实际上是一个 veth pair,另外一端“插”在 cni0 这个交换机上,因此这一过程就是一个标准的二层交换机的数据报文交换过程, cni0 相当于从交换机上的一个端口收到以太帧数据,并将数据从另外一个端口发出去。只有当在 pod 中访问 localhost,127.0.0.1,或者自己的 ip 时,数据帧只会和容器内的 eth0 交互。
泛洪查询:交换机根据收到数据帧中的源 MAC 地址建立该地址同交换机端口的映射,并将其写入 MAC 地址表中。交换机将数据帧中的目的 MAC 地址同已建立的 MAC 地址表进行比较,以决定由哪个端口进行转发。如数据帧中的目的 MAC 地址不在 MAC 地址表中,则向所有端口转发。当任意节点回应了该数据帧,就将该节点的 MAC 地址和上述 IP 绑定,存在 MAC 表中。
而如果我是在刚才的容器中 ping 了其他网段的地址 比如 docker 的默认网桥 docker0 172.17.0.2
。当 ping 执行后,根据容器路由表,没有匹配到直连网络,只能通过 default 路由将数据包发给 Gateway: 192.168.132.1。虽然都是 cni0 接收数据,但这次更类似于“数据被直接发到 Bridge 上(因为桥的 ip 就是 192.168.132.1),而不是 Bridge 从一个端口接收转发给另一个端口”。二层的目的 mac 地址填写的是 gateway 192.168.132.1 自己的 mac 地址(cni0 Bridge 的 mac 地址),此时的 cni0 更像是一块普通网卡的角色,工作在三层(网络层)。cni0 收到数据包后,发现并非是发给自己的 ip 包,通过主机路由表找到直连链路路由,cni0 将数据包 Forward 到 docker0 上(封装的二层数据包的目的 MAC 地址为 docker0 的 mac 地址)。此时的 docker0 也是一种“网卡”的角色,由于目的 ip 依然不是 docker0 自身,因此 docker0 也会继续这一转发流程。通过 traceroute 可以印证这一过程:
ip netns exec 8ef9475b6d6e traceroute 172.17.0.2#traceroute to 172.17.0.2 (172.17.0.2), 30 hops max, 60 byte packets# 1 192.168.132.1 0.124 ms 0.053 ms 0.030 ms# 2 172.17.0.1 3005.955 ms !H 3005.909 ms !H 3005.875 ms !H
现在,我们开始探索第二个问题,flannel.1 网络设备如何连通不同主机之间的 pod。通过前面的 docker0 例子中,我们知道 pod 中的数据帧如何通过宿主机的路由转发到其他网络设备,现在我们假设要发请求给另一个宿主机上的 pod(192.168.128.10),这时候会匹配到 192.168.128.0/24 via 192.168.128.0 dev flannel.1 onlink
。因为本机 flannel.1 网络设备的 ip(192.168.132.0) 并不是目标地址(192.168.128.10),所以数据帧到达 flannel.1 之后也是要发出去。数据包沿着网络协议栈向下流动,在二层时需要封二层以太包,填写目的 mac 地址,这时一般应该发出 ARP:”who is 192.168.128.10″,但是要记住 flannel.1 是一个 vxlan 设备,因为该类设备的特殊性,他并不会真正的在第二层发送这个 ARP 包,而是由 linux kernel 引发一个 ”L2 MISS” 事件并将 ARP 请求发到用户空间的 flannel 程序。flannel 程序收到 ”L2 MISS” 内核事件以及 ARP 请求(who is 192.168.128.10)后,并不会向外网发送 ARP request,而是尝试从 etcd 查找该地址匹配的子网的 VtepMAC 信息,该信息目前存在 /registry/minions/<host_name>
。
VxLan: 全称是 Virtual eXtensible Local Area Network,虚拟可扩展的局域网。它是一种 overlay 技术,通过三层的网络来搭建虚拟的二层网络, 只要是三层可达(能够通过 IP 互相通信)的网络就能部署 vxlan。接下来的实例中,您会清晰地了解到 VxLan 如何工作。
接下来,flannel 将查询到的信息放入宿主机的 ARP cache 表中:
ip n |grep 192.168#192.168.132.100 dev cni0 lladdr 7a:cf:98:ce:4b:cc STALE#192.168.132.70 dev cni0 lladdr 12:4a:7a:31:5b:d7 REACHABLE#192.168.132.150 dev cni0 lladdr ae:17:f4:64:63:05 STALE#192.168.132.73 dev cni0 lladdr 3e:43:3e:1f:48:a1 STALE#192.168.133.0 dev flannel.1 lladdr 02:4e:1e:94:98:20 PERMANENT#192.168.132.69 dev cni0 lladdr ca:b7:e3:83:0d:3a STALE#192.168.129.0 dev flannel.1 lladdr 7a:52:54:58:5f:4c PERMANENT#192.168.128.0 dev flannel.1 lladdr 26:12:3f:ba:e9:f5 PERMANENT#192.168.131.0 dev flannel.1 lladdr 62:6d:b4:f7:47:0b PERMANENT#192.168.130.0 dev flannel.1 lladdr 56:d7:1a:70:7b:e0 PERMANENT#192.168.132.72 dev cni0 lladdr f2:98:cd:7b:23:d9 STALE
flannel 完成这项工作后,linux kernel 就可以在 ARP table 中找到 192.168.128.10 对应的子网基 ip(192.168.128.0)的 mac 地址并封装二层以太包了。
到目前为止,已经呈现在大家眼前的封包如下图: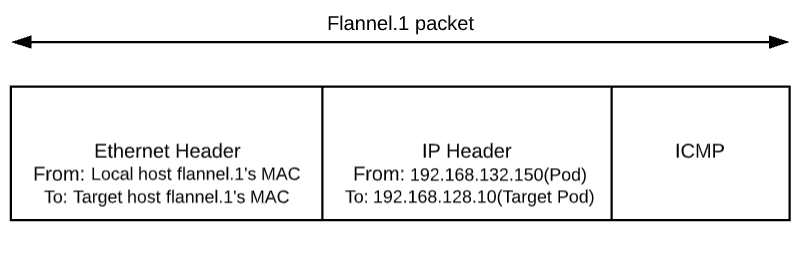 不过这个封包还不能在物理网络上传输,因为它实际上只是 vxlan tunnel 上的 packet。我们需要将上述的 packet 从本机传输到目标机器上,这就得再次封包。这个任务在 vxlan 的 flannel network 中由 linux kernel 来完成。
不过这个封包还不能在物理网络上传输,因为它实际上只是 vxlan tunnel 上的 packet。我们需要将上述的 packet 从本机传输到目标机器上,这就得再次封包。这个任务在 vxlan 的 flannel network 中由 linux kernel 来完成。
flannel.1 为 vxlan 设备,linux kernel 可以自动识别,并将上面的 packet 进行 vxlan 封包处理。在这个封包过程中,kernel 需要知道该数据包究竟发到哪个 node 上去。kernel 需要查看本机上的 fdb(forwarding database)以获得上面对端 vtep 设备(已经从 ARP table 中查到其 mac 地址:26:12:3f:ba:e9:f5)所在的 node 地址。如果 fdb 中没有这个信息,那么 kernel 会向用户空间的 flannel 程序发起”L3 MISS”事件。flannel 收到该事件后,会查询 etcd,获取该 vtep 设备对应的 node 的 IP,并将信息注册到 fdb 中。
这样 Kernel 就可以顺利查询到该信息并封包了:
bridge fdb show dev flannel.1|grep 26:12:3f:ba:e9:f5#26:12:3f:ba:e9:f5 dst <target node ip> self permanent
由于目标 ip 是对端 pod 所处宿主机的 ip,查找路由表,包应该从本机的 eth0 发出,这样 src ip 和 src mac 地址也就确定了。封好的包示意图如下: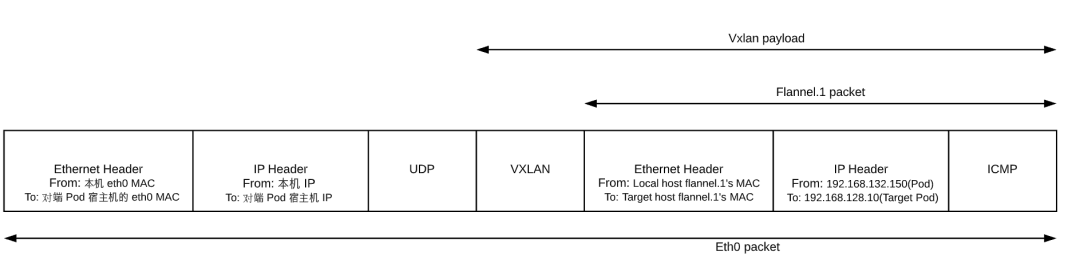 当对端宿主机 eth0 接收到该 vxlan 报文后,kernel 将识别出这是一个 vxlan 包,于是拆包后将 flannel.1 packet 转给自身的 vtep(flannel.1)。然后 flannel.1 再将这个数据包转到自己的的 cni0,继而由 cni0 传输到 Pod 的某个容器里。
当对端宿主机 eth0 接收到该 vxlan 报文后,kernel 将识别出这是一个 vxlan 包,于是拆包后将 flannel.1 packet 转给自身的 vtep(flannel.1)。然后 flannel.1 再将这个数据包转到自己的的 cni0,继而由 cni0 传输到 Pod 的某个容器里。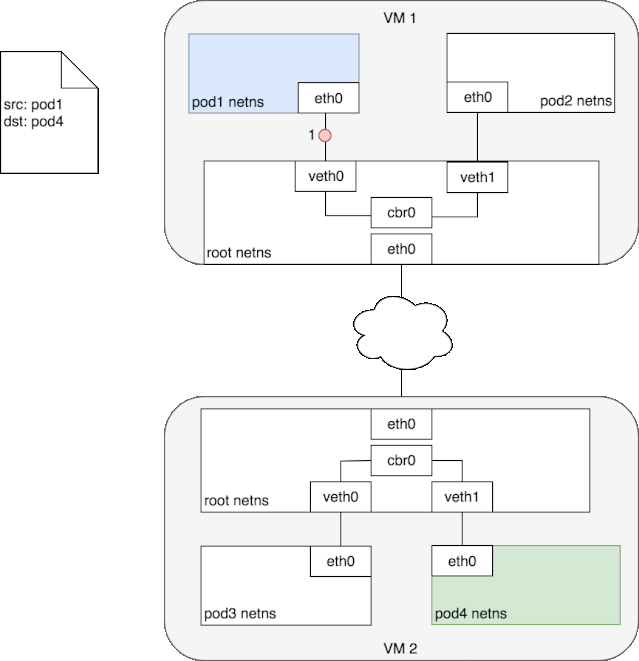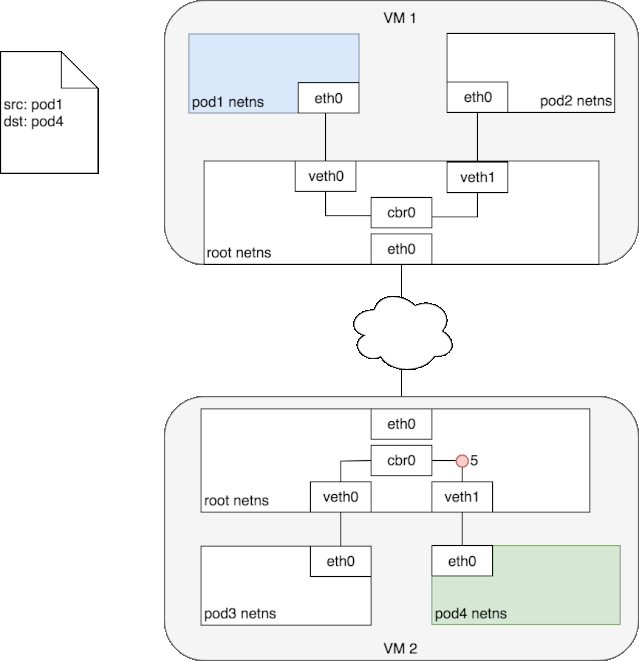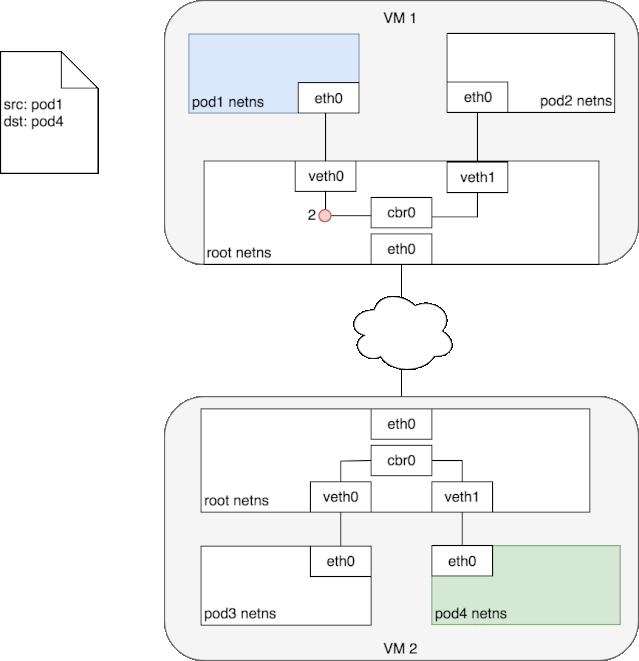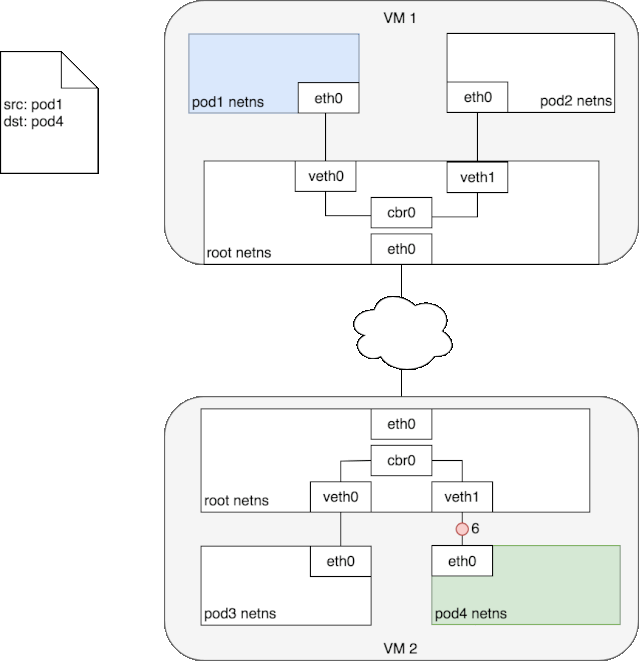
Service 网络
service network 比较特殊,每个新创建的 service 会被分配一个 service IP,它实际上只是一个存在于 iptables 中的路由规则,并没有对应的虚拟网卡。还记得我们在试玩环节创建的 kubia service 吗?我们只要在集群中的任意机器查看 iptables 就能发现端倪,这里需要声明的是我当时在创建 Kubernetes 集群时指定的 PodSubnet 为 192.168.128.0/18
,serviceSubnet 为 192.168.192.0/18
。
我们知道,linux 系统中有 route,用来和其他网络连接。如果没有它,linux 就无法和外部通信了。
iptables 是一系列的规则,用来对内核中的数据进行处理。没有它,linux 可以正常工作,有了它,linux 可以对网络中的数据的操作更加多样化,可见 iptables 是一个辅助角色,可以让 linux 的网络系统更强大。
iptables 其实不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过 iptables 这个代理,将用户的安全设定执行到对应的"安全框架"中,这个"安全框架"才是真正的防火墙,这个框架的名字叫 netfilter。
netfilter 才是防火墙真正的安全框架(framework),netfilter 位于内核空间。
iptables 其实是一个命令行工具,位于用户空间,我们用这个工具操作真正的框架。
Netfilter 是 Linux 操作系统核心层内部的一个数据包处理模块,它具有如下功能:
网络地址转换(Network Address Translate)
数据包内容修改
数据包过滤的防火墙功能
在 iptables 中 有两个概念:链和表,iptables 中定义有 5 条链,说白了就是 5 个钩子函数,它们是在数据包经过内核的过程中有五处关键地方,分别是 PREROUTING、INPUT、OUTPUT、FORWARD、POSTROUTING,因为每个钩子函数中可以定义多条规则,每当数据包到达一个钩子函数时,iptables 就会从钩子函数中第一条规则开始检查,看该数据包是否满足规则所定义的条件。如果满足,系统就会根据该条规则所定义的方法处理该数据包;否则 iptables 将继续检查下一条规则,如果该数据包不符合钩子函数中任一条规则,iptables 就会根据该函数预先定义的默认策略来处理数据包。iptables 中还有一个表的概念,每个表(tables)对应了一个特定的功能,有 filter 表(实现包过滤)、nat 表(实现网络地址转换)、mangle 表(实现包修改)、raw 表(实现数据跟踪),不同的表中包含了不同的钩子函数,不同表的同一钩子函数具有一定的优先级:raw-->mangle-->nat-->filter。一条链上可定义不同功能的规则,检查数据包时将根据上面的优先级顺序检查。
总结一下,数据包先经过 PREOUTING,由该链确定数据包的走向:
目的地址是本地,则发送到 INPUT,让 INPUT 决定是否接收下来送到用户空间,流程为 ①--->②;
若满足 PREROUTING 的 nat 表上的转发规则,则发送给 FORWARD,然后再经过 POSTROUTING 发送出去,流程为:①--->③--->④--->⑥
主机发送数据包时,流程则是 ⑤--->⑥
此处列出一些 iptables 常用的动作,在后面分析 iptables 时您将看到 Kubernetes 对各种动作的使用:
ACCEPT:允许数据包通过。
DROP:直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求泥牛入海了,过了超时时间才会有反应。
REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。
SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题。
MASQUERADE:是 SNAT 的一种特殊形式,适用于动态的、临时会变的 ip 上。
DNAT:目标地址转换。
REDIRECT:在本机做端口映射。
MARK:打标记。
我们先回顾一下 kubia service 的端口和 service ip, 可以看到它的 service endpoint 是 192.168.199.234:8080,因为采用了 NodePort 类型的 service,所以我们也可以通过所有 pod 所处宿主机的 32681 端口访问该服务。
kubectl get service -o wide#NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR#kubia NodePort 192.168.199.234 <none> 8080:32681/TCP 17h app=kubia
然后我们先看一下 iptables 的 nat 表内容,因为它控制了网络地址转换
iptables -t nat -nL#Chain PREROUTING (policy ACCEPT)#target prot opt source destination#KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */# 注入 KUBE-SERVICES 链##Chain OUTPUT (policy ACCEPT)#target prot opt source destination#KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */# 注入 KUBE-SERVICES 链
在 PREROUTING 链和 OUTPUT 链中,Kubernetes 注入了自己的链,该链匹配所有 ip 的包。然后,我们看下 KUBE-SERVICES 链都做了什么。
#Chain KUBE-SERVICES (2 references)#target prot opt source destination#KUBE-MARK-MASQ tcp -- !192.168.128.0/18 192.168.199.234 /* default/kubia: cluster IP */ tcp dpt:8080#KUBE-SVC-L5EAUEZ74VZL5GSC tcp -- 0.0.0.0/0 192.168.199.234 /* default/kubia: cluster IP */ tcp dpt:8080#KUBE-NODEPORTS all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
在 KUBE-SERVICES 链中可以看到,当我们的 destination 为 192.168.199.234 tcp 8080 时,会先判断是不是 Pod 子网,如果不是则会先进入 KUBE-MARK-MASQ 链,然后才会进入 KUBE-SVC-L5EAUEZ74VZL5GSC 链,最后一条规则是 KUBE-NODEPORTS 匹配目标地址是 local 的流量。
接下来我们分别看一看 KUBE-SERVICES 下层的三个链分别是干什么用的。
#Chain KUBE-MARK-MASQ (25 references)#target prot opt source destination#MARK all -- 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000
KUBE-MARK-MASQ 链的作用,只是打上标记 MARK or 0x4000
,该标记的作用一会儿再说。
#Chain KUBE-SVC-L5EAUEZ74VZL5GSC (2 references)#target prot opt source destination#KUBE-SEP-DHEI6HLVRKMGWFA5 all -- 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.16667000018#KUBE-SEP-U2WLSCWTWVRL43BI all -- 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.20000000019#KUBE-SEP-T3I6FPLS4WOL5Q3I all -- 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.25000000000#KUBE-SEP-SRYJEUDBHDCQM4KY all -- 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.33332999982#KUBE-SEP-VVYACXWHEDETJZUB all -- 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.50000000000#KUBE-SEP-5A4LPBRVHCEID4EO all -- 0.0.0.0/0 0.0.0.0/0
在 KUBE-SVC-L5EAUEZ74VZL5GSC 链中就对应了我们 kubia 服务的的 6 个 pod,可以看到他在这一层做了一个负载均衡,第一个 KUBE-SEP 分配了 1/6 的份额,第二个 KUBE-SEP 分配了剩余份额中的 1/5 ,以此类推,最终达到的效果就是每个 KUBE-SEP 分配 1/Pod count 的份额,我们挑选第一个 pod 对应的 KUBE-SEP-DHEI6HLVRKMGWFA5 看一下。
#Chain KUBE-SEP-DHEI6HLVRKMGWFA5 (1 references)#target prot opt source destination#KUBE-MARK-MASQ all -- 192.168.131.21 0.0.0.0/0#DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp to:192.168.131.21:8080
如果源 ip 和 pod ip 地址相同的话,则同样打上 mark,然后将目标地址(DNAT)改为该 Pod 的 ip + 服务端口,to:192.168.131.21:8080,到这里就完成了路由工作。
#Chain KUBE-NODEPORTS (1 references)#target prot opt source destination#KUBE-MARK-MASQ tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/kubia: */ tcp dpt:32681#KUBE-SVC-L5EAUEZ74VZL5GSC tcp -- 0.0.0.0/0 0.0.0.0/0 /* default/kubia: */ tcp dpt:32681
最后,在 KUBE-NODEPORTS 链中,如果目标端口和 kubia service 的 nodePort 匹配上的话,就会打上 mark 并进去之前的 service 链 KUBE-SVC-L5EAUEZ74VZL5GSC, 也就是说无论你访问集群内的任意一台机器的 32681 端口,流量均会均匀地转发到对应的 pod 中。
接下来我们看一下前面打的 MARK or 0x4000 都用来干什么了。
#Chain POSTROUTING (policy ACCEPT)#target prot opt source destination#KUBE-POSTROUTING all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */#RETURN all -- 192.168.128.0/18 192.168.128.0/18#MASQUERADE all -- 192.168.128.0/18 !224.0.0.0/4#RETURN all -- !192.168.128.0/18 192.168.132.0/24#MASQUERADE all -- !192.168.128.0/18 192.168.128.0/18# 这里是在 POSTROUTING 中注入的 KUBE-POSTROUTING 链, 并使用 MASQUERADE 进行与 Pod subnet 相关的 SNAT,实际上这是将 service pod 的源 ip SNAT 为 service ip。后面会详细介绍这个过程。##Chain KUBE-POSTROUTING (1 references)#target prot opt source destination#MASQUERADE all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */ mark match 0x4000/0x4000
KUBE-POSTROUTING 中匹配了所有打了 mark 0x4000 的报文,并通过 MASQUERADE 地址伪装,它是 SNAT 的一种特殊形式,可以自动化的进行源地址转换 SNAT,这个自动进行 SNAT 转换的过程实际是将报文的源地址转化为 Pod Subnet 的 ip 域。
回顾一下前面哪些情况下加了 mark:
KUBE-SERVICES: source ip 不在 pob subnet 域并且 destination 是 service ip + service port 时,实际的访问者在哪个集群主机上,就会使用该主机被分配的 pod subnet ip,即便是在 pod 中访问也会使用该 pod 所处的 host 被分配的 pod subnet ip(即 flannel 网卡 ip),而不是使用 pod 的 ip;
KUBE-SEP-DHEI6HLVRKMGWFA5: source ip 和 destination ip 都是目标服务 pod 的 ip 时,会使用该 pod 所处 host 的 pod subnet ip(即 flannel 网卡 ip),而不是 pod 内的 ip;
KUBE-NODEPORTS: 如果访问了 Service 使用的 NodePort,比如 Worker1 的 32681 端口,那么 SNAT 将改为 Worker1 的 pod subnet ip(即 flannel 网卡 ip);
另一个 mark 0x4000 的用途在 iptables 的 filter 表中,该表决定了数据报文的丢弃与放行的决策。
iptables -t filter -nL#Chain INPUT (policy ACCEPT)#target prot opt source destination#KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 ctstate NEW /* kubernetes service portals */#KUBE-EXTERNAL-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 ctstate NEW /* kubernetes externally-visible service portals */# 允许创建任意 ip 地址的连接,因为 service 网络是不存在与任何宿主机网络中的,但是我们需要允许以 service ip 建立连接##Chain OUTPUT (policy ACCEPT)#target prot opt source destination#KUBE-SERVICES all -- 0.0.0.0/0 0.0.0.0/0 ctstate NEW /* kubernetes service portals */# 同 INPUT,OUTPUT 链也放行以 service ip 相关的连接件建立#Chain FORWARD (policy ACCEPT)#ACCEPT all -- 192.168.128.0/18 0.0.0.0/0#ACCEPT all -- 0.0.0.0/0 192.168.128.0/18#KUBE-FORWARD all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes forwarding rules */# 在 FORWARD 链中注入了 KUBE-FORWARD,放行源 ip 或者目的 ip 为 pod subnet 的包##Chain KUBE-FORWARD (1 references)#target prot opt source destination#DROP all -- 0.0.0.0/0 0.0.0.0/0 ctstate INVALID#ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 /* kubernetes forwarding rules */ mark match 0x4000/0x4000#ACCEPT all -- 192.168.128.0/18 0.0.0.0/0 /* kubernetes forwarding conntrack pod source rule */ ctstate RELATED,ESTABLISHED#ACCEPT all -- 0.0.0.0/0 192.168.128.0/18 /* kubernetes forwarding conntrack pod destination rule */ ctstate RELATED,ESTABLISHED
ctstate description:
NEW 新建的连接的包
ESTABLISHED 已建立连接的后续包
RELATED 相关连接的包, 如 FTP 控制和数据
INVALID 没识别出来, 或者没有状态, 一般 DROP 此类的包
conntrack: 连接追踪表,记录了 SNAT 与 DNAT 的转换,可以通过
conntrack -L
查看
KUBE-FORWARD 中对打了 mark 0x4000 的包,源 ip 或者目的 ip 是 pod subnet 的包(状态:已建立连接或者存在相关连接)放行 Forward,对于其他非法状态的包则直接丢弃。
下图中所有黄色区域都为 Kubernetes 在 iptables 上做的改动。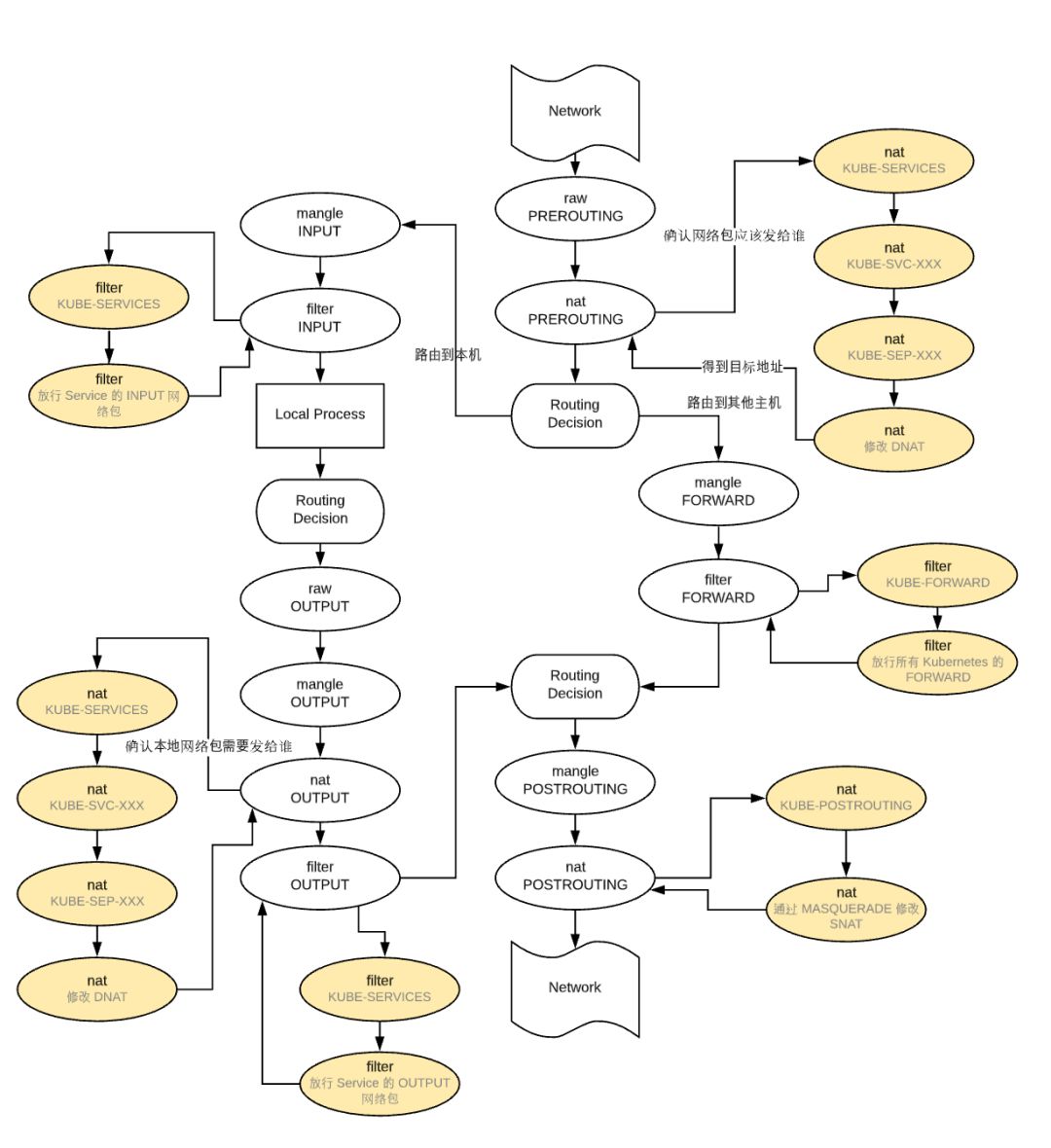 从上述 iptables 的分析中,我们可以知道,service network 实际上只是存在于 iptables 的路由规则,里面记录了一个指定 service ip 应该将流量路由到哪个 Pod ip 地址,以及收到的包应该如何进行 SNAT。下面两个动图描述了,从 Pod 发包给 Service,以及 service pod 回包的情况:
从上述 iptables 的分析中,我们可以知道,service network 实际上只是存在于 iptables 的路由规则,里面记录了一个指定 service ip 应该将流量路由到哪个 Pod ip 地址,以及收到的包应该如何进行 SNAT。下面两个动图描述了,从 Pod 发包给 Service,以及 service pod 回包的情况: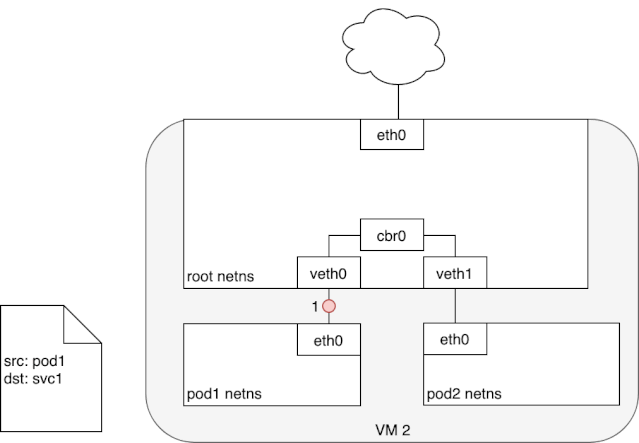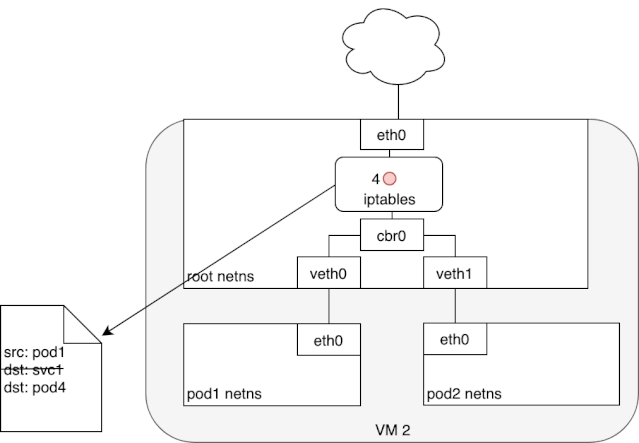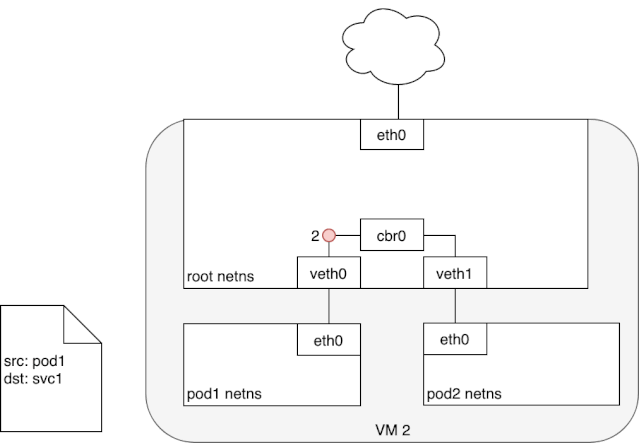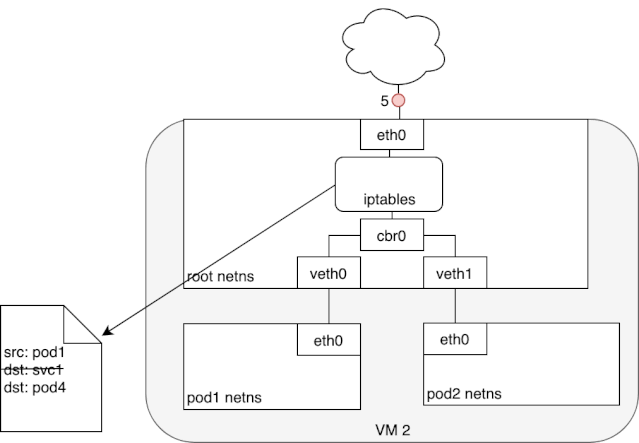 我们可以看到,来自 pod1 的报文以某种形式流到了宿主机上(我们后面会详细介绍这部分的实现原理),然后要从宿主机的 eth0 设备发出,这时候触发了 iptables 的规则匹配,根据 iptables 中的规则,最终将请求的目标地址改成了 Pod ip 并发送出去。在这个过程中 Linux kernel 的 conntrack 会记住此时选择的 pod,并且在下次这个源 pod 要发送给该 service 时,仍路由到相同的 service pod。至此,iptables 就完成了集群内的负载均衡,剩下的传输过程就由 flannel network 负责了。
我们可以看到,来自 pod1 的报文以某种形式流到了宿主机上(我们后面会详细介绍这部分的实现原理),然后要从宿主机的 eth0 设备发出,这时候触发了 iptables 的规则匹配,根据 iptables 中的规则,最终将请求的目标地址改成了 Pod ip 并发送出去。在这个过程中 Linux kernel 的 conntrack 会记住此时选择的 pod,并且在下次这个源 pod 要发送给该 service 时,仍路由到相同的 service pod。至此,iptables 就完成了集群内的负载均衡,剩下的传输过程就由 flannel network 负责了。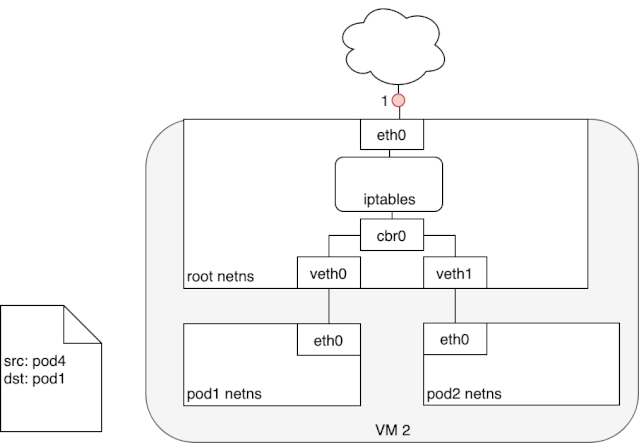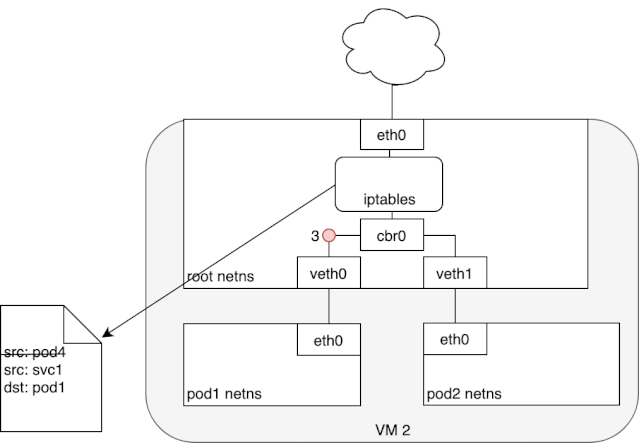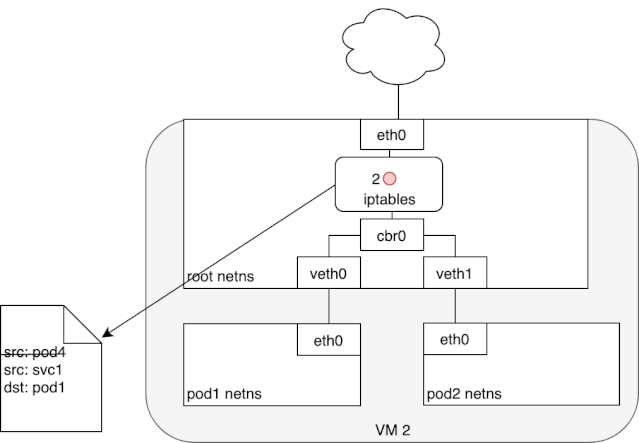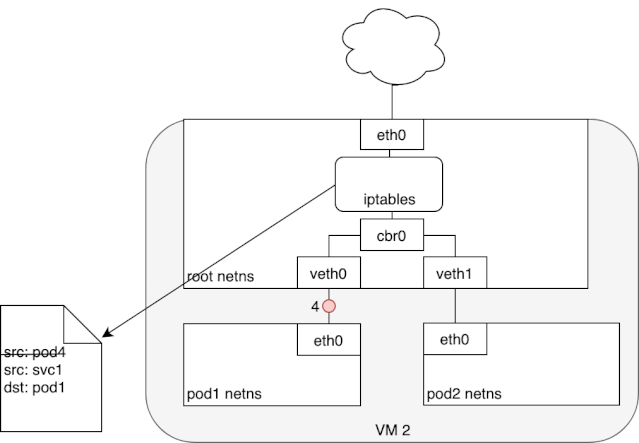 当 service 响应 pod 的请求后,数据包被 eth0 网卡接收到,并再次进入 iptables 的匹配过程,还记得前面 iptables 中的 POSTROUTING 吗?
当 service 响应 pod 的请求后,数据包被 eth0 网卡接收到,并再次进入 iptables 的匹配过程,还记得前面 iptables 中的 POSTROUTING 吗?
# 从 service pod 发来的回包,将 SNAT 恢复为 service ip 或者虚拟机的 ip#MASQUERADE all -- 192.168.128.0/18 !224.0.0.0/4# 将对外部网络的访问恢复 SNAT#MASQUERADE all -- !192.168.128.0/18 192.168.128.0/18
这里同样会使用到内核的 conntrack ,通过它可以将报文的源地址从 pod 的 ip 改为 service 的 ip,这下访问 service 的完整流程就走完了。如下是一个 conntrack 例子:
conntrack -L|grep 32681#tcp 6 9 CLOSE src=<exeternal-ip> dst=<local-eth0-ip> sport=62142 dport=32681 src=192.168.132.73 dst=192.168.128.0 sport=8080 dport=62142 mark=0 use=1#tcp 6 9 CLOSE src=<exeternal-ip> dst=<local-eth0-ip> sport=62790 dport=32681 src=192.168.132.72 dst=192.168.128.0 sport=8080 dport=62790 mark=0 use=1conntrack -L|grep 192.168.192#tcp 6 86377 ESTABLISHED src=192.168.128.2 dst=192.168.192.1 sport=38742 dport=443 src=<other-vm-ip> dst=<local-eth0-ip> sport=6443 dport=28222 [ASSURED] mark=0 use=1#tcp 6 86394 ESTABLISHED src=<exeternal-ip> dst=192.168.192.1 sport=50800 dport=443 src=<local-eth0-ip> dst=<local-eth0-ip> sport=6443 dport=50800 [ASSURED] mark=0 use=1
与外网通讯
到目前为止,我们已经清楚了 Kubernetes 集群内部的网络通讯原理,但是我们还没有讲清楚外部世界的网络怎么和我们的 Kubernetes service 交互。这包含两个部分,集群内的数据包怎么发送到外部网络,以及外部网络的数据包怎么流入 pod。
以我现在使用的内部云服务为例,我的 Kubernetes 集群实际上运行在一个虚拟机上,这些虚拟机都被指定了一个内部 ip,也就是 eth0 的 ip 地址,这个内部地址在我们的 Kubernetes 集群中能够直接访问。为了让我们的数据包能够触及外部世界的网络,云服务商会给我们的虚拟机挂载一个网关,这个网关有两个作用:其一是为我们的虚拟机提供一个路由表的 target,通过这个 target 虚拟机的数据包可以发送给网关继而由网关转发到外部网络。其二是做一个网络地址转换(NAT),给每一个数据包指定到一个公网 ip。由于这个网关的存在,我们的虚拟机才得以访问到公网。但是有一个小问题,因为我们的 pod 有自己的网络域,它是和虚拟机上的 eth0 网络域是独立的。而网关只能负责虚拟机 eth0 网络域的 ip,因为它根本不知道虚拟机上还要 pod subnet。那么 Kubernetes 是怎么解决这个问题的呢?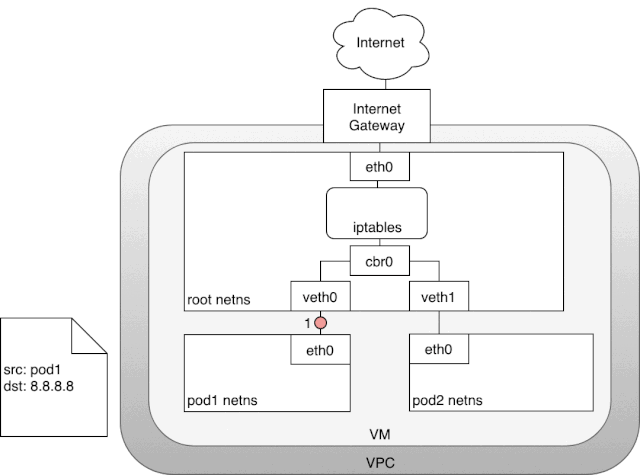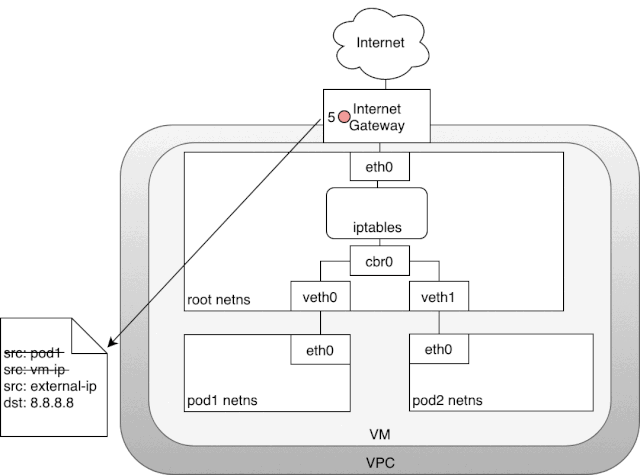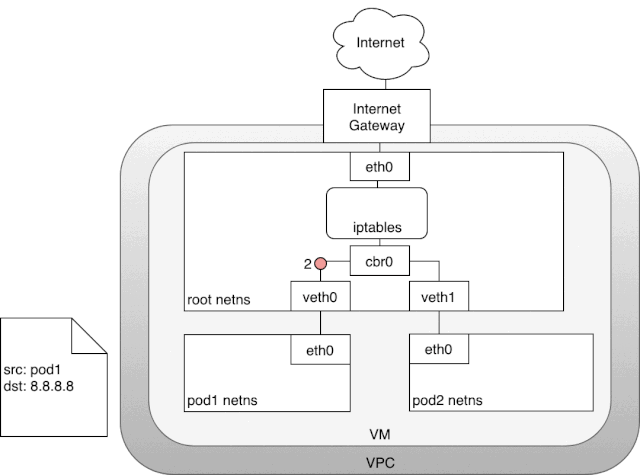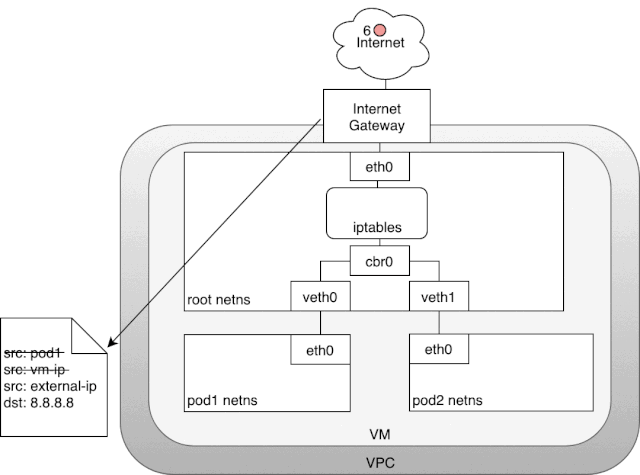 在上图中,数据包由 pod 的网络空间发出,经由 veth 对,连接到宿主机的网络空间 root。当数据包到达,root 网络空间后,会从网桥流向默认网络设备 eth0,因为数据包的目标 ip 没有命中宿主机的任意网络设备。在流到 eth0 之前,别忘了它还会经过 iptables 的处理。iptables 发现这个数据包由 pod 网络中发出,如果它保持这个源 ip 不变,网关 NAT 会无法识别这个网络域,数据包就发不出去,所以在这里 iptables 扮演着一个 NAT 的角色,它将源 ip 从 pod ip 改为 eth0 的 ip。这样这个数据包才能从虚拟机中经由网关传送到公网。在网关中,它还会再次进行一次 NAT,将虚拟机的内网地址,转换成公网地址。而从公网中返回的数据包也是经历了相同的路线,NAT 将目标地址外网 ip 转为虚拟机的内网 ip,然后虚拟机将内网 ip 转为 pod 的 ip。
在上图中,数据包由 pod 的网络空间发出,经由 veth 对,连接到宿主机的网络空间 root。当数据包到达,root 网络空间后,会从网桥流向默认网络设备 eth0,因为数据包的目标 ip 没有命中宿主机的任意网络设备。在流到 eth0 之前,别忘了它还会经过 iptables 的处理。iptables 发现这个数据包由 pod 网络中发出,如果它保持这个源 ip 不变,网关 NAT 会无法识别这个网络域,数据包就发不出去,所以在这里 iptables 扮演着一个 NAT 的角色,它将源 ip 从 pod ip 改为 eth0 的 ip。这样这个数据包才能从虚拟机中经由网关传送到公网。在网关中,它还会再次进行一次 NAT,将虚拟机的内网地址,转换成公网地址。而从公网中返回的数据包也是经历了相同的路线,NAT 将目标地址外网 ip 转为虚拟机的内网 ip,然后虚拟机将内网 ip 转为 pod 的 ip。
还记得我们在试玩环节解决的外网访问 service 的实验么,当时我们使用了云服务中的 LoadBalancer,实际上在 Kubernetes 中有两种方式可以解决外网访问我们 service 的问题,一个就是前面说的 LoadBalancer,另一个 Kubernetes 的 Ingress Controller。
LoadBalancer,又称 Layer 4 (传输层)入口。当我们创建好 service 后,可以通过云服务商的 API 来创建 LB,这个 LB 对应了一个外网的 ip 地址,外网的用户可以通过这个 LB public ip 访问到我们的服务。前面的试玩中,因为我使用的云服务没有提供 Kubernetes 对接,所以我 Service type 选为 NodePort,并将 L4 LB 绑定到 service 的 node port 上,当 Service type 选为 node port 后,会由 kube-proxy 进程在宿主机上占用一个端口 Service Port,保证该端口不会被其他进程使用,然后修改 iptables 将发送到 Service Port 的包转发到随机 pod 中,这是 kube-proxy 的默认工作模式,该模式的优点是代理过程全部经由内核态完成,而且在第四层就能完成转发工作。
让我们看一看 LB 是怎么工作起来的。首先,我们部署了自己的服务 kubia,然后创建了 LB,外网的数据包到达 LB 后会分发到任意一个 Kubernetes 集群节点,经由该虚拟机节点的 iptables,它会再次进行一个负载均衡,分发到任意一个 service 的 pod 中,当该 pod 返回数据包时,必然是用的 pod 的 ip 地址,这怎么行呢,外网的服务访问者肯定希望返回的数据包 ip 是 LB 的 ip,这样才能对的上啊。所以,当数据包从 pod 中返回时,iptables 和 conntrack 齐心协力地重写了 ip 地址,虚拟机将 ip 改为自己的 eth0 ip 并返回给 LB,LB 再将虚拟机的 ip 改为自己的外网 ip。下面这张图就展示了,这里所说的流程。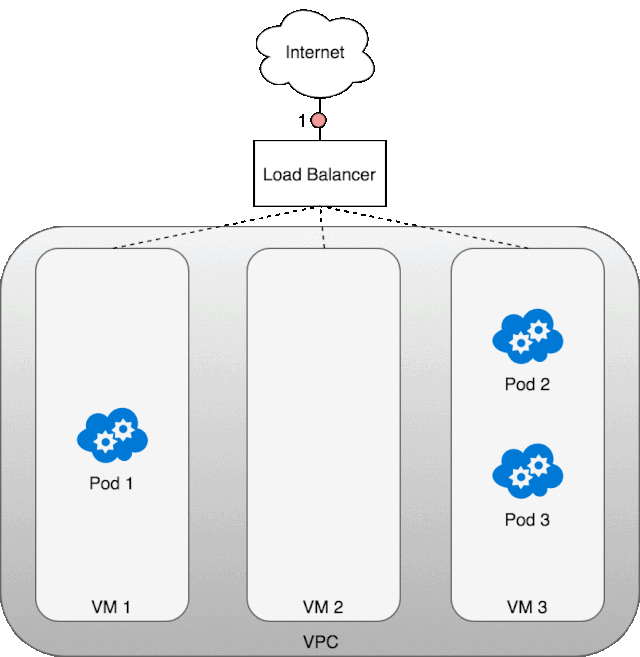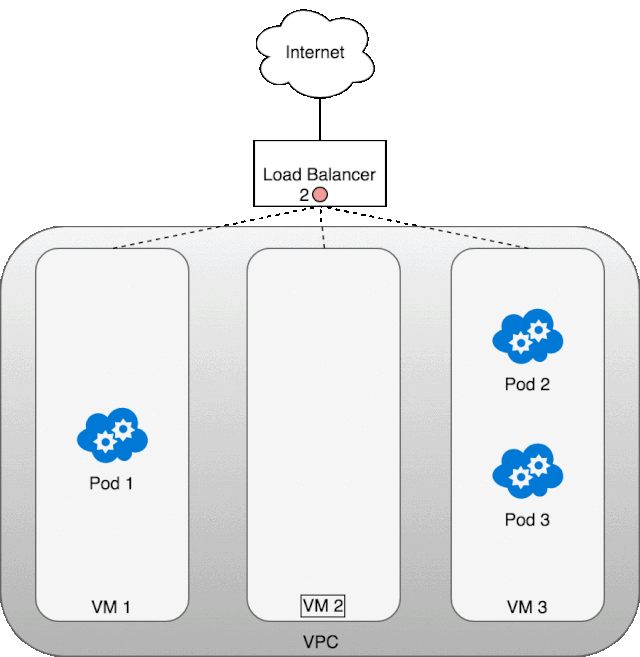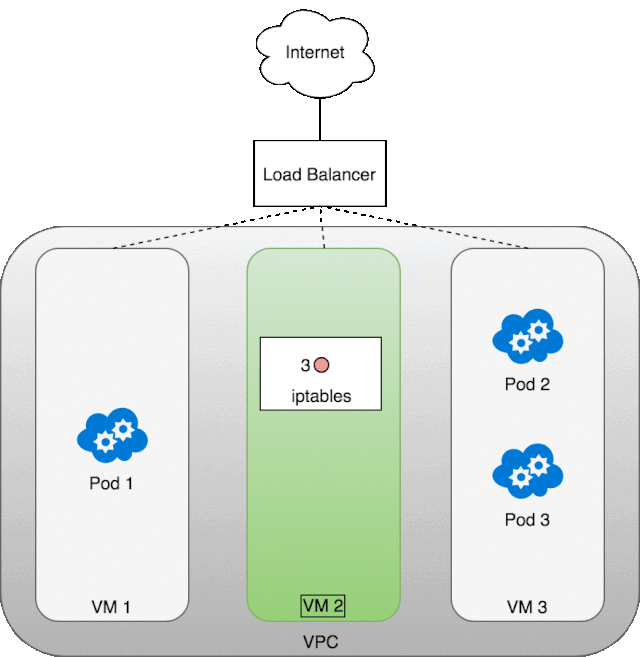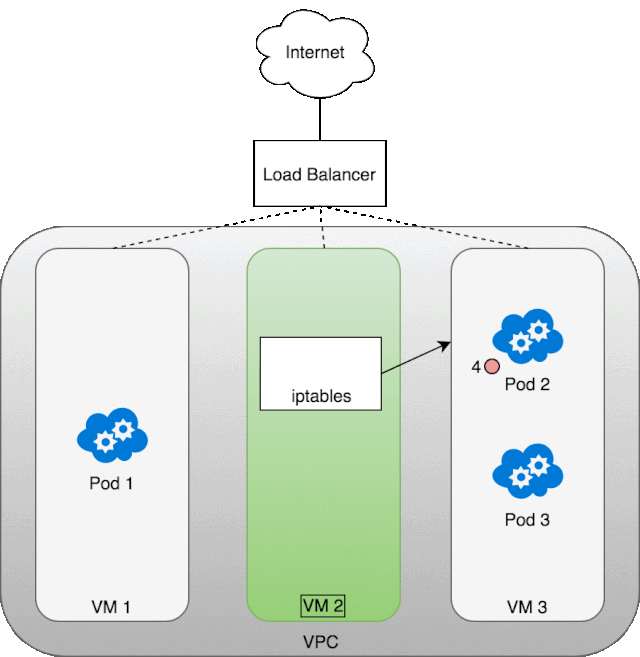 除了,LB 之外,另一种方案是 Layer 7(应用层)入口。一般来说 Layer 7 入口面向的是 HTTP/HTTPS 协议栈。我们需要将 Service 类型置为 NodePort,这样 Kubernetes 会选择一个端口作为服务的名义端口,然后每个节点上的 kube-proxy 都会占用该名义端口,防止其他进程也使用相同端口(会发生传输冲突),然后每个节点都会修改自己的 iptables,将流入该名义端口的包根据负载均衡规则转发到对应的 pod 中。
除了,LB 之外,另一种方案是 Layer 7(应用层)入口。一般来说 Layer 7 入口面向的是 HTTP/HTTPS 协议栈。我们需要将 Service 类型置为 NodePort,这样 Kubernetes 会选择一个端口作为服务的名义端口,然后每个节点上的 kube-proxy 都会占用该名义端口,防止其他进程也使用相同端口(会发生传输冲突),然后每个节点都会修改自己的 iptables,将流入该名义端口的包根据负载均衡规则转发到对应的 pod 中。
在 Kubernetes 中,我们称这种 Layer 7 的 HTTP LoadBalance 为 Ingress,它同样需要云服务商提供 L7 的 http LoadBalance,就像 Layer 4 LoadBalance 一样,它只能将请求转发到虚拟机上,然后虚拟机上的 iptables 再转发到对应的 pod 中。
下图展示的就是 Layer 7 应用级 LB 的工作方式,当我们通过 Kubernetes 的 api server 建立 Ingress 对象后,云服务提供商会感知到该事件,并建立自己的应用级 LB(ALB),该 ALB 会指向多个节点来保证可用性,同时会根据 Ingress 中定义的规则将请求转发给对应的节点 NodePort(NP)。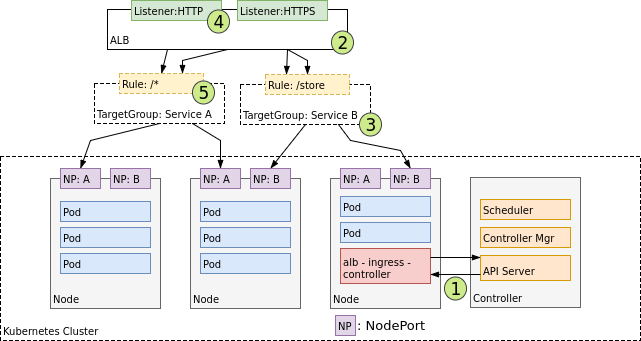 下图中描述了数据包的流转,公网中的数据包发给 Ingress LB 后,它将请求转发到虚拟机上的 NodePort,然后虚拟机根据 iptables 规则将请求转发到正确的 pod 中。就像前面所说的一样,这里也会使用 conntrack 来将返回包的源 ip 地址从 pod ip 改为 lb 的 ip。
下图中描述了数据包的流转,公网中的数据包发给 Ingress LB 后,它将请求转发到虚拟机上的 NodePort,然后虚拟机根据 iptables 规则将请求转发到正确的 pod 中。就像前面所说的一样,这里也会使用 conntrack 来将返回包的源 ip 地址从 pod ip 改为 lb 的 ip。
LB vs Ingress
我们已经知道了 Kubernetes 中当 service 的类型为 LoadBalance 时,会使用 L4 LB,当使用 Ingress 暴露服务时,会使用 L7 LB,那么他们有什么不同呢?
所谓四层负载均衡,也就是主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。以常见的 TCP 为例,负载均衡设备在接收到第一个来自客户端的 SYN 请求时,即通过上述方式选择一个最佳的服务器,并对报文中的目标 IP 地址进行修改(改为后端服务器 IP),直接转发给该服务器。TCP 的连接建立,即三次握手是客户端和服务器直接建立的,负载均衡设备只是起到一个类似路由器的转发动作。在某些部署情况下,为保证服务器回包可以正确返回给负载均衡设备,在转发报文的同时可能还会对报文原来的源地址进行修改,当然大部分情况下可能不会这么做,那样的话服务器的回包可能就不会经过 LB 设备。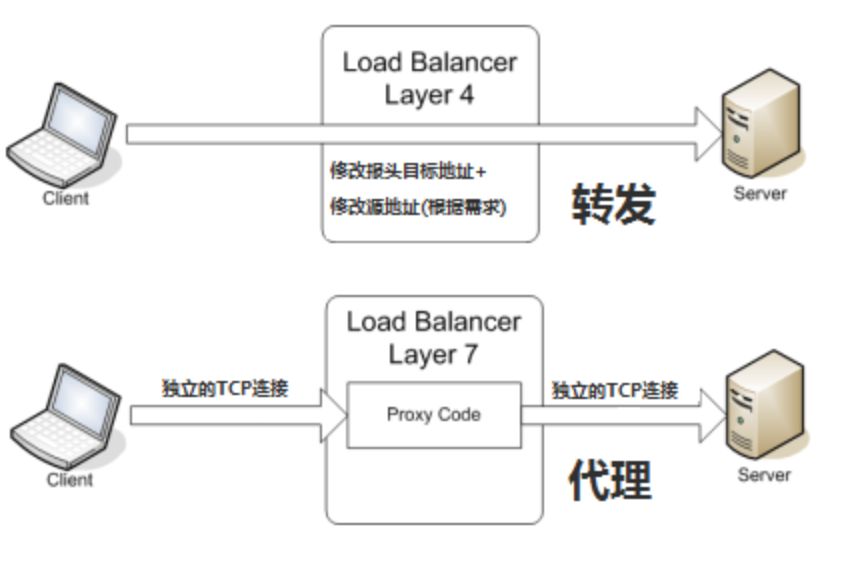 所谓七层负载均衡,也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。以常见的 TCP 为例,负载均衡设备如果要根据真正的应用层内容再选择服务器,只能先和客户端建立连接(TCP 三次握手)后,才可能接收到客户端发送的真正应用层内容的报文,然后再根据该报文中的特定字段,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。负载均衡设备在这种情况下,更类似于一个代理服务器。负载均衡和前端的客户端以及后端的服务器会分别建立 TCP 连接。所以从这个技术原理上来看,七层负载均衡明显地对负载均衡设备的要求更高,处理七层的能力也必然会低于四层模式的部署方式。
所谓七层负载均衡,也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。以常见的 TCP 为例,负载均衡设备如果要根据真正的应用层内容再选择服务器,只能先和客户端建立连接(TCP 三次握手)后,才可能接收到客户端发送的真正应用层内容的报文,然后再根据该报文中的特定字段,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。负载均衡设备在这种情况下,更类似于一个代理服务器。负载均衡和前端的客户端以及后端的服务器会分别建立 TCP 连接。所以从这个技术原理上来看,七层负载均衡明显地对负载均衡设备的要求更高,处理七层的能力也必然会低于四层模式的部署方式。
L7 LB 的优点是它更加灵活,举个例子:因为它运行在 HTTP 协议栈中,所以它能知道 URL 信息,所以可以通过 URL 来作为转发规则,同时我们还可以通过 HTTP 的 X-Forwarded-For
头来获取到 HTTP 请求的 client ip。另外一个优点是更加安全,网络中最常见的 SYN Flood 攻击,即黑客控制众多源客户端,使用虚假 IP 地址对同一目标发送 SYN 攻击,通常这种攻击会大量发送 SYN 报文,耗尽服务器上的相关资源,以达到 Denial of Service(DoS) 的目的。从技术原理上也可以看出,四层模式下这些 SYN 攻击都会被转发到后端的服务器上;而七层模式下这些 SYN 攻击自然在负载均衡设备上就截止,不会影响后台服务器的正常运营。
现在的 7 层负载均衡,主要还是着重于应用广泛的 HTTP 协议,所以其应用范围主要是众多的网站或者内部信息平台等基于 B/S 开发的系统。4 层负载均衡则对应其他 TCP 应用,例如基于 C/S 开发的系统。
高可用
在 Kubernetes 上运行应用的一个理由就是,保证运行不被中断,或者说尽量少地入工介入基础设施导致的宕机。为了能够不中断地运行服务,不仅应用要一直运行,Kubernetes 控制平面的组件也要不间断运行。接下来我们了解一下达到高可用性需要做到什么。
运行多实例来减少宕机可能性
需要你的应用可以水平扩展,不过即使不可以,仍然可以使用 Deployment, 将复制集数量设为 1。
对不能水平扩展的应用使用领导选举机制
为了避免宕机,需要在运行一个活跃的应用的同时再运行一个附加的非活跃复制集
让 Kubernetes 控制面板高可用,就像我在试玩环节使用的模式
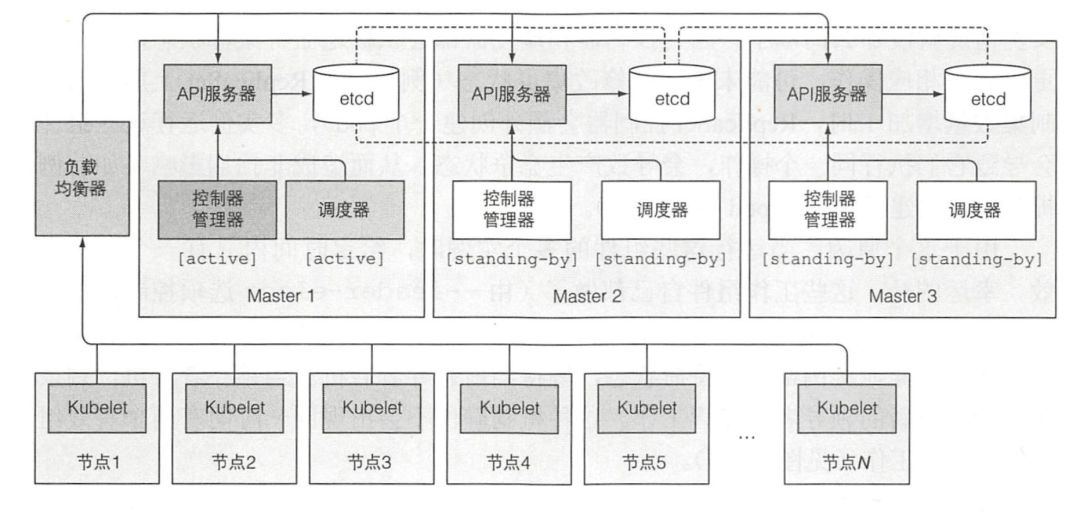
运行 etcd 集群
运行多实例 API 服务器
确保控制器和调度器的高可用性,领导人选举
参考内容
[1] https://github.com/kubernetes/kubernetes
[2] https://kubernetes.io
[3] https://github.com/kubernetes/examples
[4] 《Kubernetes in Action》
[5] https://tonybai.com/2017/01/17/understanding-flannel-network-for-kubernetes/
[6] https://jimmysong.io/posts/what-is-a-pause-container/
[7] https://vernlium.github.io/2017/09/21/iptables概念介绍及相关操作-k8s-8/
[8] https://www.linuxidc.com/Linux/2016-09/134832.htm
[9] https://tonybai.com/2017/01/11/understanding-linux-network-namespace-for-docker-network/
[10] https://sookocheff.com/post/kubernetes/understanding-kubernetes-networking-model/
[11] https://medium.com/@anilkreddyr/kubernetes-with-flannel-understanding-the-networking-part-2-78b53e5364c7
[12] https://jaminzhang.github.io/lb/L4-L7-Load-Balancer-Difference/
引用链接
官方文档: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/#
[2]本地 Dashboard 页面: http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/.
[3]官方文档: https://kubernetes.io/
