




甲骨文公司于2019年12月5日宣布Oracle Advanced Analytics 和Spatial and Graph Database Option可以免费用于开发和部署目的。甲骨文公司的这一决定旨在帮助那些希望利用Oracle数据库的机器学习、空间和图形功能的客户,使得他们不再需要针对这些特性购买额外的许可证。这个变化将使甲骨文公司更好的履行Oracle的使命:“帮助人们以新的方式看待数据、发掘数据价值、释放无限可能“。
(请参考:https://blogs.oracle.com/database/machine-learning%2c-spatial-and-graph-no-license-required-v2)
Oracle Advanced Analytics一直都是Oracle数据库内置的机器学习解决方案之一。在该数据库选件不再额外收费后,用户可以用更低的成本建设他们的机器学习和数据分析、预测系统。本文将介绍OAA的基础概念并针对其中的部分功能进行详细描述。

甲骨文目前提供多种机器学习解决方案,例如:
“OML4*”系列,Oracle数据库支持SQL\R\Python\Spark等语言通过API访问数据库中的数据;
OML Notebooks, 基于Apache Zeppelin产品的SQL Notebooks,您可以在Oracle 公有云中的ADW服务中使用该功能;
Oracle Advanced Analytics (OAA—原数据库选件),可以在本地或公有云中部署的Oracle数据库中运行,提供高级数据分析功能。
Oracle Advanced Analytics集成了Oracle Data Miner和Oracle R Enterprise两个功能组件。Oracle R Enterprise用来整合R语言和Oracle数据库,用户可以在使用数据库的过程中编写 R 脚本和运行 R 包,随后Oracle Advanced Analytics 的 R-SQL将把 R 函数和算法映射到数据库内的原生 SQL 对等对象。
Oracle Data Miner是 Oracle SQL Developer 的一个扩展组件,能够为数据分析人员提供面向数据挖掘、模型构建和分析方法开发的工作流环境。另外,基于Oracle云上云下统一的产品策略,Data Miner平台中构建的工作流、机器学习模型等可以方便的在云上、云下环境间迁移,无需额外的配置调整。
本文将以实验的形式展示 Oracle Data Miner的工作流程,介绍如何在Oracle公有云数据库服务中针对JSON数据进行便捷的处理、转化、模型训练和应用,并在云上和云下环境间移动算法(而非数据)。
如果读者在阅读后希望重复文中描述的实验,可以参考Oracle University上发布的教程(课程名:Mining JSON Data Using Oracle Data Miner)。
以下即开始详细介绍:
1.下载Oracle SQL Developer
Oracle SQL Developer是Oracle发布的开源免费平台,也是Oracle Data Miner的主要GUI工作平台。登陆Oracle官方网站,下载最新版本的SQL Developer软件。
参考连接:https://www.oracle.com/tools/downloads/sqldev-v192-downloads.html
2.申请Oracle公有云DBaas服务或创建本地数据库。
Oracle Advanced Analytics可以在云上或云下环境中部署的Oracle数据库中使用,本例中选择公有云服务作为部署平台。登陆甲骨文云平台,选择“数据库->裸金属\VM和Exadata”, 按照指引创建数据库服务。
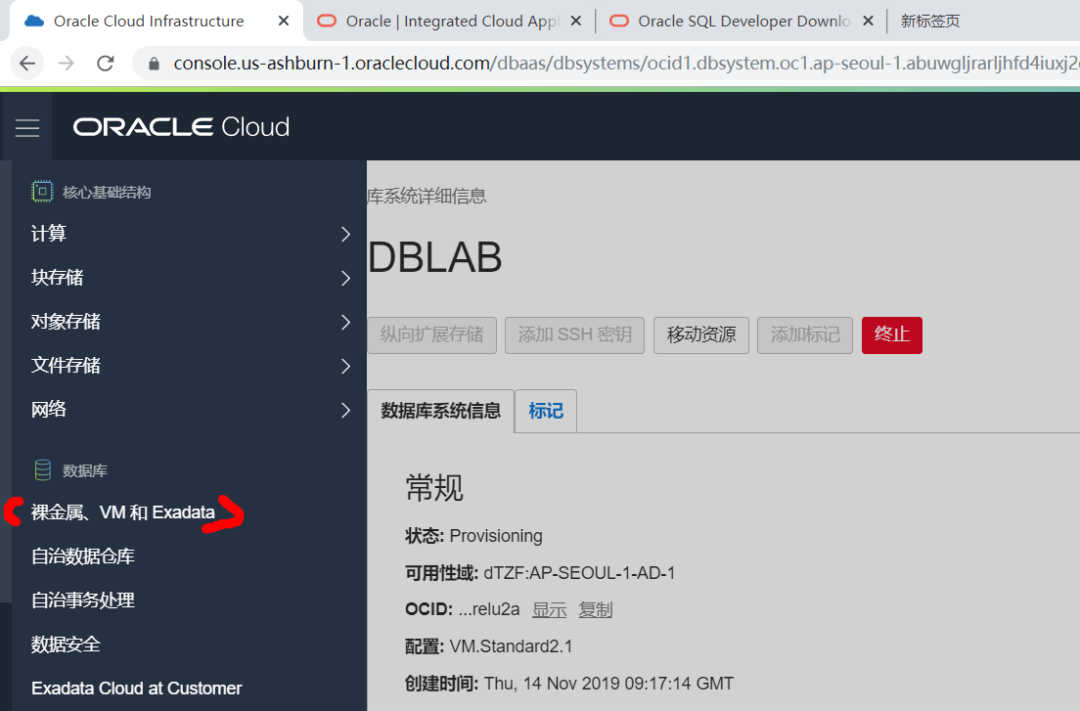
注意:创建数据库云服务时选择版本类型为Enterprise Edition High Performance或Extreme Editions,当前这两个服务中会包含OAA组件;请关注Oracle官方平台获取OAA组件在其他Oracle公有云服务上的开通信息。
3.实验数据准备
本文所描述的实验依赖预先创建的Data Miner示例数据,而创建DataMiner示例数据时需要依赖Oracle Sample Schema中的SALES HISTORY数据(SH用户),因此在实验数据准备工作的第一步,需要先创建SALES HISTORY示例用户。
从GITHUB下载Oracle Sample Schema压缩包,并参考说明文档运行脚本安装SALES HISTORY示例数据。
参考连接:https://github.com/oracle/db-sample-schemas/releases/tag/v19c
接下来使用SQL Developer通过SSH tunnel方式连接Oracle公有云数据库,建立SSH tunnel需要准备:Oracle数据库云服务的Public IP、Private IP、云服务对应的SSH密钥等, SSH tunnel创建完成后在SQL Developer中使用拥有DBA权限的用户连接云数据库。
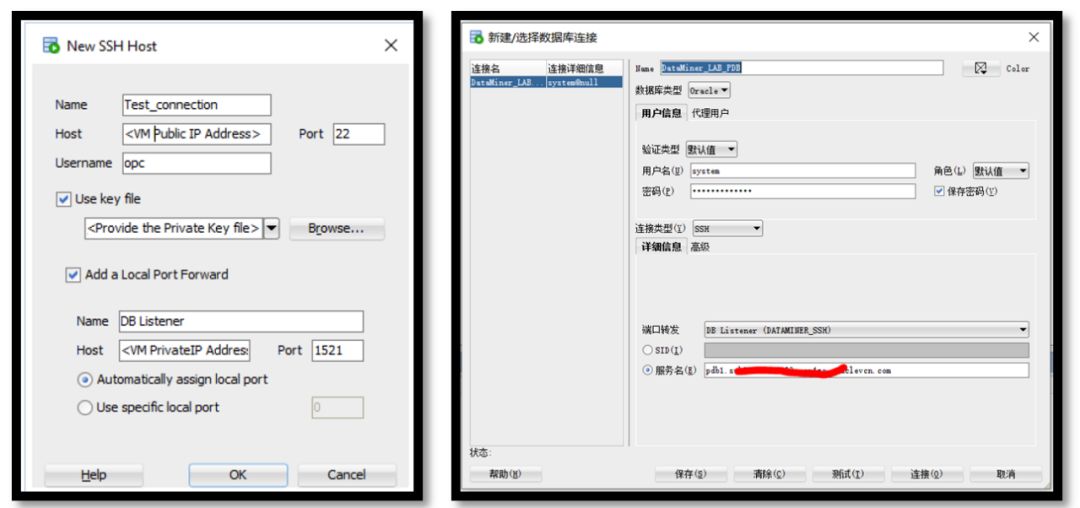
接下来创建DataMiner数据库用户,该用户将被用来保存DataMiner工作流数据、存储DataMiner示例数据等。创建完毕后使用该用户在SQL Developer中建立新的数据库连接。
Create USER "DMUSER" IDENTIFIED BY XXXXX;
ALTER USER "DMUSER" DEFAULT TABLESPACE "USERS"
TEMPORARY TABLESPACE "TEMP"
ACCOUNT UNLOCK ;
GRANT CONNECT,RESOURCE TO DMUSER;
至此基础的实验环境准备完毕。
4.打开DATA MINER并创建工作流
在SQL Developer中选择“工具->Data Miner->设为可见“,在界面中打开Data Miner TAB。
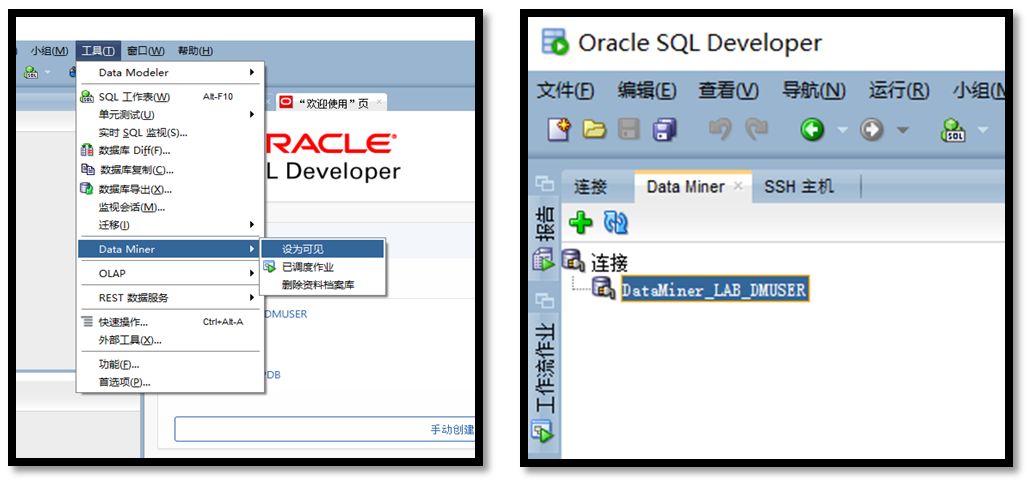
打开DataMiner TAB新建连接,选择刚刚建立的Oracle云数据库连接,首次连接时按照系统提示创建DataMiner资料库,注意在界面上选择“创建示例数据”。
资料库创建完毕后,在Data Miner中创建项目->创建工作流。
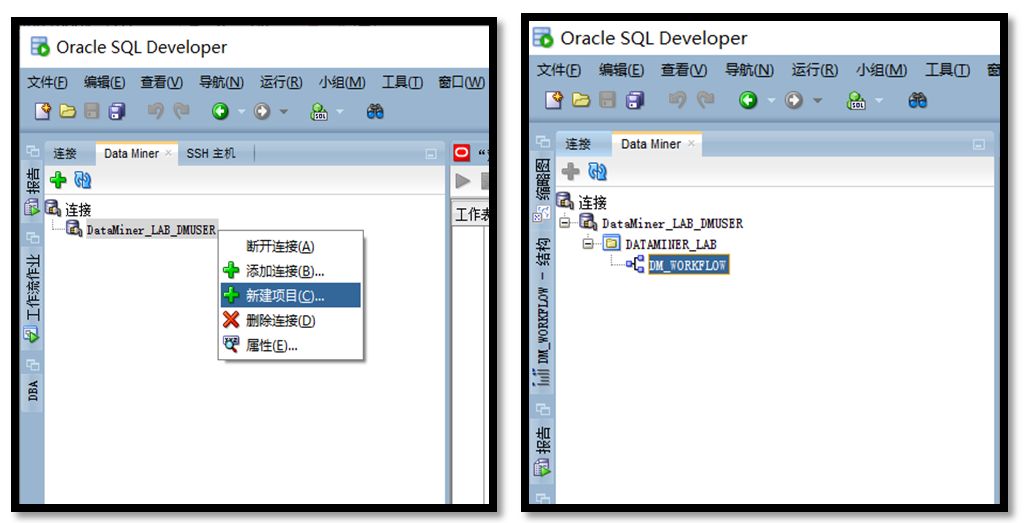
依次在工作流界面添加组件,包括:【数据源】、【JSON 查询】、【创建表和视图】、【类构建】等。
在添加【数据源】组件时选择DataMiner用户下创建的示例数据表ODMR_SALES_JSON_DATA。该表存储了销售示例数据,取出其中一行展示如下:
{"CUST_ID":100600,"EDUCATION":"11th","OCCUPATION":"Transp.","HOUSEHOLD_SIZE":"3","YRS_RESIDENCE":"3","AFFINITY_CARD":"0","BULK_PACK_DISKETTES":"1","FLAT_PANEL_MONITOR":"1","HOME_THEATER_PACKAGE":"0","BOOKKEEPING_APPLICATION":"0","PRINTER_SUPPLIES":"1","Y_BOX_GAMES":"1","OS_DOC_SET_KANJI":"0","COMMENTS":"How much would it cost to upgrade my computer to the latest model you advertised this week?","SALES":[{"PROD_ID":147,"QUANTITY_SOLD":1,"AMOUNT_SOLD":7.99,"CHANNEL_ID":9,"PROMO_ID":33},{"PROD_ID":30,"QUANTITY_SOLD":1,"AMOUNT_SOLD":9.99,"CHANNEL_ID":9,"PROMO_ID":33},{"PROD_ID":46,"QUANTITY_SOLD":1,"AMOUNT_SOLD":22.99,"CHANNEL_ID":9,"PROMO_ID":33}]}
接下来添加【JSON 查询】组件,对JSON数据做出格式转化、并初步处理,例如求出每笔订单的产品数量和价格总和。
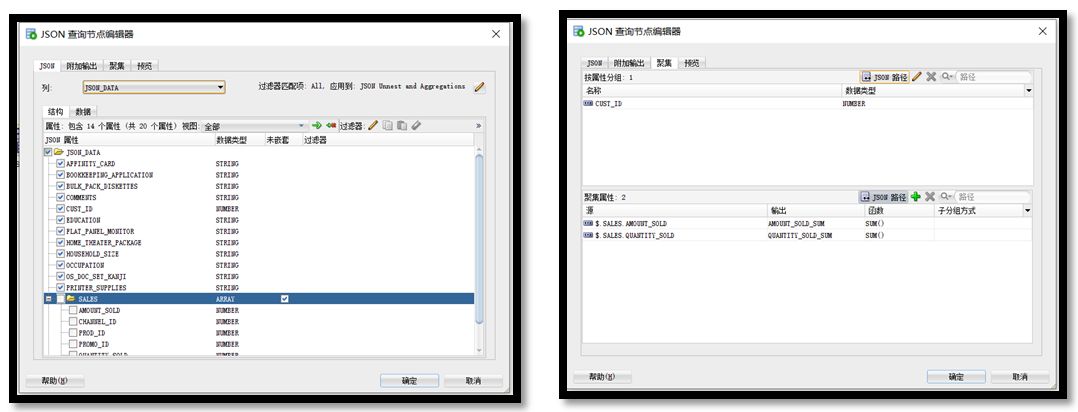
接着添加【创建表或视图】组件,将初步处理后的JSON数据存入数据库中的中间表内,为后续的数据分析做准备。添加【类构建】组件,使用处理后的数据进行模型训练。选定AFFINITY_CARD作为目标值,选择CUST_ID作为案例ID。
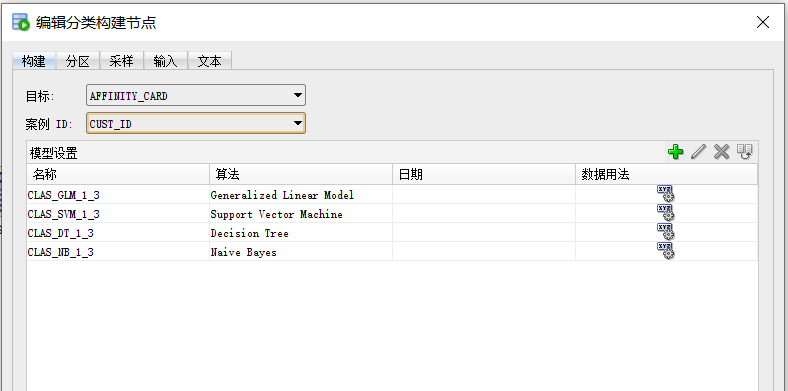
如图所示,Oracle Data Miner在【分类】组件中提供了通用线性模型、支持向量机、决策树、单纯贝叶斯等四种算法,用户可以选择删除其中不想采用的算法。
至此工作流创建完毕,可以开始模型训练,点击【类构件】组件,运行工作流。
Oracle数据库中的机器学习平台内置了数十种算法,适用于分类、异常检测、聚类等多种场景。详情请参考官方文档Data Miner User's Guide。
https://docs.oracle.com/cd/E55747_01/doc.41/e58114/model_nodes.htm#DMRUG533
5.分析模型训练结果
工作流运行完毕后,即可查看DataMiner使用销售数据训练得出的数据模型。在【类构件】组件上右键点击【比较测试结果】,可以检查模型有效性。
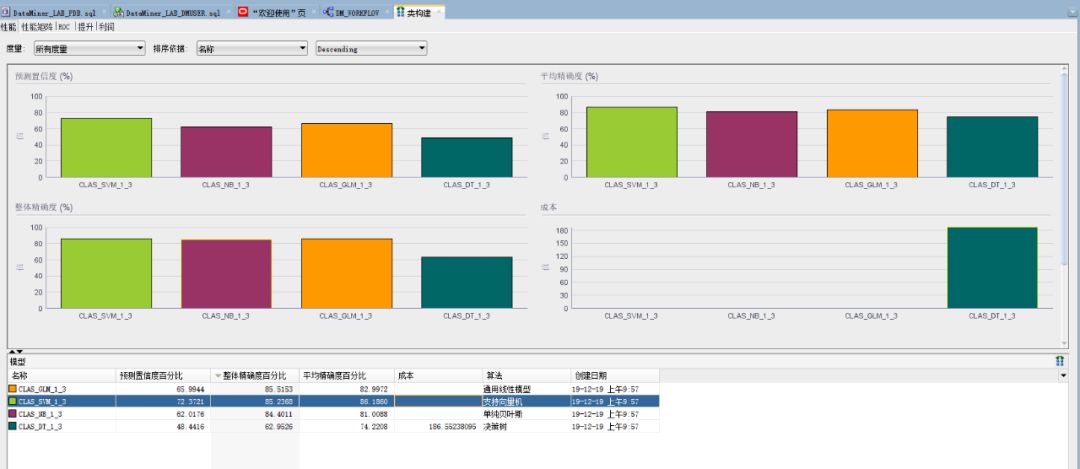
如图所示DataMiner提供了置信度、精确度等多个模型评估维度。DataMiner还能详细检查生成的各个模型,在【类构件】组件上右键点击【查看模型】,再从四个生成的分类模型中选择自己关心的模型进行详细检查。以下为【支持向量机】和【决策树】类模型的详细检查界面截图。
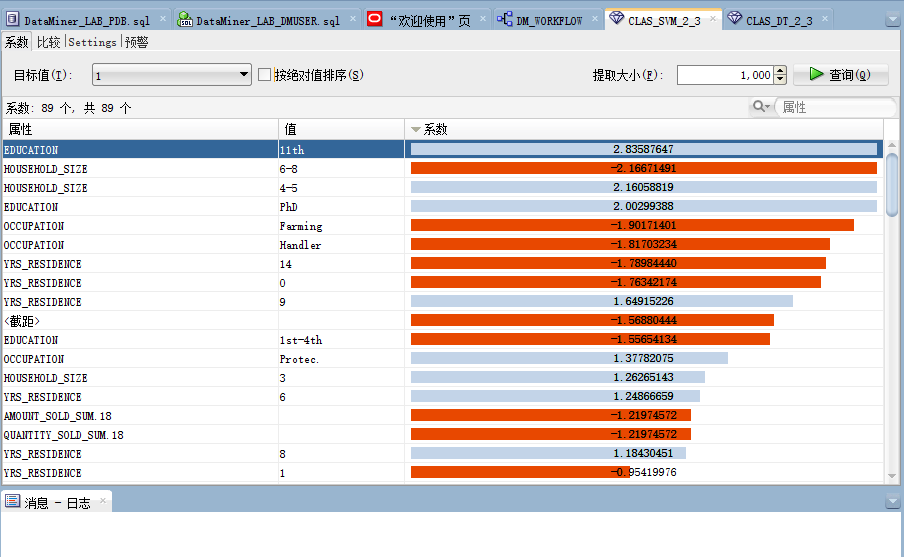
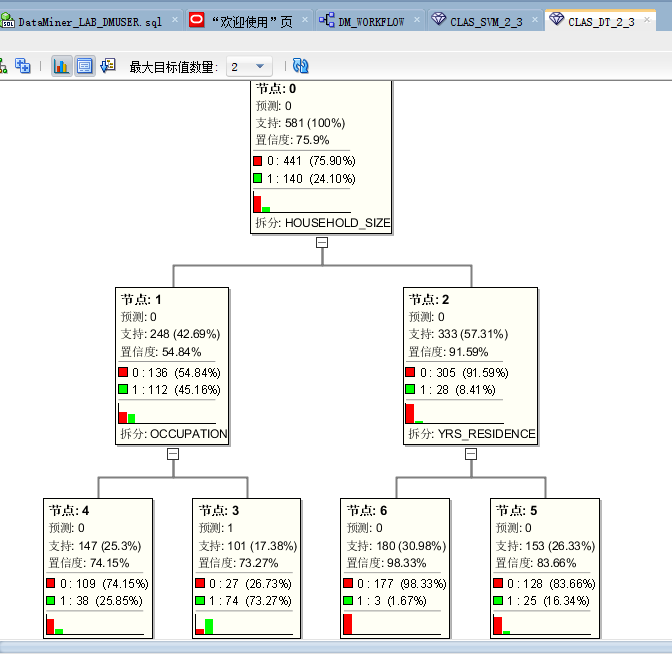
如上所示,可以直观的得出一些信息,例如顾客的教育程度(Education)、住房面积(HOUSEHOLD_SIZE)可能是影响客户是否喜欢公司产品/服务的重要因素。
6.应用模型分析数据
现在,既然我们已经有了模型,接下来即可将模型应用到数据的预测中。在工作流中增加需要被预测的数据(添加【数据源】组件以及【JSON查询】等格式转化组件)和模型应用动作(模型操作->【应用】组件)设置完毕后整体工作流图如下:
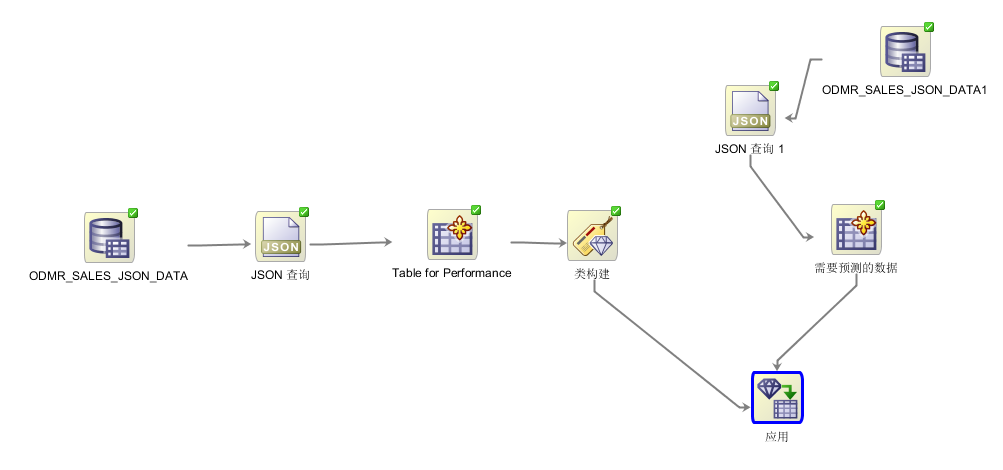
运行结束后,即可通过右键点击【应用】组件,查看预测结果。
7.导出工作流
以上我们整体的实验都是在Oracle公有云数据库服务上完成的,模型训练完成后,可以把我们训练模型的工作流导出为XML模式,导入到本地环境,使用本地数据进行模型训练。
8.总结
本文简略介绍了Oracle Advanced Analytics产品概念,并较为详细的演示了使用”Oracle Advanced Analytics -> Data Miner”功能对JSON数据进行价值挖掘的工作流程。Oracle OAA产品具备易于使用、功能强大、方便部署等特点,引入Advanced Analytics产品,能够极大的降低您企业数据分析系统的构建和运行成本,提高数据价值挖掘工作的效率。如您对相关产品感兴趣,可以随时联系Oracle相关工作人员进行咨询或访问Oracle官方网站查看相关资料。
参考资料
关于文中实验过程和产品的详细资料,读者可以参考OTN网站上关于DataMiner的章节。
https://www.oracle.com/technetwork/cn/database/options/advanced-analytics/odm/dataminerworkflow-168677-zhs.html

手把手系列文章:
扫描下方QR Code即刻预约ADW演示

编辑:殷海英

