




线上某服务前端负载均衡为Nginx,后端为Java服务,某天突然大量报服务不可用,具体错误如下:

查看后端服务压力,CPU快200了,赶紧扩容,再限流。
扩容后发现Nginx还是报错,报错仍然如上,这时重启NG就好了,但过段时间问题依旧。
查了下后端的日志,没有报错日志,响应也不慢,不过CPU还是有点高;然后分析下Nginx配置,发现Upstream配置比较可疑:
upstream xxx{server 192.1686.1.114:6280 max_fails=1 fail_timeout=300s;server 192.168.160.115:6280 max_fails=1 fail_timeout=300s;server 192.168.160.116:6280 max_fails=1 fail_timeout=300s;}
为了保证后端upstream的高可用,Nginx有错误检查机制,当后端返回错误时,可以设置达到多少次错误,则认为这个节点有问题,主动将其下线,等过多少时间后再进行尝试。
max_fails:错误多少次将其标识为下线
fail_timeout:检查周期,即多少时间内错误max_fails次,则将节点标记下线,等下一个fail_timemout周期内再检查服务是否可用。
上面的配置的意思是如果300s内只有后端返回错误超过1次,就将其标记为下线,即这300秒内不会将请求转发到这个节点,过300s后再重新发请求试试,如果再有1次以上报错,依然将其标为下线。
而这个系统的流量分布特点是准点访问量比较大:
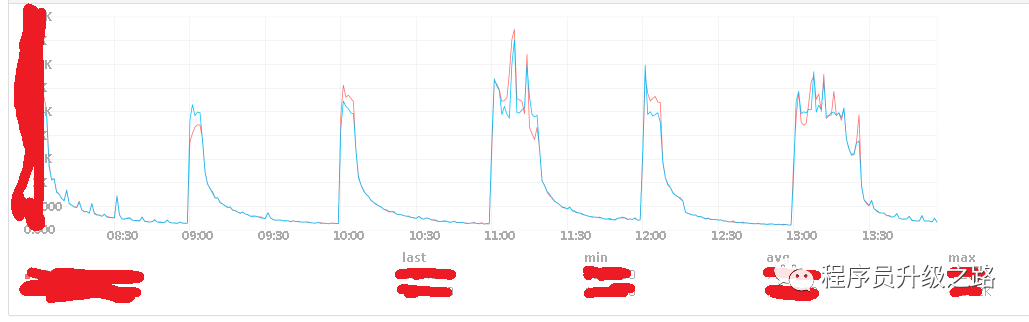
在准点时,系统负载猛增,后端有少量报错,这时会将其中1台踢下线,然后压力转移到其它机器,然后其它机器压力也增加,也报错,直到所有后端服务全部不可用。
PS:为什么准点流量这么大,和客户端了解,客户端有个功能,每1个小时从服务端取下配置,在实现时客户端没有做分流处理,全部准点向服务器发送请求,瞬间崩溃。。。
原因找到了,就容易解决了,将上述2参数调整如下:
upstream xxx{server 192.1686.1.114:6280 max_fails=50 fail_timeout=5s;server 192.168.160.115:6280 max_fails=50 fail_timeout=5s;server 192.168.160.116:6280 max_fails=50 fail_timeout=5s;}
问题彻底解决。
往期精选:
码字不易,喜欢就点击关注吧~

文章转载自程序员升级之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
