




目录
前言
使用 Python 爬取猫咪图片,并为猫咪🐱制作千图成像!

爬取猫咪图片
本文使用的 Python 版本是 3.10.0 版本,可直接在官网下载:https://www.python.org 。
Pythonn 的安装配置过程在此不做详细介绍,网上随意搜都是教程!
1、爬取绘艺素材网站
爬取网站:猫咪图片
首先安装必须的库:
pip install BeautifulSoup4 pip install requests pip install urllib3 pip install lxml
爬取图片代码:
from bs4 import BeautifulSoup
import requests
import urllib.request
import os
# 第一页猫咪图片网址
url = 'https://www.huiyi8.com/tupian/tag-%E7%8C%AB%E5%92%AA/1.html'
# 图片保存路径,这里 r 表示不转义
path = r"/Users/lpc/Downloads/cats/"
# 判断目录是否存在,存在则跳过,不存在则创建
if os.path.exists(path):
pass
else:
os.mkdir(path)
# 获得所有猫咪图片网页地址
def allpage():
all_url = []
# 循环翻页次数 20 次
for i in range(1, 20):
# 替换翻页的页数,这里的 [-6] 是指网页地址倒数第 6 位
each_url = url.replace(url[-6], str(i))
# 将所有获取的 url 加入 all_url 数组
all_url.append(each_url)
# 返回所有获取到的地址
return all_url
# 主函数入口
if __name__ == '__main__':
# 调用 allpage 函数获取所有网页地址
img_url = allpage()
for url in img_url:
# 获得网页源代码
requ = requests.get(url)
req = requ.text.encode(requ.encoding).decode()
html = BeautifulSoup(req, 'lxml')
# 添加一个 url 数组
img_urls = []
# 获取 html 中所有 img 标签的内容
for img in html.find_all('img'):
# 筛选匹配 src 标签内容以 http 开头,以 jpg 结束
if img["src"].startswith('http') and img["src"].endswith("jpg"):
# 将符合条件的 img 标签加入 img_urls 数组
img_urls.append(img)
# 循环数组中所有 src
for k in img_urls:
# 获取图片 url
img = k.get('src')
# 获取图片名称,强制类型转换很重要
name = str(k.get('alt'))
type(name)
# 给图片命名
file_name = path + name + '.jpg'
# 通过图片 url 和图片名称下载猫咪图片
with open(file_name, "wb") as f, requests.get(img) as res:
f.write(res.content)
# 打印爬取的图片
print(img, file_name)
📢 注意: 以上代码无法直接复制运行,需要修改下载图片路径:/Users/lpc/Downloads/cats,请修改为读者本地的保存路径!
爬取成功:
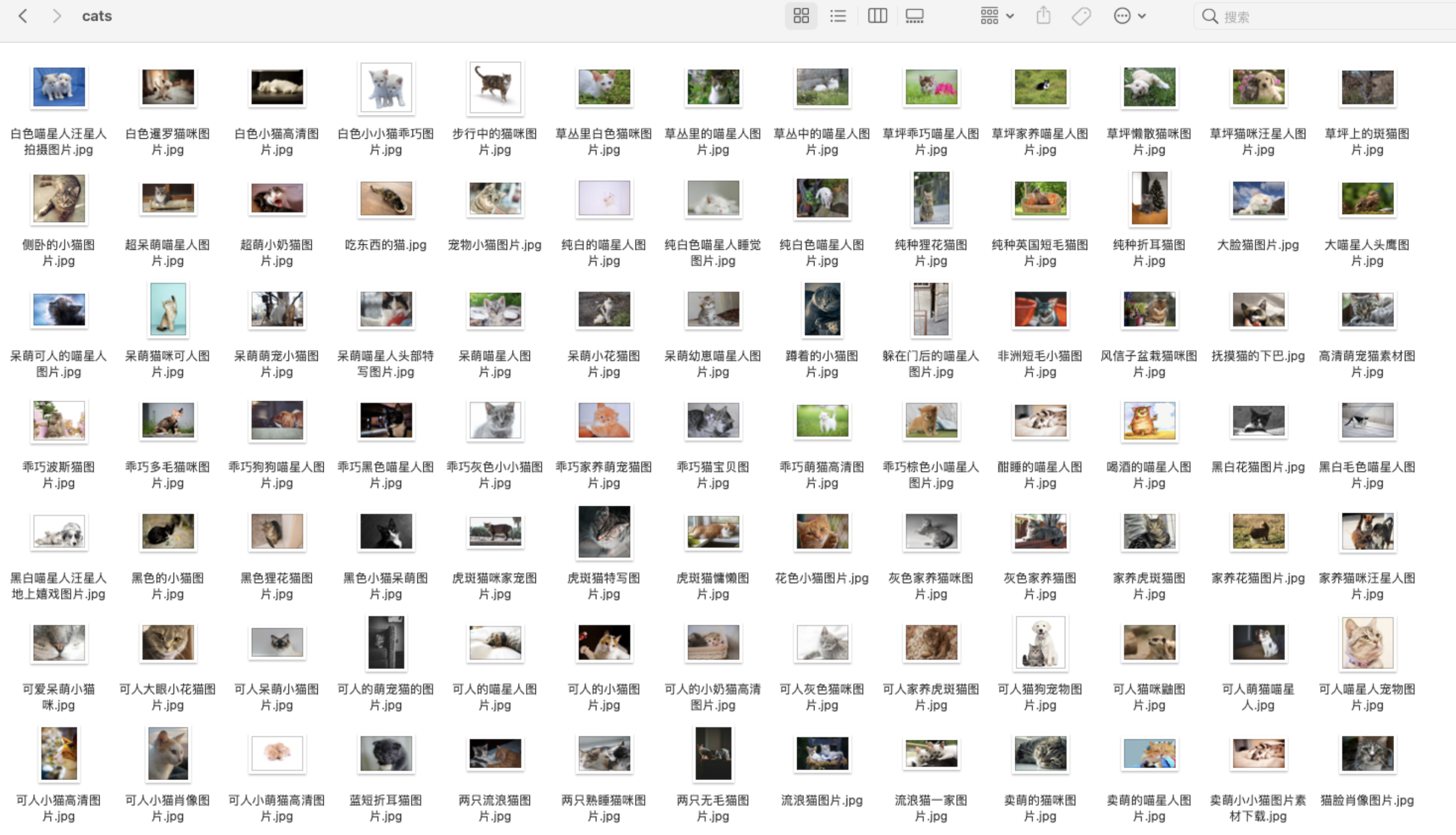
共爬取 346 张猫咪图片!
2、爬取 ZOL 网站
爬取 ZOL 网址:萌猫
爬取代码:
import requests
import time
import os
from lxml import etree
# 请求的路径
url = 'https://desk.zol.com.cn/dongwu/mengmao/1.html'
# 图片保存路径,这里 r 表示不转义
path = r"/Users/lpc/Downloads/ZOL/"
# 这里是你要保存的路径位置 前面的r 表示这段不转义
if os.path.exists(path): # 判断目录是否存在,存在则跳过,不存在则创建
pass
else:
os.mkdir(path)
# 请求头
headers = {"Referer": "Referer: http://desk.zol.com.cn/dongman/1920x1080/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36", }
headers2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0", }
def allpage(): # 获得所有网页
all_url = []
for i in range(1, 4): # 循环翻页次数
each_url = url.replace(url[-6], str(i)) # 替换
all_url.append(each_url)
return all_url # 返回地址列表
# TODO 获取到Html页面进行解析
if __name__ == '__main__':
img_url = allpage() # 调用函数
for url in img_url:
# 发送请求
resq = requests.get(url, headers=headers)
# 显示请求是否成功
print(resq)
# 解析请求后获得的页面
html = etree.HTML(resq.text)
# 获取a标签下进入高清图页面的url
hrefs = html.xpath('.//a[@class="pic"]/@href')
# TODO 进入更深一层获取图片 高清图片
for i in range(1, len(hrefs)):
# 请求
resqt = requests.get("https://desk.zol.com.cn" + hrefs[i], headers=headers)
# 解析
htmlt = etree.HTML(resqt.text)
srct = htmlt.xpath('.//img[@id="bigImg"]/@src')
# 截图片名称
imgname = srct[0].split('/')[-1]
# 根据url获取图片
img = requests.get(srct[0], headers=headers2)
# 执行写入图片到文件
with open(path + imgname, "ab") as file:
file.write(img.content)
# 打印爬取的图片
print(img, imgname)
爬取成功:
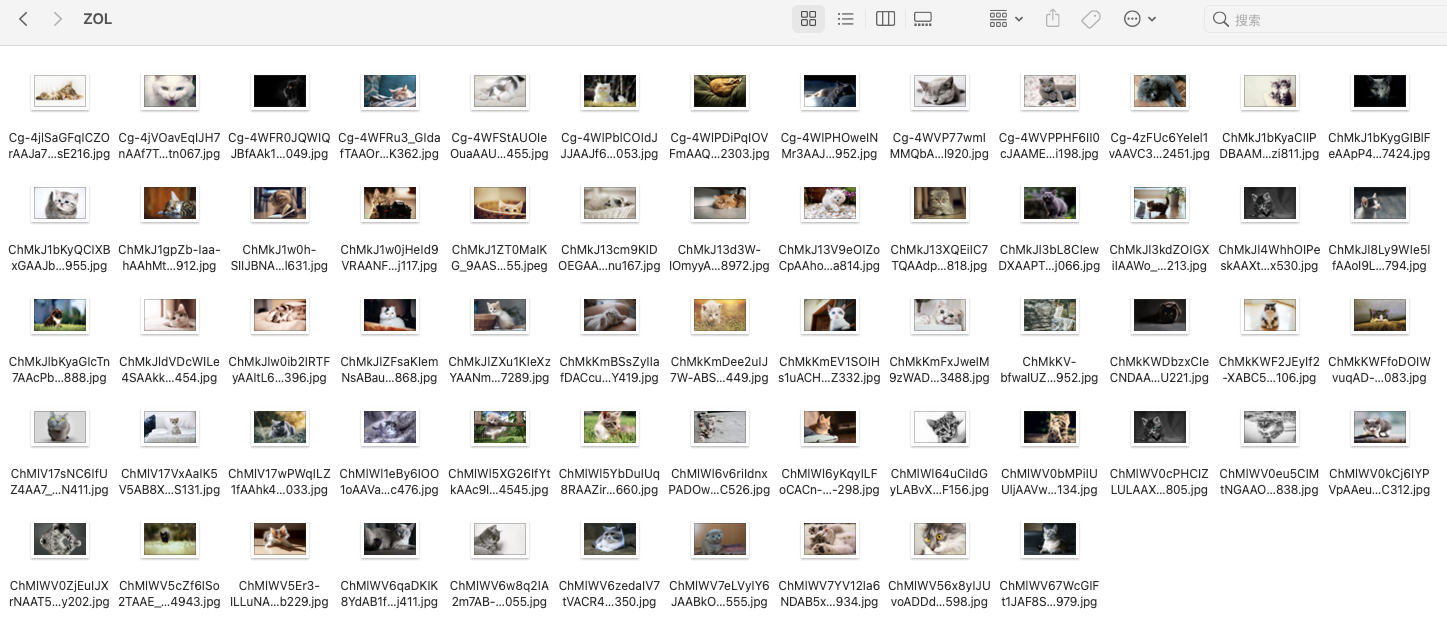
共爬取 81 张猫咪图片!
3、爬取百度图片网站
爬取百度网站:百度猫咪图片
1、爬取图片代码:
import requests
import os
from lxml import etree
path = r"/Users/lpc/Downloads/baidu1/"
# 判断目录是否存在,存在则跳过,不存在则创建
if os.path.exists(path):
pass
else:
os.mkdir(path)
page = input('请输入要爬取多少页:')
page = int(page) + 1
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
n = 0
pn = 1
# pn是从第几张图片获取 百度图片下滑时默认一次性显示30张
for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '7680290037940858296',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '猫咪',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'hd': '1',
'latest': '',
'copyright': '',
'word': '猫咪',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'nojc': '',
'acjsonfr': 'click',
'pn': pn, # 从第几张图片开始
'rn': '30',
'gsm': '3c',
'1635752428843=': '',
}
page_text = requests.get(url=url, headers=header, params=param)
page_text.encoding = 'utf-8'
page_text = page_text.json()
print(page_text)
# 先取出所有链接所在的字典,并将其存储在一个列表当中
info_list = page_text['data']
# 由于利用此方式取出的字典最后一个为空,所以删除列表中最后一个元素
del info_list[-1]
# 定义一个存储图片地址的列表
img_path_list = []
for i in info_list:
img_path_list.append(i['thumbURL'])
# 再将所有的图片地址取出,进行下载
# n将作为图片的名字
for img_path in img_path_list:
img_data = requests.get(url=img_path, headers=header).content
img_path = path + str(n) + '.jpg'
with open(img_path, 'wb') as fp:
fp.write(img_data)
n = n + 1
pn += 29
2、爬取代码
# -*- coding:utf-8 -*-
import requests
import re, time, datetime
import os
import random
import urllib.parse
from PIL import Image # 导入一个模块
imgDir = r"/Volumes/DBA/python/img/"
# 设置headers 为了防止反扒,设置多个headers
# chrome,firefox,Edge
headers = [
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive'
},
{
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive'
},
{
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19041',
'Accept-Language': 'zh-CN',
'Connection': 'keep-alive'
}
]
picList = [] # 存储图片的空 List
keyword = input("请输入搜索的关键词:")
kw = urllib.parse.quote(keyword) # 转码
# 获取 1000 张百度搜索出来的缩略图 list
def getPicList(kw, n):
global picList
weburl = r"https://image.baidu.com/search/acjson?tn=resultjson_com&logid=11601692320226504094&ipn=rj&ct=201326592&is=&fp=result&queryWord={kw}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word={kw}&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&cg=girl&pn={n}&rn=30&gsm=1e&1611751343367=".format(
kw=kw, n=n * 30)
req = requests.get(url=weburl, headers=random.choice(headers))
req.encoding = req.apparent_encoding # 防止中文乱码
webJSON = req.text
imgurlReg = '"thumbURL":"(.*?)"' # 正则
picList = picList + re.findall(imgurlReg, webJSON, re.DOTALL | re.I)
for i in range(150): # 循环数比较大,如果实际上没有这么多图,那么 picList 数据不会增加。
getPicList(kw, i)
for item in picList:
# 后缀名 和名字
itemList = item.split(".")
hz = ".jpg"
picName = str(int(time.time() * 1000)) # 毫秒级时间戳
# 请求图片
imgReq = requests.get(url=item, headers=random.choice(headers))
# 保存图片
with open(imgDir + picName + hz, "wb") as f:
f.write(imgReq.content)
# 用 Image 模块打开图片
im = Image.open(imgDir + picName + hz)
bili = im.width / im.height # 获取宽高比例,根据宽高比例调整图片大小
newIm = None
# 调整图片的大小,最小的一边设置为 50
if bili >= 1:
newIm = im.resize((round(bili * 50), 50))
else:
newIm = im.resize((50, round(50 * im.height / im.width)))
# 截取图片中 50*50 的部分
clip = newIm.crop((0, 0, 50, 50)) # 截取图片,crop 裁切
clip.convert("RGB").save(imgDir + picName + hz) # 保存截取的图片
print(picName + hz + " 处理完毕")
爬取成功:
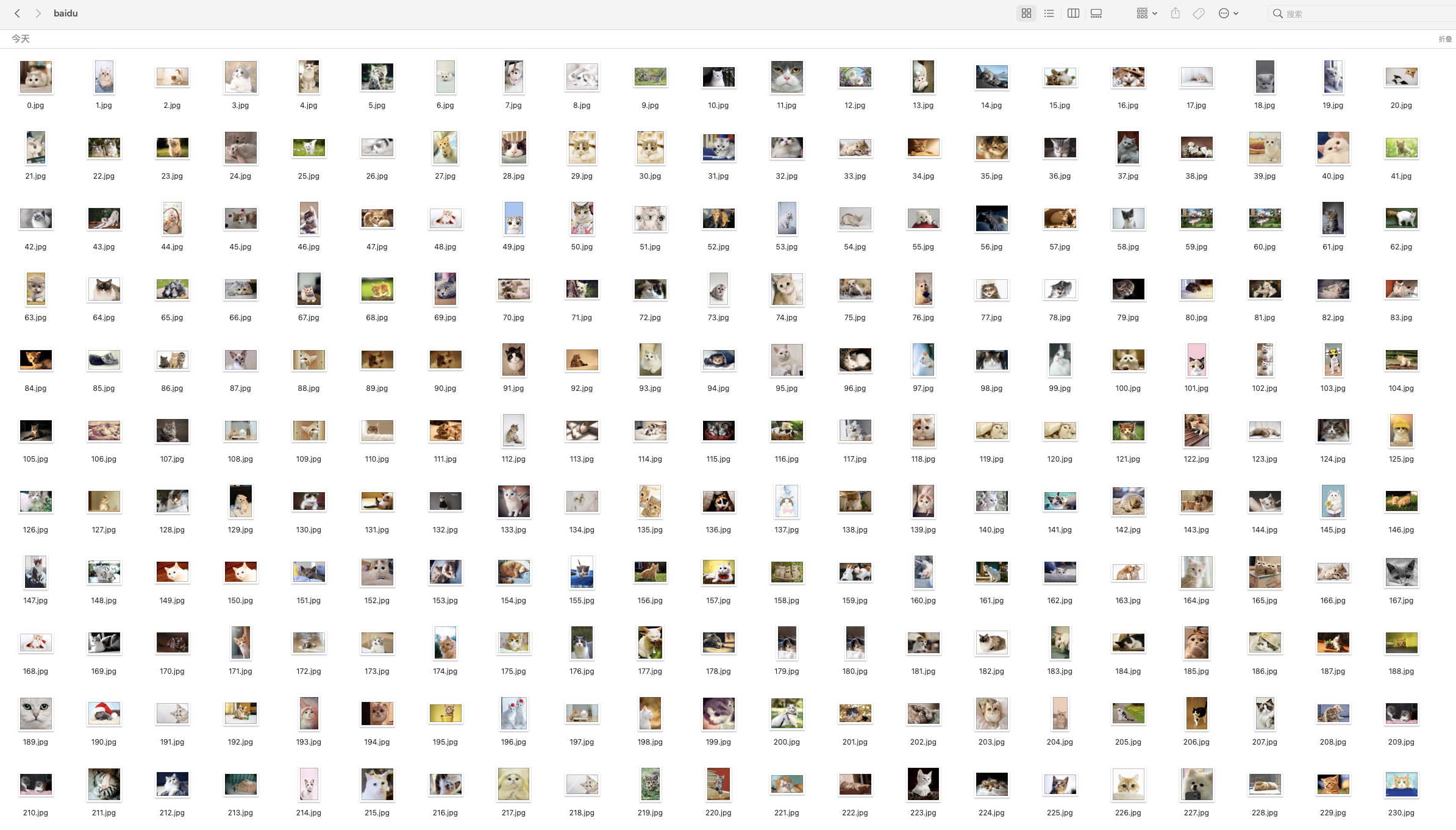
总结: 三个网站共爬取 1600 张猫咪图片!
千图成像
爬取千张图片之后,接下来就需要使用图片拼接成一张猫咪图片,即千图成像。
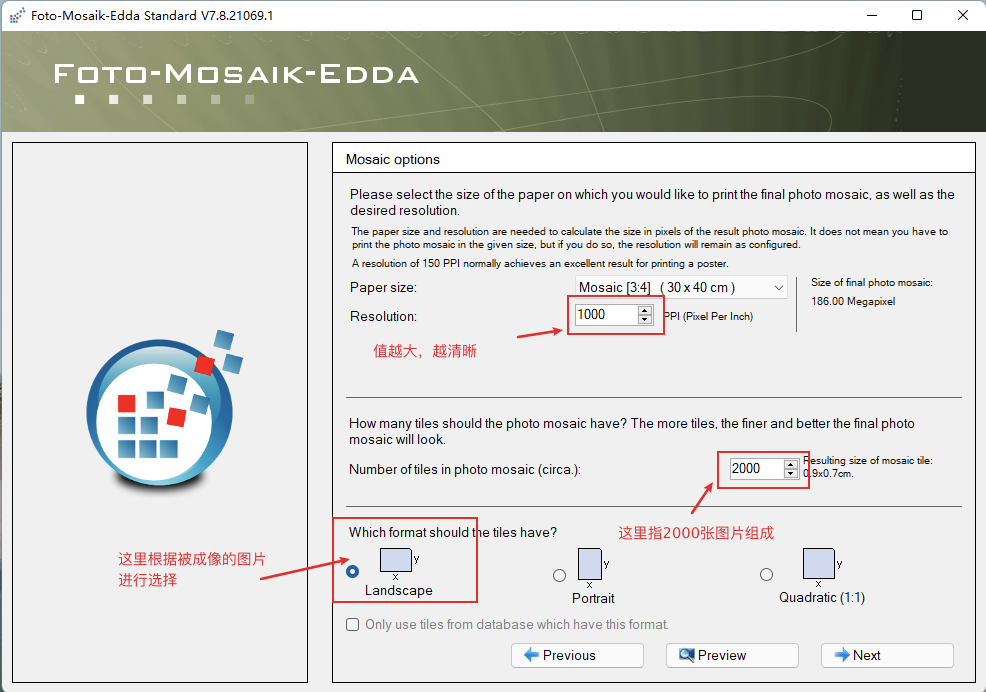
1、Foto-Mosaik-Edda 软件实现
首先下载软件:Foto-Mosaik-Edda Installer,如果无法下载,直接百度搜索 foto-mosaik-edda!
Windows 安装 Foto-Mosaik-Edda 过程比较简单!
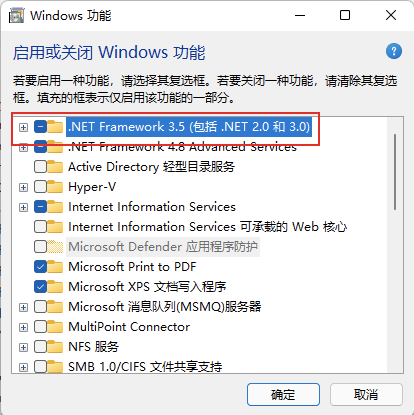
📢 注意: 但是需要提前安装 .NET Framework 2,否则报错如下无法成功安装!
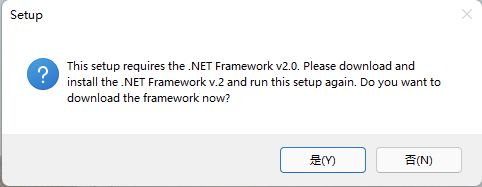
启用 .NET Framework 2 的方式:


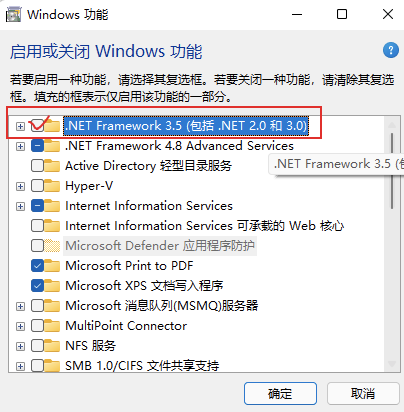
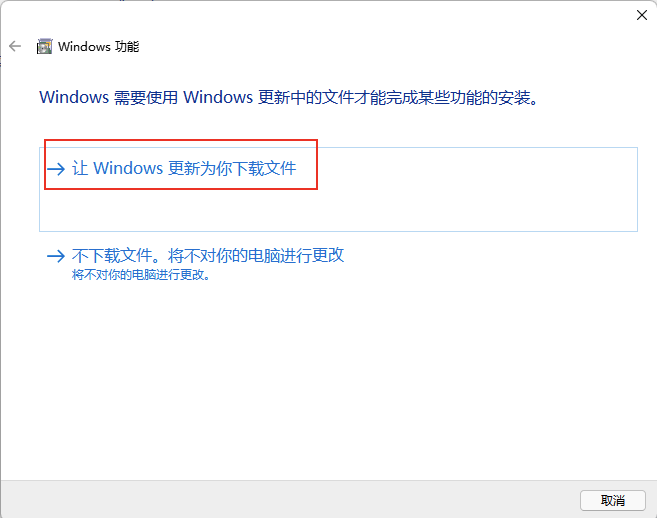
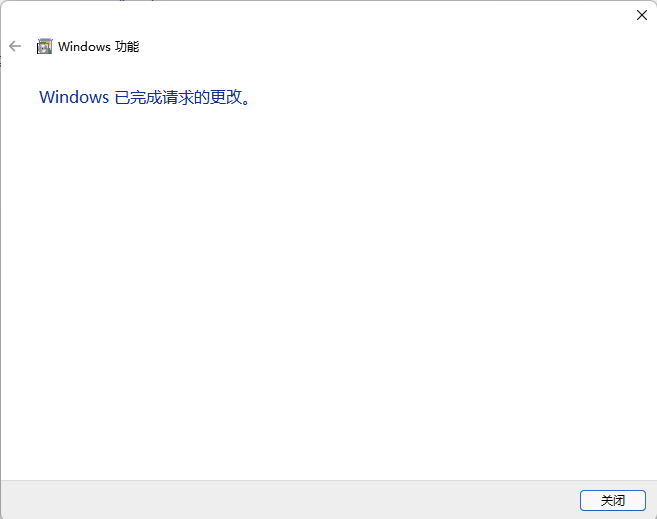
确认已经成功启用:
接下来就可以继续安装!
安装完成后,打开如下:
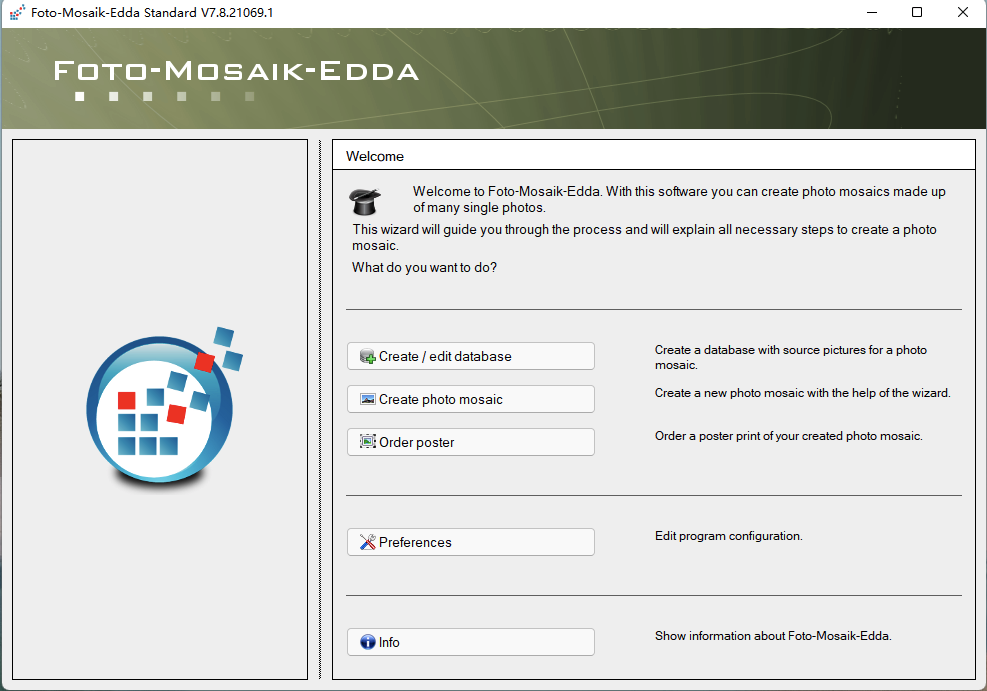
第一步,创建一个图库:
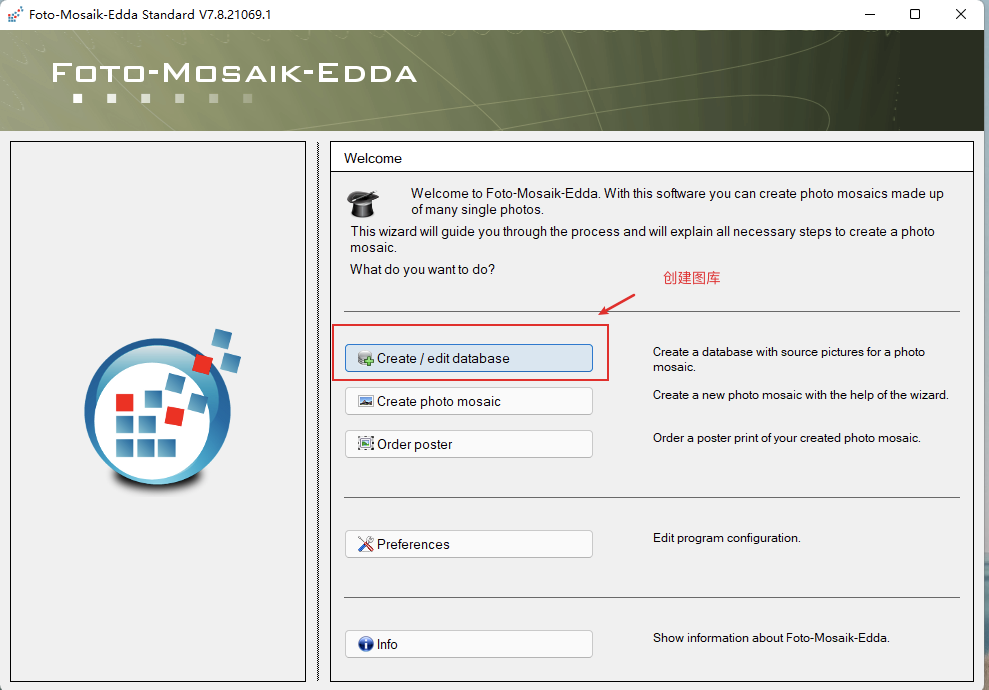

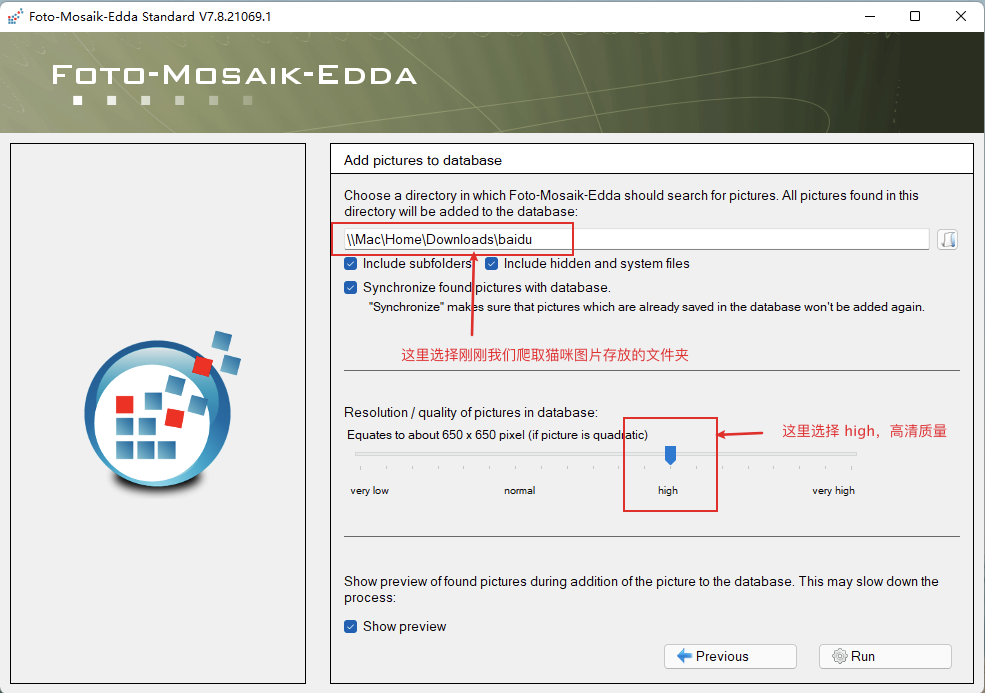
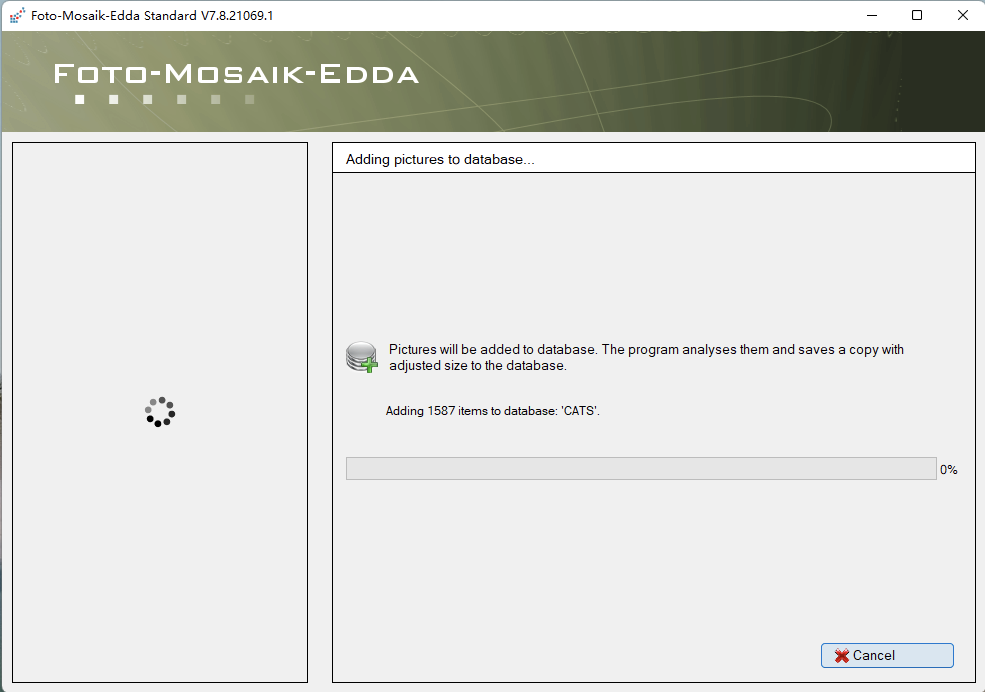
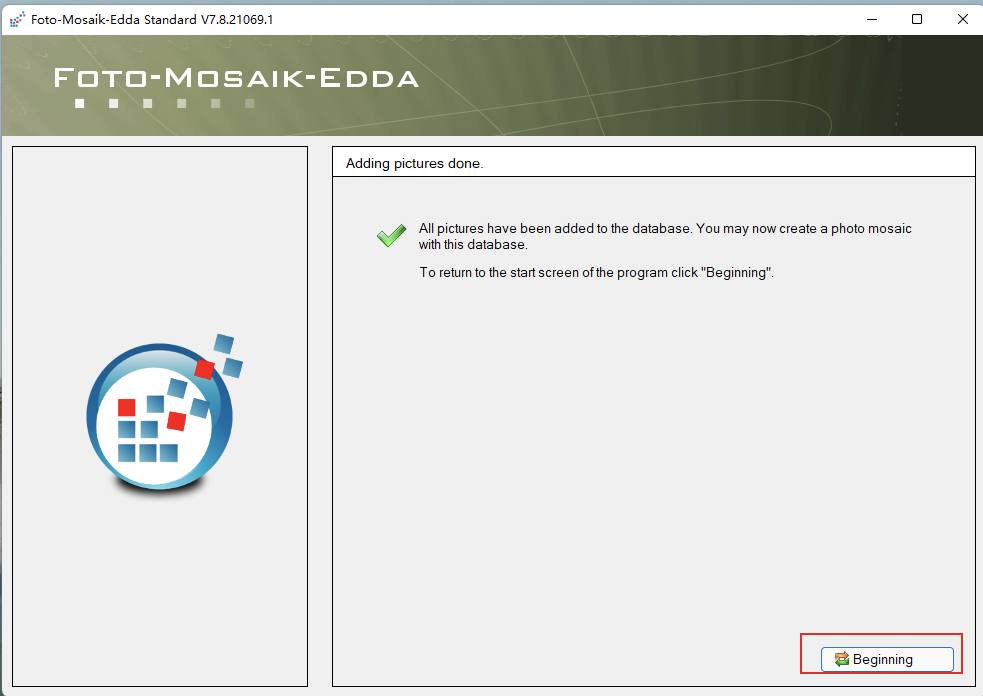
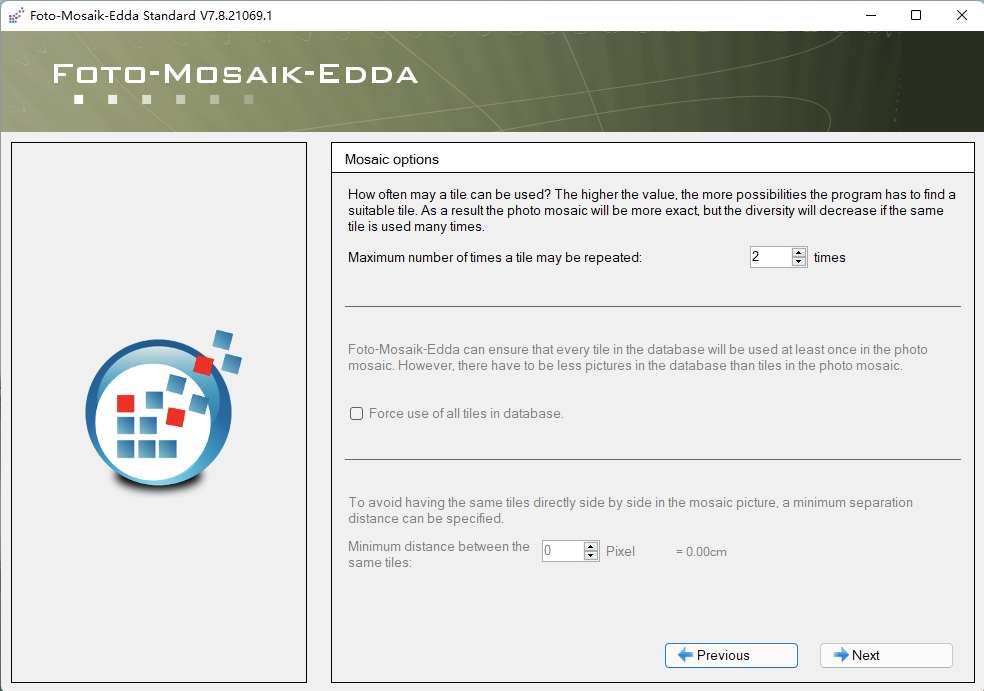
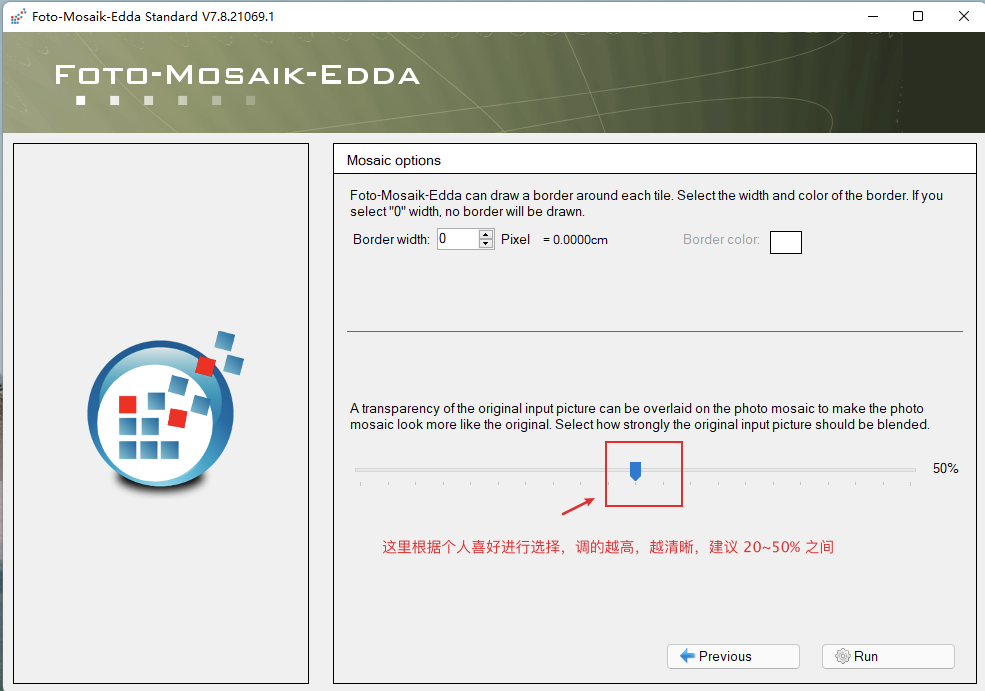
第二步,千图成像:
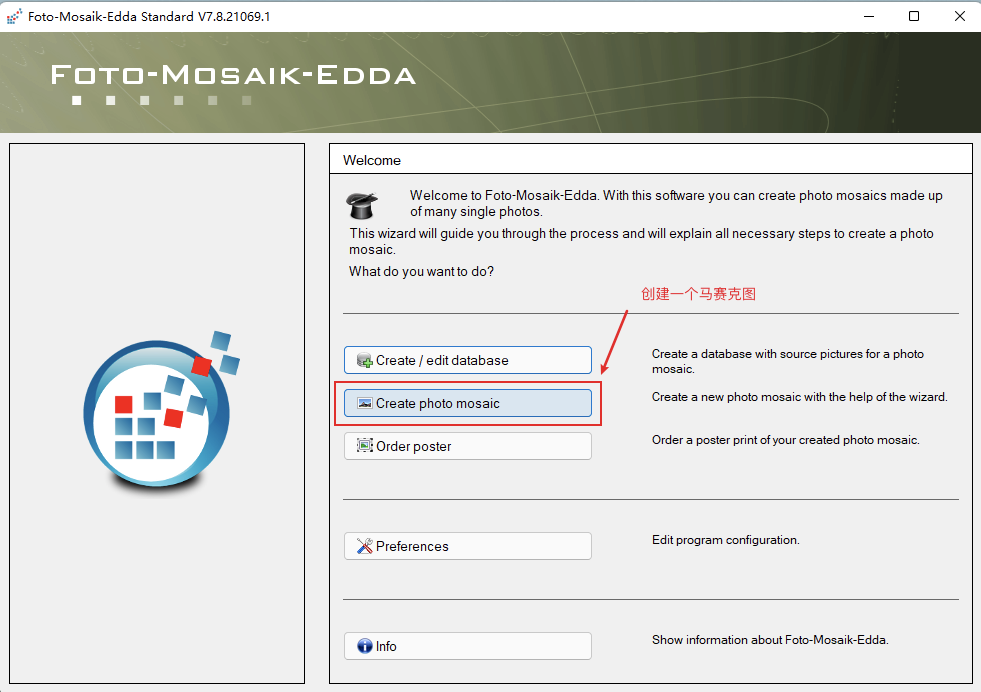
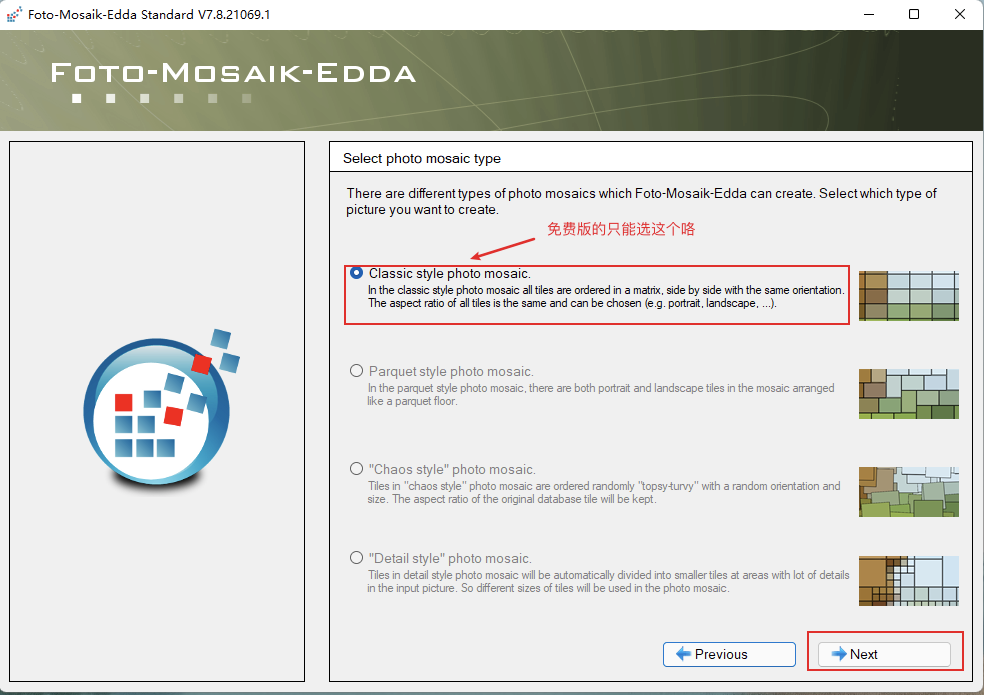
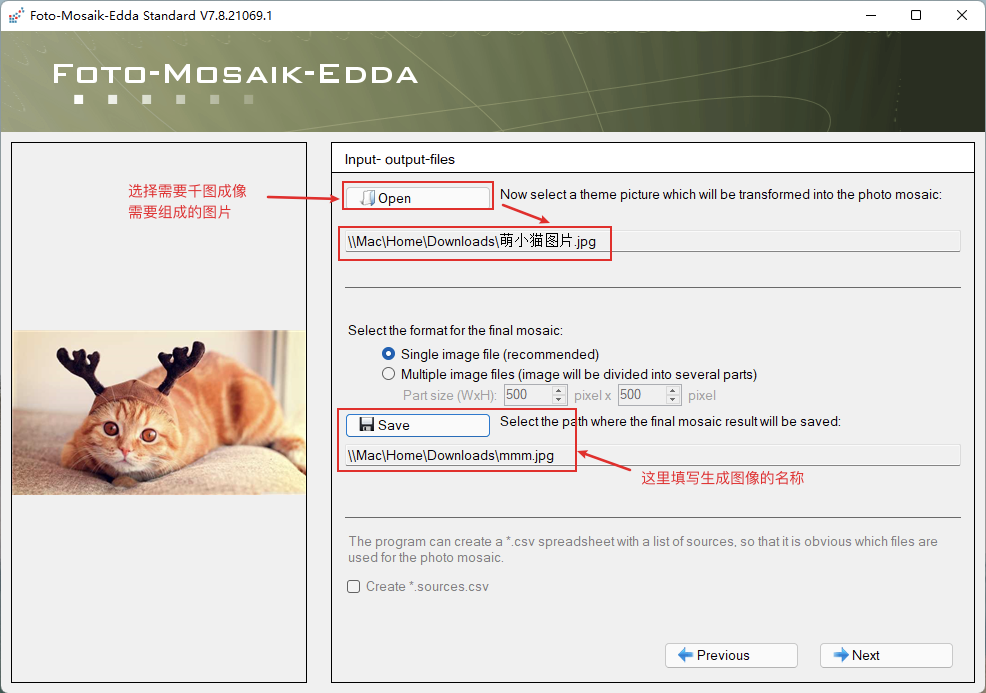
这里勾选第一步创建好的图库:
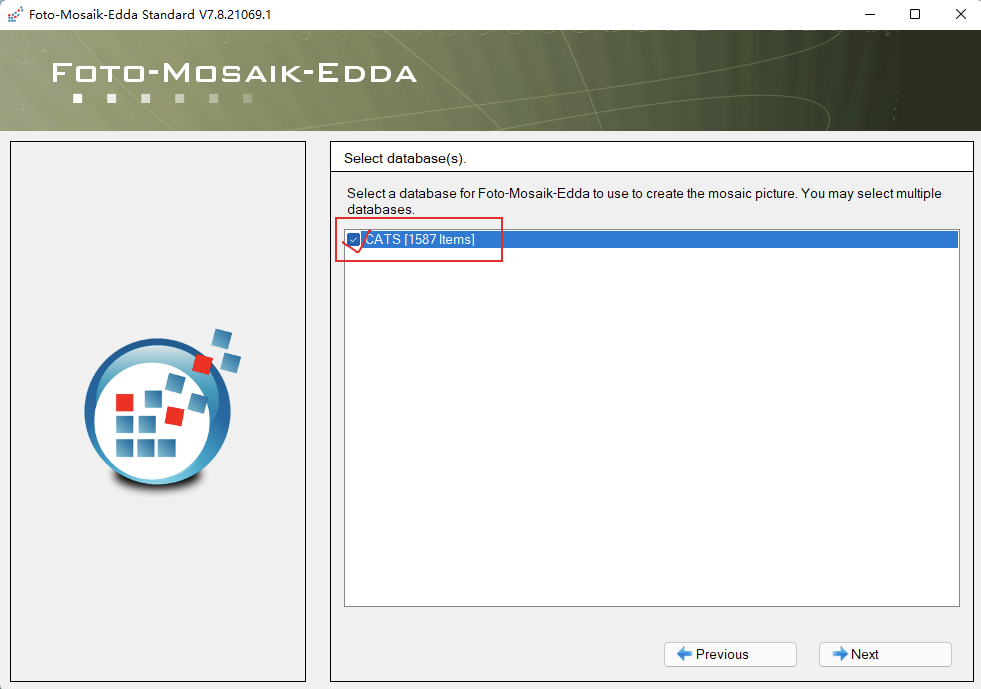
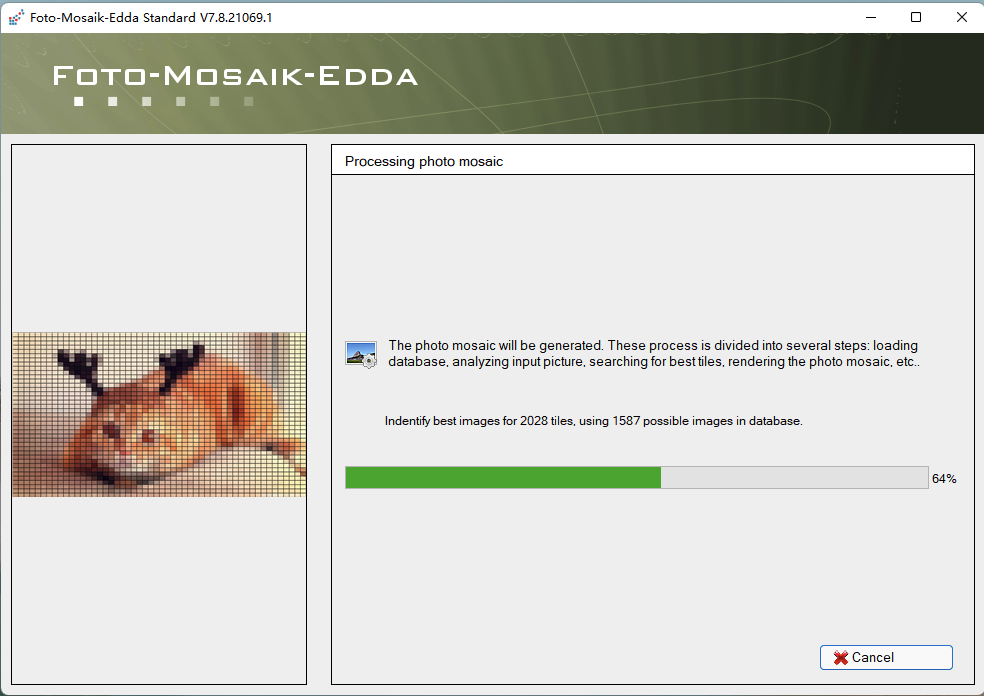
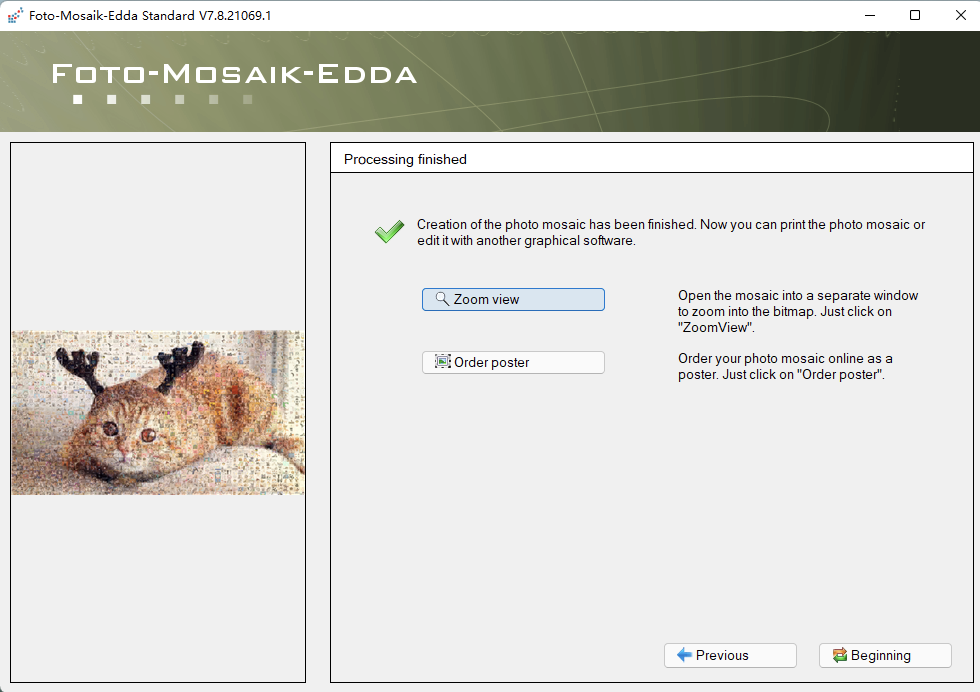
见证奇迹的时刻:

再制作一张可爱的猫咪:

大功告成!
2、使用 Python 实现
首先,选取一张图片:

运行以下代码:
# -*- coding:utf-8 -*-
from PIL import Image
import os
import numpy as np
imgDir = r"/Volumes/DBA/python/img/"
bgImg = r"/Users/lpc/Downloads/494.jpg"
# 获取图像的平均颜色值
def compute_mean(imgPath):
'''
获取图像平均颜色值
:param imgPath: 缩略图路径
:return: (r,g,b)整个缩略图的rgb平均值
'''
im = Image.open(imgPath)
im = im.convert("RGB") # 转为 rgb模式
# 把图像数据转为数据序列。以行为单位,每行存储每个像素点的色彩
'''如:
[[ 60 33 24]
[ 58 34 24]
...
[188 152 136]
[ 99 96 113]]
[[ 60 33 24]
[ 58 34 24]
...
[188 152 136]
[ 99 96 113]]
'''
imArray = np.array(im)
# mean()函数功能:求指定数据的取均值
R = np.mean(imArray[:, :, 0]) # 获取所有 R 值的平均值
G = np.mean(imArray[:, :, 1])
B = np.mean(imArray[:, :, 2])
return (R, G, B)
def getImgList():
"""
获取缩略图的路径及平均色彩
:return: list,存储了图片路径、平均色彩值。
"""
imgList = []
for pic in os.listdir(imgDir):
imgPath = imgDir + pic
imgRGB = compute_mean(imgPath)
imgList.append({
"imgPath": imgPath,
"imgRGB": imgRGB
})
return imgList
def computeDis(color1, color2):
'''
计算两张图的颜色差,计算机的是色彩空间距离。
dis = (R**2 + G**2 + B**2)**0.5
参数:color1,color2 是色彩数据 (r,g,b)
'''
dis = 0
for i in range(len(color1)):
dis += (color1[i] - color2[i]) ** 2
dis = dis ** 0.5
return dis
def create_image(bgImg, imgDir, N=2, M=50):
'''
根据背景图,用头像填充出新图
bgImg:背景图地址
imgDir:头像目录
N:背景图缩放的倍率
M:头像的大小(MxM)
'''
# 获取图片列表
imgList = getImgList()
# 读取图片
bg = Image.open(bgImg)
# bg = bg.resize((bg.size[0] // N, bg.size[1] // N)) # 缩放。建议缩放下原图,图片太大运算时间很长。
bgArray = np.array(bg)
width = bg.size[0] * M # 新生成图片的宽度。每个像素倍放大 M 倍
height = bg.size[1] * M # 新生成图片的高度
# 创建空白的新图
newImg = Image.new('RGB', (width, height))
# 循环填充图
for x in range(bgArray.shape[0]): # x,行数据,可以用原图宽替代
for y in range(bgArray.shape[1]): # y,列数据,,可以用原图高替代
# 找到距离最小的图片
minDis = 10000
index = 0
for img in imgList:
dis = computeDis(img['imgRGB'], bgArray[x][y])
if dis < minDis:
index = img['imgPath']
minDis = dis
# 循环完毕,index 就是存储了色彩最相近的图片路径
# minDis 存储了色彩差值
# 填充
tempImg = Image.open(index) # 打开色差距离最小的图片
# 调整图片大小,此处可以不调整,因为我在下载图的时候就已经调整好了
tempImg = tempImg.resize((M, M))
# 把小图粘贴到新图上。注意 x,y ,行列不要搞混了。相距 M 粘贴一张。
newImg.paste(tempImg, (y * M, x * M))
print('(%d, %d)' % (x, y)) # 打印进度。格式化输出 x,y
# 保存图片
newImg.save('final.jpg') # 最后保存图片
create_image(bgImg, imgDir)
运行结果:

从上图可以发现,图片的清晰度堪比原图,放大之后小图依然清晰可见!
📢 注意: 使用 Python 运行会比较慢!
写在最后
真好,又可以愉快地吸猫了~

本文参考:
- python批量爬取猫咪图片
- Python实现多线程并发下载大文件
- python爬取ZOL桌面壁纸高清图片
- Python爬取百度图片
- Python—如何实现千图成像:初级篇
- Python学习笔记17:玩转千图成像
📚 推荐阅读:DBA 学习之路
如果这篇文章对你有帮助,推荐访问我的 Oracle DBA 系统学习站点,涵盖 100 天完整学习路线:
- 🔧 Oracle 安装部署 · RMAN 备份恢复 · Data Pump 数据迁移
- 🏗️ RAC 高可用 · DataGuard 容灾 · 多租户架构
- 🔍 故障排查 · 升级迁移 · GoldenGate 数据同步
