




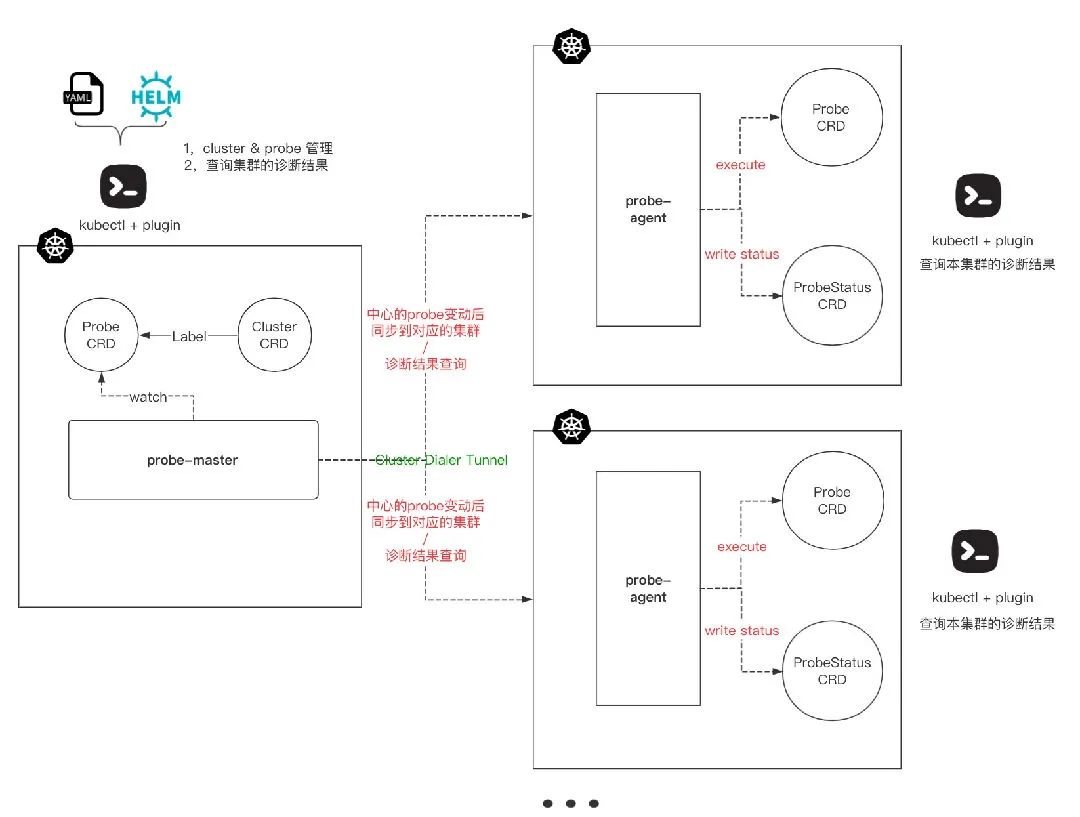
支持大规模集群 支持多集群管理,支持在管理端配置集群跟诊断项的关系以及统一查看所有集群的诊断结果;
云原生 核心逻辑采用 operator 来实现,提供完整的Kubernetes API兼容性;
可扩展 支持用户自定义巡检项。
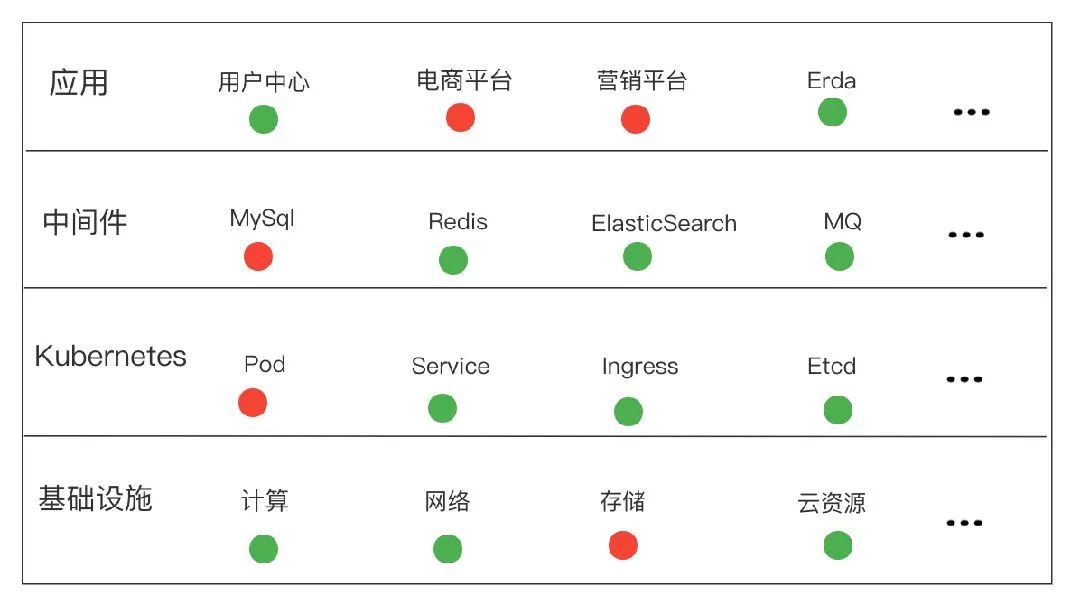
集中的所有节点是否均可以被调度,有没有特殊的污点存在等;
pod是否可以正常的创建,销毁,验证从 kubernetes,kubelet 到 docker 的整条链路;
创建一个service,并测试连通性,验证 kube-proxy 的链路是否正常;
解析一个内部或者外部的域名,验证 CoreDNS 是否正常工作;
访问一个 ingress 域名,验证集群中的 ingress 组件是否正常工作;
创建并删除一个namespace,验证相关的 webhook 是否正常工作;
对Etcd执行 put/get/delete 等操作,用于验证 Etcd 是否正常运行;
通过 mysql-client 的操作来验证 MySQL 是否正常运行;
模拟用户对业务系统进行登录,操作,验证业务的主流程是否常常;
检查各个环境的证书是否过期;
云资源的到期检查;
... 更多
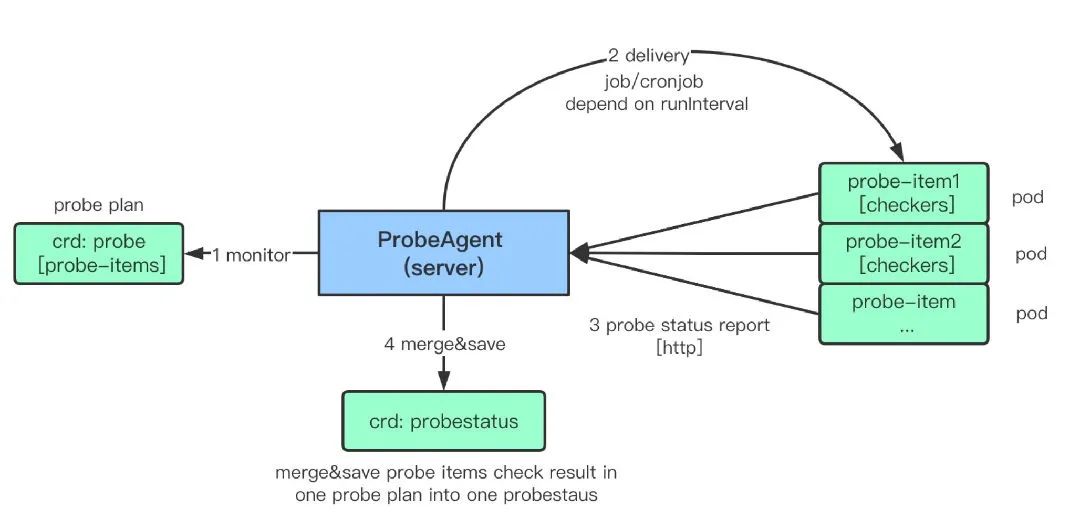
kubectl apply -f https://github.com/jetstack/cert-manager/releases/download/v1.3.1/cert-manager.yaml
vim deployment/probe-master.yamlapiVersion: apps/v1kind: Deploymentmetadata:name: probe-masterspec:template:spec:containers:- command:- /probe-masterenv:- name: SERVER_SECRET_KEYvalue: your-token-here
APP=probe-master make deploy
vim deployment/probe-agent.yaml---apiVersion: v1kind: ConfigMapmetadata:name: probeagentnamespace: systemdata:probe-conf.yaml: |probe_master_addr: http://probe-master.kubeprober.svc.cluster.local:8088cluster_name: erda-cloudsecret_key: your-token-here
APP=probe-agent make deploy
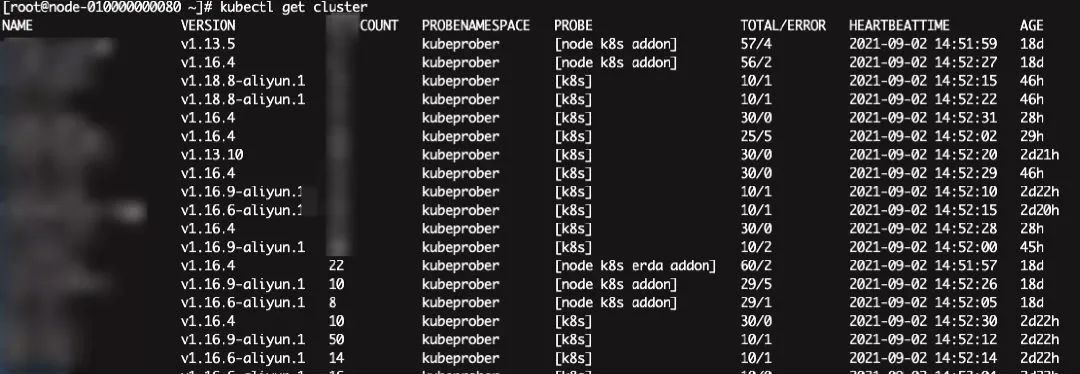
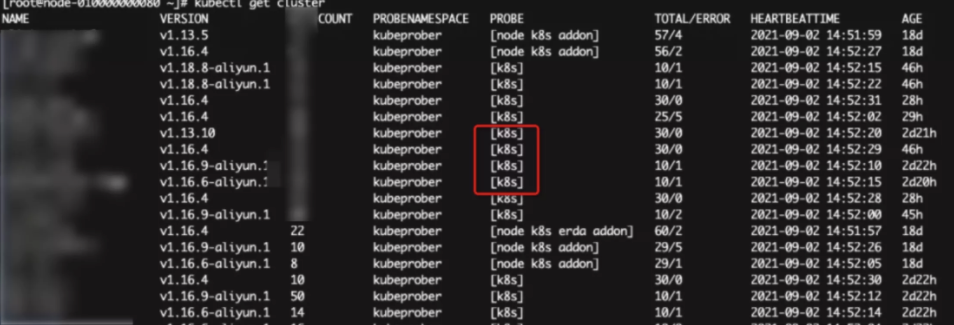
kubectl get cluster
apiVersion: kubeprober.erda.cloud/v1kind: Probemetadata:name: k8sspec:policy:# unit: minuterunInterval: 30template:containers:- env:- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeNamename: k8simage: kubeprober/probe-k8s:v0.1.5resources:requests:cpu: 10mmemory: 50MirestartPolicy: Neverconfigs:- name: control-planeenv:- name: PRIVATE_DOMAINvalue: "kubernetes.default"- name: DNS_CHECK_NAMESPACEvalue: "kube-system"- name: DNS_NODE_SELECTORvalue: "k8s-app=kube-dns"- name: PUBLIC_DOMAINvalue: "www.baidu.com"
kubectl apply -f probe.yaml

kubectl label cluster erda-cloud probe/k8s=true
创建 kubectl probe 所需要的配置文件,没有该文件则 kubectl probe 会自动将 ws://probe-master.kubeprober.svc.cluster.local:8088/clusterdialer 作为 master 的 地址,其他情况可以自行修改该配置文件。
vi ~/.kubeprober/config{"masterAddr": "ws://probe-master.kubeprober.svc.cluster.local:8088/clusterdialer"}
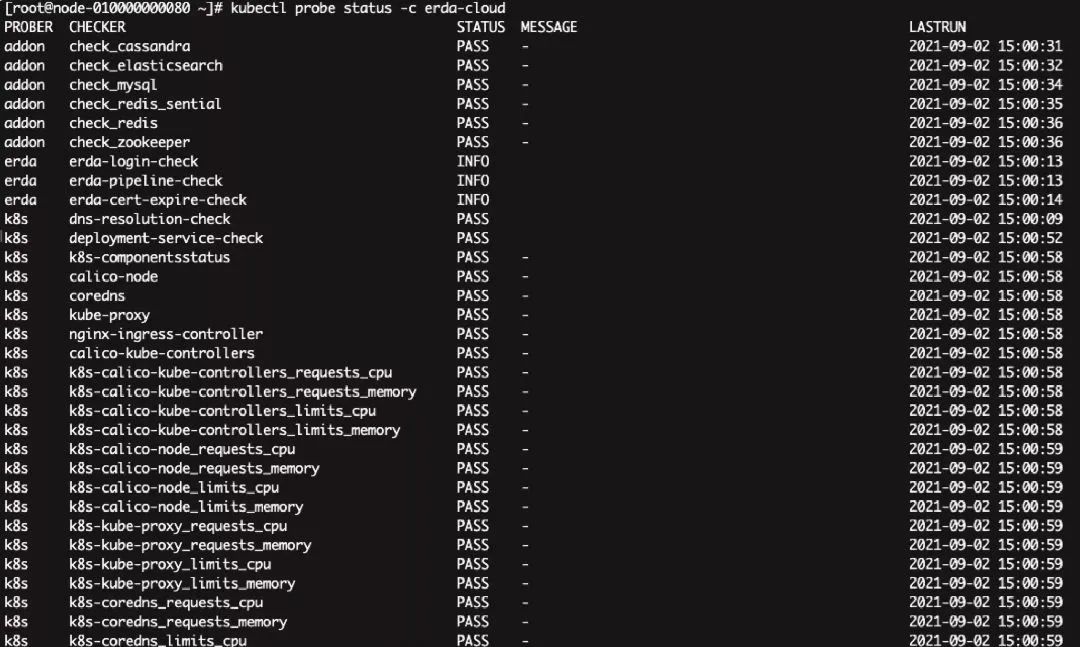
使用 kubectl probe status 可以查看特定集群的当前诊断结果的状态, 由于诊断项是定时在运行的,因此该命令查到的就是最新一次的诊断结果。
kubectl probe status -c erda-cloud
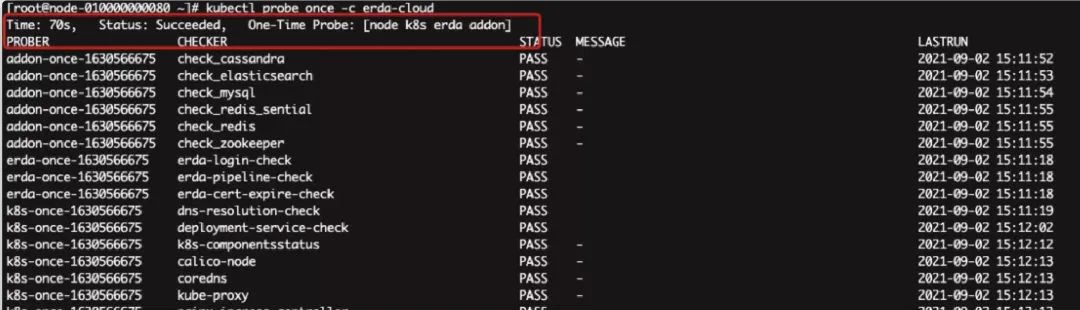
kubectl probe once -c erda-cloud #诊断已经 attatch 了的 probekubectl probe once -c erda-cloud -p k8s,host #诊断特定 probe
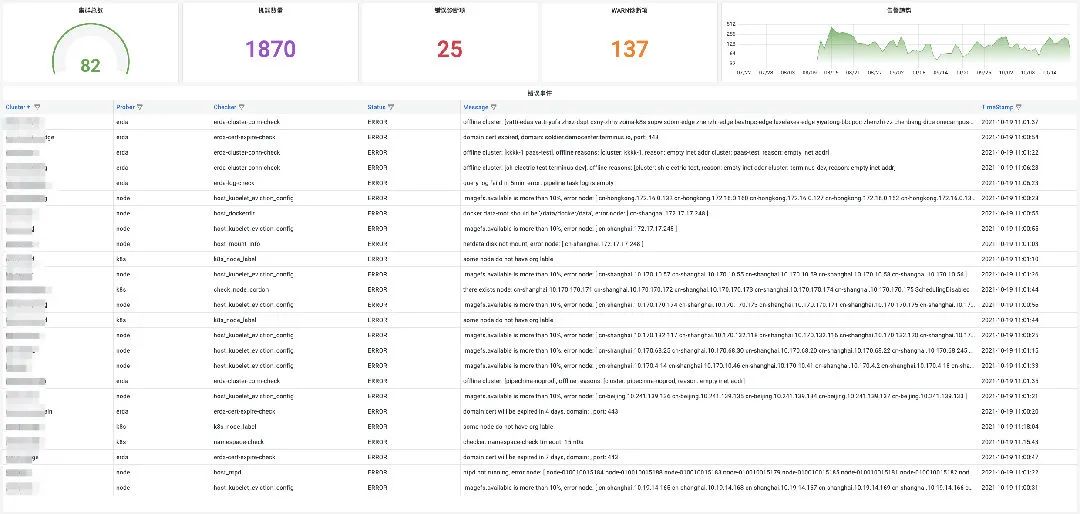
一次性诊断的历史记录会被保存起来,可以使用如下命令来进行查看历史记录。
kubectl probe oncestatus -c erda-cloud -l

查看历史某一次一次性诊断的诊断结果。
kubectl probe oncestatus -c erda-cloud -i 1630566675
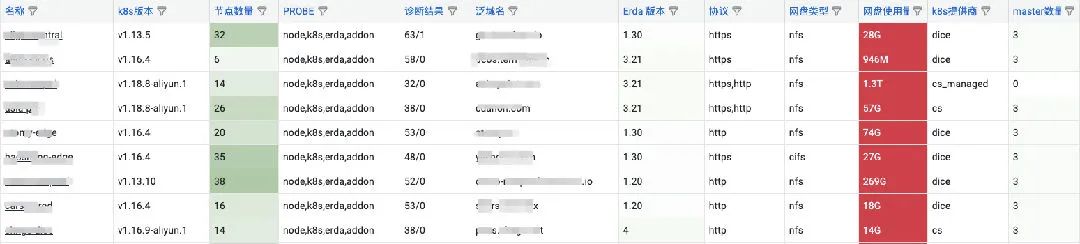
END

 觉得不错,请点个在看呀
觉得不错,请点个在看呀
文章转载自OSC开源社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
