




LAB 本章的实验室可以在GitHub上找到,网址是https://github.com/jgperrin/net.jgp.books.spark.ch01。这是实验室#400。如果你不熟悉GitHub和Eclipse,附录A、B、C和D提供了指导。
大框架:Spark是什么,它的作用是什么
什么是Spark?

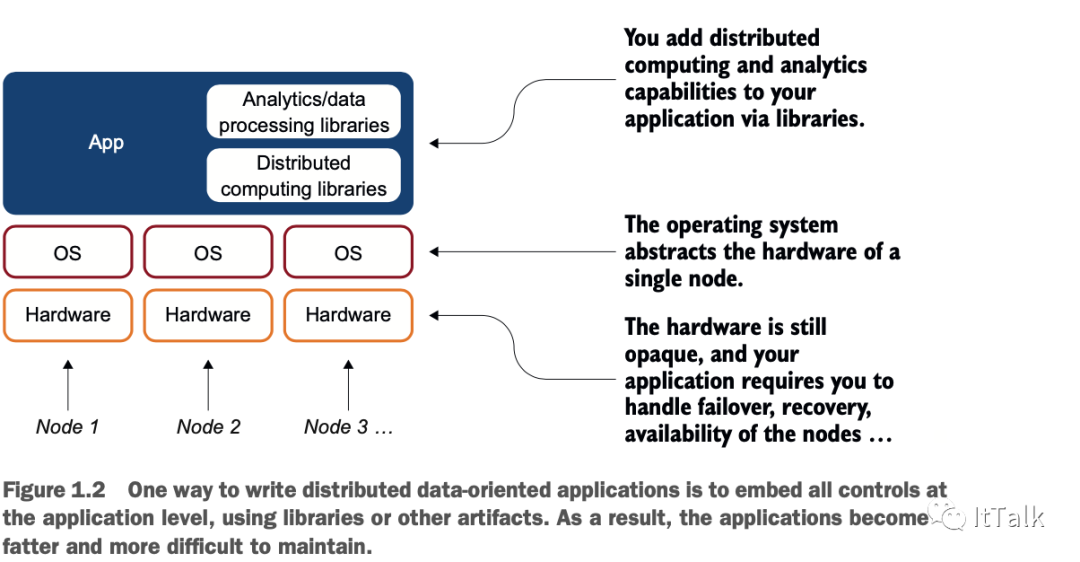
说了这么多,Apache Spark可能看起来像一个复杂的系统,需要你有很多先前的知识。我坚信,你只需要Java和关系型数据库管理系统(RDBMS)的技能,就可以理解、使用、利用和扩展Spark构建应用程序。应用程序也变得更加智能,可以生成报表并进行数据分析(包括数据聚合、线性回归或简单地显示环形图)。因此,当你想在你的应用程序中添加这样的分析功能时,你必须连接库或建立自己的库。所有这些都会让你的应用变得更大(或者说更胖,如胖客户端),更难维护,更复杂,因此,企业的成本也更高。"那为什么不把这些功能放在操作系统层面呢?"你可能会问。把这些功能放在操作系统等较低层次的好处很多,包括以下几点:
提供处理数据的标准方法(有点像结构化查询语言,或关系数据库的SQL)。
降低了应用程序的开发(和维护)成本。
使你能够专注于了解如何使用工具,而不是工具如何工作。例如,Spark执行分布式摄取,你可以学习如何从中受益,而不必完全掌握Spark完成任务的方式)。
而这正是Spark对我的意义:一个分析操作系统。图1.3显示了这个简化的栈。

四大法力支柱
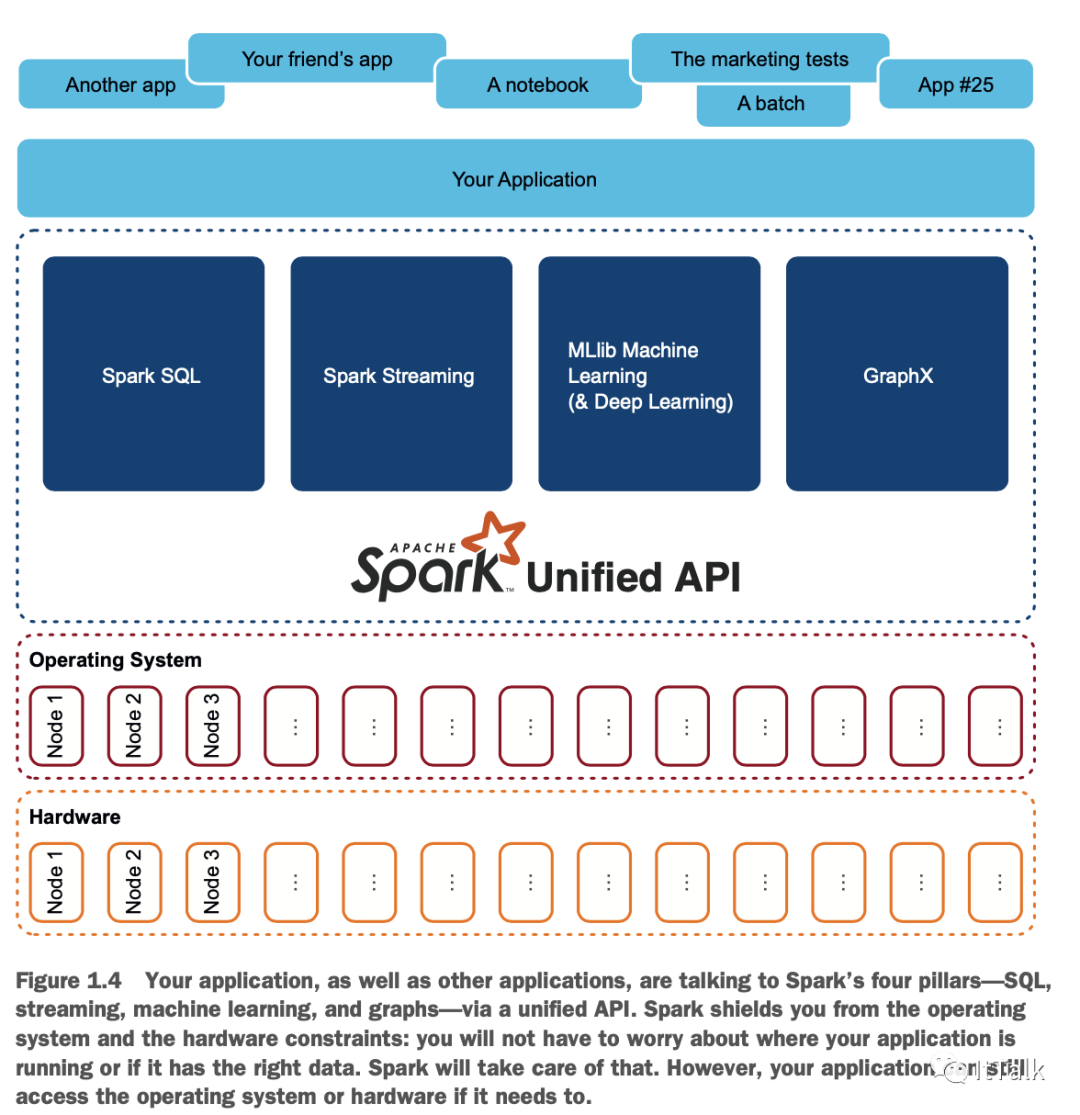
Spark SQL来操作数据,就像RDBMS中的传统SQL作业一样。Spark SQL提供了API和SQL来操作你的数据。你将在第11章发现Spark SQL,并在之后的大部分章节中阅读更多关于它的内容。Spark SQL是Spark的基石。
Spark Streaming,特别是Spark结构化流,来分析流数据。Spark的统一API将帮助你以类似的方式处理你的数据,无论是流式数据还是批处理数据。你将在第10章学习关于流式数据的具体内容。
用于机器学习的Spark MLlib和最近在深度学习方面的扩展。机器学习、深度学习和人工智能都有自己专门的书。
用于利用图数据结构的GraphX。要了解更多关于GraphX的信息,你可以阅读Michael Malak和Robin East所著的《Spark GraphX in Action》(Manning,2016)。
如何使用Spark?
Spark在数据处理/工程场景中的应用案例分析
1 摄取 2 提高数据质量(DQ) 3 转换 4 发布 图1.5说明了这一过程。
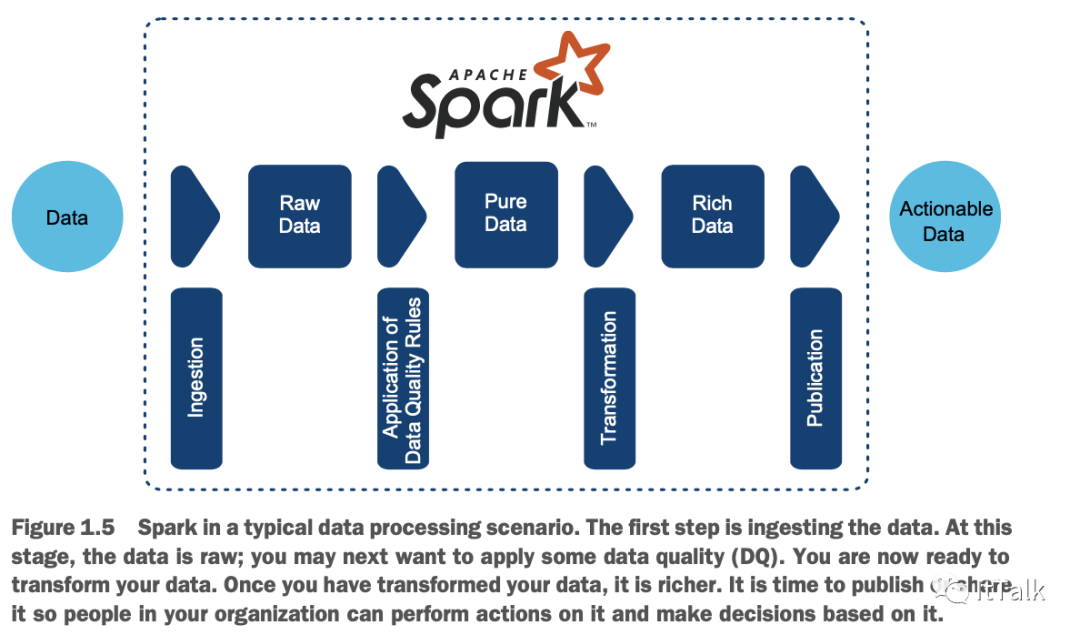
这个过程包括四个步骤,每一步之后,数据都会落在一个区域:
1 摄取数据-Spark 可以从各种来源摄取数据(参见第 7、8 和 9 章关于摄取的内容)。如果你找不到支持的格式,你可以建立自己的数据源。我把这个阶段的数据称为原始数据。你也可以发现这个区域被命名为staging,landing,bronze,even,swamp zone。
2 提高数据质量(DQ) -在处理数据之前,你可能想检查数据本身的质量。DQ的一个例子是确保所有的出生日期都在过去。作为这个过程的一部分,你也可以选择混淆一些数据:如果你是在医疗保健环境中处理社会安全号码(SSN),你可以确保SSN不能被开发人员或非授权人员访问,我把这个阶段称为纯数据区。你可能也会发现这个区域被称为refinery, silver, pond, sandbox, 或 exploration。
3 转化数据--下一步是处理你的数据。您可以将其与其他数据集加入,应用自定义函数,执行聚合,实现机器学习等。这一步的目标是获得丰富的数据,即你的分析工作的成果。大部分章节都在讨论转化。这个区域也可以称为production, gold, refined, lagoon, 或 operationalization zone。
4 加载和发布--与ETL流程一样,你可以通过将数据加载到数据仓库、使用商业智能(BI)工具、调用API或将数据保存在文件中来完成。其结果是为您的企业提供可操作的数据。
数据科学场景下的Spark
如果你想了解更多关于Spark和数据科学的知识,可以看看这些书。
Jonathan Rioux所著的《PySpark in Action》(Manning,2020,www.manning.com/books/pyspark-in-action?a_aid=jgp)。
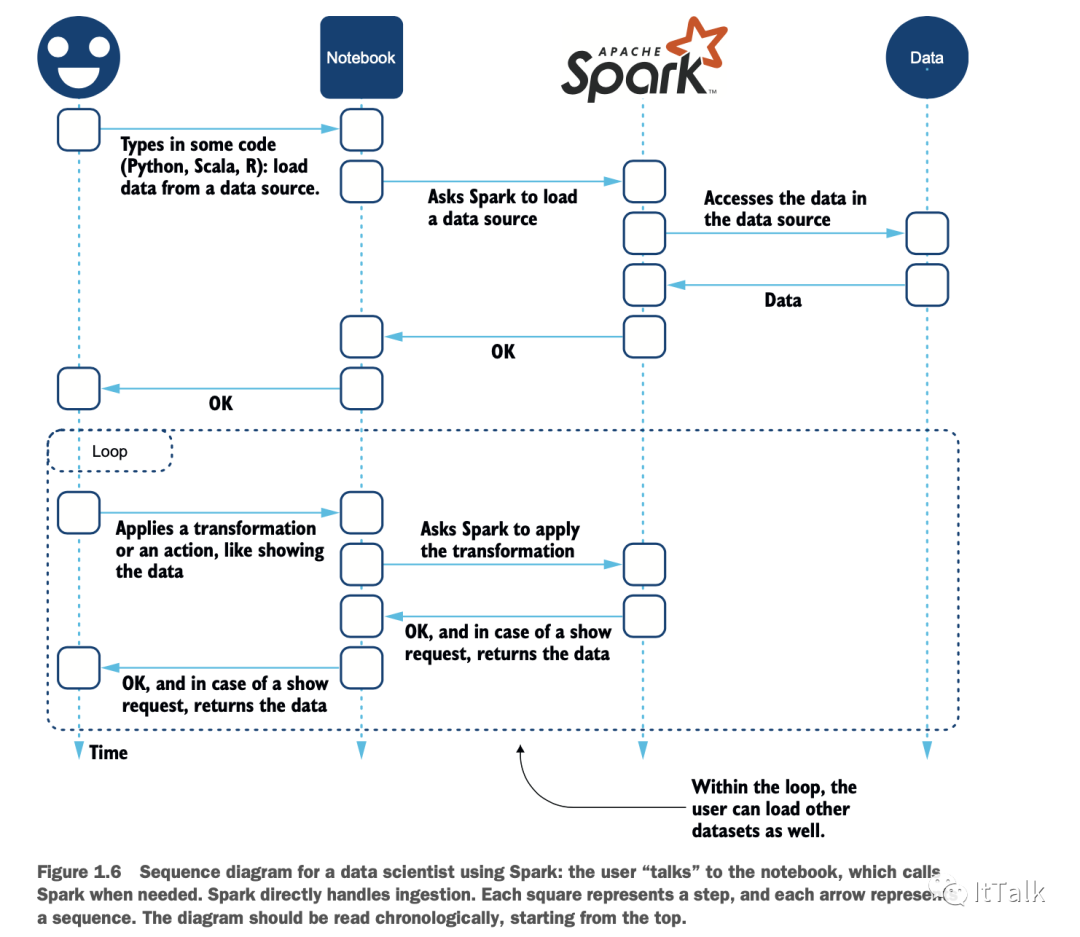
Mastering Large Datasets with Python by John T. Wolohan (Manning, 2020, www.manning.com/books/mastering-large-datasets-with-python?a_aid=jgp)。在图1.6描述的用例中,数据被加载到Spark中,然后用户将使用数据,应用转换,并显示部分数据。显示数据并不是这个过程的结束。用户还可以继续以交互的方式,就像实体笔记本一样,在笔记本上写配方、做笔记等等。最后,笔记本用户可以将数据保存到文件或数据库中,或者制作(交互式)报告。
用Spark可以做什么?
Spark预测北卡罗来纳州餐馆的质量
Spark允许Lumeris快速传输数据
Spark为欧洲核子研究中心分析设备日志
其他用例
Spark还参与了许多其他的用例,包括以下几种:
构建交互式数据整理工具,如IBM的Watson Studio和Databricks的笔记本。
监测MTV或Nickelodeon等电视频道的视频馈送质量。
通过Riot Games公司监测在线电子游戏玩家的不良行为,并准实时调整玩家互动,最大限度地提高所有玩家的积极体验。
为什么你会喜欢dataframe
一个拼写问题 在大多数文献中,你会发现dataframe有不同的拼法:DataFrame. 我决定采用最英式的写法,我同意,这对一个法国人来说可能很奇怪。然而,dataframe仍然是一个普通名词,所以没有理由在这里和那里玩大写字母。这又不是汉堡店!
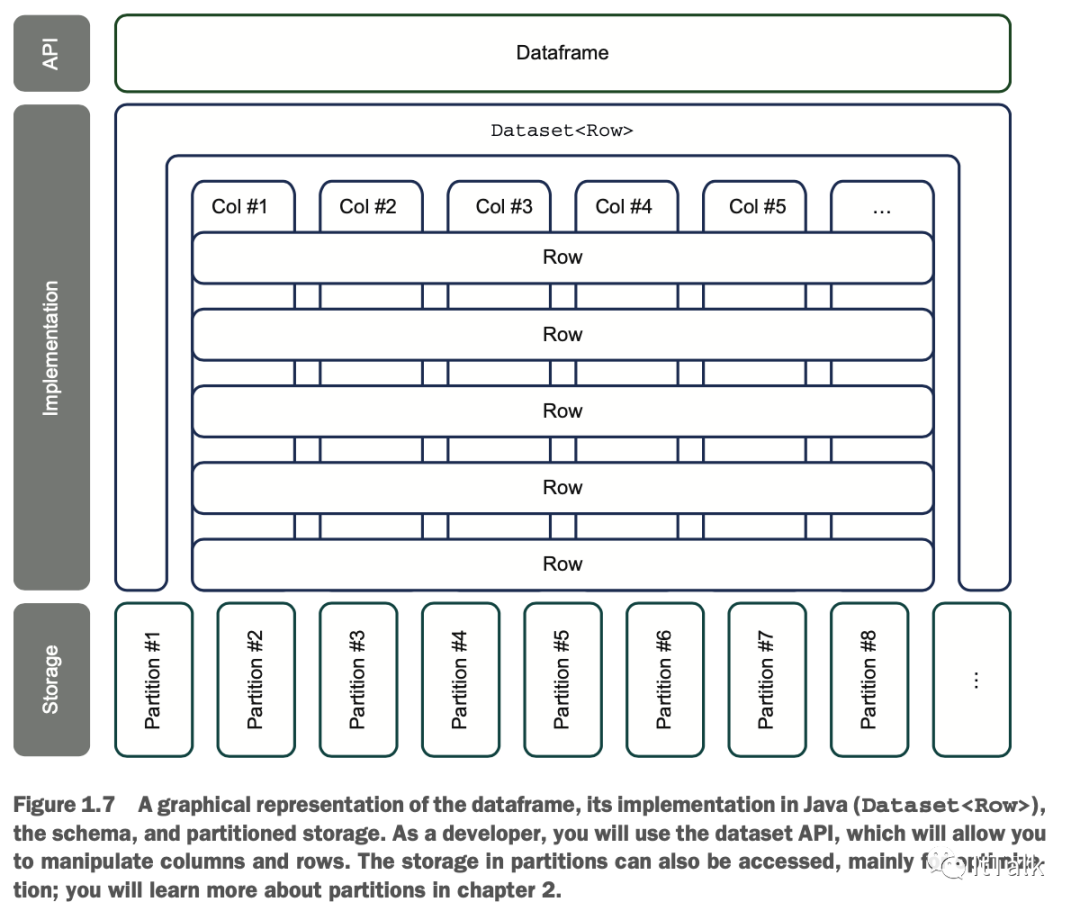
从Java角度看dataframe
数据可以通过一个简单的API访问。
你可以访问schema。这里有一些不同之处:
你不能用 next() 方法浏览它。
它的 API 可通过用户定义函数(UDFs)进行扩展。你可以编写或包装现有的代码并将其添加到Spark中。然后,这些代码将以分布式模式被访问。你将在第16章学习UDF。
如果你想访问数据,你首先要得到Row,然后用getter(类似于ResultSet)去访问该行的列。
元数据是相当基本的,因为在Spark中没有主键或外键或索引。在Java中,一个dataframe被实现为dataset
("行的数据集")。
从RDBMS角度看dataframe
数据是用列和行来定义的。
数据列是强类型。
下面是一些不同之处:
数据可以被嵌套,就像JSON或XML文档一样。第7章描述了这些文档的摄取,你将在第13章使用这些嵌套结构。
你不需要更新或删除整个行,而是创建新的数据框架。
你可以轻松地添加或删除列。
在dataframe中没有约束、索引、主键、外键或触发器。
dataframe的图形表示
你的第一个例子
安装基本软件,你可能已经有了。Git, Maven, Eclipse.
从GitHub下载代码。
执行这个例子,它将加载一个基本的CSV文件并显示一些行。
推荐软件
Apache Spark 3.0.0。
主要是macOS Catalina,但也可以在Ubuntu 14~18和Windows 10上运行。
Java 8 (尽管你不会使用很多在8版本中引入的新特性,比如lambda函数)。我知道Java 11是可用的,但大多数企业在采用较新的版本方面进展缓慢(而且我发现Oracle最近的Java策略有点令人困惑)。截至目前,只有Spark v3获得了Java 11的认证。示例将使用命令行或Eclipse。对于命令行,你可以使用以下方法。
Maven:本书使用的是3.5.2版本,但任何最近的版本都可以使用。
Git的版本是2.13.6,但任何最新的版本也可以使用。在macOS上,你可以使用Xcode打包的版本。在 Windows 上,你可以从 https://git-scm.com/download/win 下载。如果你喜欢图形用户界面(GUI),我强烈推荐Atlassian Sourcetree,你可以从以下网站下载。来自www.sourcetreeapp.com。项目使用Maven的pom.xml结构,它可以被导入或直接用于许多集成开发环境(IDE)。然而,所有的可视化示例都将使用Eclipse。你可以使用任何比4.7.1a(Eclipse Oxygen)更早的Eclipse版本,但Maven和Git的集成在Eclipse的Oxygen版本中得到了增强。我强烈建议你至少使用Oxygen版本,现在已经很老了。
下载代码
运行您的第一个应用程序
$ cd net.jgp.books.spark.ch01
$ mvn clean install exec:exec
您的第一个代码

虽然这个例子很简单,但你已经完成了以下工作。
安装了使用Spark所需的所有组件。是的,就是这么简单!)。
创建一个可以执行代码的会话。
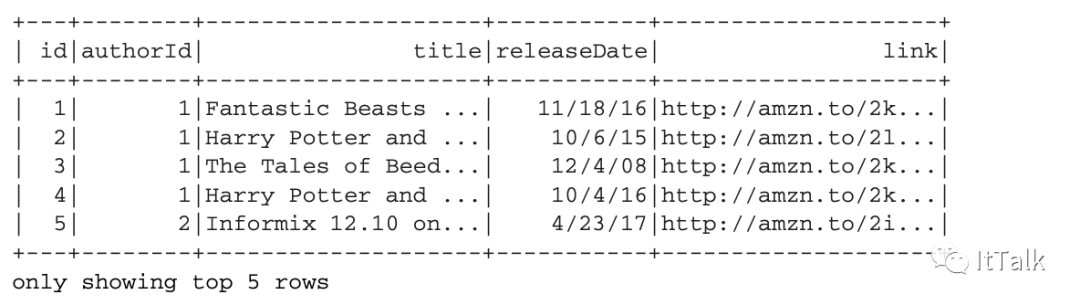
加载了一个CSV数据文件。
显示该数据集的五行。现在你已经准备好深入了解Apache Spark,并更多地了解引擎盖下的东西。
概要
Spark是一个分析操作系统;你可以用它以分布式的方式处理工作量和算法。而且它不仅适用于分析:你可以使用Spark进行数据传输、海量数据转换、日志分析等。
Spark支持SQL、Java、Scala、R和Python作为编程接口,但在本书中,我们主要关注Java(有时也关注Python)。
Spark的内部主要数据存储是dataframe。dataframe将存储和API结合起来。
如果你有JDBC开发的经验,你会发现与JDBC ResultSet有相似之处。
如果你有关系型数据库的开发经验,你可以把dataframe比作元数据较少的表。
在Java中,dataframe被实现为Dataset
。
你可以用Maven和Eclipse快速设置Spark。Spark不需要安装。
Spark不局限于MapReduce算法:它的API允许很多算法应用于数据。
流式处理在企业中的使用越来越频繁,因为企业希望能够使用实时分析。Spark支持流式分析。
分析已经从简单的连接和聚合发展到了现在。企业希望计算机能够替我们思考,因此Spark支持机器学习和深度学习。
图表是分析的一个特殊的场景,尽管如此,Spark支持他们。
