




概述
大数据计算服务MaxCompute(原名ODPS)是阿里云提供的一种快速、完全托管的EB级数据仓库解决方案,这里对MaxCompute的表创建做一个总结,方便后续在建表时,做参考。
创建方法
创建非分区表,语法:
create table [if not exists] <table_name>[(<col_name> <data_type> [comment <col_comment>], ...)][comment <table_comment>];
示例:
CREATE TABLE IF NOT EXISTS my_tab1 (id INT ,name STRING ,create_time DATETIME) COMMENT 'my_tab1';
基于已存在的表创建新表:
create table [if not exists] <table_name> [as <select_statement> | like <existing_table_name>];
示例:
#只创建对应的表CREATE TABLE IF NOT EXISTS my_tab2 like user_action_test;#创建对应的表并导入数据,但不会生成分区信息CREATE TABLE IF NOT EXISTS my_tab3 AS SELECT * FROM user_action_test WHERE ds = '20210319' limit 10;
创建分区表:
create table [if not exists] <table_name>[(<col_name> <data_type> [not null] [default <default_value>] [comment <col_comment>], ...)][comment <table_comment>][partitioned by (<col_name> <data_type> [comment <col_comment>], ...)];
分区表的分区层次不能超过6级超过7个字段报错提示如下: 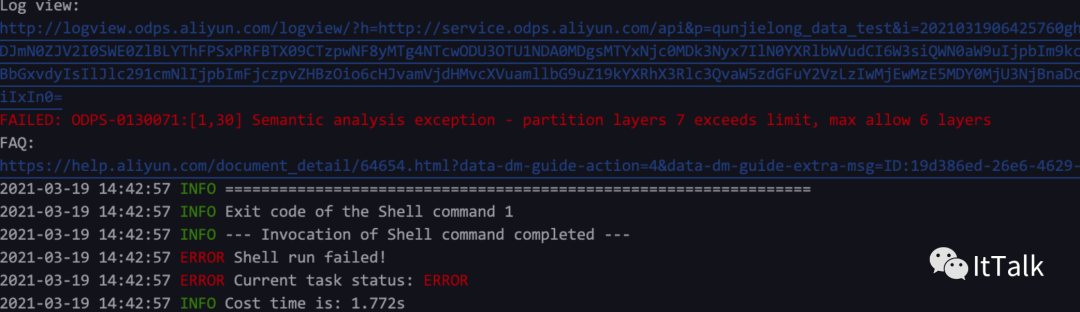
一张表允许的最大分区个数支持按照具体的项目配置,默认为6万个,示例:
CREATE TABLE my_tab4(id INT) PARTITIONED BY (a STRING,b STRING,c STRING ,d STRING ,e STRING,f STRING);
创建生命周期表 在MaxCompute中,每当表的数据被修改后,表的LastDataModifiedTime将会被更新。MaxCompute会根据每张表的LastDataModifiedTime以及生命周期的设置来判断是否要回收此表: 如果表是非分区表,自最后一次数据被修改开始计算,经过days天后数据仍未被改动,则此表无需您干预,MaxCompute会自动回收,类似drop table操作。 如果表是分区表,则根据各分区的LastDataModifiedTime判断该分区是否该被回收。分区表的最后一个分区被回收后,该表不会被删除。 days:使用lifecycle选项后,days必填,只能为正整数,单位为天。
create [external] table [if not exists] <table_name>[(<col_name> <data_type> [default <default_value>] [comment <col_comment>], ...)][comment <table_comment>][partitioned by (<col_name> <data_type> [comment <col_comment>], ...)]lifecycle <days>;
示例:
CREATE TABLE my_tab5(uid STRING,client_type STRING) LIFECYCLE 1;
创建聚簇表 聚簇表支持Hash聚簇表与Range聚簇表 Hash聚簇表 clustered by:指定Hash Key。MaxCompute将对指定列进行Hash运算,按照Hash值分散到各个Bucket中。为避免数据倾斜和热点,并取得较好的并行执行效果,clustered by列适宜选择取值范围大,重复键值少的列。此外,为了达到join优化的目的,也应该考虑选取常用的Join或Aggregation Key,即类似于传统数据库中的主键。 sorted by:指定Bucket内字段的排序方式。建议sorted by和clustered by保持一致,以取得较好的性能。此外,当指定sorted by子句后,MaxCompute将自动生成索引,并且在查询时利用索引来加快执行。 number_of_buckets:指定哈希桶的数量。该值必须填写,且由数据量大小决定。此外,MaxCompute默认支持最多1111个Reducer,所以此处最多只支持1111个哈希桶。您可以使用set odps.sql.reducer.instances=xxx;来提升这个限制,但最大不得超过4000,否则会影响性能。选择哈希桶数目时,请您遵循以下两个原则: 哈希桶大小适中:建议每个Bucket的大小为500 MB左右。例如,分区大小估计为500 GB,初略估算Bucket数目应该设为1000,这样平均每个Bucket大小约为500 MB。对于特别大的表,500 MB的限制可以突破,每个Bucket在2 GB~3 GB左右比较合适。同时,可以结合set odps.sql.reducer.instances=xxx;来突破1111个桶的限制。 对于join优化场景,去除Shuffle和Sort步骤能显著提升性能。因此要求两个表的哈希桶数目成倍数关系,例如256和512。建议哈希桶的数量统一使用2n,例如512、1024、2048或4096,这样系统可以自动进行哈希桶的分裂和合并,也可以去除Shuffle和Sort的步骤,提升执行效率。Range聚簇表 range clustered by:指定范围聚簇列。MaxCompute将对指定列进行分桶运算,按照分桶编号分散到各个Bucket中。 sorted by:指定Bucket内字段的排序方式,使用方法与Hash聚簇表相同。 number_of_buckets:指定哈希桶的数量。Range聚簇表的Bucket桶数没有Hash聚簇表的2n最佳实践,在数据量分布合理的情况下,任何桶数都可以。Range聚簇表的Bucket数不是必须的,可以省略,此时系统会根据数据量自动决定最佳的Bucket数目。 当Join或Aggregation的对象是Range聚簇表,且Join Key或Group Key是Range Clustering Key或其前缀时,可以通过控制Flag消除数据的重分布,即Shuffle Remove,提升执行效率。
create table [if not exists] <table_name>[(<col_name> <data_type> [not null] [default <default_value>] [comment <col_comment>], ...)][comment <table_comment>][partitioned by (<col_name> <data_type> [comment <col_comment>], ...)]--用于创建聚簇表时设置表的Shuffle和Sort属性。[clustered by | range clustered by (<col_name> [, <col_name>, ...]) [sorted by (<col_name> [asc | desc] [, <col_name> [asc | desc] ...])] into <number_of_buckets> buckets] ;
示例:
#Hash聚簇表CREATE TABLE IF NOT EXISTS my_tab7(uid STRING,client_type STRING,function_name STRING)PARTITIONED BY (ds STRING)CLUSTERED BY (function_name) SORTED BY (function_name) INTO 256 BUCKETS;#Range聚簇表CREATE TABLE IF NOT EXISTS my_tab8(uid STRING,client_type STRING,function_name STRING)PARTITIONED BY (ds STRING)RANGE CLUSTERED BY (function_name) SORTED BY (function_name) INTO 256 BUCKETS;#可省略BUCKETSCREATE TABLE IF NOT EXISTS my_tab9(uid STRING,client_type STRING,function_name STRING)PARTITIONED BY (ds STRING)RANGE CLUSTERED BY (function_name) SORTED BY (function_name);
文章转载自ItTalk,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
