




原理分析
HDFS HA的原理:
HDFS HA架构图
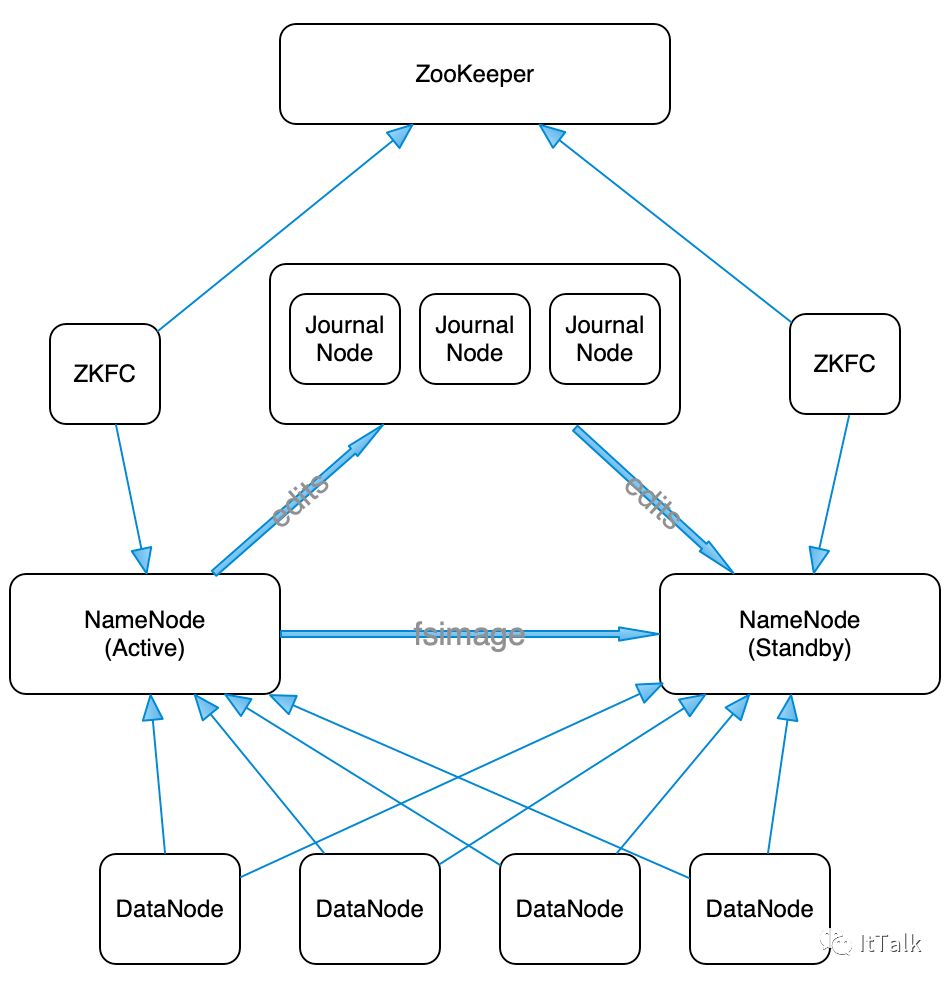
HDFS HA 架构中有两台 NameNode 节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
元数据文件有两个文件:fsimage 和 edits,备份元数据就是备份这两个文件。JournalNode 用来实时从 Active NameNode 上拷贝 edits 文件,JournalNode 有三台也是为了实现高可用。
Standby NameNode 不对外提供元数据的访问,它从 Active NameNode 上拷贝 fsimage 文件,从 JournalNode 上拷贝 edits 文件,然后负责合并 fsimage 和 edits 文件,相当于 SecondaryNameNode 的作用。最终目的是保证 Standby NameNode 上的元数据信息和 Active NameNode 上的元数据信息一致,以实现热备份。fsimage是HDFS文件系统存于硬盘中的元数据检查点,里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息;而edits保存了自最后一次检查点之后所有针对HDFS文件系统的操作,比如:增加文件、重命名文件、删除目录等等
在NameNode启动时候,会先将fsimage中的文件系统元数据信息加载到内存,然后根据eidts中的记录将内存中的元数据同步至最新状态;所以,这两个文件一旦损坏或丢失,将导致整个HDFS文件系统不可用。这两种文件存放在${dfs.namenode.name.dir}/current/目录下,文件名以edits和fsimage命名,该目录为NameNode上的本地目录。为了保证这两种元数据文件的高可用性,一般的做法,将dfs.namenode.name.dir设置成以逗号分隔的多个目录,这多个目录至少不要在一块磁盘上,最好放在不同的机器上,比如:挂载一个共享文件系统。
类似于数据库中的检查点,为了避免edits日志过大,在Hadoop1.X中,SecondaryNameNode会按照时间阈值(比如24小时)或者edits大小阈值(比如1G),周期性的将fsimage和edits的合并,然后将最新的fsimage推送给NameNode。而在Hadoop2.X中,这个动作是由Standby NameNode来完成。
Zookeeper 来保证在 Active NameNode 失效时及时将 Standby NameNode 修改为 Active 状态。
ZKFC(失效检测控制)是 Hadoop 里的一个 Zookeeper 客户端,在每一个 NameNode 节点上都启动一个 ZKFC 进程,来监控 NameNode 的状态,并把 NameNode 的状态信息汇报给 Zookeeper 集群,其实就是在 Zookeeper 上创建了一个 Znode 节点,节点里保存了 NameNode 状态信息。当 NameNode 失效后,ZKFC 检测到报告给 Zookeeper,Zookeeper把对应的 Znode 删除掉,Standby ZKFC 发现没有 Active 状态的 NameNode 时,就会用 shell 命令将自己监控的 NameNode 改为 Active 状态,并修改 Znode 上的数据。Znode 是个临时的节点,临时节点特征是客户端的连接断了后就会把 znode 删除,所以当 ZKFC 失效时,也会导致切换 NameNode。
DataNode 会将心跳信息和 Block 汇报信息同时发给两台 NameNode, DataNode 只接受 Active NameNode 发来的文件读写操作指令。
YARN HA原理:
YARN HA架构图
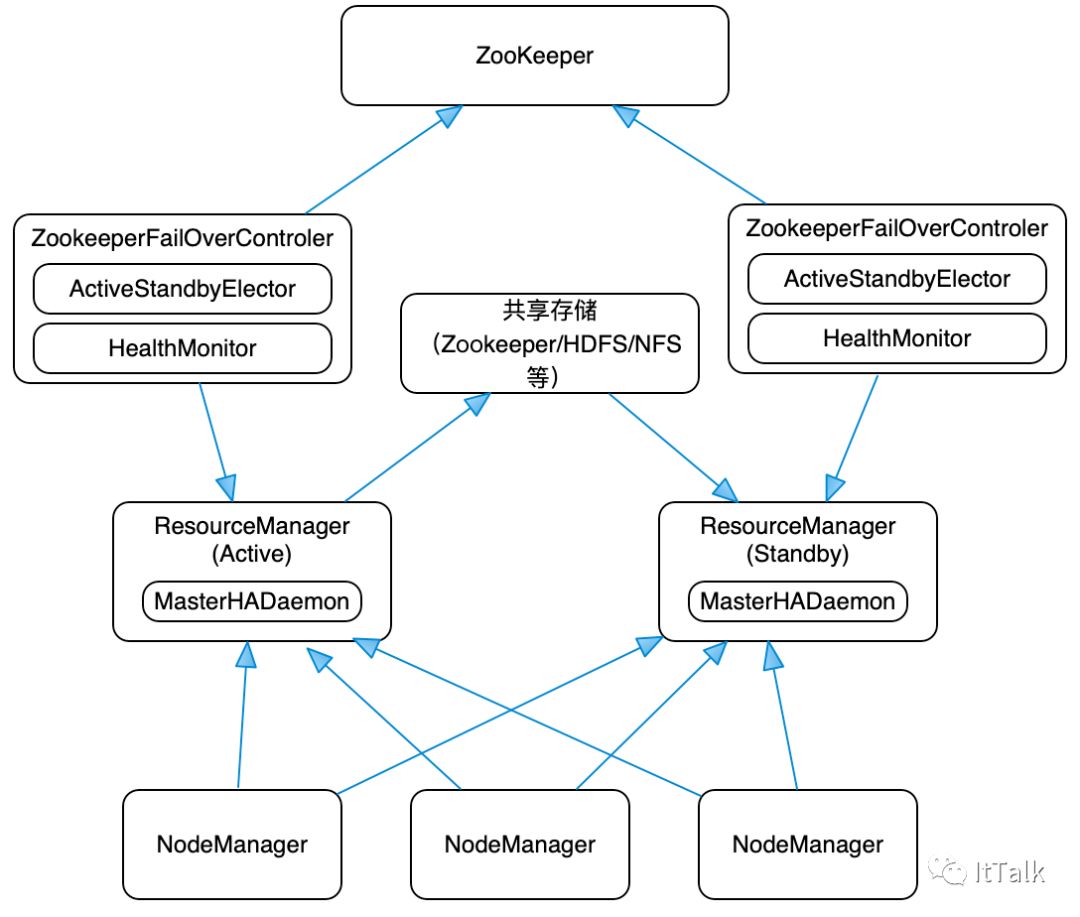
Hadoop2.4 版本之前,ResourceManager 也存在单点故障的问题,也需要实现HA来保证 ResourceManger 的高可也用性。
ResouceManager 从记录着当前集群的资源分配情况和 JOB 的运行状态,YRAN HA 利用 Zookeeper 等共享存储介质来存储这些信息来达到高可用。另外利用 Zookeeper 来实现 ResourceManager 自动故障转移。
MasterHADaemon:控制RM的 Master的启动和停止,和RM运行在一个进程中,可以接收外部RPC命令。
共享存储:Active Master将信息写入共享存储,Standby Master读取共享存储信息以保持和Active Master同步。
ZKFailoverController:基于 Zookeeper 实现的切换控制器,由 ActiveStandbyElector 和 HealthMonitor 组成,ActiveStandbyElector 负责与 Zookeeper 交互,判断所管理的 Master 是进入 Active 还是 Standby;HealthMonitor负责监控Master的活动健康情况,是个监视器。
Zookeeper:核心功能是维护一把全局锁控制整个集群上只有一个 Active的ResourceManager。
部署集群
参考:https://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-common/ClusterSetup.html
环境准备
1.三台操作系统(CentOS7.7),分别配置如下的hosts:
10.5.1.10 hadoop110.1.2.102 hadoop210.1.3.10 hadoop3
2.建立hdfs用户,并配置hadoop1,hadoop2,hadoop3三台机器的SSH免密码登录
分别在三台机器上执行ssh-keygen:
ssh-keygen
配置免密登录(三台机器都可以相互登录):
#分别在三台机器上执行以下三条命令,需要输入密码hdfs用户密码,如果SSH端口为非标准端口,可加-p选项:ssh-copy-id -i ~/.ssh/id_rsa.pub -p 7642 hdfs@hadoop1ssh-copy-id -i ~/.ssh/id_rsa.pub -p 7642 hdfs@hadoop2ssh-copy-id -i ~/.ssh/id_rsa.pub -p 7642 hdfs@hadoop3
Java版本,参考如下链接:https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions

3.准备zookeeper集群环境:略。我这里的地址为:
10.1.3.100:2181,10.1.3.100:2182,10.1.3.100:2183
4.服务器规划
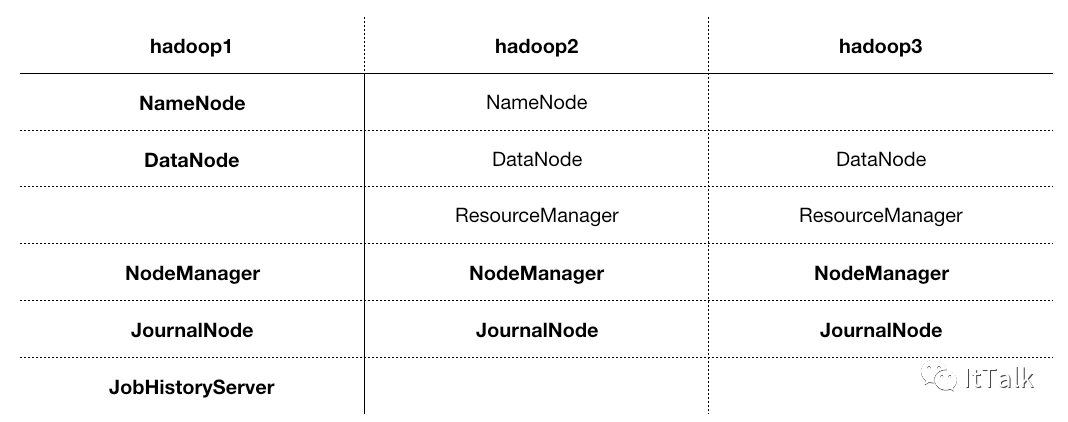
安装
1.解压安装包到安装目录,并配置环境变量
#三台机器分别执行如下命令:#解压tar -xf hadoop-3.1.3.tar.gz#配置软链ln -s hadoop-3.1.3 hadoop#如在~/.bash_profile加上以下配置:HADOOP_HOME=/data/hdfs/hadoopPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinexport PATH
2.配置(注:所有的配置可先在一台机器执行,后面再同步到其它节点) etc/hadoop/hadoop-env.sh:
#环境变量配置#配置JAVA_HOME,修改hadoop-env.sh文件中JDK路径:export JAVA_HOME=/usr/local/java#ssh为非标准端口,加如下选项export HADOOP_SSH_OPTS="-p 7642"#配置完可执行bin/hadoop测试一下
etc/hadoop/hdfs-site.xml:
#configuration中加入以下配置:<property><name>dfs.replication</name><value>2</value></property><property><!-- 为namenode集群定义一个name services --><name>dfs.nameservices</name><value>ns1</value></property><property><!-- nameservice 包含哪些namenode,为各个namenode起名 --><name>dfs.ha.namenodes.ns1</name><value>nn1,nn2</value></property><property><!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --><name>dfs.namenode.rpc-address.ns1.nn1</name><value>hadoop1:8020</value></property><property><!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 --><name>dfs.namenode.rpc-address.ns1.nn2</name><value>hadoop2:8020</value></property><property><!--名为nn1的namenode 的http地址和端口号,web客户端 --><name>dfs.namenode.http-address.ns1.nn1</name><value>hadoop1:50070</value></property><property><!--名为nn2的namenode 的http地址和端口号,web客户端 --><name>dfs.namenode.http-address.ns1.nn2</name><value>hadoop2:50070</value></property><property><!-- namenode间用于共享编辑日志的journal节点列表 --><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/jn</value></property><property><!-- journalnode 上用于存放edits日志的目录 --><name>dfs.journalnode.edits.dir</name><value>/data/hdfs/data/jn</value></property><property><!-- 客户端连接可用状态的NameNode所用的代理类 --><name>dfs.client.failover.proxy.provider.ns1</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence(hdfs:7642)</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hdfs/.ssh/id_rsa</value></property><property><name>dfs.namenode.name.dir</name><value>/data/hdfs/data/nn</value></property><property><name>dfs.datanode.data.dir</name><value>/data/hdfs/data/dn</value></property><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property>
etc/hadoop/core-site.xml:
<property><!-- hdfs 地址,ha中是连接到nameservice --><name>fs.defaultFS</name><value>hdfs://ns1</value></property><property><name>ha.zookeeper.quorum</name><value>10.1.3.100:2181,10.1.3.100:2182,10.1.3.100:2183</value></property>
etc/hadoop/yarn-site.xml:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>106800</value></property><property><!-- 启用resourcemanager的ha功能 --><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><!-- 为resourcemanage ha 集群起个id --><name>yarn.resourcemanager.cluster-id</name><value>yc1</value></property><property><!-- 指定resourcemanger ha 有哪些节点名 --><name>yarn.resourcemanager.ha.rm-ids</name><value>rm12,rm13</value></property><property><!-- 指定第一个节点的所在机器 --><name>yarn.resourcemanager.hostname.rm12</name><value>hadoop2</value></property><property><!-- 指定第二个节点所在机器 --><name>yarn.resourcemanager.hostname.rm13</name><value>hadoop3</value></property><property><!-- 指定resourcemanger ha 所用的zookeeper 节点 --><name>yarn.resourcemanager.zk-address</name><value>10.1.3.100:2181,10.1.3.100:2182,10.1.3.100:2183</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><property><name>yarn.log.server.url</name><value>http://hadoop1:19888/jobhistory/logs</value></property>
etc/hadoop/mapred-site.xml:
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value><description>MapReduce JobHistory Server IPC host:port</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:19888</value><description>MapReduce JobHistory Server Web UI host:port</description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/job/history/done</value></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/job/history/done_intermediate</value></property>
etc/hadoop/slaves:
hadoop1hadoop2hadoop3
3.三台机器分别启动journalnode:
hdfs --daemon start journalnode
4.在nn1节点上对namenode进行格式化,并启动namenode:
hdfs namenode -formathdfs --daemon start namenode#查看nn1 namenode的状态hdfs haadmin -getServiceState nn1
5.在nn2上同步节点1的元数据信息,并启动namenode:
hdfs namenode -bootstrapStandbyhdfs --daemon start namenode#查看nn2 namenode的状态hdfs haadmin -getServiceState nn2
6.切换nn1为active:
hdfs haadmin -transitionToActive nn1#查看 nn1现在的状态hdfs haadmin -getServiceState nn1
7.验证故障转移,并测试:
# 创建znodehdfs zkfc -formatZK# zkfs只会针对namenode监听,因此在nn1,nn2分别启动 zkfshdfs --daemon start zkfc# 通过 hdfs hadmin查看当前namenode节点的状态hdfs haadmin -getServiceState nn1hdfs haadmin -getServiceState nn2# kill掉一个namenode节点,再次查看节点状态
8.启动resource manager并验证HA:
#分别在haddop2,hadoop3启动resource manageryarn --daemon start resourcemanager#通过下面的命令查看resource manager的状态yarn rmadmin -getServiceState rm12yarn rmadmin -getServiceState rm13#kill掉active的节点,再次查看resource manager的状态
9.确认Resource Manager的HA功能正常后,分别在hadoop1,haddop2,hadoop3三个节点启动nodemanager
yarn --daemon start nodemanager
10.hadoop1机器上启动history server:
mapred --daemon start historyserver
总结
1.配置dfs.ha.fencing.methods时,如果使用非标准端口,需要在()中指出ssh的用户及端口号,形如:sshfence(hdfs:7642),这里的含义为:使用hdfs用户,ssh端口号为7642,对应的dfs.ha.fencing.ssh.private-key-files要配置hdfs用户的私钥 2.hadoop.tmp.dir这个配置需要注意,设置后NameNode 和 DataNode 的数据存在这个路径下,dfs.namenode.name.dir与dfs.datanode.data.dir就不会生效了
