




我在两年前写了关于CSI的一个系列,当时的四篇文章是基于版本1.0.0写的。虽然现在CSI spec最新的版本是1.3.0,但当时的四篇文章放在现在基本没有过时(当然有些细微的区别)。
CSI spec定义的workflow总体来说很清晰,并不复杂。但是由于Topology的存在,导致CSI的复杂度瞬间上了一个台阶。笔者在两年多前开发一个CSI Driver的时候,就意识到了这个问题,所以当时特意写了一篇《你真的理解Topology吗》,也是上面那个系列的第四篇。
本文再次系统阐述Topology,不过这次我尽量不涉及过多的细节问题,特别是我之前的系列文章里已经描述过的细节。
CSI部署方式
先简要回顾一下CSI Driver的部署方式。CSI Driver主要分两部分:CSI Controller和CSI Node Service。CSI Controller通常部署在master节点上,在无需HA的情况下,只需要运行一个实例。而CSI Node Service则通常以DaemonSet的方式运行,所以在每个worker节点上都运行一个实例。部署方式大致如下图所示:
这里说的CSI Controller/Node"实例",通常来说是指一个POD,当然也可以是直接运行的worker node上的一个process(进程)。
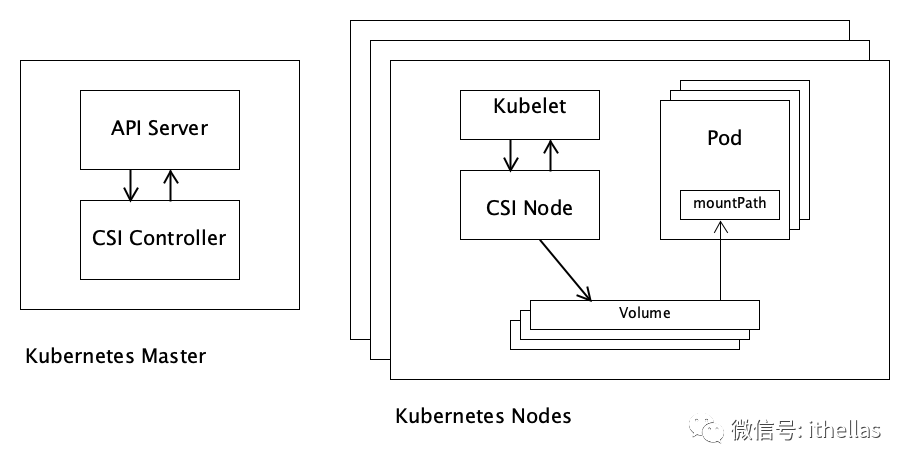
CSI Controller负责动态创建/删除volume,以及动态 attach/detach volume 到某个worker节点上。CSI Node Service主要负责将volume mount到某个POD内,以及执行相应的unmount操作。
CSI Controller和CSI Node Service通常也需要与一些sidecar containers一起部署,具体参考前面系列二那篇文章。
Topology的本质
Topology本质上要解决的问题是:确保workload所在的节点与对应的PV的Topology信息保持一致。
在cloud环境,通常会有多个region,每个region又会有多个zone。有些存储卷是无法跨region/zone访问的,例如某个POD调度到了node1,属于zone-a,而某个PV属于zone-b,那么该POD就可能无法正常访问这个PV;为了让POD能访问到PV,就要让POD和PV都属于同一个zone。这就是Topology这个feature要解决的本质问题。
要解决这个问题,CSI Driver要解决两个核心问题:
如何确定某个worker node的Topology
如何确定某个PV的Topology
如何定义Topology
Topology信息是通过下面几个label来定义的,前面两个已经不推荐使用了。
failure-domain.beta.kubernetes.io/region (deprecated)failure-domain.beta.kubernetes.io/zone (deprecated)topology.kubernetes.io/regiontopology.kubernetes.io/zone
例如下面这个节点属于region-1以及zone-c,
kubo@jumper:~$ kubectl describe node 66c619c2-d3a7-44e7-8785-2d7b51a1ef58Name: 66c619c2-d3a7-44e7-8785-2d7b51a1ef58Roles: <none>Labels: beta.kubernetes.io/arch=amd64beta.kubernetes.io/os=linuxfailure-domain.beta.kubernetes.io/region=region-1failure-domain.beta.kubernetes.io/zone=zone-c
下面这个PV同样属于region-1以及zone-c,
kubo@jumper:~$ kubectl describe pv pvc-6d82d016-af2f-4767-9aeb-dfbab2e79102Name: pvc-6d82d016-af2f-4767-9aeb-dfbab2e79102Labels: <none>Annotations: pv.kubernetes.io/provisioned-by: csi.test.example.comFinalizers: [kubernetes.io/pv-protection]StorageClass: example-vanilla-block-scStatus: BoundClaim: default/example-vanilla-block-pvcReclaim Policy: DeleteAccess Modes: RWOVolumeMode: FilesystemCapacity: 5GiNode Affinity:Required Terms:Term 0: failure-domain.beta.kubernetes.io/zone in [zone-c]failure-domain.beta.kubernetes.io/region in [region-1]
接下来分描述如何确定node和PV的topology信息。
确定worker节点的topology
worker 节点的topology信息主要是CSI Node Service中的方法NodeGetInfo来实现的。
因为Node Service以DaemonSet方式运行,所以每个worker节点上都会运行一个Node Service的实例(POD)。Kubelet调用CSI Node Service的NodeGetInfo方法时,返回的topology就决定了当前worker节点的topology信息。
NodeGetInfo方法的返回值(包括topology),是返回给kubelet。Kubelet收到之后,会动态给当前的worker节点打上相应的label。
至于如何实现NodeGetInfo这个方法,那就是CSI Driver的开发人员要考虑的事情。一般来说,需要从IaaS平台获取worker节点的真实的topology信息。
worker节点的topology确定了,那么如何确定PV的topology呢?
确定PV的topology
确定PV的topology就复杂多了,这也是导致topology复杂的根源。
这里要明确一点,external-provisioner在调用CSI Controller的CreateVolume方法时,会传入topology信息。所以主要是靠external-provisioner来确定PV的topology,当然也要看CSI Driver如何使用传入的topology信息。
我们知道,StorageClass中的volumeBindMode有Immediate和WaitForFirstConsumer两种模式。在这两种模式下,确定PV的topology的逻辑会有所不同。而external-provisioner配置不同的启动参数,也会对PV的topology信息产生不同的影响。
综合起来,有下面六种场景,每种场景下PV的topology的确定方式都不同。
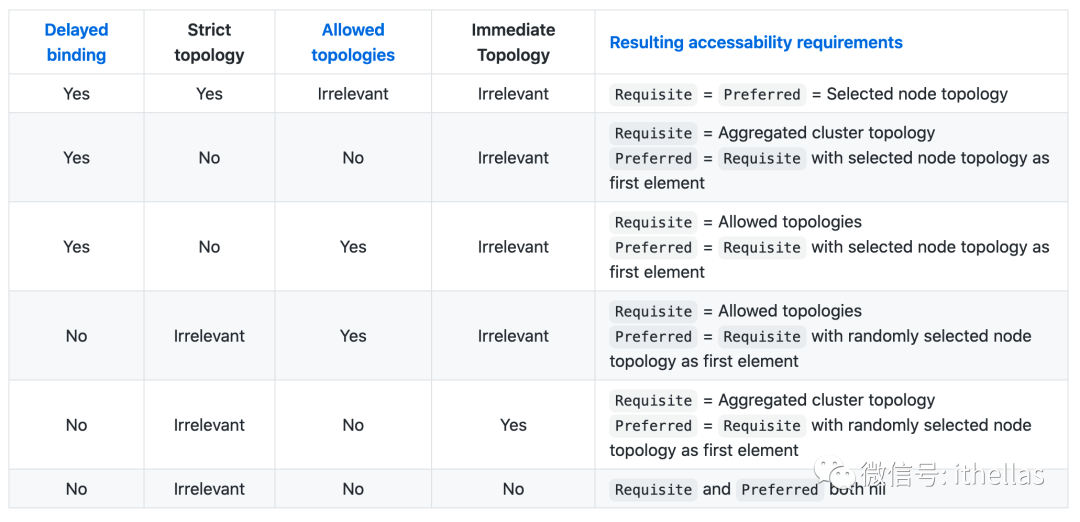
这个表格来自下面的链接:
https://github.com/kubernetes-csi/external-provisioner/blob/master/README.md#topology-support
Delayed binding为Yes时,表示StorageClass中的volumeBindMode采用的是WaitForFirstConsumer,No自然表示的是Immediate。默认是Immediate。
Strict topology为Yes时,表示external-provisioner启动时配置下面的参数,
--strict-topology
Immediate Topology为No时,表示表示external-provisioner配置了下面的启动参数。注意这个参数的默认值是true,所以如果想enable这个功能,可以压根就不配置这个参数。
--immediate-topology=false
另外,对于"Aggregated cluster topology"这个术语/过程,我估计有人不理解,所以还是要解释一下。其实主要是分两步,首先是从CSINodes对象中获取topologyKeys。例如下面这个CSINode对象中包含两个topologyKey,
kubo@jumper:~$ kubectl get csinodes 66c619c2-d3a7-44e7-8785-2d7b51a1ef58 -o yamlapiVersion: storage.k8s.io/v1kind: CSINodemetadata:creationTimestamp: "2021-02-25T05:57:05Z"managedFields:......spec:drivers:- name: csi.test.example.comnodeID: 66c619c2-d3a7-44e7-8785-2d7b51a1ef58topologyKeys:- failure-domain.beta.kubernetes.io/region- failure-domain.beta.kubernetes.io/zone
然后就是找出所有包含这两个label的worker节点,并提取出每个节点中的topology信息(region和zone),最后汇总起来,就得到了"Aggregated cluster topology"。
上面表格中的每一项都解释清楚了,那这个表格所要表达的思想自然就清晰了。这个就留给读者自行去慢慢体会:)。有问题欢迎留言讨论。
确保POD与PV的topology一致
POD和PV的创建是有先后顺序的。注意,这里说的POD是指使用了对应PV的POD。
如果PV先创建,POD后创建(Immediate模式),那么Kubernetes会保证将POD调度到与PV topology(Node Affinity中包含的信息)匹配的worker节点。
如果POD先创建,PV后创建(WaitForFirstConsumer),那么Kubernetes同样会保证在POD所在Node的topology范围内创建PV。具体体现在调用CSI Driver的CreateVolume方法时,传入的参数中包含Node(POD被调度到的node)的topology信息。
总结
本文对CSI spec中的Topology的机制做了全面的总结。关键是要理解“确定PV的topology”的那个表格。有任何疑问,欢迎留言讨论!
References
https://kubernetes.io/docs/concepts/storage/
https://kubernetes-csi.github.io/docs/
https://github.com/kubernetes-csi/external-provisioner
https://github.com/kubernetes-csi/node-driver-registrar
https://github.com/container-storage-interface/spec/blob/master/spec.md
--END--
