排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
DASFAA 2021: 基于自定中心星状图和注意力机制的行人轨迹预测(附论文下载)
DASFAA 2021: 基于自定中心星状图和注意力机制的行人轨迹预测(附论文下载)
时空实验室
2021-09-18
1044
本文将介绍电子科技大学数据与智能实验室团队发表在DASFAA 2021 (International Conference on Database Systems for Advanced Applications, CCF B类国际学术会议)上的论文《SCSG Attention: A Self-Centered Star Graph with Attention for Pedestrian Trajectory Prediction》,作者:陈旭,刘顺程,许志,刁宇鹏,吴少智,郑凯,苏涵。
1 背景
在行人轨迹预测问题中,因为行人的行走方式往往受到多种因素的影响,例如:在不拥挤的道路里往往基于自己的行走习惯行走,而在拥挤的道路里则因为受到其他行人或静态障碍物的影响会改变行走方式。因此,如何让机器学习行人的历史轨迹,并且从行人与环境的交互中提取特征进而预测行人走路的轨迹成为了一个难题。目前,预测行走轨迹的方式可以分为四类,分别为:基于规则的方法、基于网格的方法、基于注意力的方法和基于时空图的方法。
(1) 基于规则的方法:Social Force是一种基于规则来预测行人轨迹的方法。它将行人之间的交互归结为两种作用力:吸引力和排斥力。基于两个行人的一些基本信息来计算这两种力,进而预测出行人轨迹。但是这种方法很难考虑周全所有的情况。同时,这种方法也不具有延展性,当数据集有较大变化(例如环境发生较大的变化)时,它很难做出精确的预测,因此无法很好地推广到现代数据集。
(2) 基于网格的方法:Social LSTM是一项开拓性的工作,它使用RNN模型进行预测,并且还利用基于网格的池化层来聚合多个交互。它还有很多类似的工作,例如卷积池化层和Social GAN。但是,基于网格的测量效率不高。它为了包含道路上所有的行人,需要建立巨大的网格。而很多时候网格是非常稀疏的,稀疏的网格占用了大量的存储空间,因此需要大量的计算能力并需要遍历网格才能实现测量。另外,这种方法将行人的影响按照相同的权重结合,易造成周围行人的影响因子相似,导致难以对行人的交互作出准确的衡量。
(3) 基于注意力的方法:为解决不同行人或障碍物重要性不一样的问题,Sophie在模型中加入了global attention。但是,global attention忽略了对自己历史轨迹的注意力以及其他行人的多重潜在信息。换句话说,他对其他行人的学习不够充分。
(4) 基于时空图的方法:SAPTP使用基于时空图的方法来关联时间和空间信息并获得了不错的结果。尽管如此,他们还是使用完全图来模拟人与人之间的交互,完全图连接所有人之间的交互,这将花费多余的计算能力。于是在该论文中,作者旨在解决上述方法存在的问题,从而提升行人轨迹预测的准确率。
2 问题定义
给定一个目标行人
k
,以及它的历史轨迹
,同时给出他附近的行人
i
的历史轨迹
,预测目标行人
k
的未来轨迹
。
3 框架方法
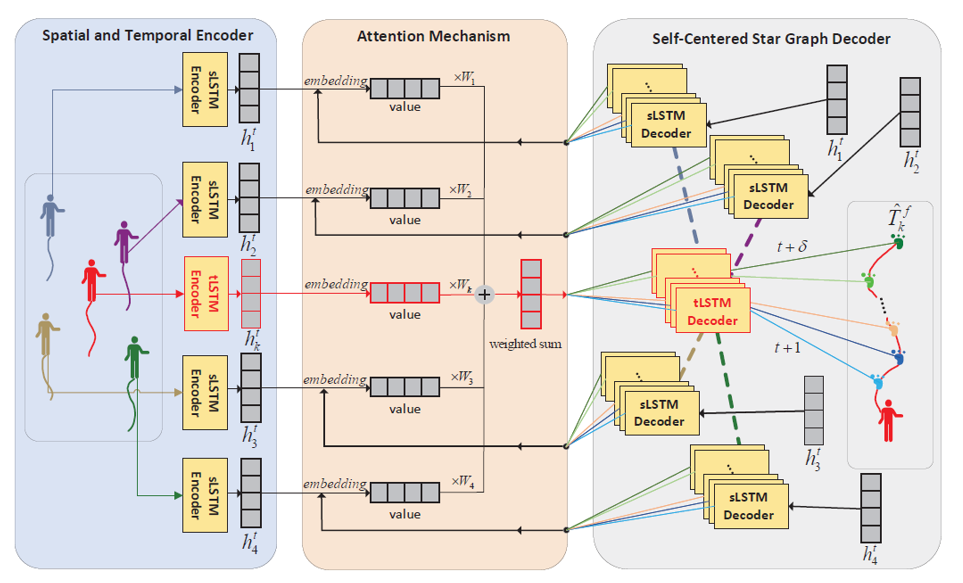
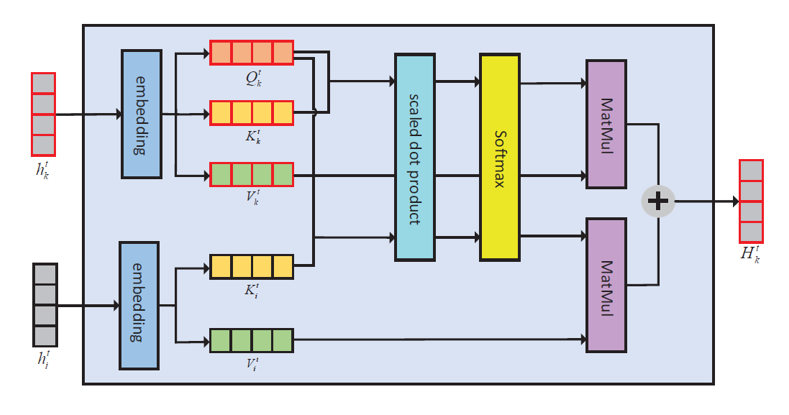
作者提出的SCSG的模型结构如图1所示,其包含三个组件,即:(1)空间和时间编码器;(2)多头注意力机制;(3)自定星状图解码器。
图1
下面分别阐述三个组件的功能:
(1)空间和时间编码器:行人位置描述基于笛卡尔坐标,目标行人
k
的历史轨迹包含时间信息,其他行人的历史轨迹被视为空间信息。长短期记忆网络(LSTM)在序列存储和编码方面有非常好的表现。对于此特定问题,将时间信息和空间信息分别编码。在空间和时间编码器中,该模型将目标行人的历史轨迹作为时间信息进行编码,同时将目标行人周围的行人轨迹作为空间信息进行编码,并且空间信息的学习不与时间信息的学习共享参数,而是在周围的行人之间共享参数。
(2)多头注意力机制:在该框架中,多头注意力被用来模仿要预测的人对附近人的注意力。因此,目标行人附近的不同行人将通过唯一的权重进行测量。多头注意力可以模拟来自多种潜在推理的注意力,可以大幅增强模型的鲁棒性。
在注意力机制中,如下图所示,框架将计算目标行人对周围每一个行人编码后的向量的注意力权重,具体为:将时间信息嵌入到三个向量中,即查询向量
Q
,关键词向量
K
和价值向量
V
,同时将空间信息嵌入到两个向量关键词向量
K
和价值向量
V
。嵌入的时间信息和空间信息将做内积并通过分类激活函数得到注意力权重。
图2
最后,将这些注意力权重进行加和。需要说明的是,这种注意力将会计算多次,每一次的注意力层作为一个模型学习到的隐藏特征。因此,模型能更完备的学习到行人的交互。
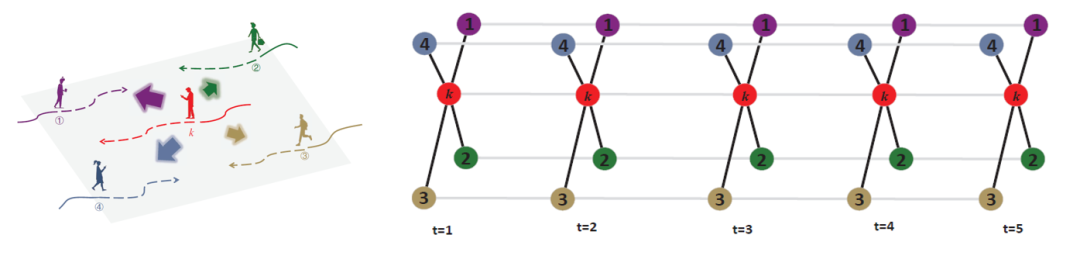
(3)自定星状图解码器:为了更好的将时间与空间的信息结合,该方法先建立星状时空图,再以其对注意力权重的加和进行解码,星状时空图的建立方式如下:
(a)将目标行人
k
及其周围的行人
i
加到顶点集
V
。例如下图中的示例,开始时有五个顶点
V
k
、
V
1
、
V
2
、
V
3
、
V
4
。然后将从
V
k
到
V
i
以无向边相连,用
e
(
k
,
i
)表示,就完成了一个平面自定中心星图;
(b)重复步骤(a)4次(如下图所示),可以得到一个三维自中心星图。
图3
(c)在每个帧
t
到
t
+1分别添加从
V
i
到
V
i
和从
V
k
到
V
k
的无向边,分别用
e
(
i
,
i
)和
e
(
k
,
k
)表示。这就是上图中的示例变为拓扑结构的方式。
边
e
(
k
,
k
)表示时间信息的传播,边
e
(
i
,
i
)表示空间信息的传播,这两个边都用LSTM传递信息。边
e
(
k
,
i
)代表从行人
k
到行人
i
的注意力(用多头注意力机制计算)。
最后,在每帧
t
处,边
e
(
k
,
i
)代表从行人
k
到行人
i
的注意力,目标行人每个时刻的隐藏状态将与三个向量结合输出的矩阵
W
o
相乘,从而生成目标行人的预测位置(一次输出一个预测位置)。
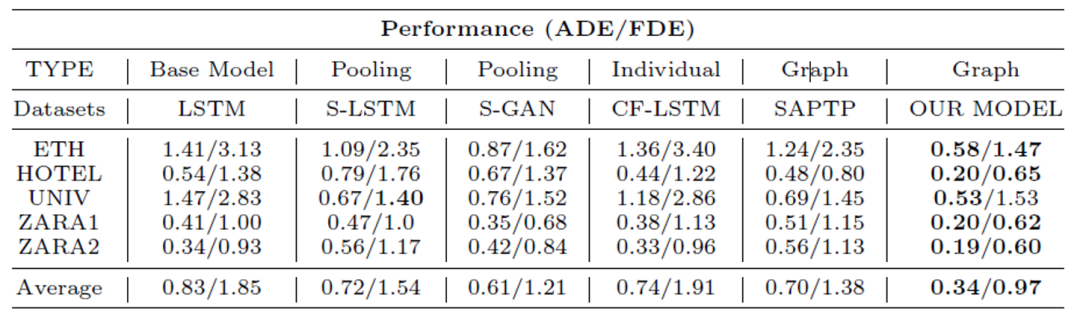
4 主要实验结果
表1
图4
实验采用了两个公开的行人轨迹数据集分别是ETH (ETH + hotel)和UCY (univ+zara1+zara2)。评价指标分别是ADE (平均位移偏差)和FDE (最后一个预测点的位移偏差)。如表1所示,作者将SCSG与5个方法 (LSTM, S-LSTM, S-GAN, CF-LSTM, SAPTP)进行了对比,可以看到SCSG在多个数据集上的ADE和FDE都小于对比方法,证明了模型的有效性。
此外作者也给出了一些可视化的预测轨迹案例,如图4所示,SCSG的预测轨迹与ground truth轨迹也非常的接近。
5 结论
SCSG模型设计了自定中心星状图,旨在同时捕获时空特征。在星状图中产生的计算量更少。相比采用完全图的方式来说,它加速了模型迭代速度并且没有牺牲模型的准确率,从而可以在更短的时间内产生准确的结果。并且在这之中,空间信息的学习不与时间信息的学习共享参数,而是在相邻行人之间共享参数,因为相邻行人一起代表目标行人的背景信息。如此一来,在模型中也减少了参数的学习,增加了周围行人之间的联动性。此外利用多头注意力机制来模拟行人的真实注意力,这种注意力模拟机制能自动提取隐藏的特征。实践表明,SCSG模型是行之有效的,尽可能多地重构了现实生活中的复杂情况和社会规范。注意机制在SCSG模型中起着重要作用,不同的注意机制具有不同的性能。而SCSG采用的多头注意力之所以有效,一个重要的原因是多头注意力机制可以关注周围行人的微妙线索,而其他的注意力机制都只能关注部分信息,从而导致某些重要信息的疏忽。
关注公众号,回复“DASFAA2021SCSG”,下载论文
数据库
文章转载自
时空实验室
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨

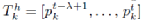 ,同时给出他附近的行人i的历史轨迹
,同时给出他附近的行人i的历史轨迹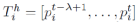 ,预测目标行人k的未来轨迹
,预测目标行人k的未来轨迹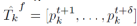 。
。







 ,同时给出他附近的行人i的历史轨迹,预测目标行人k的未来轨迹。
,同时给出他附近的行人i的历史轨迹,预测目标行人k的未来轨迹。