相似轨迹搜索是一个非常基础的问题,比较两条轨迹之间的相似性具有非常实际的应用。在过去,通常这类问题都是比较两条完整的轨迹之间的相似性。然而,南洋理工大学的研究人员在VLDB2020上发表了《Efficient and Effective Similar Subtrajectory Search with Deep Reinforcement Learning》,指出许多应用程序是将子轨迹相似性搜索(similar subtrajectory search,SimSub)作为基本分析单元。SimSub相比于传统的相似轨迹搜索,其以更细粒度的方式捕获轨迹的相似性,最终返回的结果是数据轨迹(data trajectory)与给定的查询轨迹Tq最为相似的一部分(即子轨迹)。针对SimSub问题,该论文提出了一种有效且高效的相似子轨迹搜索算法--DQN。并在真实数据集上验证了其有效性及高效性。

一、背景介绍
轨迹数据就是时空环境下,通过对一个或多个移动对象运动过程的采样所获得的数据信息,这些采样点数据信息根据采样先后顺序构成了轨迹数据。例如一辆携带GPS的车辆,固定采样频率记录GPS终端所在位置的经纬度信息,这些信息构成的数据用来描绘该车辆在这段时间的轨迹信息。这类轨迹数据是无处不在的,近些年,它被用于各种类型的数据分析,比如聚类和相似性搜索等。但现有的大多数研究都将轨迹作为一个整体进行分析,忽略了局部相似的问题。例如,考虑data trajectory(T)和查询轨迹Tq,当作为一个整体考虑时,T与Tq基于某些轨迹相似性度量,它们并不相似,但T的某些部分与查询轨迹非常相似。使用传统的相似轨迹搜索查询,尽管其中T一部分与查询轨迹Tq非常相似,T也会被排除。
因此,为解决这种现象,有一些研究人员尝试在查询过程中,将子轨迹视为基本单元,并且将查询轨迹Tq作为一个整体进行分析。这种处理方式相比于传统的相似轨迹搜索,它能以更细粒度的方式捕获轨迹的相似性。
在相当多的实际应用中,子轨迹被视为分析的基本单元,例如子轨迹搜索、子轨迹连接、子轨迹聚类等。其中一个应用是对体育比赛数据的子轨迹搜索查询。在足球和篮球等运动中,现在的一种常见做法是使用一些特殊用途的摄像机或GPS设备跟踪球或球员的运动过程,并将生成的轨迹数据用于捕获精彩时刻的语义或进行不同类型的数据分析。此类体育比赛数据的一个典型任务是从比赛数据库中搜索比赛的一部分或分段,判断在这段某球员的轨迹或球的轨迹与给定的查询轨迹是否相似。这项任务本质上是搜索相似的子轨迹。另一个潜在的应用是绕行路线检测。它首先收集乘客提供的绕行路线轨迹(作为查询轨迹Tq),然后搜索出租车路线(作为T)的子轨迹,若这些子路段与绕行路线轨迹Tq相似,则判定该出租车绕行了。
二、问题定义
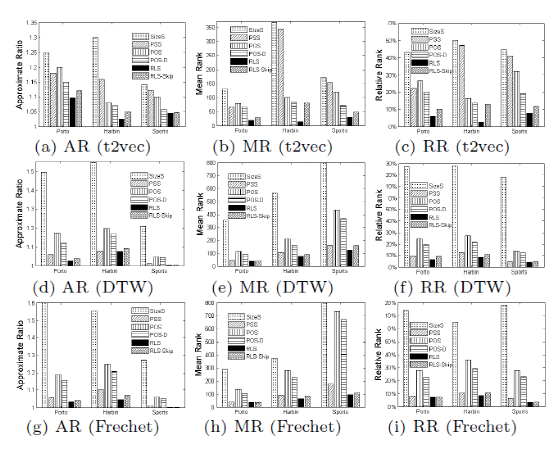
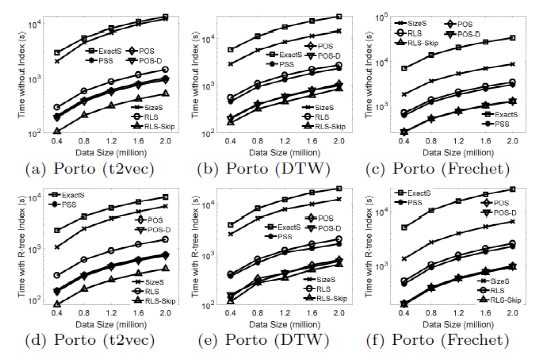
给定一条数据轨迹 T=<p1, p2,… pn-1, pn>和一条查询轨迹Tq=<q1, q2,…qm>,相似子轨迹搜索(SimSub)问题是查找一个T的子轨迹T[i, j],其中i和j 属于[1, n],这段轨迹与查询轨迹最为相似。即θ(T[i, j], Tq)最大化,θ为相似性度量。该论文提供了三个表示两条轨迹相似度的指标,分别是t2vec,DTW和Frechet。其中t2vec通过使用一个循环神经网络RNN得到一条sequence轨迹的embedding表示形式。通过计算两条轨迹的embedding距离得到两轨迹的相似度。由于查询轨迹Tq在搜索过程中是不变的,所以只需要生成一次embedding,因此在三个方法中,t2vec是时间复杂度最低的相似度检测方法。 该论文的深度强化学习搜索框架实际上是一个分割模型。即模型遍历轨迹的每一个点,由强化学习的agent来决策该点是否分割。State:是一个三元组triplet(θbest,θpre,θsuf),其中θbest表示目前为止所有的分割得到的子轨迹与查询轨迹的最佳相似度;θpre则表示当前遍历的节点,与前一个分割节点所构成的子轨迹与查询轨迹的相似度;θsuf表示当前遍历的节点,与该轨迹最末端节点构成的子轨迹与查询轨迹的相似度。Actions:该问题一共有两个action,分割或者不分割,即0或1的action集合。Transition:由于在分割轨迹的过程中,当执行一个action后,状态转移概率是未知的,所以此问题没有transition的具体形式。Reward:reward是对agent当前执行的决策的一个评价,该论文是将执行action之后与之前的最佳相似度的差值作为reward。如图1,该方法通过使用两个网络(主网络Q以及目标网络Q’)来完成对policy的优化。Agent从Environment中获取当前节点的state,并根据Q函数最大化的结果来输出action(分割或者不分割),之后根据上述定义,agent将会得到一个reward,并且state将会更新到state’。由此获得一个四元组(s,a,r,s’),并将这四元组存往经验回放池,在训练时,随机从回放池中提取一个batch的样本进行训练。在一个epoch完成之后将主网络Q的参数复制给目标网络Q’完成一个epoch的训练操作,当所有epoch完成后最终得到的网络Q可以根据输入的当前State精确输出reward最大的action。Reinforcement Learning based Search Algorithm(RLS):按照上述训练得到的网络Q作出对当前遍历点需执行的决策,与传统模型中分割的过程类似,不过分割的决策是由强化学习的agent作出。RLS with skip:为了增加分割决策的效益,在RLS的基础上增加了另一个action:skip,该行为跳过一些节点不再进行分割决策,即不会使用网络对其是否分割的决策做计算,跳过后其效果和不分割结果上是完全一样的。图2所示为RLS-Skip案例,给定一条数据轨迹T=<p1,p2,…p5>和查询轨迹Tq,分别将h(头节点),Tbest(最佳子轨迹),θbest(最佳相似度)初始为0、空集、0。RL-agent依次遍历T的每一个点。例如,当遍历到p1时,s1为(0,0.124,0.150),将s1输入到强化学习模型,agent作出的决策是分割,此时便可更新h,Tbest,θbest的值,依次类推,当遍历完轨迹T的最后一个节点后,此时的Tbest即为强化学习模型找到与查询轨迹Tq最相似的子轨迹。图2:the process of RLS-Skip该论文使用Porto,Harbin,STATS SPORTS三个数据集执行实验,其囊括了车辆轨迹以及人类轨迹多种轨迹数据。作者将强化学习的方案与多个传统的方案进行了比较:(1)SizeS:考虑数据轨迹T的所有子轨迹(假设T的长度为n,即有n(n+1)/2条子轨迹),该算法只考虑满足预先定义好的Size范围内的子轨迹;(2)PSS:一个贪心算法,依次遍历所有的节点,一直维持最优结果,当遍历结束后,返回当前维持的最优结果;(3)POS:是PSS的一个变种,其只考虑当前遍历节点的前半部分子轨迹。(4)POS-D:是POS的一个变种,当PSS找到一个最相似的子轨迹时,POS-D继续向后遍历D个点。Approximate Ratio(AR):定义为由近似算法求出的解,与精确算法求出的解不同的比例。AR越小表示算法越好。Mean Rank(MR):将数据轨迹的所有子轨迹按照它们与查询轨迹的不同程度的升序进行排序。MR被定义为由近似算法返回的解的排名。Relative Rank(RR):RR是MR的标准化版本,由数据轨迹的子轨迹总数决定。MR或RR越小,表示算法越好。图3给出了各个搜索算法在三个数据集上不同评价指标的实验结果,证明了强化学习算法的有效性。图4给出了各个搜索算法在Porto数据集上的查询效率,证明了强化学习模型的高效性。图3:the effectiveness of RLS关注公众号,回复“VLDB2020SimSub”,下载论文