




简单动态字符串
双向链表
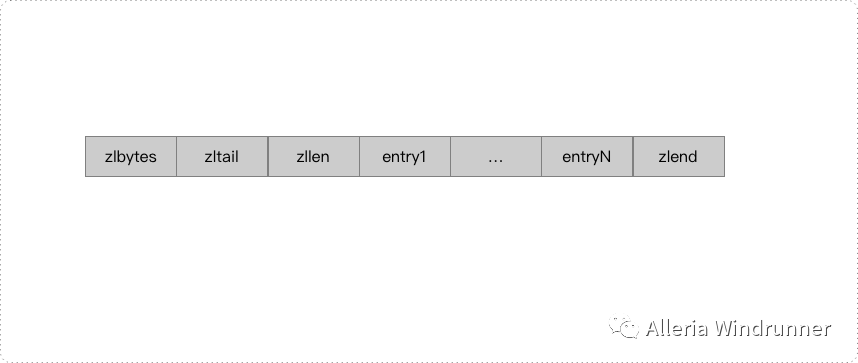
压缩列表
哈希表
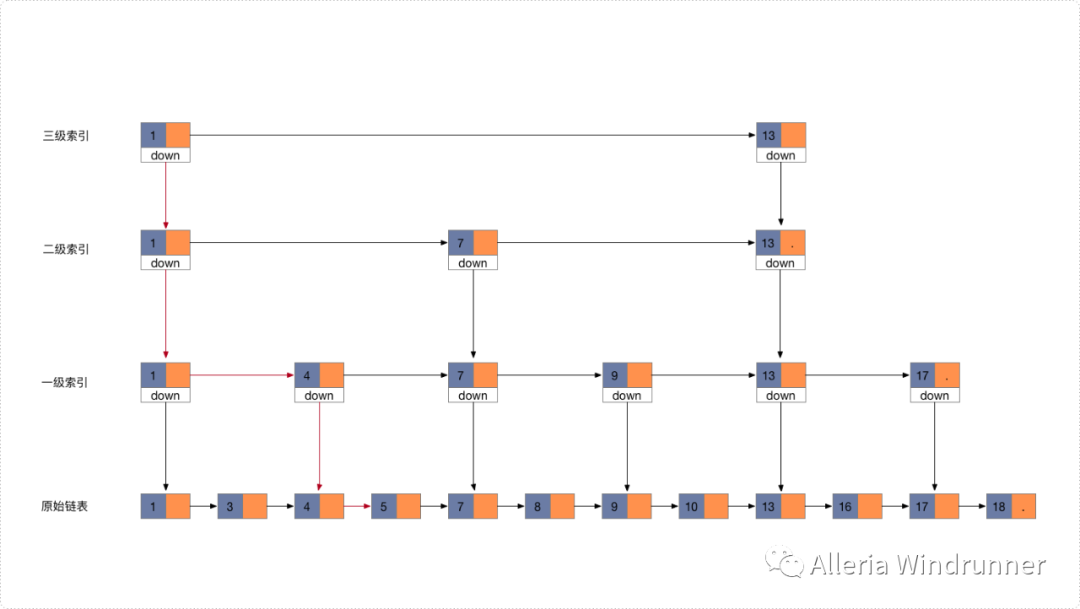
跳表
整数数组
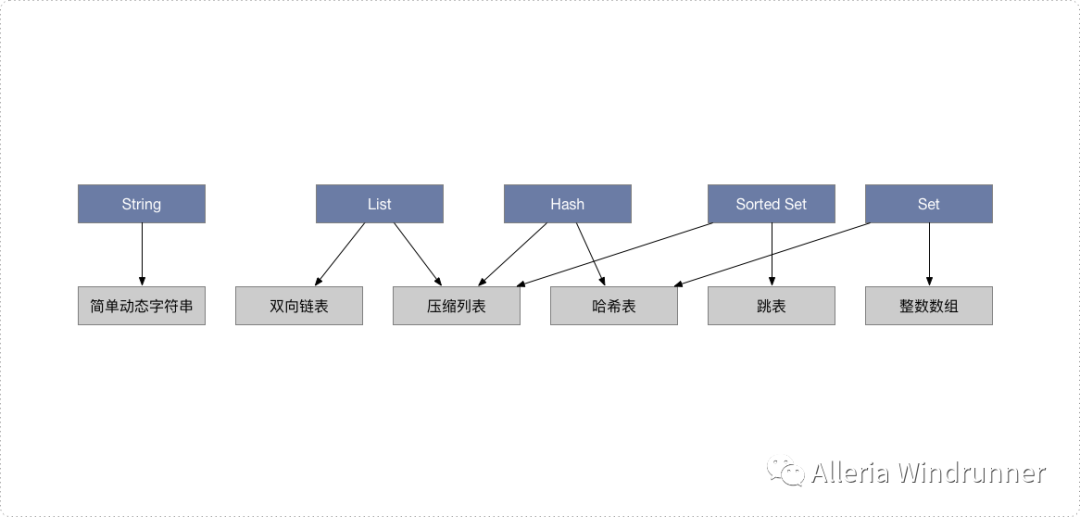
这些数据结构都是值的底层实现,键和值本身之间用什么结构组织?
为什么集合类型有那么多的底层结构,它们都是怎么组织数据的?
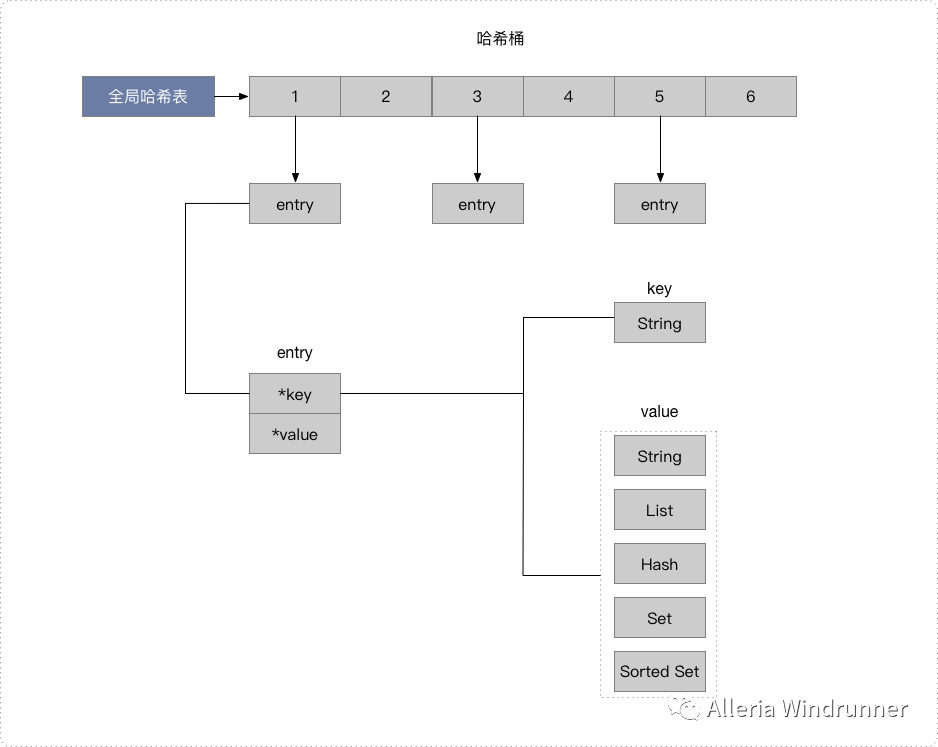
键和值用什么结构组织?
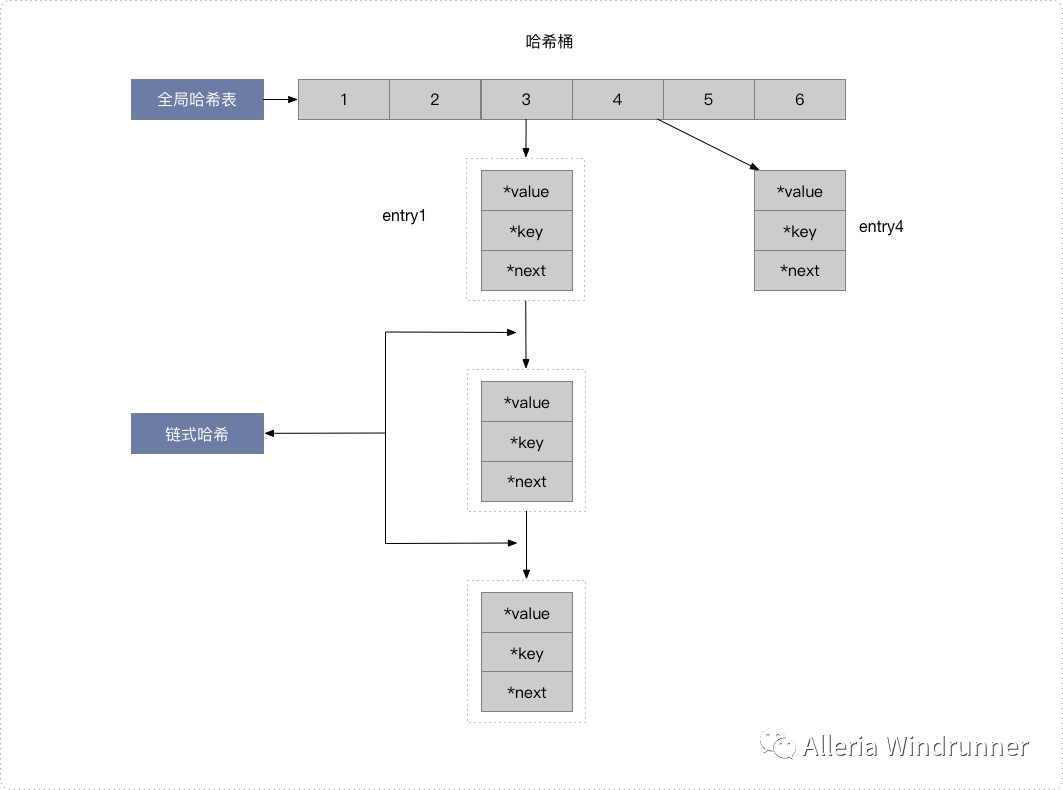
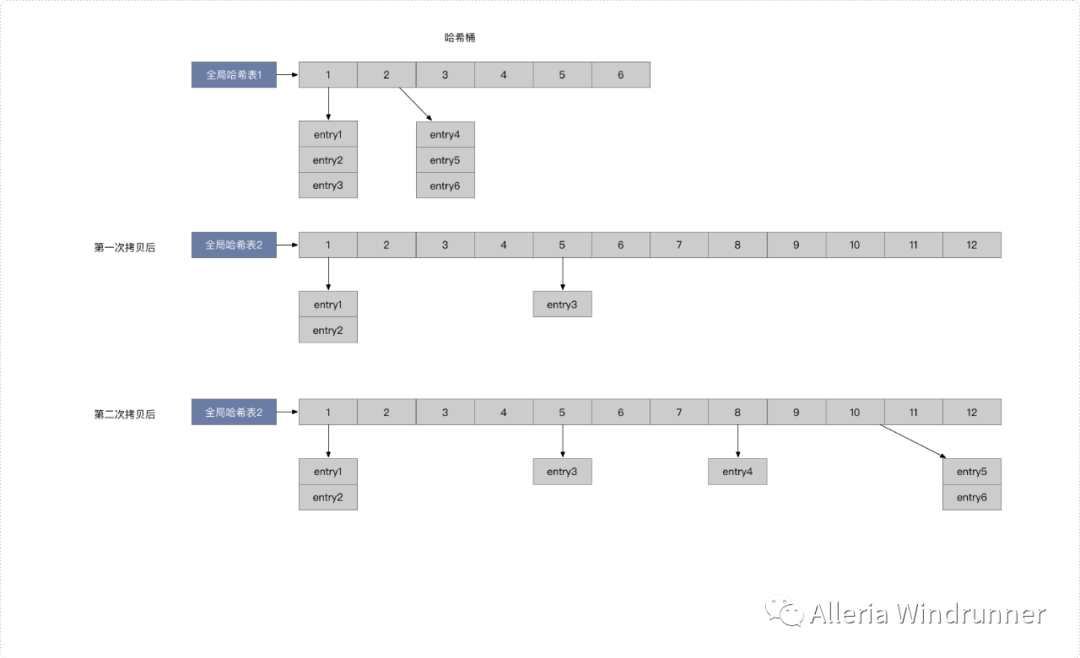
给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
释放哈希表 1 的空间。
字符串和集合数据类型的操作效率
有哪些底层数据结构?
文章转载自Alleria Windrunner,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
