排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
秒杀系统的热点数据处理
秒杀系统的热点数据处理
Alleria Windrunner
2021-10-22
958
上一篇我们介绍完了秒杀系统的降级处理,本篇我们来看一下秒杀系统的热点数据处理。
在讲热点数据的处理之前,我们先看看高并发的常规解决思路。分布式系统设计,解决高并发问题,可能你很快会想到,如果是数据库,可以通过分库分表来应对,如果是 Redis,可以增加 Redis 集群的分片来解决,而应用层一般是无状态的设计。所以从数据库、Redis 缓存到应用服务,都是可以通过增加机器来水平扩展服务能力,解决高并发的问题。
然而,这样就能应对秒杀的挑战了吗?其实还不够,前面我有提到,秒杀的核心问题是要解决单个商品的高并发读和高并发写问题,也就是要处理好热点数据问题。
所谓热点数据,是从单个数据被访问的频次角度去看的。单位时间(1s)内,一个数据非常频繁的被访问,就可以称之为热点数据,反之可以归为一般数据或冷数据。那么单位时间内究竟多高的频次才能称为热点数据呢?实际上并没有一个明确的定义,可以根据你自己的系统吞吐能力而定。
平价茅台在进行秒杀时,只有这个 SKU 是热点,所以再怎么进行分库分表,或者增加 Redis 集群的分片数,茅台 SKU 落在的那个分片的能力实际并没有提升,总会触达上限,把 Redis 打挂,最后可能引发缓存击穿、系统雪崩。那我们应该怎么解决这个棘手的热点问题呢?
我们把这个问题分为两类:读热点问题和写热点问题。下面我们分别展开讨论。
先看下读热点如何解决,我先抛出解决该问题的思路:
增加热点数据的副本数;
让热点数据离用户越近越好。
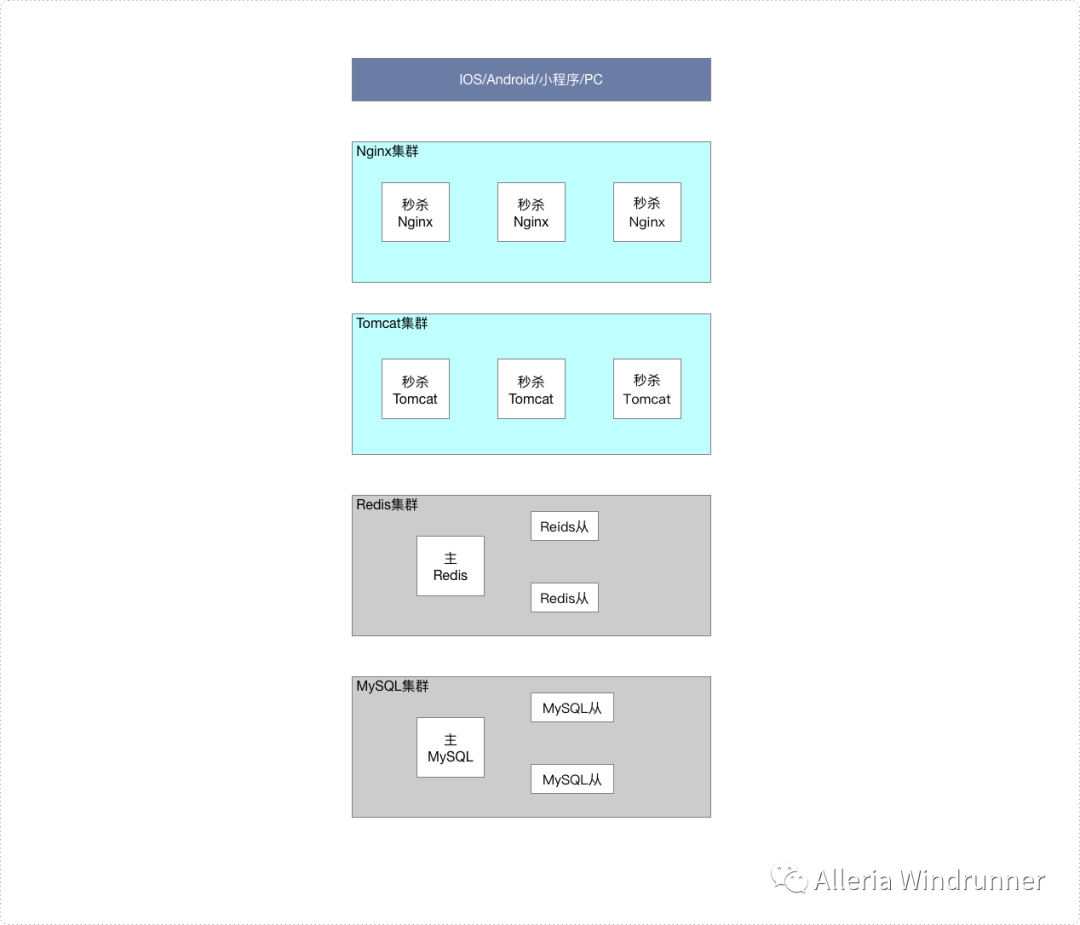
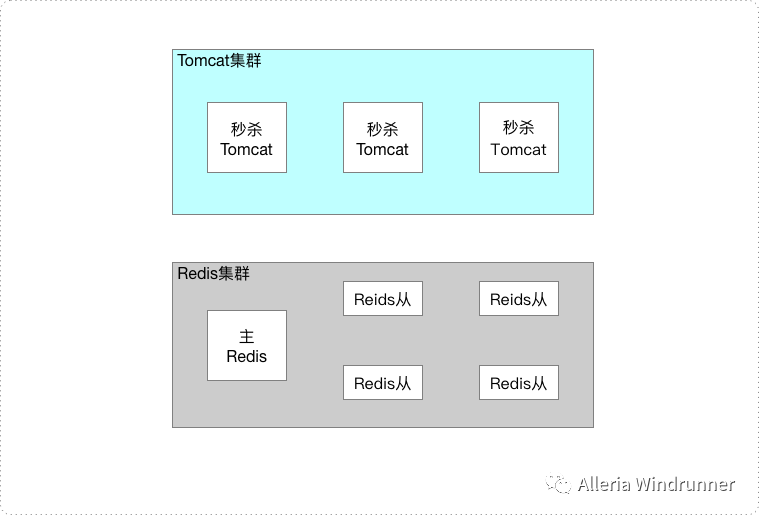
以上是秒杀系统的部署结构图,参照解决思路,我们的第一个解决方案,就是增加 Redis 从的副本数,然后业务层(Tomcat 集群)轮询查询不同的副本,提高同一数据的 QPS。一般情况下,单个 Redis 从,可提供 8~10 万的查询,所以如果我们增加 12 个副本,就可以提供百万 QPS 的热点查询。
这个方法能解决热点问题,但成本比较高,如果你的集群分片数比较多,那分片数 * 副本数就是一笔不小的开销。
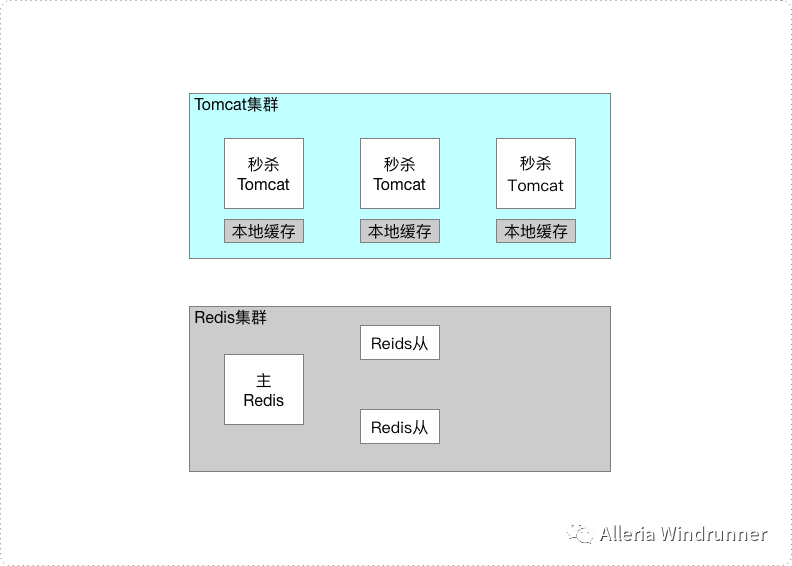
第二个解决方案,我们把热点数据再上移,在 Tomcat 集群做热点数据的本地缓存,也就是让业务层的每个实例里都有份数据副本,读请求数据的时候,无需去 Redis 获取,直接从本地缓存里取。这时候,数据的副本数和 Tomcat 实例一样多,另外请求链路减少了一层,而且也减少了对 Redis 单片 QPS 上限的依赖,具有更高的可靠性和更高的性能。
这种方式热点数据的副本数随实例的增加而增加,非常容易扩展,扛高流量。不过你要思考一个问题,本地缓存的数据延迟业务是否能够接受?
如果能接受,本地缓存的时候可以设置几分钟?如果对延迟要求比较高,可以设置 1s,这样对 Redis 而言,OPS 的压力直接降低到实例数 每秒,就不需要那么多副本了。
本地缓存的实现比较简单,可以用 HashMap、Ehcache,或者 Google 提供的 Guava 组件。
读热点还有一个比较简单粗暴的方法,那就是直接短路返回。这么说可能比较抽象,我举个例子,茅台秒杀的时候,这个 SKU 是不支持使用优惠券的,那么优惠券系统在处理的时候,可以根据配置中心的茅台 SKU 编码,直接返回空的券列表,这样基本上不怎么耗资源,效率非常高。当然了,这种方式和具体商品的活动方式有关,不具有通用性,但是在几百万的流量面前,简单有效。
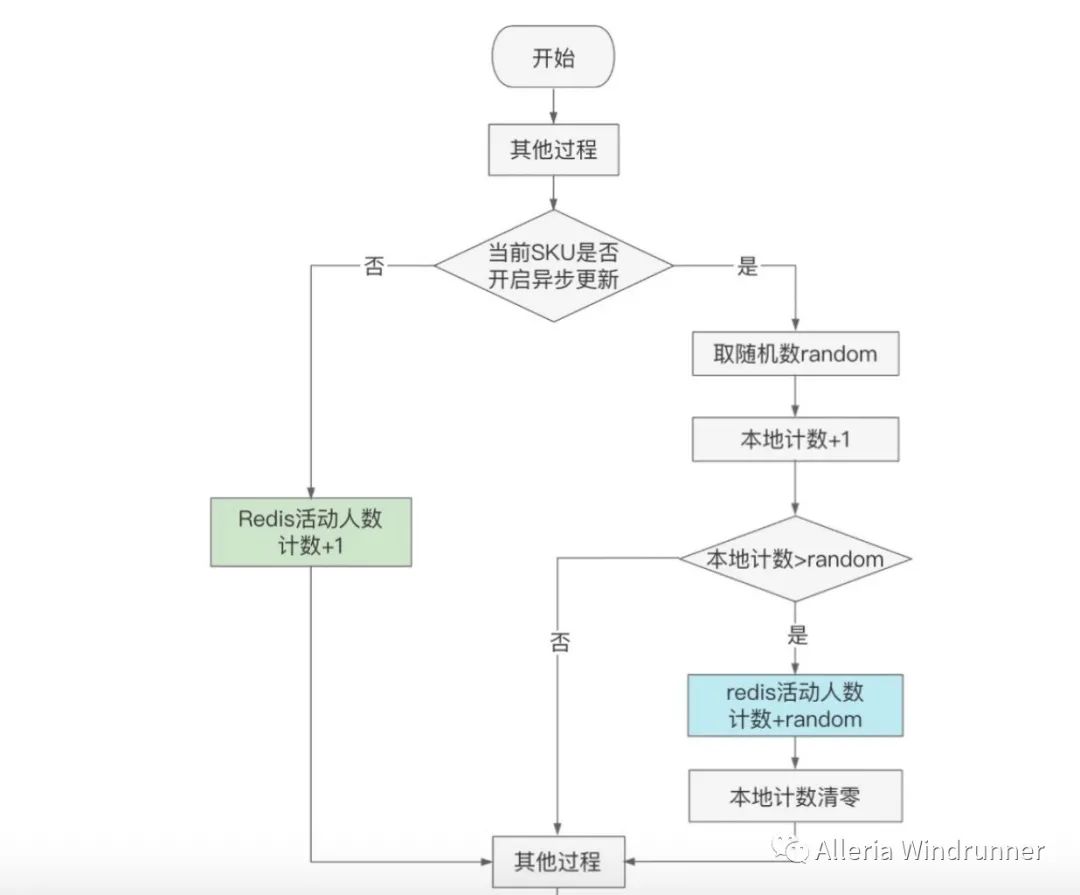
介绍完读热点,接下来我们看写热点问题。我们先回忆一下,在前面讲流量管控里,我们介绍到用户点击“立即预约”的时候,会往“预约人数”这个 Redis key 上进行 ++ 操作,当几百万人同时预约的时候,这个 key 就是热点写操作了。
这个预约总人数有个特点,只是在前端给用户展示用,除此之外,没有其他用途,因此在高并发的场景下,这个人数可以不用那么及时和精确。知道了问题所在,解决方案就在眼前了,我们的思路就是先在 JVM 内存里 ++,延迟提交到 Redis,这样就可以把 Redis 的 OPS 降低几十倍。以下是示意图:
写热点还有一个场景就是库存的扣减,这里讲一下基本思路,可以通过把一个热 key 拆解成多个 key 的方式,避免热点问题。这种设计涉及到对库存进行再细分,以及子库存挪动,非常复杂,而且边界问题比较多,容易出现少卖或者超卖问题,一般不推荐这种方法。
另一个思路就是对单 SKU 的库存直接在 Redis 单分片上进行扣减,实际上,库存系统在秒杀链路的末端,通过我们之前介绍的削峰和限流,真正到库存的流量是有限的,单片的 Redis OPS 能承受得了。然后,我们可以针对单 SKU 的库存扣减进行限流,保证库存单片 Redis 的压力。这样双管齐下,单 SKU 的库存 Redis 扣减压力就是可控的了。
数据库
文章转载自
Alleria Windrunner
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨