




Apache ShardingSphere(Incubator) 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立,却又能够混合部署配合使用的产品组成。
Sharding JDBC的整体架构示意图如下:
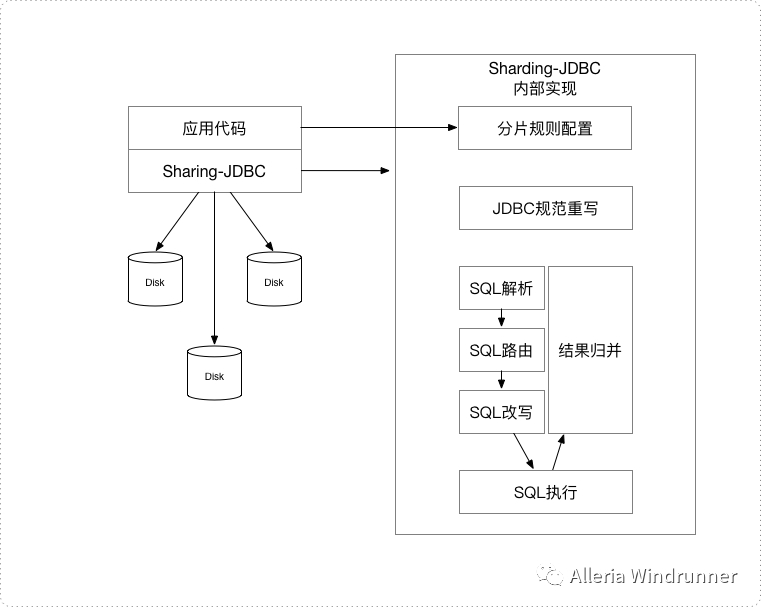
关于Sharding JDBC相关的主要概念有以下这些:
逻辑表 真实表 数据节点 绑定表 广播表
逻辑表是指水平拆分的数据库(表)的相同逻辑和数据结构表的总称。真实表则是指在分片的数据库中真实存在的物理表。数据节点指数据分片的最小单元。由数据源名称和数据表组成。绑定表则指指分片规则一致的主表和子表。例如: t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提 升。最后广播表指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
ShardingJDBC包含分片键和分片算法。分片键是用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。常用的分片算法包括:
精确分片算法 范围分片算法 复合分片算法 Hint分片算法
首先来说精确分片算法(PreciseShardingAlgorithm)用于处理使用单一键作为分片键的(=、in)进行分片的场景,需要配合StandardShardingStrategy使用,代码示例如下:
public class DemoTableShardingAlgorithm implementsPreciseShardingAlgorithm<Long> {@Overridepublic String doSharding(Collection<String> collection,PreciseShardingValue<Long> preciseShardingValue) {for (String each : collection) { if(each.endsWith(Long.parseLong(preciseShardingValue.getValue().toString()) %2+"")) {return each;}}throw new IllegalArgumentException();}}
而范围分片算法(RangeShardingAlgorithm)用于处理使用单一键作为分片键的(BETWEEN、AND)进行分片的场景,需要配合StandardShardingStrategy使用,代码示例如下:
public class MyRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {@Overridepublic Collection<String> doSharding(Collection<String> collection,RangeShardingValue<Long> rangeShardingValue) {log.info("Range collection:" + JSON.toJSONString(collection) +",rangeShardingValue:" + JSON.toJSONString(rangeShardingValue));Collection<String> collect = new ArrayList<>();Range<Long> valueRange = rangeShardingValue.getValueRange();for (Long i = valueRange.lowerEndpoint(); i <=valueRange.upperEndpoint(); i++) {for (String each : collection) {if (each.endsWith(i % collection.size() + "")) {collect.add(each);} }}return collect;}}
另外复合分片算法(ComplexKeysShardingAlgorithm)用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度,需要配合 ComplexShardingStrategy使用,代码示例如下:
public class MyComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm{@Overridepublic Collection<String> doSharding(Collection<String> collection,Collection<ShardingValue> shardingValues) {log.info("collection:" + JSON.toJSONString(collection) +",shardingValues:" + JSON.toJSONString(shardingValues));Collection<Long> orderIdValues = getShardingValue(shardingValues,"order_id");Collection<Long> userIdValues = getShardingValue(shardingValues,"user_id");List<String> shardingSuffix = new ArrayList<>();/**例如:根据user_id + order_id 双分片键来进行分表*///Set<List<Integer>> valueResult = Sets.cartesianProduct(userIdValues,orderIdValues);for (Long userIdVal : userIdValues) {for (Long orderIdVal : orderIdValues) {String suffix = userIdVal % 2 + "_" + orderIdVal % 2;collection.forEach(x -> {if (x.endsWith(suffix)) {shardingSuffix.add(x);} });return shardingSuffix;}private Collection<Long> getShardingValue(Collection<ShardingValue>shardingValues, final String key) {Collection<Long> valueSet = new ArrayList<>();Iterator<ShardingValue> iterator = shardingValues.iterator();while (iterator.hasNext()) {ShardingValue next = iterator.next();if (next instanceof ListShardingValue) {} }} }return valueSet;}}
最后Hint分片算法(HintShardingAlgorithm)用于处理使用Hint行分片的场景,需要配合 HintShardingStrategy使用。
常用的分片策略包括:
标准分片策略 复合分片策略 行表达式分片策略 Hint分片策略
首先标准分片策略(StandardShardingStrategy)提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和 RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置 RangeShardingAlgorithm,SQL中的BETWEEN、AND将按照全库路由处理。
而复合分片策略(ComplexShardingStrategy)提供对SQL语句中的=,IN和BETWEEN、AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略(InlineShardingStrategy)使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代 码开发。
行表达式的使用非常直观,只需要在配置中使用 ${ expression } 或 $->{ expression } 标识行表达式即可。目前支持数据节点和分片算法这两个部分的配置,行表达式的内容使用的是Groovy的语法,Groovy能够支持的所有操作,行表达式均能够支持。
Hint分片策略(HintShardingStrategy)通过Hint而非SQL解析的方式分片的策略。对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。
Sharding JDBC不仅仅局限于对MySql的支持,其支持的数据库有很多:
MySQL ORACLE SQL Server PostgreSQL mongoDB
对于Sharding JDBC的使用也很简单,我们直接在工程中引入jar包,调用API即可:
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-core</artifactId><version>3.0.0</version></dependency>
好了,关于Sharding JDBC的基础概念本篇就介绍到这里。
