




import java.util.concurrent.TimeUnit;public class VolatileFoo{//init_value 的最大值final static int MAX = 5;//init_value 的初始值static int init_value = 0;public static void main(String[] args){//启动一个 Reader 线程,当发现 local_value和init_value 不同时,则输出 init_value 被修改的信息new Thread(() ->{int localValue = init_value;while (localValue < MAX){if (init_value != localValue){System.out.printf("The init_value is updated to [%d]\n", init_value);//对 localValue 进行重新赋值localValue = init_value;}}}, "Reader").start();//启动 Updater 线程,主要用于对 init_value 的修改,当 local_value>=5 的时候则退出生命周期new Thread(() ->{int localValue = init_value;while (localValue < MAX){//修改init_valueSystem.out.printf("The init_value will be changed to [%d]\n", ++localValue);init_value = localValue;try{//短暂休眠,目的是为了使 Reader 线程能够来得及输出变化内容TimeUnit.SECONDS.sleep(2);} catch (InterruptedException e){e.printStackTrace();}}}, "Updater").start();}}
The init_value will be changed to [1]The init_value will be changed to [2]The init_value will be changed to [3]The init_value will be changed to [4]The init_value will be changed to [5]
static volatile int init_value = 0;
The init_value will be changed to [1]The init_value is updated to [1]The init_value will be changed to [2]The init_value is updated to [2]The init_value will be changed to [3]The init_value is updated to [3]The init_value will be changed to [4]The init_value is updated to [4]The init_value will be changed to [5]The init_value is updated to [5]
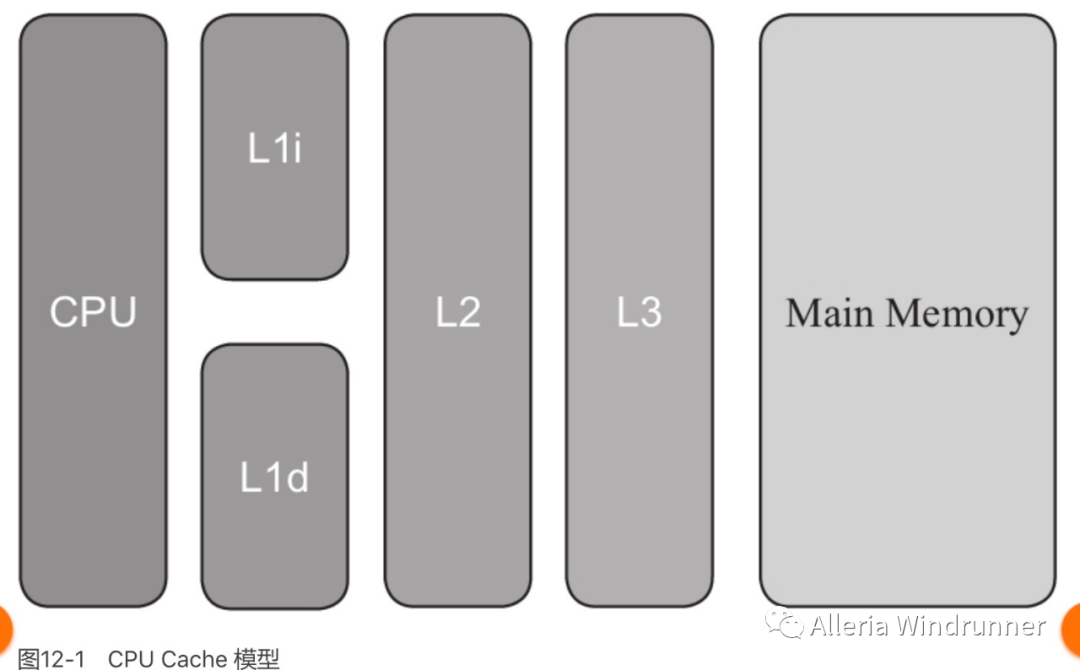

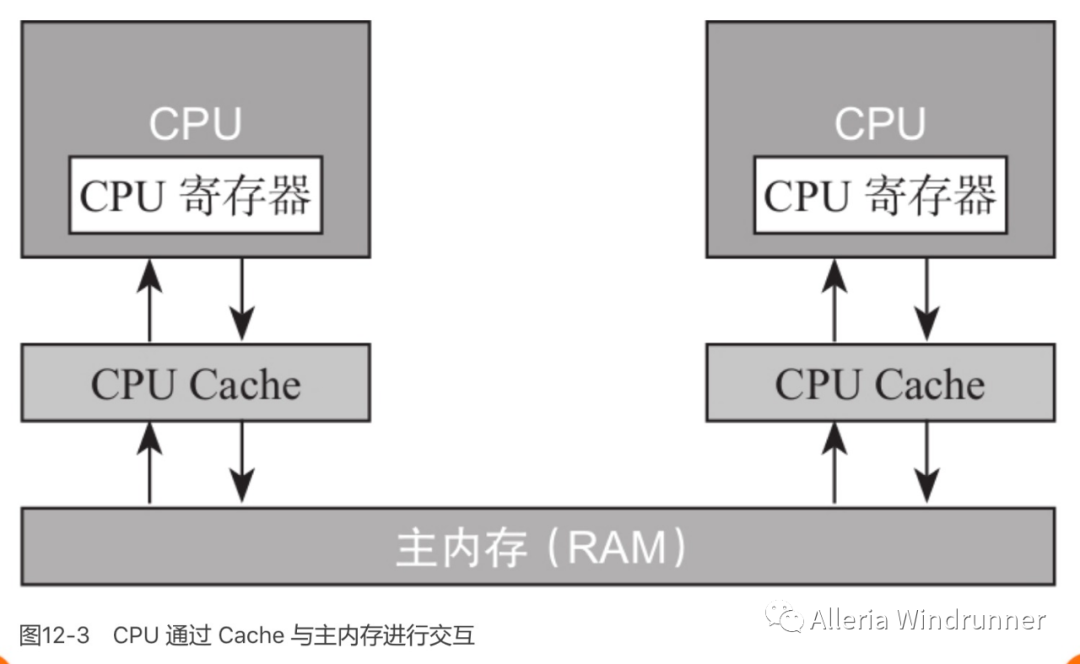
由于缓存的出现,极大地提高了 CPU 的吞吐能力,但是同时也引入了缓存不一致的问题,比如 i++ 这个操作,在程序的运行过程中,首先需要将主内存中的数据复制一份存放到 CPU Cache 中,那么 CPU 寄存器在进行数值计算的时候就直接到 Cache 中读取和写入,当整个过程运算结束之后再将 Cache 中的数据刷新到主存当中,具体过程如下。
读取主内存的 i 到 CPU Cache 中。 对i进行加1操作。 将结果写回到 CPU Cache 中。 将数据刷新到主内存中。
i++ 在单线程的情况下不会出现任何问题,但是在多线程的情况下就会有问题,每个线程都有自己的工作内存(本地内存,对应于 CPU 中的 Cache),变量 i 会在多个线程的本地内存中都存在一个副本。如果同时有两个线程执行 i++ 操作,假设 i 的初始值为0,每一个线程都从主内存中获取 i 的值存入 CPU Cache 中,然后经过计算再写入主内存中,很有可能 i 在经过了两次自增之后结果还是1,这就是典型的缓存不一致性问题。
通过总线加锁的方式。
通过缓存一致性协议。
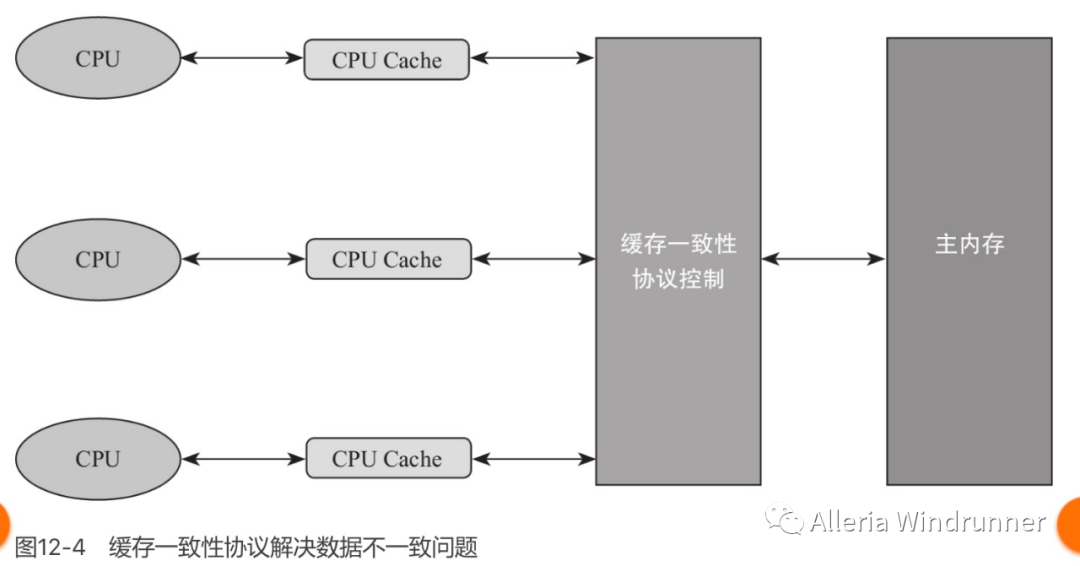
读取操作,不做任何处理,只是将 Cache 中的数据读取到寄存器。
写入操作,发出信号通知其他 CPU 将该变量的 Cache line 置为无效状态,其他 CPU 在进行该变量读取的时候不得不到主内存中再次获取。
共享变量存储于主内存之中,每个线程都可以访问。
每个线程都有私有的工作内存或者称为本地内存。
工作内存只存储该线程对共享变量的副本。
线程不能直接操作主内存,只有先操作了工作内存之后才能写入主内存。
工作内存和 Java 内存模型一样也是一个抽象的概念,它其实并不存在,它涵盖了缓存、寄存器、编译器优化以及硬件等。
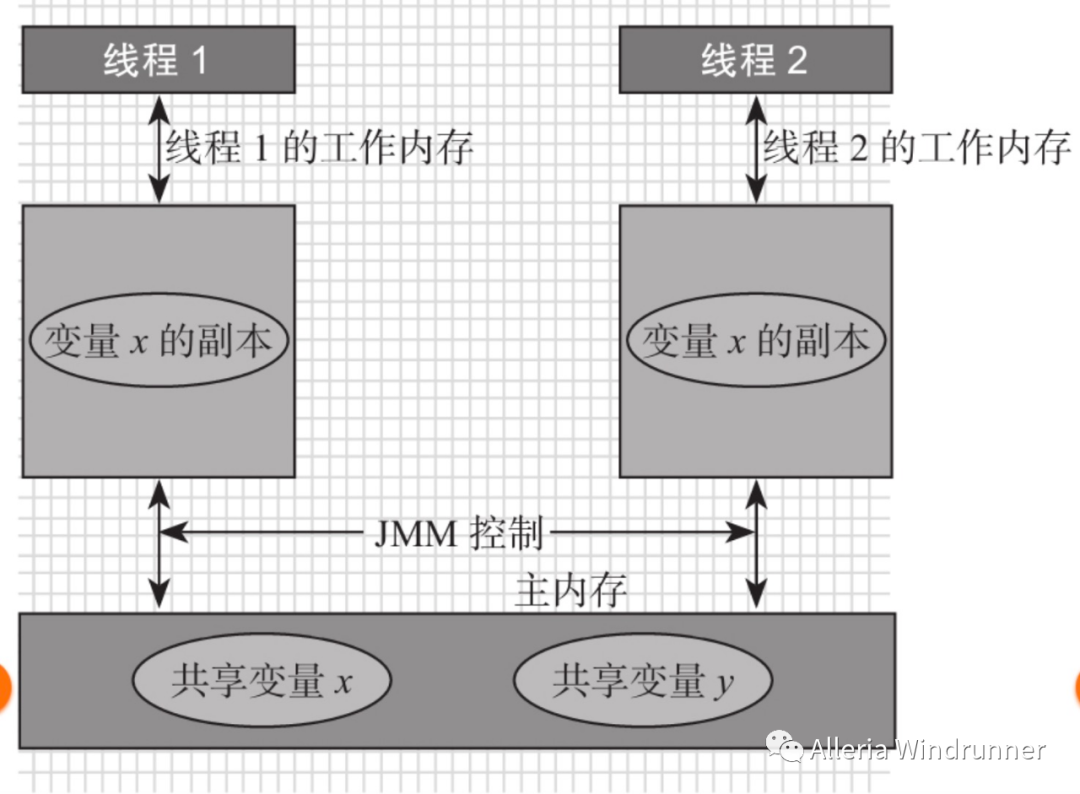
假设主内存的共享变量为0,线程1和线程2分别拥有共享变量 X 的副本,假设线程1此时将工作内存中的 x 修改为1,同时刷新到主内存中,当线程2想要去使用副本 x 的时候,就会发现该变量已经失效了,必须到主内存中再次获取然后存入自己的工作内容中,这一点和 CPU 与 CPU Cache 之间的关系非常类似。
Java 的内存模型是一个抽象的概念,其与计算机硬件的结构并不完全一样,比如计算机物理内存不会存在栈内存和堆内存的划分,无论是堆内存还是虚拟机栈内存都会对应到物理的主内存,当然也有一部分堆栈内存的数据有可能会存入 CPU Cache 寄存器中。下图所示的是 Jave 内存模型与 CPU 硬件架构的交互图。
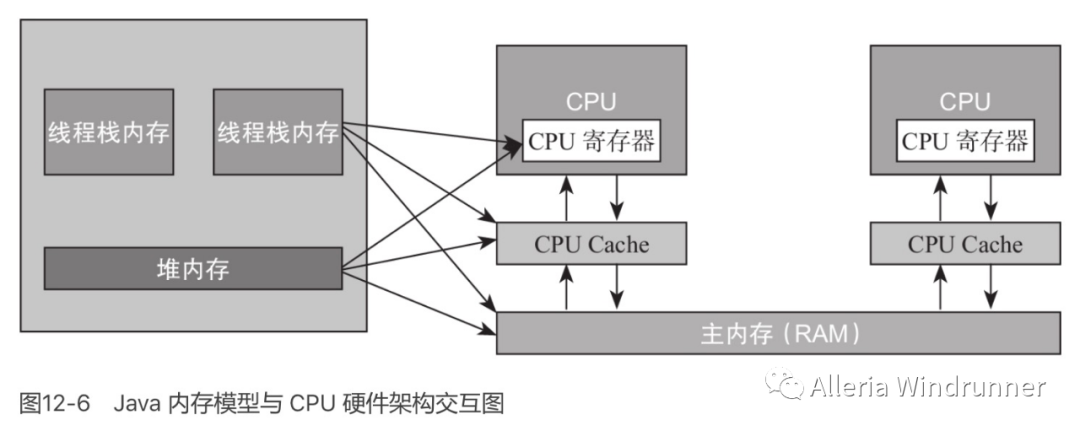
当同一个数据被分别存储到了计算机的各个内存区域时,势必会导致多个线程在各自的工作区域中看到的数据有可能是不一样的,在 Java 语言中如何保证不同线程对某个共享变量的可见性?
