





一、现场环境
主机类型:IBM P740 (32G RAM+16 Core CPU+2*146G)
操作系统:AIX 6.1
数 据 库 :oracle 10.2.0.5 RAC
集群软件:Power HA6.1
存储方式:Raw device
磁盘阵列:IBM DS5020 15KRPM 300GB FC 磁盘*12
主机名称:db01/db02
二、现象描述
现场同事反馈,现场应用系统查询异常缓慢,已经影响操作及数据存盘,在数据库服务器上执行sqlplus as sysdba也是hang住,几乎没有反应;
回想起前段时间,另一同事也反馈过现场的库存在问题,当时由于忙于其它事情,客户又急于恢复,重启实例后问题解决;
三、信息收集及问题分析
本想让同事进行AWR/ASH/ADDM的收集,在收集AWR时发现,最近的SNAP没有生成,已经没有意义,其它信息也是hang住而无法收集,只能让其收集alert日志,分析alert日志发现如下信息:
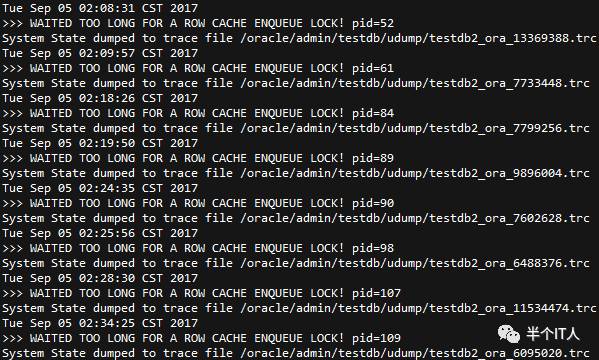
于是又让同事把相应的trace文件收集一下,分析trace文件得知如下信息:
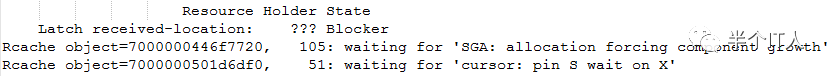
在这里我们可以明显看到存在:SGA: allocation forcing component growth 等待事件,这是由于SGA无法增长导致,也就是SGA被撑爆了,这也解释了前段时间出问题时,重启实例数据库恢复正常,可以初步判断问题的根源在这里,查看MOS后发现一篇文档:文档 ID 1170814.1,有账号的朋友可以自行查阅,文档里也印证了我的分析与猜测。
三、处理方法
前面已经定位问题,我们就需要从SGA入手,调整SGA的大小,主要步骤如下:
1、查看主机内存大小

2、查看数据库SGA与PGA
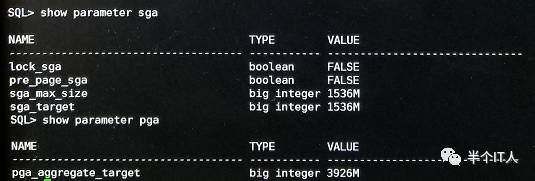
到这里就很明显了,主机内存为32G,而数据库分配的SGA大小仅为:1536M,显然不合理。
3、调整SGA大小
官方文档建议参见相应文档:
10g:http://docs.oracle.com/cd/B19306_01/server.102/b14211/memory.htm#i51933
11g:http://docs.oracle.com/cd/E11882_01/server.112/e41573/memory.htm#PFGRF94351
12c:http://docs.oracle.com/database/122/TGDBA/tuning-program-global-area.htm#TGDBA471
对于本此问题对应版本oracle 10g R2的要求如下:

为了保险,我们分配SGA为16G,PGA为5G大小,更改如下:
SGA:
alter system set sga_max_size=16G scope=spfile sid='×';
alter system set sga_target=16G scope=spfile sid='×';
PGA:
alter system set pga_aggregate_target=5G scope=both sid='×';
调整完成后,需要依次重启实例生效,重启实例后再次查看各自大小,正常;
注:操作前务必备份参数文件,以防操作失误用于回退。
至此问题已处理完毕,同事反馈应该已经恢复正常,后序再进行观察反馈。
四、总结
本案例这种情况,是属于事后分析,这种分析的方法只有一个,就是查看日志,如果是操作系统,就要查看操作系统的日志,是数据库自然就要查看数据库的日志。我们知道数据库有很多日志,但是最关键的日志就是alert日志,如果是RAC环境可能会涉及到CRS的日志,如果是单机环境,我们就只需要关注alert日志就可以了,当然通过分析alert日志后,还可能会涉及到其它trace文件 ,如果需要,收集相应文件进行分析即可。
如果你觉得有所收获并愿意继续学习的话,请扫码关注:

 你也可以赞赏哟
你也可以赞赏哟

