




仔细研究了一下Oracle RAC on Extended Distance Clusters,这个看起来很高大上的东西说穿了其实就是RAC把节点放在不同的机房,存储做冗余----至少写两份。来看看Extended RAC的架构图:
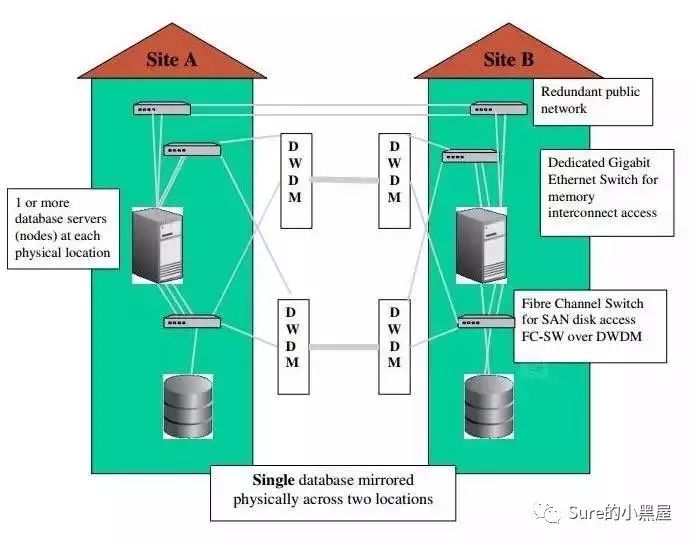
玩转这个有2个关键点:一个是网络,一个是存储。EMC和netapp都给出了相应的解决方案,但是这两家高大上的公司的方案都是烧钱!
那我们如何玩转平民版的Extended RAC呢?
既然叫平民版,那我们就要少花钱甚至不花钱!所以除了网络外,我们将不去采购额外的第三方设备,仅仅使用Oracle提供的特性即可。
玩转平民版大概有这么几个关键点:
(1)存储做冗余,利用Oracle自己提供的asm方式:节点A所在机房A,节点B所在机房B,两个机房提供共享存储,然后把A和B的磁盘做冗余,冗余级别有3种,分别是:不冗余,常规冗余(损失1/2的磁盘容量),高冗余(损失2/3 的磁盘容量)。这样就可以数据至少是多份,可以保证一个机房的存储即使挂了,也不会丢数据。
btw,建议使用Host-Based的存储方式替代array-based方式,后者属于active-inactive的模式,前者是active-active的模式。
(2)保证在冗余的存储基础上,本地节点优先访问本地机房的存储。这个是非常值得关注的一个地方,如果本地的节点进行数据访问,每次都去读取远程机房的共享存储上的数据,那么性能损耗要比本机房多一个网络的开销以及Oracle GI的cache fushion的开销,所以为了让本地节点优先访问本地机房的存储,我们需要用到11g ASM的一些重要特性,ASM_PREFERRED_READ_FAILURE_GROUPS(ASM 首选镜像读取),我们可以将本地及远程的存储(磁盘),分别划分到不同的FAILURE_GROUP,然后根据这个参数来指定优先读取哪个FAILURE_GROUP。设置后可以通过 select instname, failgroup, sum(reads), sum(writes) from v$asm_disk_iostat group by instname,failgroup 来确认是否生效。
(3)创建不同的service name,中间件连接的时候,就指定service name来连接,让不同的业务在不同的节点上运行,这样可以最大程度的减少cache fushion的开销。
(4)基于GI架构,我们将采用奇数个投票盘(OCR),让在2个节点自身的机房存储外,添加第三个地点的存储卷,将3个存储卷组作为OCR的存储地方。这样可以避免脑裂的发生。
(5)最后说说网络:
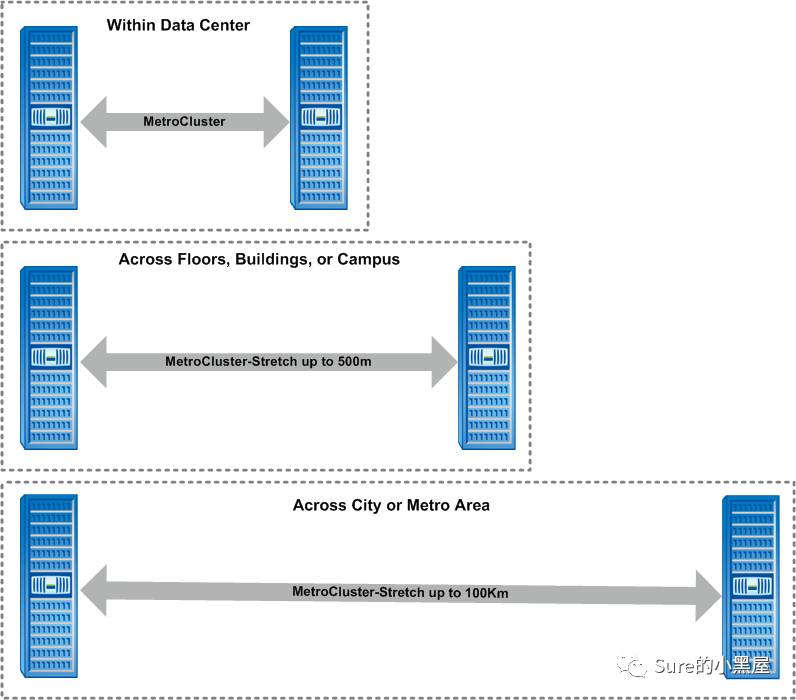
2个节点间距离小于10km,可以使用平常使用的网络;超过10km,建议使用dwdm进行节点间数据的传递(DWDM:Dense Wavelength Division Multiplexing 密集型光波复用,这是一项用来提高带宽的激光技术。该技术是在一根指定的光纤中,多路复用单个光纤载波的紧密光谱间距,以便利用可以达到的传输性能);10-50km之间需要SAN网络要减少距离带来的性能影响;超过50km。。。
