




通俗的来讲,索引在表中的作用,相当于书的目录对书的作用。
----前言
一、索引的优点
索引是与表相关的一个可选结构
一个表中可以存在索引,也可以不存在索引,不做硬性要求。
用于提高SQL语句执行的性能
快速定位我们需要查找的表的内容(物理位置),提高SQL语句的执行性能。
减少磁盘I/O
取数据从磁盘上取到数据缓冲区中,再交给用户。磁盘I/O非常不利于表的查找速度(效率的提高)
使用CREATE INDEX 语句创建索引
在逻辑上和物理上都独立于表的数据
索引与表完全独立,表里的内容是我们所需要的内容,而索引则是做了一些编制,索引和数据可以存放在不同的表空间下面,可以存放在不同的磁盘下面。
ORACLE自动维护索引
当对一个建立索引的表的数据进行增删改查的操作时,ORACLE会自动维护索引,使得其仍然能够更好的工作。
####二、索引的类型与结构
####1、索引类型
从总的概念上来说,索引分为B树索引(也叫平衡树索引,即就是什么都不写,最常用)和位图索引(多用于数据仓库)。这两种索引在逻辑结构(存储)上完全不同。
####B树索引
其中B树索引 又可以具体分为:
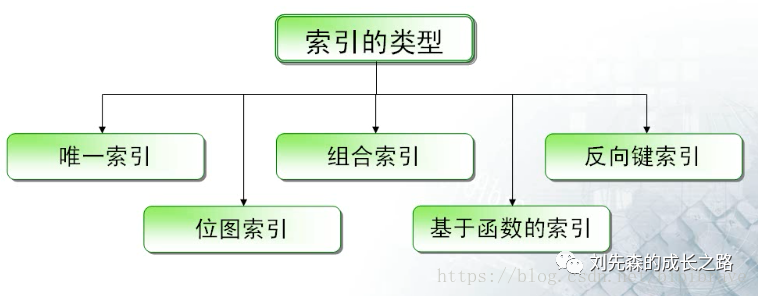
(1)唯一索引:
唯一索引确保在定义索引的列中没有重复值
ORACLE自动在表的主键列上创建唯一索引
使用CREATE UNIQUE INDEX语句创建唯一索引
2)组合索引:
组合索引是在表的多个列上创建的索引
索引中列的顺序是任意的
如果 SQL 语句的 WHERE 子句中引用了组合索引的所有列或大多数列,则可以提高检索速度
创建索引时使用REVERSE关键字
语法:create index index_name on table_name (column_name) reverse;
具体列值:适用于某列值前面相同,后几位不同的情况,例如
sno: 1001 1002 1003 1004 1005 1006 1007
索引转化:1001 2001 3001 4001 5001 6001 7001
(4)位图索引:
位图索引适合创建在低基数列上
位图索引不直接存储ROWID,而是存储字节位到ROWID的映射
节省空间占用
如果索引列被经常更新的话,不适合建立位图索引
总体来说,位图索引适合于数据仓库中,不适合OLTP中。
(5)基于函数的索引:
基于一个或多个列上的函数或表达式创建的索引
表达式中不能出现聚合函数
不能在LOB类型的列上创建
创建时必须具有 QUERY REWRITE 权限
语法:create index index_name on table_name (函数(column_name));
具体列值:不能在LOB类型的列上创建,用户在该列上对该函数有经常性的要求。
例如:用户不知道存储时候姓名是大写还是小写,使用
select * from student where upper(sname)=‘TOM’;
####2、索引结构
索引的结构是一个倒立的树状结构,其中每个节点的左子树比他的右子树小,索引最终指向表里面的数据与表里面的数据对应。
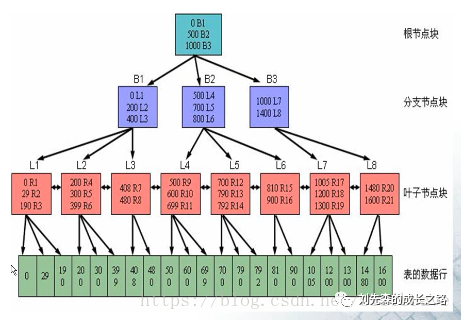
如上图,前三行时索引的内部结构,第三行与最后一行,这是索引指向表里数据的一个指向。索引是建立在列上的。最后一行是索引建立在表中的某列上的值。
**根节点块 :**如果索引列的值>0时,指向B1这个分支节点块,如果索引列的值>500时,指向B2这个分支节点块,如果索引列的值>1000时,指向B3这个分支节点块。
**分支节点块:**对于B1来说,再进行细分 如果索引列的值>0且<200时,指向L1这个分支节点块,如果索引列的值>200且<400时,指向L2这个分支节点块,如果索引列的值>400且<500时,指向L3这个分支节点块。
叶子节点块:对于L1来说,如果数据行的值为0,那就放在R1这个数据行中,如果数据行的值为29,那就放在R2这个数据行中,如果数据行的值为190,那就放在R3这个数据行中,等。
####三、索引的创建。
1— 建立一张表:
create table student(sno number ,sname varchar2(10),sage int,male char(3)); --一个汉字占三个字符insert into student values(1,'TOM',21,'男');insert into student values(2,'kite',22,'男');insert into student values(3,'john',23,'女');
2— 创建该表上的索引:
create index ind1 on student(sno);
3-- 查询索引相关信息:
-- 索引的全部信息 select * from user_indexes;
--查询索引涉及到的列 select * from user_ind_columns u where u.index_name='IND1’;
####四、索引的变动,查询索引碎片
由于我们在对表的使用过程中,必然引发增删查改等操作,当表中的数据不存在,但其索引仍然存在,极大的影响了查询速度,降低了索引的利用率。
我们可以通过 查看index_stats表中的pct_used列的值,如果pct_used的值过低,说明在索引中存在碎片,可以重建索引,来提高pct_used的值,减少索引中的碎片。
对索引碎片的查询,在该语句前后都要使用分析索引语句,已使得索引利用率发生改变。
--关于索引的知识拓展起来会很多,逐一记录下来
