上一篇我们从整体上说了下数据库的发展历史,先简单的回顾一下:
RDBMS(单机关系型)
NoSQL(分布式非关系型)
NewSQL(分布式关系型)
分库实践
但是基于目前行业的现状,传统单机关系型的RDBMS仍然是大头,那本篇我们来说一说传统单机关系型RDBMS分库分表实践。传统单机关系型的RDBMS使用比较多的有:但是由于Oracle的使用成本较高,我们就以MySQL作为案例来分析。在互联网行业,由于数据量的增长,单机数据库肯定是不能一直撑下去的,所以当数据量上来之后我们需要分库分表。分库一般按照业务功能垂直拆分,例如将我们的整个库按照业务拆分为用户库、商品库、交易库。而分表就是水平方向的操作,例如我们将某张数据量比较大的单表水平方向拆成1024张表,每次操作前我们可以采用主键%1024获取到表的信息然后进行操作。按分库的逻辑来提升系统性能我们可以从以下两方面入手:
架构升级我们可以从简单的M-S架构到DB拆分架构,从无Cache到Cache,示意图如下: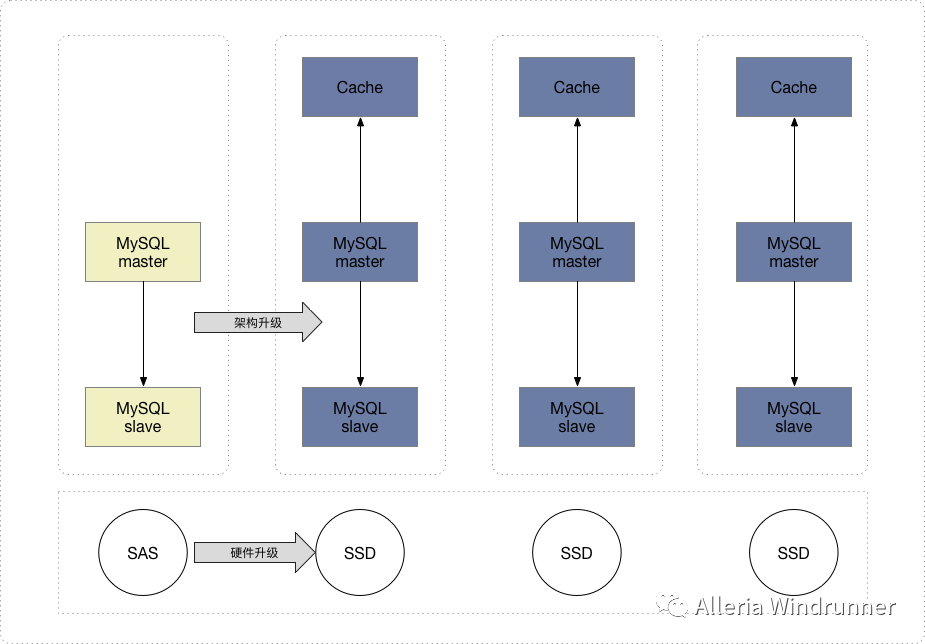
至于硬件方面,如果公司没钱可以将SAS盘升级到PCIE口的SSD,土豪的话可以考虑NVME口的SSD。当然分库后会带来跨数据库事务的问题,至于分布式事务的解决方案可以参考架构设计的分布式事务设计与实践。
按分表的逻辑来提升系统性能我们也可以从以下两方面入手:
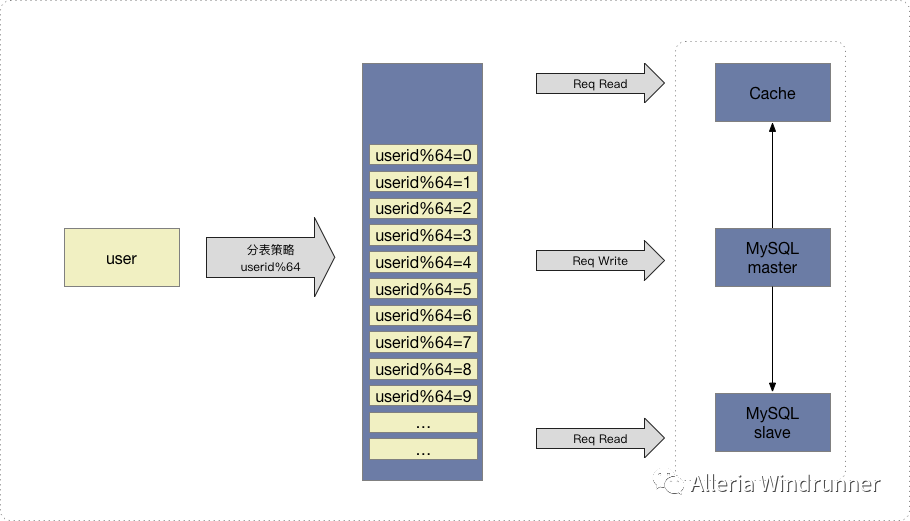
分表的策略也很简单,拿数据库的主键对分表数量做个哈希函数即可,然后应用层可以使用读写分离,写主库读缓存或者从库。当然这样也存在一些问题,首先是读写分离需要在应用层实现,然后是非partition key读写的问题。当数据量再大一点的时候我们的架构可以继续进行升级,例如我们对之前拆分过的用户库继续进行垂直拆分,示意图如下:
当然这个样子的话又会存在一些问题:
最最简单的一个问题就是我们的业务逻辑层需要引入Sharding-JDBC(Sphere)组件,架构层面就带来了耦合性。那这个问题我们怎么解决呢?最直接的想法就是将Sharding-JDBC组件抽出来变成一个进程,示意图如下:
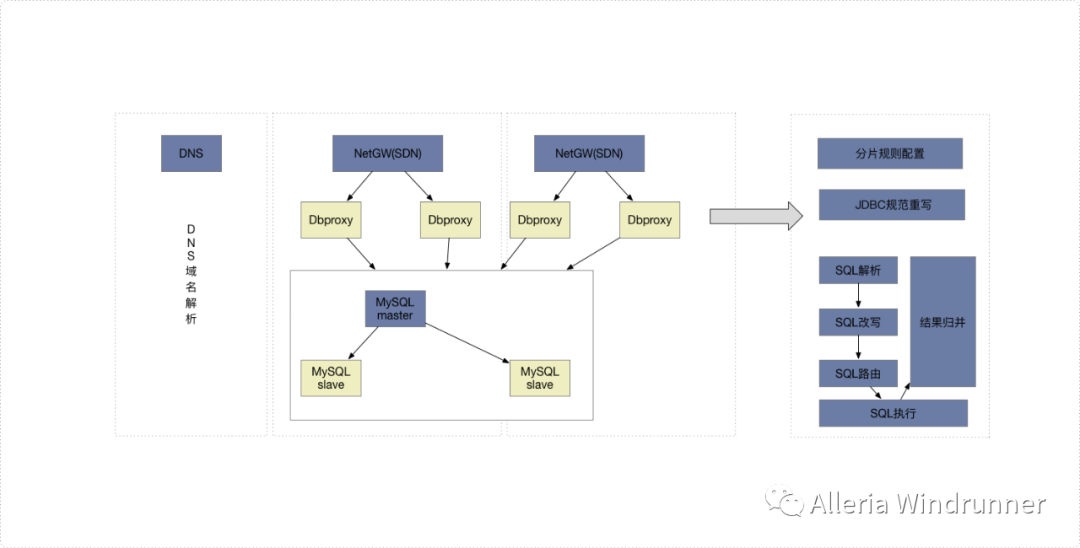
有好处就会有问题,单独抽象成一个进程的话会导致链路过长的问题。所谓分久必合合久必分,所以回到我们上一篇的介绍,如果有可能,大家可以尝试使用NewSQL。分库其实相对比较简单,所以我们重点来聊一聊分表实践。
分表实践
用户表
uid(8byte),name(16byte),city(16byte)
timestamp(long),sex(int),age(int)
5亿条记录
部署在X86_64位的机器上
那么首当其冲的问题就是我们要分几张表?这个其实要看每行记录的大小,按照经验值来说可以分为两种:那么我们的理论来说5亿条数据我们的用户表应该分为10张表,但是对于我们二进制来说,10不是一个整数,所以我们可以向上取整分为16张表。第二个问题就是我们的partition key如何选择?
要是按照城市作为partition key,如果你的用户群体分布不均匀,例如京东、淘宝的用户群体多在一二线城市,而拼多多的用户群体可能就是四五线城市,所以对于你表数据分布就不均匀。要是按照时间作为partition key,比如:2020.01 - 06
2020.07 - 12
2021.01 - 06
...
这样的话,表的数据分布是均匀的,但是对于表的访问率是不均匀的,访问量最大的肯定是最新的表。所以分表的partition key的选择最好就是uid(用户唯一标识)。上面讨论的是查询唯独单一的情况下,如果我们的查询条件不单一呢?例如:uid(用户id)
infoid(商品id)
timestamp
例如我既要可以按照上面的每个条件单独查询,又要可以组合查询,这时候我们的partition key如何选择呢?timestamp我们后面说,我们先来聊uid和infoid,我们可以分为两种情况:uid固定,infoid生成
uid固定,infoid固定
如果我们的partition key是uid,那么infoid单独查询的情况下我们怎么能快速定位到需要查询的表呢?遍历肯定不行吧?其实就是做好映射就行了:uid固定,infoid生成的时候打上uid的烙印,比如转换为二进制低8位生成和uid一样的值
uid固定,infoid固定这个时候建立映射表,当然infoid对partition key的映射要是一对一的
最后我们来说说timetamp的问题,其实你想想什么场景下我们会有针对timestamp的查询需求?一般情况下多是报表之类的需求,所以这个时候已经从一个oltp的查询需求转换为了一个olap的统计需求了,我相信这个时候慢一点也是能接受的,所以我们可以不必考虑了。
数据库中间件
作为互联网公司,对于工具、框架的选择我相信第一要素是开源、免费,毕竟公司的目的是盈利,那么增效降本是第一性原理。对于ORM框架来说,Mybatis无疑是最好的选择。分表的工具推荐Sharding-JDBC/Sphere。DataBase Connection Pool的话Druid是不二选择,当然传统的DBCP和c3p0也是可以的。





