




双向链表的最简实现
public class DLL {Node head;class Node {int data;Node prev;Node next;Node(int d) { data = d; }}}
DLL可以向前和向后遍历。
如果提供了指向要删除节点的指针,则DLL中的删除操作效率更高。
我们可以在指定节点之前快速插入一个新的节点。
DLL 的每个节点都需要为上一个指针提供额外空间。
所有操作都需要额外的维护上一个指针。例如,在插入中,我们需要将上一个指针与下一个指针一起修改。例如,在不同位置插入的后续函数中,我们需要 1 或 2 个额外的步骤来设置上一个指针。
双向链表遍历
public void printlist(Node node){Node last = null;System.out.println("Traversal in forward Direction");while (node != null) {System.out.print(node.data + " ");last = node;node = node.next;}System.out.println();System.out.println("Traversal in reverse direction");while (last != null) {System.out.print(last.data + " ");last = last.prev;}}
双向链表节点的插入可以分为以下四种:
在链表的头部插入 在给定链表节点后插入 在链表的尾部插入 在给定链表节点前插入
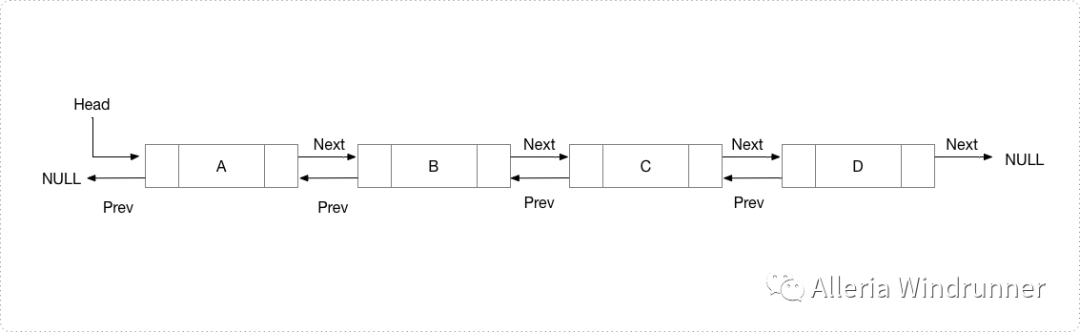
新节点始终添加到给定链表的头部之前。新添加的节点将成为 DLL 的新头节点。例如,如果给定的链表是 10152025,并且在前面添加节点 5,则链表变为 510152025。通常情况下我们把在链表头部插入节点函数命名为 push()。push() 必须接收指向头部指针的指针,因为必须更改头指针以指向新节点。示意图如下:
public void push(int new_data){Node new_Node = new Node(new_data);new_Node.next = head;new_Node.prev = null;if (head != null)head.prev = new_Node;head = new_Node;}
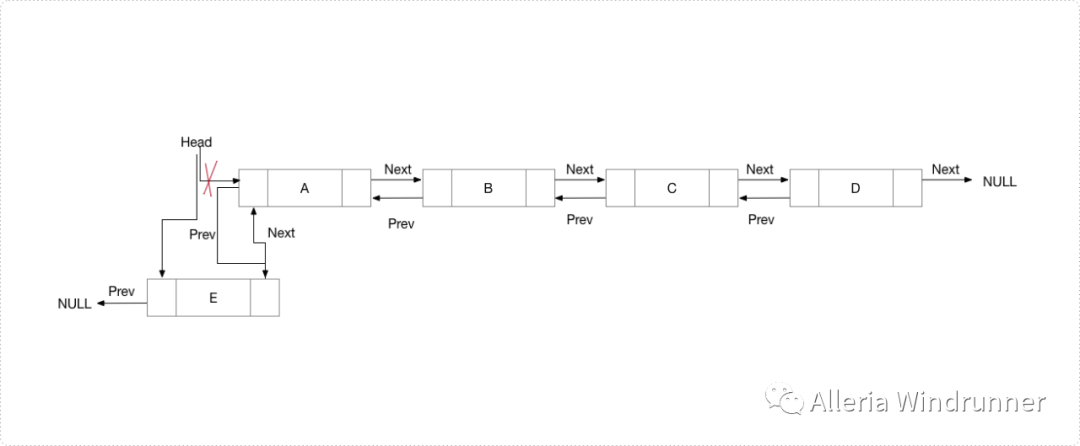
输入参数为prev_node和要插入节点的数据。示意图如下:
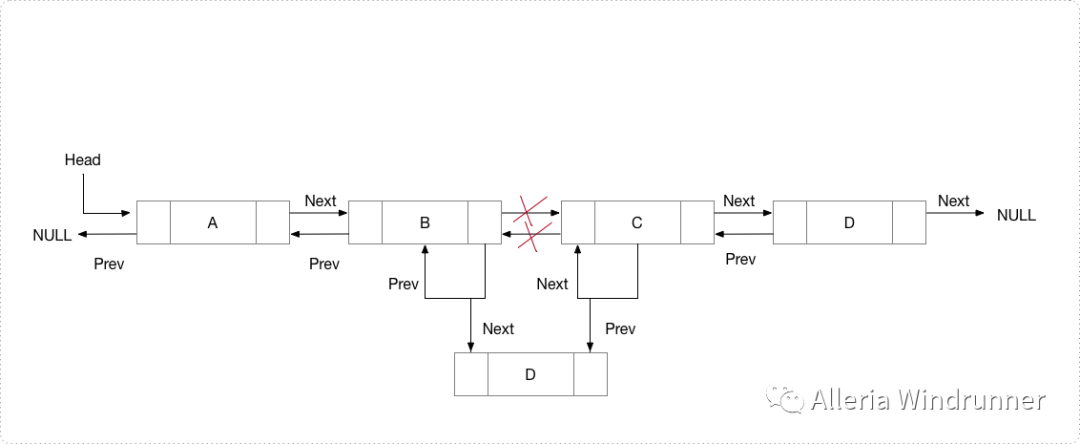
代码示例如下:
public void InsertAfter(Node prev_Node, int new_data){if (prev_Node == null) {System.out.println("The given previous node cannot be NULL ");return;}Node new_node = new Node(new_data);new_node.next = prev_Node.next;prev_Node.next = new_node;new_node.prev = prev_Node;if (new_node.next != null)new_node.next.prev = new_node;}
新节点始终在给定链表的最后一个节点之后添加。例如,如果给定的 DLL 为 510152025,并且我们在末尾添加项目 30,则 DLL 变为 51015202530。由于链表通常由列表的头部表示,因此我们必须遍历列表直到结束,然后将下一个节点更改为新节点。示意图如下:
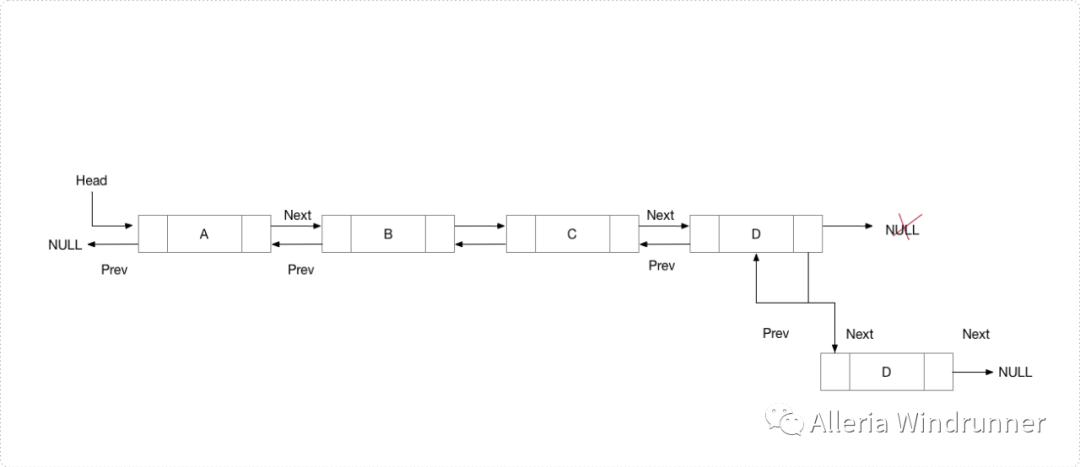
void append(int new_data){Node new_node = new Node(new_data);Node last = head;new_node.next = null;if (head == null) {new_node.prev = null;head = new_node;return;}while (last.next != null)last = last.next;last.next = new_node;new_node.prev = last;}
双向链表的节点删除,具体算法步骤如下:
如果要删除的节点是头节点,则直接将头节点指针指向当前头节点的下一个节点即可。 如果要删除节点上一个节点存在,则将其next指针指向要删除节点的next。 如果要删除节点下一个节点存在,则将其prev指针指向要删除节点的prev。
代码示例如下:
public class DLL {Node head;class Node {int data;Node prev;Node next;Node(int d) { data = d; }}void deleteNode(Node head_ref, Node del){// 基础条件判断if (head == null || del == null) {return;}// 如果要删除的节点是头节点if (head == del) {head = del.next;}// 如果要删除的节点不是最后一个节点if (del.next != null) {del.next.prev = del.prev;}// 如果要删除的节点不是第一个节点if (del.prev != null) {del.prev.next = del.next;}return;}}
删除操作的时间复杂度也为O(1)。
以上为双向链表的最简实现与常见操作的时间复杂度分析。链表经典的应用场景为 LRU 缓存淘汰算法。常见的缓存清理策略有三种:
先进先出策略 FIFO(First In, First Out) 最少使用策略 LFU(Least Frequently Used) 最近最少使用策略LRU(Least Recently Used)
大致的思路为:维护一个有序链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头部开始顺序遍历链表:
如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据的对应结点,并将其从原来的位置删除,并插入到链表头部。 如果此数据没在缓存链表中,又可以分为两种情况处理: 如果此时缓存未满,可直接在链表头部插入新节点存储此数据; 如果此时缓存已满,则删除链表尾部节点,再在链表头部插入新节点。
当然也有朋友说,链表这种数据结构的最大的作用是为了让大家可以继续学习后面的树形数据结构(>o<),好像也与道理。
