




上一篇我们讨论了分布式事务的由来、数据不一致的原因、同步和异步两种驱动场景下的分布式事务、分布式事务的分类以及业界内分布式事务解决方案的理论。此篇我们继续来聊柔性分布式事务的实现方案,因为刚性分布式事务肯定不适合互联网业务场景的,而且刚性事务就是我们常说的本地事务,也比较简单,没有什么好聊的。
解决问题的思路
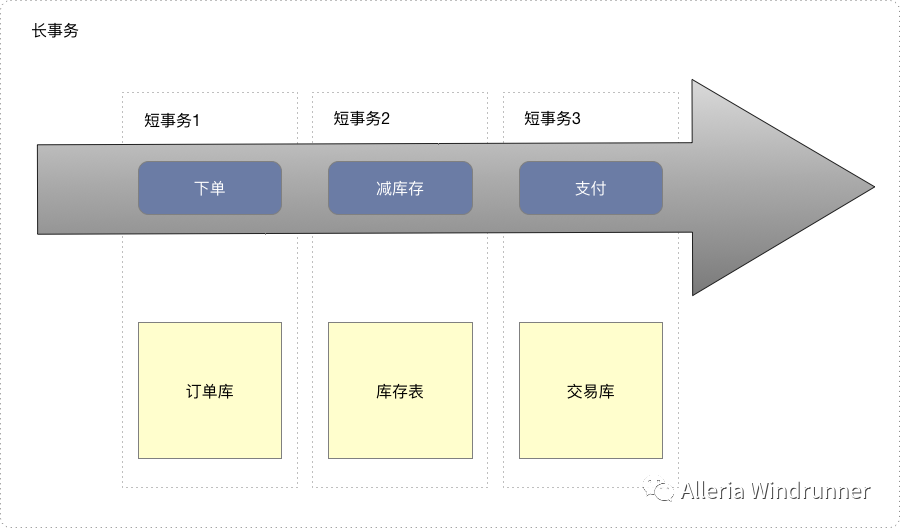
首先我们思考一下事务这个问题本身,本地事务好不好解决?答案肯定是好解决!本地事务我们可以理解为短事务。那分布式事务为什么不好解决,因为分布式事务相对于本地事务来说是长事务,所以问题就很简单了,我们就把分布式事务转换为多个本地事务,即把长事务转换为多个短事务,然后我们去协调好多个短事务,分布式事务的问题就解决了。
举个实际的例子,比如常见的电商系统下单->减库存->支付场景:
下单->DB1(订单表)
减库存->DB2(库存表)
支付->DB3(交易表)
有两类情况会出现,第一类就是下单、减库存、支付都成功,那分布式事务就成功。第二类就是下单、减库存成功,支付失败,那我们就需要对下单和减库存做补偿处理。这个例子中我们就把下单、减库存、支付这个长的分布式事务转换为了多个短事务,最后如果是有失败的步骤我们的补偿处理就是解决思路里面的协调。示意图如下:
分布式事务场景
上篇我们分析了异步和同步两种分布式事务场景,那接下来我们就分情况聊一下两种情况下的解决方案。
异步场景分布式事务解决方案
MQ事务消息
所谓事务消息就是MQ提供类似X/Open XA的分布式事务功能,通过MQ事务消息能达到分布式事务的最终一致。在事务消息中有半消息的概念,半消息就是暂不能投递的消息,发送方已经将消息成功发送到MQ服务端,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,处于该种状态下的消息即半消息。事务消息的方案需要业务方提供消息回查的功能,因为在网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,MQ服务端通过扫描发现某条消息长期处于“半消息”时,需要主动向消息生产者询问该消息的最终状态(Commit 或是 Rollback)。示意图如下:
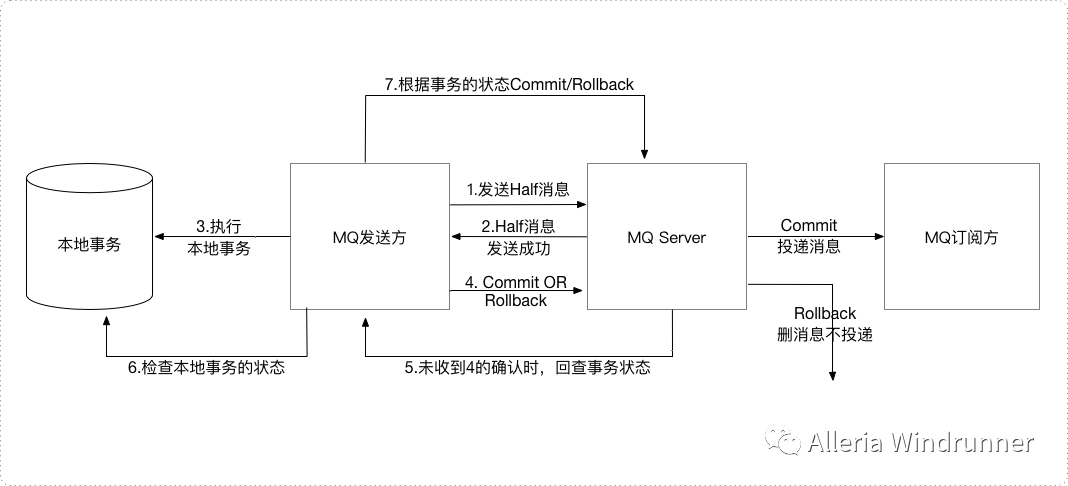
具体的事务流程如下:
事务发起方首先发送prepare消息到MQ;
在发送prepare消息成功后执行本地事务;
根据本地事务执行结果返回commit或者rollback;
如果消息是rollback,MQ将删除该prepare消息不进行下发,如果是commit消息,MQ将会消息发送给consumer端;
如果执行本地事务过程中,执行端挂掉,或者超时,MQ服务端将不停的询问producer来获取事务状态;
Consumer端的消费成功机制有MQ保证;
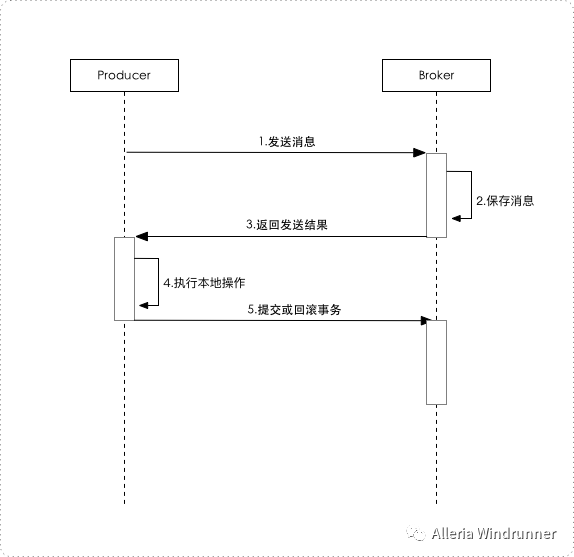
MQ事务消息系统时许图如下:
MQ事务消息的优缺点如下:
* 优点* 通用* 缺点* 业务方需提供回查接口,对业务侵入大* 发送消息非幂等* 消费端需要处理幂等
MQ事务消息的方案推荐大家直接使用RocketMQ,在v4.2的时候已经开源出半消息了。
本地事务消息表
异步场景下处理分布式消息的另外一种常用方案就是本地事务消息表,其示意图如下:
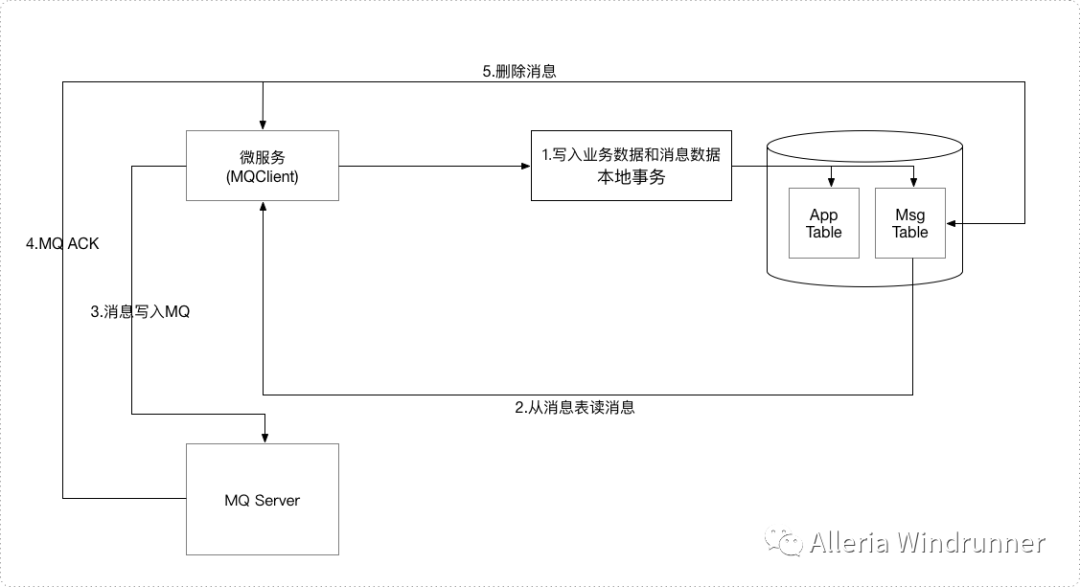
具体的事务流程如下:
写入业务数据和消息数据
从消息表读消息
消息写入MQ
收到消息ACK之后删除消息表中的事务消息
本地事务消息表的方案中,业务数据和消息数据通过本地事务保证强一致性。但是有点需要注意的。发送端消息不幂等,事务消息发送的语义是at least once,因为业务节点可能部署多个,所以从消息表读消息发送到MQ的时候我们需要分布式锁。
本地事务消息表优缺点如下:
* 优点* 业务侵入小* 缺点* 发送消息非幂等* 消费端需要处理幂等
对于异步场景分布式事务如果消费端一直重试失败,我们只需要记录错误日志,报警然后人工介入即可。
同步场景分布式事务解决方案
Saga分布式事务解决方案
还是拿之前同步驱动的图来分析,我们一个完整的事务流程是下单->减库存->支付三个步骤,结合上一篇讲的Saga分布式事务理论部分,我们的架构设计要关注以下三个关键点:
记录请求调用链条
提供幂等补偿接口
基于异步补偿机制
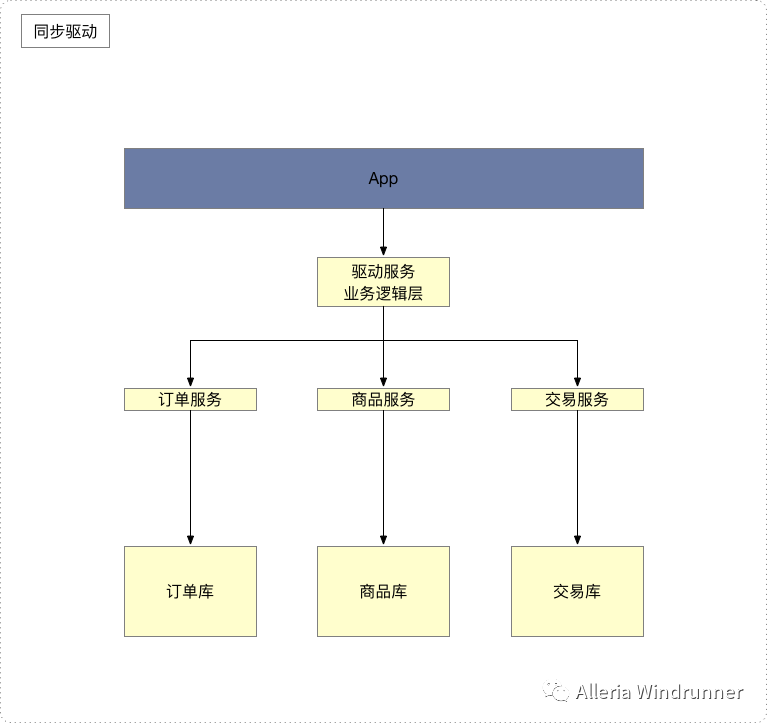
为什么需要关注这三个关键点?记录请求调用链条是因为我们在补偿的时候需要知道原请求的调用参数之类的信息,幂等的补偿接口是因为如果出现超时的情况我们会重试,不做幂等处理可能会出现重复处理的问题,而基于异步补偿机制是什么意思呢?假如下单成功,减库存成功,支付失败,那基于Saga分布式事务处理模型需要向后补偿,也就是我们要把订单置为失效,把剪掉的库存加回去,请你思考一下,这个时候我们是马上返回用户失败异步去做补偿好?还是等同步补偿成功之后返回用户失败好?从用户的体验的角度来思考,肯定是异步去做补偿好吧?
架构设计概览
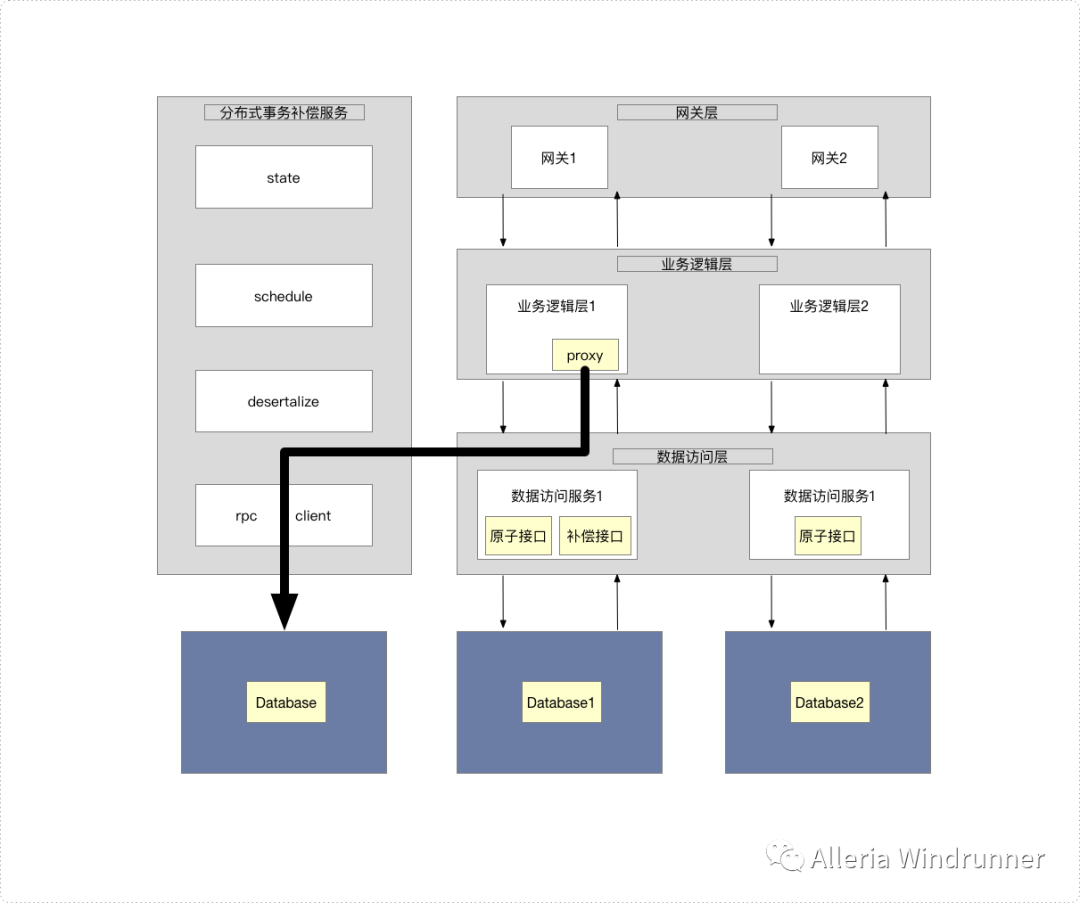
还记得我们说分布式事务的处理思路吗?把长事务转化为短事务,把分布式事务转化为本地事务然后去做协调。那我们依据什么去协调呢?有朋友肯定会说我自己写的代码我肯定知道怎么去协调啊?那我告诉你,你要针对每个业务场景去写一段代码,下一个累死的就是你,这种做法肯定不是平台化的思路。我们可以这么理解,把分布式事务像订单一样看待,每一次分布式事务相关的步骤和参数等我都持久化下来,然后拿这条持久化下来的记录去做协调。从架构设计来看有三个关键点:
业务逻辑层的proxy的设计
数据访问层的原子接口和补偿接口的设计
分布式事务补偿服务事务主表和事务明细表的设计
业务逻辑层的proxy的设计
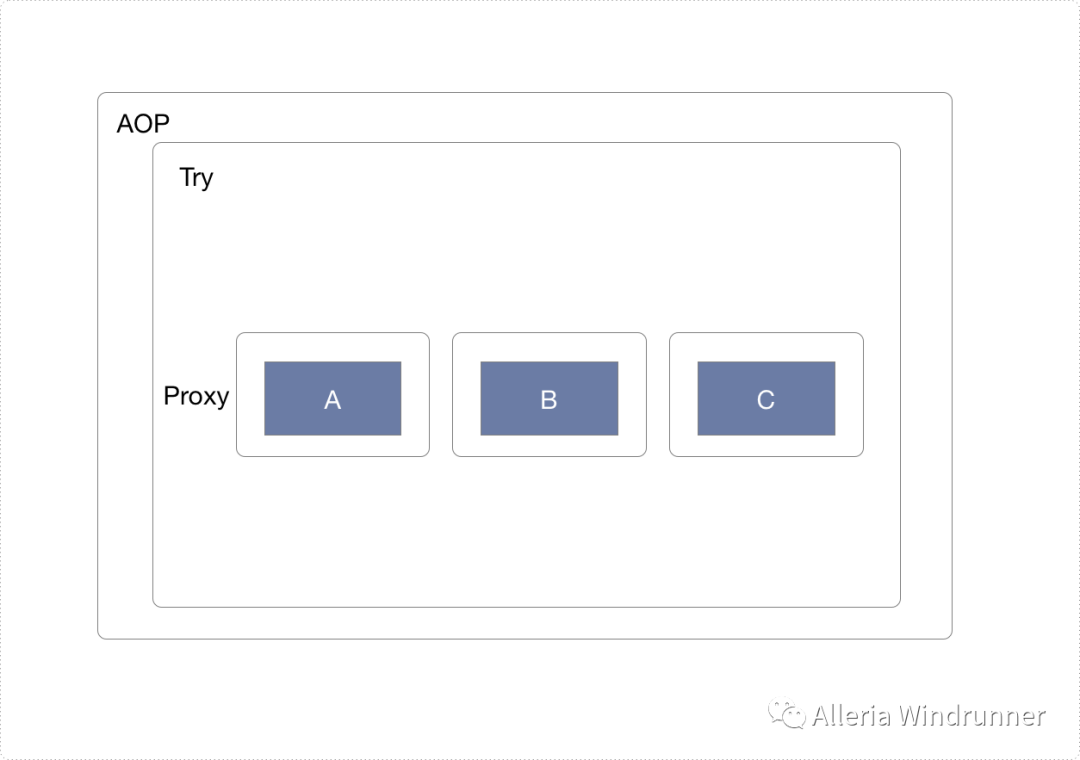
业务逻辑层的proxy是最开端也是最重要的一环,因为我们要在这里把分布式事务的步骤和参数都持久化下来。具体的步骤如下:
业务逻辑层调用加上事务注解@Around("execution(* *(..)) && @anotation(TX)")
proxy在业务逻辑层被调用的开始,生成一个全局唯一的TXID标识事务组,TXID保存在ThreadLocal变量里,方法开始前写入,完成后清除,并向分布式事务补偿服务数据库写入TXID并把事务组置为开始状态
业务逻辑层调用数据访问层之前,通过RPCProxy代理记录当前调用请求参数
如果业务正常,调用完成后,当前方法的调用记录存档或删除
如果业务异常,查询调用链反向补偿
业务逻辑层proxy设计如下:
数据访问层设计
数据访问层包涵原子接口和补偿接口的设计。原子接口也就是业务接口,比如下单接口,那补偿接口也就是将订单置为失效的接口。两个接口分开来说都很好做,关键是要把原子接口和补偿接口关联起来,因为在持久化分布式事务记录的时候需要把这些参数也记录下来,这里可以在原子接口的方法上用注解来标记补偿接口名称。还有一点,补偿接口要做幂等处理,因为补偿可能出现超时重试。
分布式事务补偿服务设计
分布式事务补偿服务的设计有三个关键点:
分布式事务主表的设计
分布式事务明细表的设计
补偿策略
首先我们来说分布式事务主表,你要记录一次分布式事务起码要有3个元素,全局唯一的txid,事务的状态state以及时间戳timestamp。其次是分布式事务明细表,此表需要记录一次分布式事务的步骤以及每个步骤的调用参数,主要字段有txid,actionid,callmethod,paramtype以及params。最后就是补偿策略,调用之行失败修改事务主表状态然后分布式事务补偿服务异步之行补偿。特别需要注意的是,如果分布式事务补偿服务本身执行失败我们就记录错误日志、报警然后人工跟进。
好了关于分布式事务的东西就聊到这里,搞清楚了处理思路实现的方式也不只这一种。关键在于把分布式事务转换为本地事务,把长事务转化为短事务,把分布式事务当订单一样对待,把相关的调用步骤和参数持久化下来,平台化思路定时做协调就行了。最后,认知才是最重要的,因为懂套路的人才厉害。
