




背景:
经巡检,发现ceph集群存储节点osd故障。查询日志后,发现为硬盘损坏,需要更换损坏硬件,重新添加osd。
正文:
以下为更换osd实施步骤:
1.确认故障osd与host对应关系
目标主机:存储控制节点
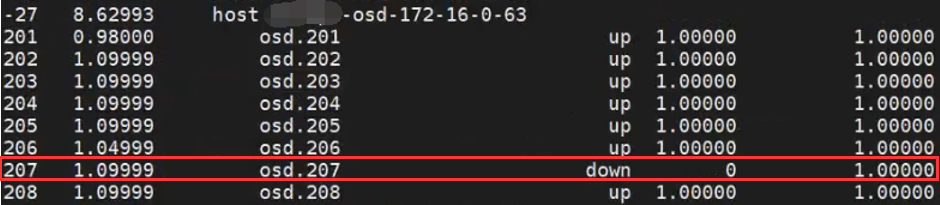
ceph osd tree | egrep 'down|host'
(或者直接使用osd tree查看)
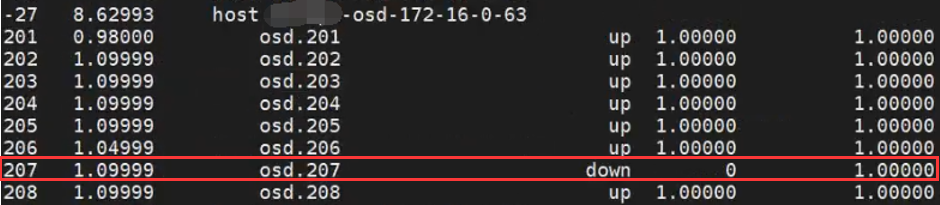
损坏的osd为osd.207,对应host 172.16.0.63
2.检查ceph集群健康状态
确保当前集群健康状态为HEALTH_OK,且所有PG处于active + clean状态(否则可能会出现pg不一致的问题)
目标主机:存储控制节点

3.查询并记录原来的 OSD 的 DATA 与 JOURNAL 对应关系
目标主机:需要处理的存储节点
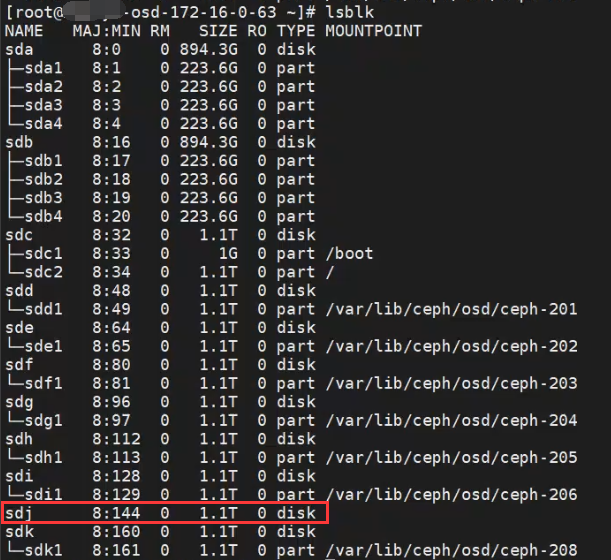
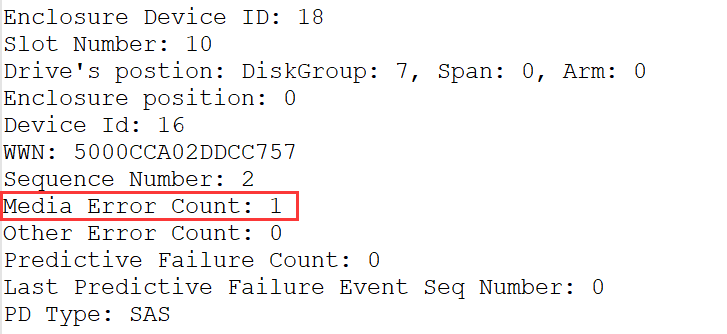
sdj硬盘挂载异常,为故障盘
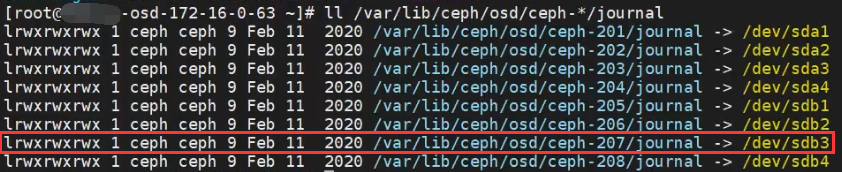
osd.207对应的日志盘(分区)为 /dev/sdb3
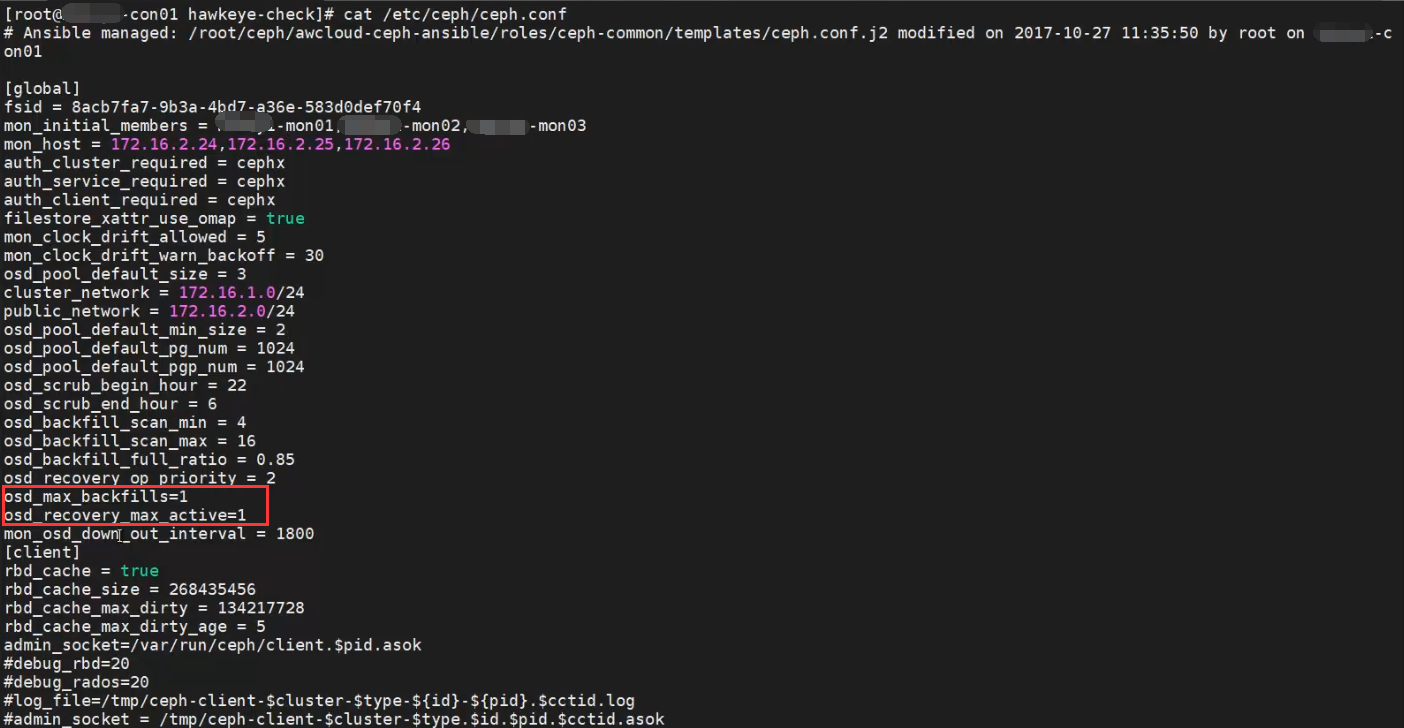
4.检查ceph参数
目标主机:存储控制节点
cat /etc/ceph/ceph.conf
确保 osd_max_backfills =1, osd_recovery_max_active = 1
5.配置ceph状态标志位
目标主机:存储控制节点
执行以下操作命令:
ceph osd set norebalance
ceph osd set nobackfill
ceph osd set noout
ceph osd set noscrub
ceph osd set nodeep-scrub
6.移除损坏的osd
目标主机:存储控制节点
替换 [id] 为需要移除的故障 osd id,此处应为osd.207
ceph osd crush reweight osd.[id] 0
ceph osd crush rm osd.[id]
ceph osd rm osd.[id]
ceph auth del osd.[id]
ceph osd crush reweight osd.207 0
ceph osd crush rm osd.207
ceph osd rm osd.207
ceph auth del osd.207
7.卸载该OSD对应的磁盘
目标主机:需要处理的存储节点
umount /dev/sdj1
如果该磁盘已无法识别,则检查目录有没有异常挂载(目录信息为“???”),存在则执行卸载目录操作。
ll /var/lib/ceph/osd/
umount -l /var/lib/ceph/osd/ceph-207
如步骤3图所示,该盘已经无挂载信息,则不需要操作。
8.更换损坏硬盘
此步骤可以直接更换硬盘,不需要对存储节点(服务器)进行关机;如果需要进入raid卡配置,则需要关机重启,不会影响现有集群,更换完成后启动服务器。
9.检查日志盘分区权限
ls -l /dev/sdb3
此处日志盘分区为步骤3查到的对应分区,权限应为ceph:ceph,若不是,则需要手动修改权限,否则osd服务启动不成功。
chown ceph:ceph /dev/sdb3

10.重新添加osd节点新硬盘至集群
方法一:在mon节点使用工具添加。
目标主机:mon节点
ceph-deploy --overwrite-conf osd prepare [hostname]:[数据盘]:[日志盘分区] --zap-disk
ceph-deploy osd activate [hostname]:[数据盘分区]
本文应执行如下命令
cd /root/ceph-cluster
ceph-deploy --overwrite-conf osd prepare hdzwy1-osd-172-16-0-63:/dev/sdj:/dev/sdb3 --zap-disk
ceph-deploy osd activate hdzwy1-osd-172-16-0-63:/dev/sdj1
方法二:在需要处理的存储节点直接添加
ceph‐disk prepare [数据盘] [日志分区] ‐‐zap‐disk ‐‐filestore
ceph‐disk activate [数据盘分区]
本文应执行如下命令:
ceph‐disk prepare /dev/sdj /dev/sdb3 ‐‐zap‐disk ‐‐filestore
ceph‐disk activate /dev/sdj1
11.检查ceph集群状态
目标主机:存储控制节点
ceph -s
加入OSD的2分钟内,会进行PG的remap操作,remap到新OSD上的PG会处于 peering状态,无法对外IO,故会对部分虚拟机造成慢请求。
如果处于peering状态的pg数量未减少,且慢请求一直持续,请执行回滚操作
12.移除 ceph 状态标志位
目标主机:存储控制节点
确认需要添加的 osd 添加完成且 pg peering 全部完成之后,执行以下操作
ceph osd unset norebalance
ceph osd unset nobackfill
13.移除剩余ceph状态标志位
待集群所有 pg 状态恢复为 active + clean 之后,执行以下操作
ceph osd unset noout
ceph osd unset noscrub
ceph osd unset nodeep-scrub
至此,ceph集群更换osd结束。
