




一、简介
Prometheus 是由前 Google 工程师从 2012 年开始在 Soundcloud 以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入 CNCF 基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目.
二、特点
Prometheus主要特点:
a multi-dimensional data model with time series data identified by metric name and key/value pairs PromQL, a flexible query language to leverage this dimensionality no reliance on distributed storage; single server nodes are autonomous time series collection happens via a pull model over HTTP pushing time series is supported via an intermediary gateway targets are discovered via service discovery or static configuration multiple modes of graphing and dashboarding support
三、组件
Prometheus server :收集并存储时间序列数据 client libraries:用于检测应用程序代码 push gateway:支持短期工作 special-purpose exporters:支持HAProxy,StatsD,Graphite等服务 alertmanager:处理警报 various support tools
官方工作架构图:
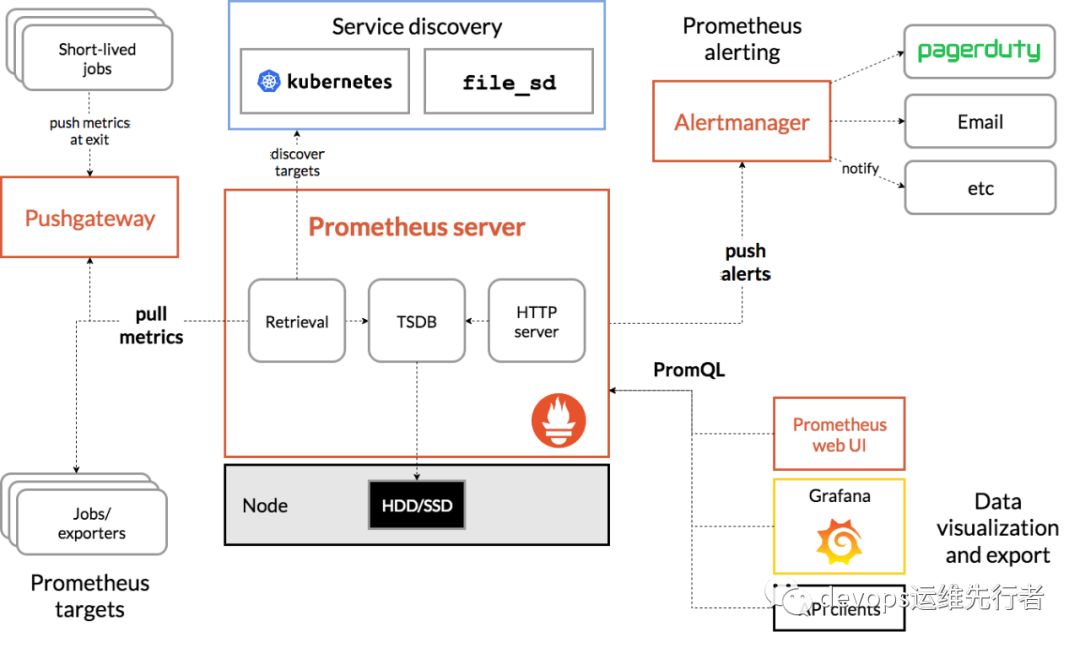
四、环境背景
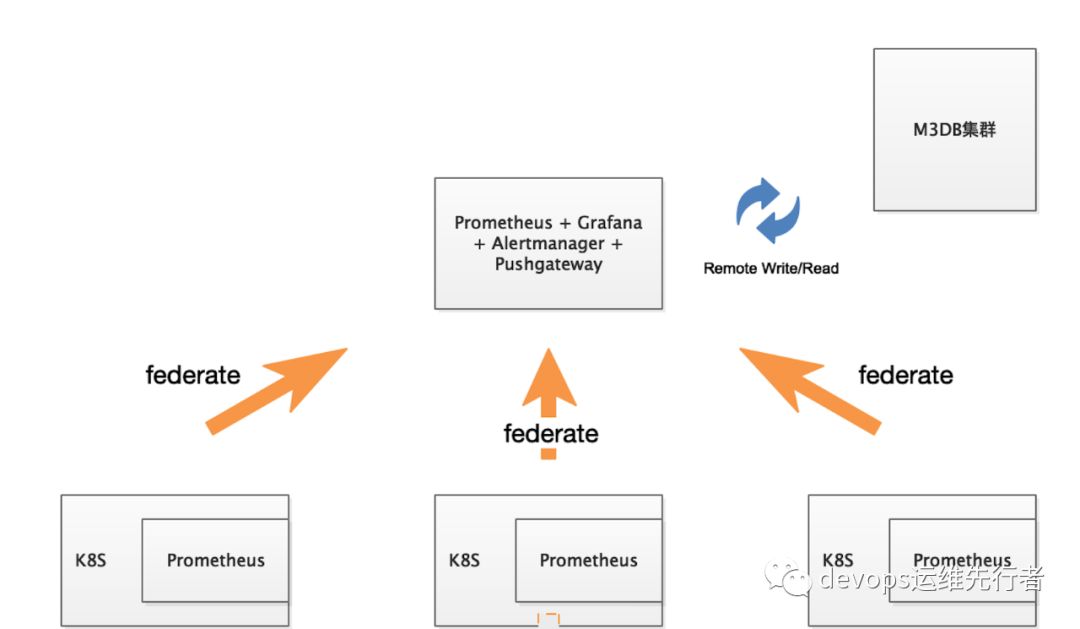
架构说明:目标环境为K8S环境,每个k8S环境都伴有一个Prometheus集群,由一个外部Prometheus通过federate采集prometheus数据,并将数据写入remote storage 远端TSDB数据库 -- M3DB,通过外部Grafana查询prometheus datasource,Alertmanager 采用Gossip协议部署高可用双节点,Pushgateway 负责接收端节点的exporter数据。
注:每个架构都不是十全十美的,上述架构有一个明显的瓶颈就是在外部prometheus上,当外部Prometheus出现资源不足时,会造成数据采集异常,并且M3DB的Coordinator出现IO资源不足时,容易造成数据读写堵塞。目前可以优化的是,K8S Prometheus集群采用Operator方式,利用k8s sidecar模式,将Prometheus的数据写入Thanos tsdb数据库,这将会大大减少单点故障的影响,并且Thanos支持更多的功能特性,想要了解的可以访问Thanos官网。出于Thanos现不支持aliyun oss的考虑,暂不采用如下方式:
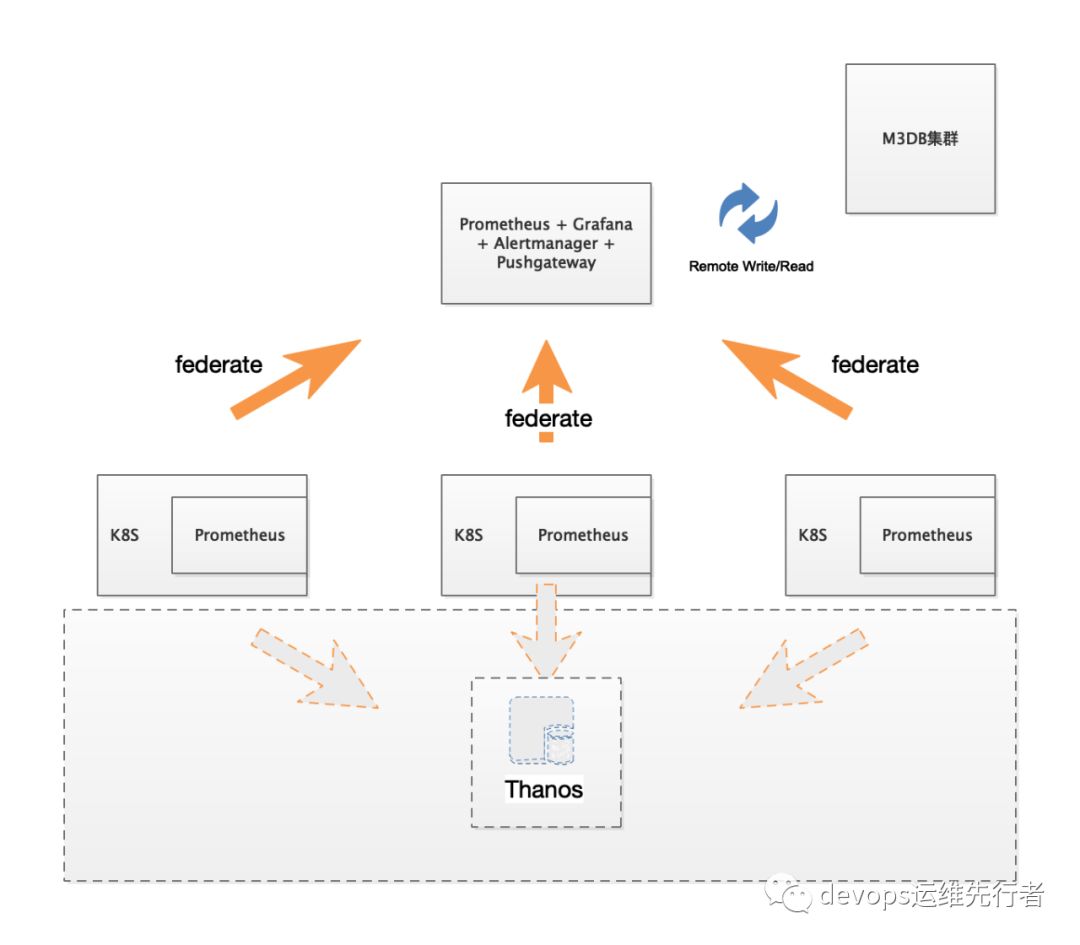
五、K8S Prometheus部署
由于公司采用的是Rancher,故K8S的prometheus集群就不具体描述,可以通过Rancher的应用商店,或者下载官方配置文件部署。需要指出的是,prometheus的端口可以通过nodeport或者ingress的方式暴露出来,在此可以假设域名为prom-01.domain.com,prom-02.domain.com
『后续外部prometheus federate用到』。考虑安全性,可以用basic-auth等方式,对端口/域名进行访问加密『公司采用Traefik v2.0的middleware进行basic-auth加密』。
六、外部Prometheus部署
外部Prometheus 采用Docker-compose的方式部署:
系统环境:
IP: 172.16.18.6 系统: centos7.4
docker images:
prometheus server: prom/prometheus:v2.14.0 alertmanager: prom/alertmanager:v0.19.0 pushgateway: prom/pushgateway:v1.0.0 grafana: grafana/grafana:6.4.4
docker-compose.yml 配置参考:
version: "3"services:prom:image: prom/prometheus:v2.14.0hostname: prom.domain.comcontainer_name: prometheusrestart: alwaysvolumes:- opt/prometheus.yml:/etc/prometheus/prometheus.yml- opt/rules.yml:/etc/prometheus/rules.yml- opt/rules:/etc/prometheus/rules- opt/prometheus:/prometheusenvironment:- STORAGE.TSDB.RETENTION=7d #prometheus本地tsdb数据保留时间为7天ports:- 9090:9090alertmanager01:image: prom/alertmanager:v0.19.0hostname: alert1.domain.comcontainer_name: alertmanager_01restart: alwaysvolumes:- opt/alertmanager.yml:/etc/alertmanager/config.ymlcommand:- '--web.listen-address=:9093'- '--cluster.listen-address=0.0.0.0:8001' #开启gossip协议- '--config.file=/etc/alertmanager/config.yml'ports:- 9093:9093- 8001:8001alertmanager02:image: prom/alertmanager:v0.19.0hostname: alert2.domain.comcontainer_name: alertmanager_02restart: alwaysdepends_on:- alertmanager01volumes:- opt/alertmanager.yml:/etc/alertmanager/config.ymlcommand:- '--web.listen-address=:9094'- '--cluster.listen-address=0.0.0.0:8002'- '--cluster.peer=172.16.18.6:8001' #slave监听- '--config.file=/etc/alertmanager/config.yml'ports:- 9094:9094- 8002:8002pushgateway:image: prom/pushgateway:v1.0.0container_name: pushgatewayrestart: alwaysports:- 9091:9091grafana:image: grafana/grafana:6.4.4hostname: grafana.domain.comcontainer_name: grafanarestart: alwaysvolumes:- opt/grafana-storage:/var/lib/grafanaports:- 3000:3000environment:- GF_SECURITY_ADMIN_PASSWORD=xxxxxx- GF_SMTP_ENABLED=true- GF_SMTP_HOST=smtp.qiye.aliyun.com:465- GF_SMTP_USER=xxxxxxx- GF_SMTP_PASSWORD=xxxxxx- GF_SMTP_FROM_ADDRESS=xxxxxxxx- GF_SERVER_ROOT_URL=http://grafana.domain.com
附各配置文件:
#prometheus.ymlglobal: # 全局设置scrape_interval: 60s # 用于向pushgateway采集数据的频率evaluation_interval: 30s # Evaluate rules every 15 seconds. The default is every 1 minute.表示规则计算的频率external_labels:cid: '1'alerting:alertmanagers:- static_configs:- targets: ['172.16.18.6:9093','172.16.18.6:9094'] #alertmanager主从节点rule_files:- etc/prometheus/rules.yml- etc/prometheus/rules/*.rulesremote_write:- url: "http://172.16.10.12:7201/api/v1/prom/remote/write" #M3DB 远程写queue_config:batch_send_deadline: 60scapacity: 40000max_backoff: 600msmax_samples_per_send: 8000max_shards: 10min_backoff: 50msmin_shards: 6remote_timeout: 30swrite_relabel_configs:- source_labels: [__name__]regex: go_.*action: drop- source_labels: [__name__]regex: http_.*action: drop- source_labels: [__name__]regex: prometheus_.*action: drop- source_labels: [__name__]regex: scrape_.*action: drop- source_labels: [__name__]regex: go_.*action: drop- source_labels: [__name__]regex: net_.*action: drop- source_labels: ["kubernetes_name"]regex: prometheus-node-exporteraction: drop- source_labels: [__name__]regex: rpc_.*action: keep- source_labels: [__name__]regex: jvm_.*action: keep- source_labels: [__name__]regex: net_.*action: drop- source_labels: [__name__]regex: crd.*action: drop- source_labels: [__name__]regex: kube_.*action: drop- source_labels: [__name__]regex: etcd_.*action: drop- source_labels: [__name__]regex: coredns_.*action: drop- source_labels: [__name__]regex: apiserver_.*action: drop- source_labels: [__name__]regex: admission_.*action: drop- source_labels: [__name__]regex: DiscoveryController_.*action: drop- source_labels: ["job"]regex: kubernetes-apiserversaction: drop- source_labels: [__name__]regex: container_.*action: dropremote_read:- url: "http://172.16.7.172:7201/api/v1/prom/remote/read" #M3DB 远程读read_recent: truescrape_configs:#基于consul服务发现# - job_name: 'consul-prometheus'# metrics_path: metrics# scheme: http# consul_sd_configs:# - server: '172.16.18.6:8500'# scheme: http# services: ['ops']# refresh_interval: 1m#基于文件的服务发现- job_name: 'file_ds'file_sd_configs:- refresh_interval: 30sfiles:- prometheus/*.json# - job_name: 'm3db'# static_configs:# - targets: ['172.16.10.12:7203']- job_name: 'federate'scrape_interval: 15shonor_labels: truemetrics_path: '/federate'params:'match[]':- '{job=~"kubernetes-.*"}'static_configs:- targets:- 'prom-01.domain.com'- 'prom-02.domain.com' #k8s prometheus域名或者ip:portbasic_auth:username: xxxxpassword: xxxxxxxrelabel_configs:- source_labels: [__name__]regex: http_.*action: drop- source_labels: [__name__]regex: prometheus_.*action: drop- source_labels: [__name__]regex: scrape_.*action: drop- source_labels: [__name__]regex: go_.*action: drop
#alertmanager.yml# 全局配置项global:resolve_timeout: 5m #处理超时时间,默认为5minsmtp_smarthost: 'smtp.qq.com:587'smtp_from: 'xxxxxxx@qq.com'smtp_auth_username: 'xxxxxxxxx@qq.com'smtp_auth_password: 'xxxxxxxxxx'smtp_require_tls: true# 定义路由树信息route:group_by: ['alertname'] #定义分组规则标签group_wait: 30s #定义一定时间内等待接收新的告警group_interval: 1m #定义相同Group之间发送告警通知的时间间隔repeat_interval: 1h #发送通知后的静默等待时间receiver: 'bz' # 发送警报的接者的名称,以下receivers name的名称routes:- receiver: bzmatch:severity: red|yellow #与rules.yml里labels对应# 定义警报接收者信息receivers:- name: 'bz'email_configs:- to: "xiayun@domain.com"send_resolved: truewebhook_configs:- send_resolved: trueurl: http://172.16.18.6:8060/dingtalk/webhook1/send# 一个inhibition规则是在与另一组匹配器匹配的警报存在的条件下,使匹配一组匹配器的警报失效的规则。两个警报必须具有一组相同的标签。inhibit_rules:- source_match:alertname: InstanceDownseverity: redtarget_match:severity: yellowequal: ['instance']
#rules.ymlgroups:- name: hostStatsAlertrules:#####server pod down- alert: InstanceDownexpr: up{job=~"prometheus"} != 1for: 1mlabels:severity: redwarn: highapps: prometheusannotations:summary: "Instance {{$labels.instance}} down"description: "{{$labels.instance}} of job {{$labels.job}} has been down for more than 1 minutes."- alert: CPULoad5Highexpr: node_load5 > 10for: 1mlabels:severity: yellowannotations:summary: "Instance {{$labels.instance}} CPU load-5m High"description: "{{$labels.instance}} of job {{$labels.job}} CPU load-5m was greater than 10 for more than 1 minutes (current value: {{ $value }})."- alert: FilesystemFreeexpr: node_filesystem_free_bytes{fstype!~"nsfs|rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} node_filesystem_size_bytes{fstype!~"nsfs|rootfs|selinuxfs|autofs|rpc_pipefs|tmpfs|udev|none|devpts|sysfs|debugfs|fuse.*"} < 0.05for: 1mlabels:severity: yellowannotations:summary: "Instance {{$labels.instance}} filesystem bytes was less than 5%"description: "{{$labels.instance}} of job {{$labels.job}} filesystem bytes usage above 95% (current value: {{ $value }}"- name: k8s-promrules:- alert: K8sPrometheusDownexpr: up{job=~"prometheus"} != 1for: 1mlabels:severity: redwarn: highapps: prometheusannotations:summary: "Prometheus {{$labels.instance}} down"description: "{{$labels.instance}} of job {{$labels.job}} has been down for more than 1 minutes."- alert: K8sNodeDownexpr: up{job=~"kubernetes-nodes"} != 1for: 1mlabels:severity: redwarn: highapps: nodeannotations:summary: "K8s node {{$labels.instance}} down"description: "{{$labels.instance}} of job {{$labels.job}} has been down for more than 1 minutes."
安装docker环境
# 安装依赖包yum install -y yum-utils device-mapper-persistent-data lvm2# 添加Docker软件包源yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo# 安装Docker CEyum install docker-ce -y# 启动systemctl start docker# 开机启动systemctl enable docker# 查看Docker信息docker info
安装docker-compose
curl -L https://github.com/docker/compose/releases/download/1.23.2/docker-compose-`uname -s`-`uname -m` -o usr/local/bin/docker-composechmod +x usr/local/bin/docker-compose
启停
#在docker-compose.yml目录下执行docker-compose up -d #启docker-compose down #停docker-compose restart #重启
 由于prometheus采用remote storage,所以暂时不启动,等下面M3DB部署完成再启动。
由于prometheus采用remote storage,所以暂时不启动,等下面M3DB部署完成再启动。
七、M3DB 集群部署
M3特性
M3具有作为离散组件提供的多个功能,使其成为大规模时间序列数据的理想平台:
分布式时间序列数据库M3DB,它为时间序列数据和反向索引提供可伸缩的存储。 辅助进程M3Coordinator,允许M3DB充当Prometheus的长期存储。 分布式查询引擎M3Query,其对PromQL和Graphite的原生支持(即将推出M3QL)。 聚合层M3Aggregator,作为专用的度量聚合器/下采样器运行,允许以不同的分辨率以各种保留方式存储度量。
为什么选择M3DB
其实在选用M3DB之前,我们有尝试过timescaleDB与InfluxDB,由于timescaleDB依赖PG数据库『不熟悉···』,InfluxDB分片功能收费,考量之下选择了M3DB,M3DB其实刚开源,文档真的很少,相对于其它TSDB,数据压缩比还算不错。
集群部署
M3DB集群管理建立在etcd之上,所以需要一个etcd集群,具体可拜读官网。
环境
172.16.7.170 node1 172.16.7.171 node2 172.16.7.172 node3 172.16.10.12 coordinator
etcd集群部署
yum install etcd -y
#etcd配置文件/etc/etcd/etcd.confETCD_DATA_DIR="/etcd-data"ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"ETCD_NAME="node1" #依次为node2,node3ETCD_INITIAL_ADVERTISE_PEER_URLS="http://node1:2380"ETCD_ADVERTISE_CLIENT_URLS="http://node1:2379"ETCD_INITIAL_CLUSTER="node1=http://node1:2380,node2=http://node2:2380,node3=http://node3:2380"ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"ETCD_INITIAL_CLUSTER_STATE="new"
依次启动etcd节点systemctl start etcd
M3DB集群部署
mkdir opt/m3db etcd-data/m3db/cache -p
cat << EOF >/opt/m3db/m3dbnode.ymlcoordinator:listenAddress:type: "config"value: "0.0.0.0:7201" # 交互端口local:namespaces:- namespace: default # 数据要存入的表type: unaggregated # 数据类型retention: 720h # 数据保存时间logging:level: errormetrics: # coordinator本身的metricscope:prefix: "coordinator"prometheus:handlerPath: metricslistenAddress: 0.0.0.0:7203 # until https://github.com/m3db/m3/issues/682 is resolvedsanitization: prometheussamplingRate: 1.0extended: nonelimits:maxComputedDatapoints: 10000tagOptions:# Configuration setting for generating metric IDs from tags.idScheme: quoted # 这个必须db:logging:level: errormetrics:prometheus:handlerPath: /metricssanitization: prometheussamplingRate: 1.0extended: detailedlistenAddress: 0.0.0.0:9000clusterListenAddress: 0.0.0.0:9001httpNodeListenAddress: 0.0.0.0:9002httpClusterListenAddress: 0.0.0.0:9003debugListenAddress: 0.0.0.0:9004hostID: #采用此配置文件自定义hostnameresolver: configvalue: node1 #hostname为 node1,其余节点依次为node2,node3,node4[coordinator]client:writeConsistencyLevel: majority # 写一致性级别readConsistencyLevel: unstrict_majoritygcPercentage: 100writeNewSeriesAsync: truewriteNewSeriesLimitPerSecond: 1048576writeNewSeriesBackoffDuration: 2msbootstrap:bootstrappers: # 启动顺序- filesystem- commitlog- peers- uninitialized_topologycommitlog:returnUnfulfilledForCorruptCommitLogFiles: falsecache:series:policy: lrupostingsList:size: 262144commitlog:flushMaxBytes: 524288flushEvery: 1squeue:calculationType: fixedsize: 2097152fs:filePathPrefix: /etcd-data/m3db # m3dbnode数据目录config:service:env: default_envzone: embeddedservice: m3db # 服务名。可以按照consul中的service进行理解cacheDir: /etcd-data/m3db/cacheetcdClusters:- zone: embeddedendpoints:- node1:2379- node2:2379- node3:2379EOF
依次启动
docker run -d -v /opt/m3db/m3dbnode.yml:/etc/m3dbnode/m3dbnode.yml -v /etcd-data/m3db:/etcd-data/m3db -p 7201:7201 -p 7203:7203 -p 9000:9000 -p 9001:9001 -p 9002:9002 -p 9003:9003 -p 9004:9004 --name m3db quay.io/m3db/m3dbnode:latest
初始化
placement init
curl -sSf -X POST localhost:7201/api/v1/placement/init -d '{"num_shards": 1024,"replication_factor": 3,"instances": [{"id": "node1","isolation_group": "node1","zone": "embedded","weight": 100,"endpoint": "172.16.7.170:9000","hostname": "172.16.7.170","port": 9000},{"id": "node2","isolation_group": "node2","zone": "embedded","weight": 100,"endpoint": "172.16.7.171:9000","hostname": "172.16.7.171","port": 9000},{"id": "node3","isolation_group": "node3","zone": "embedded","weight": 100,"endpoint": "172.16.7.172:9000","hostname": "172.16.7.172","port": 9000},{"id": "node4","isolation_group": "node4","zone": "embedded","weight": 99,"endpoint": "172.16.10.12:9000","hostname": "172.16.10.12","port": 9000}]}'
namespace init
curl -X POST localhost:7201/api/v1/namespace -d '{"name": "default","options": {"bootstrapEnabled": true,"flushEnabled": true,"writesToCommitLog": true,"cleanupEnabled": true,"snapshotEnabled": true,"repairEnabled": false,"retentionOptions": {"retentionPeriodDuration": "720h","blockSizeDuration": "12h","bufferFutureDuration": "1h","bufferPastDuration": "1h","blockDataExpiry": true,"blockDataExpiryAfterNotAccessPeriodDuration": "5m"},"indexOptions": {"enabled": true,"blockSizeDuration": "12h"}}}'
etcd的故障容忍程度如图: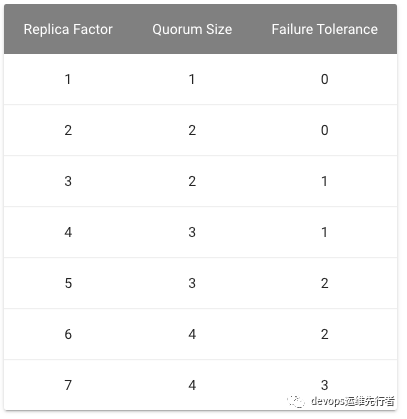 本集群可容忍1个节点的故障,2个及以上故障时会引起集群不可用。
本集群可容忍1个节点的故障,2个及以上故障时会引起集群不可用。
八、Prometheus remote Write/Read
外部Prometheus节点启动:docker-compose up -d
Ending 部署完成
想了解prometheus 基于springcloud监控的,可以查看公众号历史文章。
历史文章
k8s traefik配置custom headers: AccessControlAllowHeaders CORS问题
Traefik - Kubernetes 配置服务basic auth验证

