




作为一名数据打工人,窗口函数是我们的老朋友了。在日常工作中,学会和窗口函数好好相处,能够让我们的工作事半功倍。
在本文中,我们将先简单复习一下窗口函数,然后通过案例来了解不同窗口函数的应用场景和使用技巧。文中将会附上对应的 Spark SQL 和 PySpark代码实现。
一、 窗口函数介绍
1.1 厘清概念
a. 聚合函数是将多条记录聚合运算为一条,是数据聚合过程;窗口函数是就每一条记录对应的窗口进行运算,返回一个对应值,不改变记录的条数。
b. 窗口函数的执行顺序是在 FROM、JOIN、WHERE、GROUP BY、HAVING之后,在ORDER BY、LIMIT、SELECT、DISTINCT之前。它执行时 GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。
c. 当窗口函数和聚合函数一起使用时,窗口函数是基于聚合后的数据执行的。
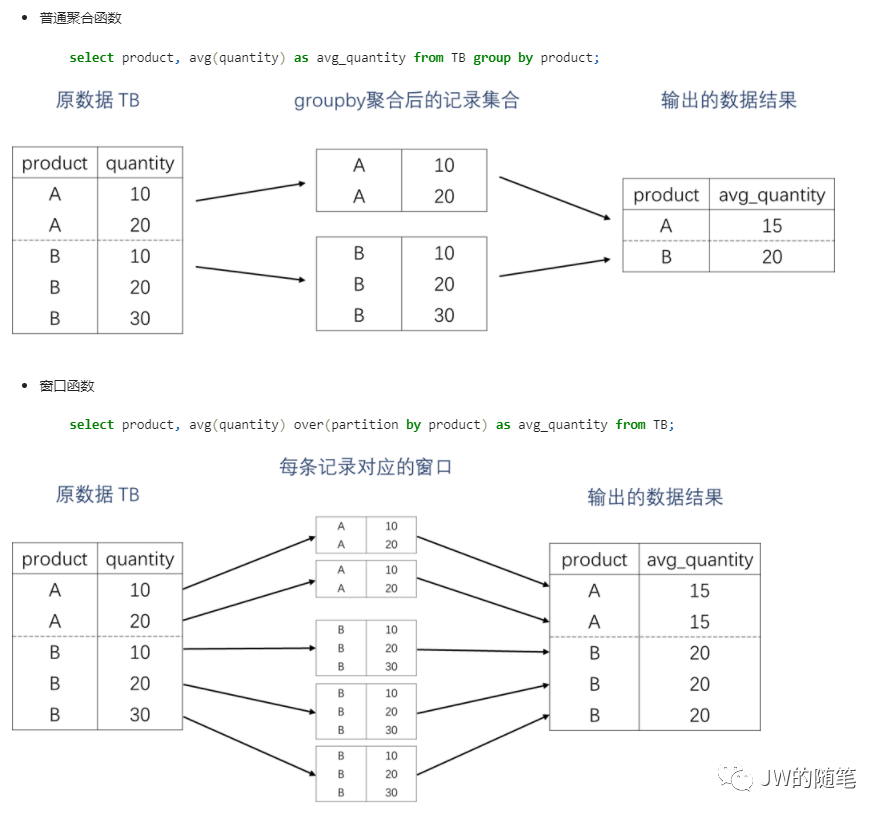
1.2 窗口函数的使用语法
窗口函数使用时由“窗口函数”和over从句组成;其中,over从句分为三部分:分组(partition by)、排序(order by)、frame选取(rangeBetween 和 rowsBetween)。
SQL和PySpark的写法分别如下所示:

分布函数:percent_rank()、cume_dist()序号函数:row_number()、rank()、dense_rank()前后函数:lag()、lead()头尾函数:first()、last()其他函数:如分桶函数 nth_value()
1.4 over从句中的frame子句
1.4.1 讲讲你可能不知道的frame子句语法默认规则

1.4.2 frame子句格式规范

二、窗口函数应用案例(SQL & Pyspark)
2.1 数据准备
在本节中,我们创建并使用南华西地区2010~2019年销售量数据进行讲解,数据和创建代码如下:
# 我们先来创建一个SparkSession实例,并配置好相关参数import osimport sysimport numpy as npimport pandas as pdimport pyspark.sql.functions as ffrom pyspark.sql import Windowfrom pyspark.sql import SparkSessionos.environ["PYSPARK_DRIVER_PYTHON"] = "/usr/bin/python3.6"os.environ["PYSPARK_PYTHON"] = "/usr/bin/python3.6"os.environ["SPARK_HOME"] = "/opt/app/spark-2.2.0"# 获取一个SparkSession的实例spark = (SparkSession.builder.master("yarn").appName("Window_JW").config("spark.sql.execution.arrow.enabled", "true").config("spark.debug.maxToStringFields", "9999").config('spark.executor.memory', '8g').config('spark.driver.memory', '48g').enableHiveSupport().getOrCreate())spark.conf.set("spark.sql.execution.arrow.enabled", "true")test_sdf = spark.createDataFrame([('华南', 2010, 60),('华南', 2011, 70),('华南', 2012, None),('华南', 2013, 80),('华南', 2014, 80),('华南', 2015, None),('华南', 2016, 90),('华南', 2017, 90),('华南', 2018, 100),('华南', 2019, 120),('华西', 2010, None),('华西', 2011, 90),('华西', 2012, 90),('华西', 2013, 90),('华西', 2014, None),('华西', 2015, 100),('华西', 2016, 70),('华西', 2017, None),('华西', 2018, 120),('华西', 2019, 100)]).toDF("district", "year", "quantity")# 可以使用 createOrReplaceTempView() 将 spark_dataframe 注册成一张临时的hive表:test_sdf.createOrReplaceTempView("temp_table_sales_data")# 数据预览如下test_sdf.show()

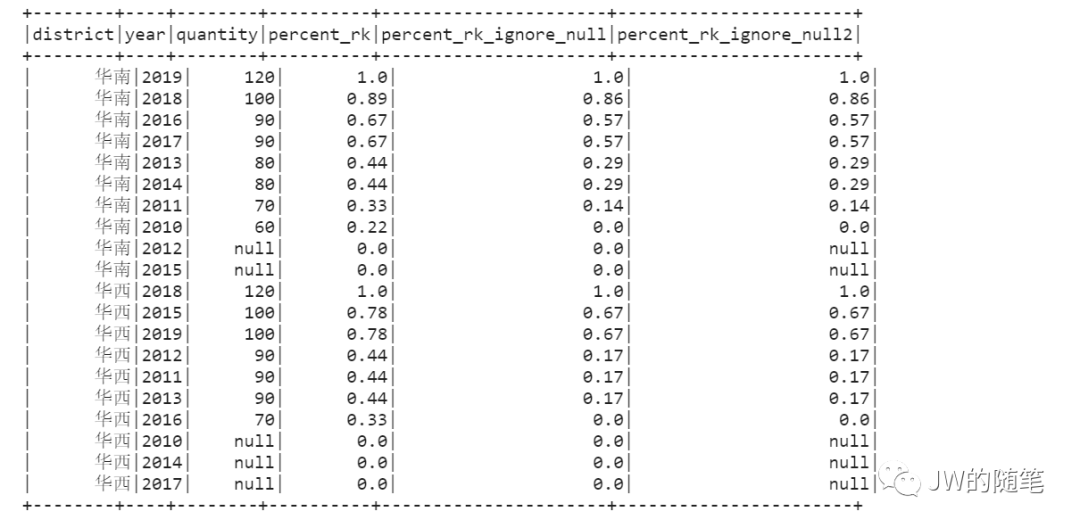
2.2 分布函数 —— 巧用 <colname> is not null 进行分组

SQL:adding <colname> is not null
sql_percent_rank = spark.sql("""select district, year, quantity, round(percent_rank() over(partition by district order by quantity asc), 2) as percent_rk, round(percent_rank() over(partition by quantity is not null, district order by quantity asc), 2) as percent_rk_ignore_null, case when quantity is not nullthen round(percent_rank() over(partition by quantity is not null, district order by quantity asc), 2)else null end as percent_rk_ignore_null2from temp_table_sales_dataorder by district, quantity desc""")sql_percent_rank.show()
Pyspark:adding isnull("colname")
pyspark_percent_rank = (test_sdf.withColumn("percent_rk",f.round(f.percent_rank().over(Window.partitionBy("district").orderBy(f.asc("quantity"))), 2)).withColumn("percent_rk_ignore_null",f.round(f.percent_rank().over(Window.partitionBy(f.isnull("quantity"), "district").orderBy(f.asc("quantity"))), 2)).withColumn("percent_rk_ignore_null2",f.when(~f.isnull("quantity"),f.round(f.percent_rank().over(Window.partitionBy(f.isnull("quantity"), "district").orderBy(f.asc("quantity"))), 2))))pyspark_percent_rank.orderBy("district", f.desc("quantity")).show()
结果如下:
2.3 序号函数 —— 使用 `NULLs last` 将 NULL值 放置最后;或者增加一个排序列 <colname> is null 达到同样效果

Question:升序排序时,序号函数会将NULL值排在首位,是否可以将NULL值排在最后?
SQL:adding nulls last
sql_row_number_rank = spark.sql("""select district, year, quantity, row_number() over(partition by district order by quantity asc) as row_number_rk, row_number() over(partition by district order by quantity asc nulls last) as row_number_rk_nulls_last1, row_number() over(partition by district order by quantity is null, quantity asc) as row_number_rk_nulls_last2from temp_table_sales_dataorder by district, row_number_rk asc""")sql_row_number_rank.show()
Pyspark:using `asc_nulls_first`
# 由于目前pyspark版本无法使用asc_nulls_first()函数,仅演示增加一列排序列isnull("quantity")的效果。pyspark_row_number_rank = (test_sdf.withColumn("row_number_rk",f.row_number().over(Window.partitionBy("district").orderBy(f.asc("quantity")))).withColumn("row_number_rk_nulls_last2",f.row_number().over(Window.partitionBy("district").orderBy(f.isnull("quantity"), f.asc("quantity")))).orderBy("district", "row_number_rk"))pyspark_row_number_rank.show()
结果如下:

2.4 前后函数 ——常用于求解“曾经连续 N 年出现某种行为”

Question:类似“曾经连续 N 年销售量都未曾增长的地区” 这类问题如何求解?

以“求曾经连续3年销售量都未曾增长的地区” 为例:
SQL
# Step1:找到之后第三次出现同销售量时对应的年份 later_thrid_year# Step2. 只有 later_thrid_year 和 当前年份 相差2年时,才是连续3年未曾增长sql_quantity_maintain_step2 = spark.sql("""select tb.district as districtfrom(select district, year, lead(year, 2) over(partition by district, quantity order by year asc) as later_thrid_yearfrom temp_table_sales_datawhere quantity is not null) tbwhere tb.later_thrid_year is not nulland tb.later_thrid_year - tb.year = 2group by tb.district""")sql_quantity_maintain_step2.show()
Pyspark
pyspark_quantity_maintain = (test_sdf.where("quantity is not null").withColumn("later_thrid_year",f.lead("year", 2).over(Window.partitionBy("district", "quantity").orderBy(f.asc("year")))).where("later_thrid_year is not null and later_thrid_year - year = 2").select("district").drop_duplicates())pyspark_quantity_maintain.show()
在这份数据中,只有华西地区符合题意。
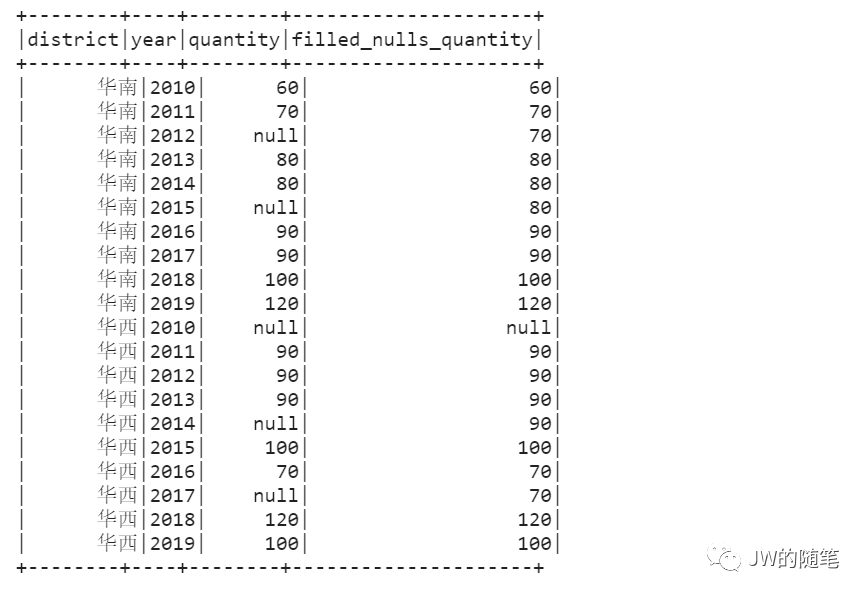
2.5 头尾函数 —— 常用于缺失值填补

Question:对各个区域中销售量缺失值,使用按年份往前推第一个非缺失数据填补,如何操作?
SQL:spark sql 不支持 ignore nulls
语法,没有找到简洁的写法!
# 使用传统解法:借助 row_number() 窗口函数求解sql_filled_nulls_quantity = spark.sql("""select tb.district as district, tb.year as year, tb.quantity as quantity, tb.filled_nulls_quantity as filled_nulls_quantityfrom(select a.district as district, a.year as year, a.quantity as quantity, row_number() over(partition by a.district, a.year order by b.year desc) as rk, b.quantity as filled_nulls_quantityfrom temp_table_sales_data aleft join(select district, year, quantityfrom temp_table_sales_datawhere quantity is not null) bon a.district = b.district and a.year >= b.year) tbwhere tb.rk = 1order by tb.district, tb.year""")sql_filled_nulls_quantity.show()
Pyspark
pyspark_quantity_maintain = (test_sdf.withColumn("filled_nulls_quantity",f.last("quantity", ignorenulls=True).over(Window.partitionBy("district").orderBy(f.asc("year")))).orderBy("district", "year"))pyspark_quantity_maintain.show()
结果如下:
三、over从句相关应用案例
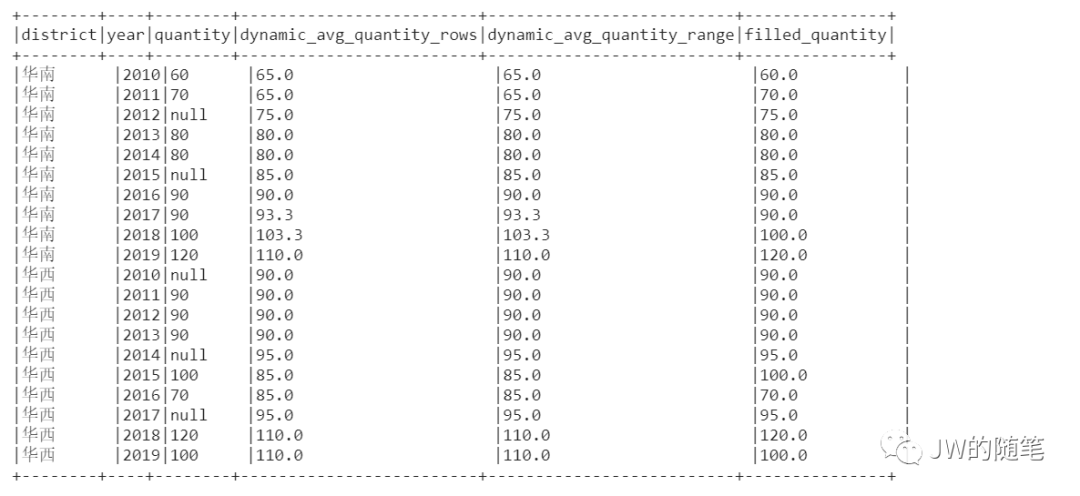
3.1 frame子句 —— 不得不提的动态窗口
range是逻辑窗口,通过指定列(列数不固定)行值的范围来定义窗口框架。即根据order by 子句中指定列,只要行值在当前行对应行值范围内,就在当前行的对应窗口内。
rows是物理窗口,通过当前行中指定物理偏移来定义窗口框架。即根据order by 子句排序后,取当前行的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)。
Question:对各个区域中销售量缺失值,使用当前区域前一年和后一年的均销售量值填充,如何操作?
错误解法:大家往往会惯性选择rows从句,当年份缺失时,计算结果就不对了。
正确解法:使用range从句。
SQL
sql_dynamic_windows = spark.sql("""select district, year, quantity, round(avg(quantity) over(partition by district order by year asc rows between 1 preceding and 1 following), 1) as dynamic_avg_quantity_rows, round(avg(quantity) over(partition by district order by year asc range between 1 preceding and 1 following), 1) as dynamic_avg_quantity_range, coalesce(quantity, round(avg(quantity) over(partition by district order by year asc range between 1 preceding and 1 following), 1)) as filled_quantityfrom temp_table_sales_datawhere district = '华西' or (district = '华南' and year <> 2013)order by district, year""")sql_dynamic_windows.show(truncate = False)
Pyspark
pyspark_dynamic_windows = (test_sdf.withColumn("dynamic_avg_quantity_rows",f.round(f.avg("quantity").over(Window.partitionBy("district").orderBy(f.asc("year")).rowsBetween(Window.currentRow - 1, Window.currentRow + 1)), 1)).withColumn("dynamic_avg_quantity_range",f.round(f.avg("quantity").over(Window.partitionBy("district").orderBy(f.asc("year")).rangeBetween(Window.currentRow - 1, Window.currentRow + 1)), 1)).withColumn("filled_quantity",f.coalesce(f.col("quantity"), f.col("dynamic_avg_quantity_range"))).orderBy("district", "year"))pyspark_dynamic_windows.show(truncate = False)
四、其他小技巧
4.1 如何使用窗口函数实现distinct操作
Question:窗口函数不支持直接使用distinct操作,如果不想进行groupby操作,可以如何实现distinct操作呢?
Answer:先使用 collect_set 进行聚合操作,生成去重后的list,然后使用 size() 函数对 list 进行计算操作。
SQL
sql_quantity_maintain_step1 = spark.sql("""select district, year, collect_set(quantity) over(partition by district) as quantity_sets, size(collect_set(quantity) over(partition by district)) as quantity_kindsfrom temp_table_sales_dataorder by district, year""")sql_quantity_maintain_step1.show(truncate = False)
Pyspark
pyspark_quantity_maintain = (test_sdf.withColumn("quantity_sets",f.collect_set("quantity").over(Window.partitionBy("district"))).withColumn("quantity_kinds", f.size("quantity_sets")).orderBy("district", "year"))pyspark_quantity_maintain.show(truncate = False)
结果如下:

- 版权声明 -
文章版权属于本文作者
若有侵权,请联系本公众号删除或修改~
如有问题,欢迎留言~
