




JDBC概述
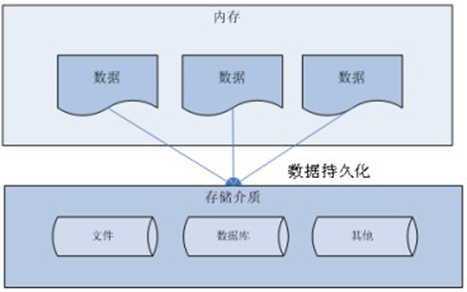
- 数据持久化
持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用。大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以”固化”,而持久化的实现过程大多通过各种关系数据库来完成。
持久化的主要应用是将内存中的数据存储在关系型数据库中,当然也可以存储在磁盘文件、XML数据文件中。
- Java中的数据存储技术
在Java中,数据库存取技术可分为如下几类:
JDBC直接访问数据库
JDO (Java Data Object )技术
第三方O/R工具,如Hibernate, Mybatis 等
JDBC是java访问数据库的基石,JDO、Hibernate、MyBatis等只是更好的封装了JDBC。
- JDBC介绍
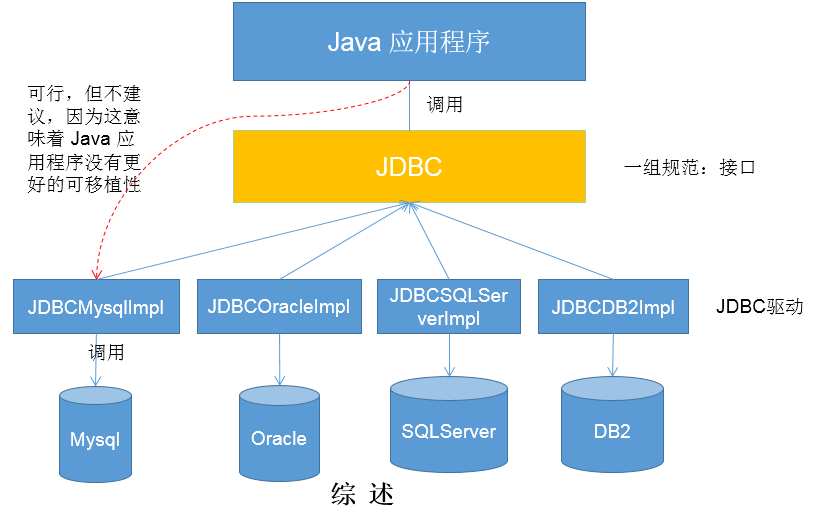
JDBC是SUN公司提供的一套用于数据库操作的接口,Java程序员只需要面向这套接口编程即可。不同的数据库厂商,需要针对这套接口,提供不同实现。不同的实现的集合,即为不同的数据库驱动。--面向接口的编程
JDBC(Java Database Connectivity)是一个独立于特定数据库管理系统、通用的SQL数据库存取和操作的公共接口(一组API),定义了用来访问数据库的标准Java类库,(java.sql,javax.sql)使用这些类库可以以一种标准的方法、方便地访问数据库资源。
JDBC为访问不同的数据库提供了一种统一的途径,为开发者屏蔽了一些细节问题。
JDBC的目标是使Java程序员使用JDBC可以连接任何提供了JDBC驱动程序的数据库系统,这样就使得程序员无需对特定的数据库系统的特点有过多的了解,从而大大简化和加快了开发过程。
- JDBC体系结构
JDBC接口(API)包括两个层次:
面向应用的API:Java API,抽象接口,供应用程序开发人员使用(连接数据库,执行SQL语句,获得结果)。
面向数据库的API:Java Driver API,供开发商开发数据库驱动程序用。
- JDBC程序编写步骤
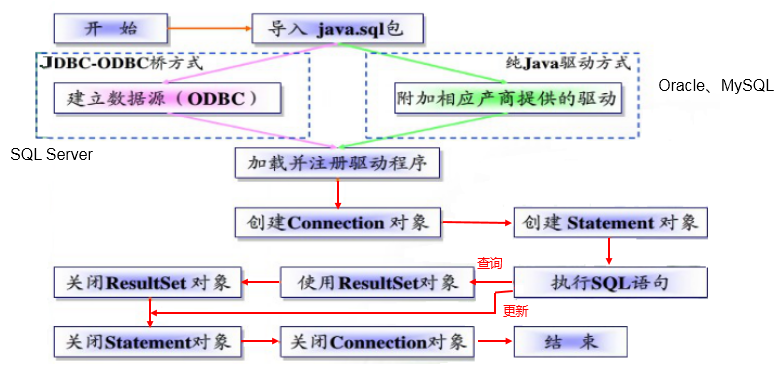
数据库连接
实现数据库连接的方式有多种,本次记录使用配置文件方式获取数据连接。使用配置文件好处如下
实现了代码和数据的分离,如果需要修改配置文件,直接在配置文件中修改,不需要深入代码
如果修改了配置信息,省去重新编译的过程
public void testConnect() throws Exception {//1.加载配置文件InputStream is = ConnectionTest.class.getClassLoader().getResourceAsStream("jdbc.properties");Properties pros = new Properties();pros.load(is);//2.读取配置信息String user = pros.getProperty("user");String password = pros.getProperty("password");String url = pros.getProperty("url");String driverClass = pros.getProperty("driverClass");//3.加载驱动Class.forName(driverClass);//4.获取连接Connection conn = DriverManager.getConnection(url,user,password);System.out.println(conn);}
其中,配置文件声明在工程的src目录下: [jdbc.properties]
user=rootpassword=123456url=jdbc:mysql://localhost:3306/testdriverClass=com.mysql.jdbc.Driver
使用PreparedStatement实现CURD操作
- 操作和访问数据库
数据库连接被用于向数据库服务器发送命令和SQL语句,并接受数据库服务器返回的结果。其实一个数据库连接就是一个Socket连接
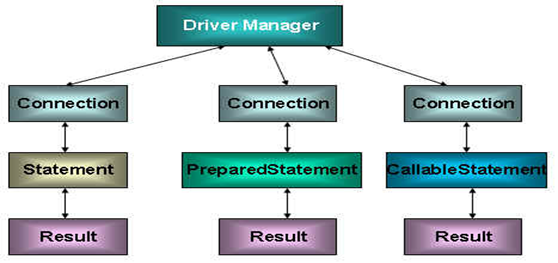
在java.sql包有3个接口分别定义了对数据库的调用的不同方式:
Statement:用于执行静态 SQL 语句并返回它所生成结果的对象。
PrepatedStatement:SQL 语句被预编译并存储在此对象中,可以使用此对象多次高效地执行该语句。
CallableStatement:用于执行 SQL 存储过程
- 使用Statement操作数据表的弊端
问题一:存在拼串操作,繁琐
问题二:存在SQL注入问题
SQL 注入是利用某些系统没有对用户输入的数据进行充分的检查,而在用户输入数据中注入非法的 SQL 语句段或命令(如:SELECT user, password FROM user_table WHERE user='a' OR 1 = ' AND password = ' OR '1' = '1') ,从而利用系统的 SQL 引擎完成恶意行为的做法。对于 Java 而言,要防范 SQL 注入,只要用 PreparedStatement(从Statement扩展而来) 取代 Statement 就可以了。
- PreparedStatement的使用
PreparedStatement介绍
可以通过调用 Connection 对象的 preparedStatement(String sql) 方法获取 PreparedStatement 对象
PreparedStatement 接口是 Statement 的子接口,它表示一条预编译过的 SQL 语句
PreparedStatement 对象所代表的 SQL 语句中的参数用问号(?)来表示,调用 PreparedStatement 对象的 setXxx() 方法来设置这些参数. setXxx() 方法有两个参数,第一个参数是要设置的 SQL 语句中的参数的索引(从 1 开始),第二个是设置的 SQL 语句中的参数的值
使用PreparedStatement实现增删改的操作
//通用的增、删、改操作(体现一:增、删、改 ;体现二:针对于不同的表)public void update(String sql,Object ... args){Connection conn = null;PreparedStatement ps = null;try {//1.获取数据库的连接conn = JDBCUtils.getConnection();//2.获取PreparedStatement的实例 (或:预编译sql语句)ps = conn.prepareStatement(sql);//3.填充占位符for(int i = 0;i < args.length;i++){ps.setObject(i + 1, args[i]);}//4.执行sql语句ps.execute();} catch (Exception e) {e.printStackTrace();}finally{//5.关闭资源JDBCUtils.closeResource(conn, ps);}}
使用PreparedStatement实现查询操作
public <T> List<T> getForList(Class<T> clazz, String sql, Object ...args){Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;List<T> list = null;try{conn = JDBCUtils.getConnection();ps = conn.prepareStatement(sql);for(int i=0;i<args.length;i++){ps.setObject(i+1,args[i]);}rs = ps.executeQuery();ResultSetMetaData metaData = rs.getMetaData();int columnCount = metaData.getColumnCount();while(rs.next()){T t = clazz.getDeclaredConstructor().newInstance();for(int i=1;i<=columnCount;i++){String columnLabel = metaData.getColumnLabel(i);Object columnValue = rs.getObject(i);Field field = clazz.getDeclaredField(columnLabel);field.setAccessible(true);field.set(t,columnValue);}if(list == null) list = new ArrayList<T>();list.add(t);}return list;}catch (Exception e){e.printStackTrace();}finally {JDBCUtils.closeResource(conn,ps,rs);}return null;}/*** 返回一个实例* @param clazz* @param sql* @param args* @param <T>* @return T*/public <T> T getInstance(Class<T> clazz, String sql, Object ...args){Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;try{conn = JDBCUtils.getConnection();ps = conn.prepareStatement(sql);for(int i=0;i<args.length;i++){ps.setObject(i+1,args[i]);}rs = ps.executeQuery();ResultSetMetaData metaData = rs.getMetaData();int columnCount = metaData.getColumnCount();if(rs.next()){T t = clazz.getDeclaredConstructor().newInstance();for(int i=1;i<=columnCount;i++){Object columnValue = rs.getObject(i);String columnLabel = metaData.getColumnLabel(i);Field field = clazz.getDeclaredField(columnLabel);field.setAccessible(true);field.set(t,columnValue);}return t;}}catch (Exception e){e.printStackTrace();}finally {JDBCUtils.closeResource(conn,ps,rs);}return null;}
查询过程中可以总结为两种编程思想和运用两种技术
[两种编程思想]
面向接口编程的思想
ORM编程思想(object relation mapping)
一个数据表对应一个Java类
表中的一条记录对应Java类中的一个字段
表中一个字段对应Java类中的一个属性
[两种技术]
使用结果集的元数据:ResultSetMetaData
getColumnCount(): 获取列数
getColumnLabel(): 获取列的别名
使用反射
数据库的事务
数据库事务介绍
事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态。
事务处理(事务操作):保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务回滚(rollback)到最初状态。
为确保数据库中数据的一致性,数据的操纵应当是离散的成组的逻辑单元:当它全部完成时,数据的一致性可以保持,而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。
数据库的ACID属性
原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
隔离性(Isolation)事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。
数据库并发问题
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
脏读: 对于两个事务 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段。之后, 若 T2 回滚, T1读取的内容就是临时且无效的。
不可重复读: 对于两个事务T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段。之后, T1再次读取同一个字段, 值就不同了。
幻读: 对于两个事务T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行。之后, 如果 T1 再次读取同一个表, 就会多出几行。
数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题。
一个事务与其他事务隔离的程度称为隔离级别。数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱。
数据库四种隔离级别

Oracle 支持的 2 种事务隔离级别:READ COMMITED, SERIALIZABLE。Oracle 默认的事务隔离级别为: READ COMMITED 。
Mysql 支持 4 种事务隔离级别。Mysql 默认的事务隔离级别为: REPEATABLE READ。
DAO及相关实现类
DAO:Data Access Object访问数据信息的类和接口,包括了对数据的CRUD(Create、Retrival、Update、Delete),而不包含任何业务相关的信息。有时也称作:BaseDAO。作用:为了实现功能的模块化,更有利于代码的维护和升级。
层级结构如下:

BaseDao.java
import java.lang.reflect.ParameterizedType;import java.lang.reflect.Type;import java.sql.Connection;import java.sql.SQLException;import java.util.List;import org.apache.commons.dbutils.QueryRunner;import org.apache.commons.dbutils.handlers.BeanHandler;import org.apache.commons.dbutils.handlers.BeanListHandler;import org.apache.commons.dbutils.handlers.ScalarHandler;/*** 定义一个用来被继承的对数据库进行基本操作的Dao** @author HanYanBing** @param <T>*/public abstract class BaseDao<T> {private QueryRunner queryRunner = new QueryRunner();// 定义一个变量来接收泛型的类型private Class<T> type;// 获取T的Class对象,获取泛型的类型,泛型是在被子类继承时才确定public BaseDao() {// 获取子类的类型Class clazz = this.getClass();// 获取父类的类型// getGenericSuperclass()用来获取当前类的父类的类型// ParameterizedType表示的是带泛型的类型ParameterizedType parameterizedType = (ParameterizedType) clazz.getGenericSuperclass();// 获取具体的泛型类型 getActualTypeArguments获取具体的泛型的类型// 这个方法会返回一个Type的数组Type[] types = parameterizedType.getActualTypeArguments();// 获取具体的泛型的类型·this.type = (Class<T>) types[0];}/*** 通用的增删改操作** @param sql* @param params* @return*/public int update(Connection conn,String sql, Object... params) {int count = 0;try {count = queryRunner.update(conn, sql, params);} catch (SQLException e) {e.printStackTrace();}return count;}/*** 获取一个对象** @param sql* @param params* @return*/public T getBean(Connection conn,String sql, Object... params) {T t = null;try {t = queryRunner.query(conn, sql, new BeanHandler<T>(type), params);} catch (SQLException e) {e.printStackTrace();}return t;}/*** 获取所有对象** @param sql* @param params* @return*/public List<T> getBeanList(Connection conn,String sql, Object... params) {List<T> list = null;try {list = queryRunner.query(conn, sql, new BeanListHandler<T>(type), params);} catch (SQLException e) {e.printStackTrace();}return list;}/*** 获取一个但一值得方法,专门用来执行像 select count(*)...这样的sql语句** @param sql* @param params* @return*/public Object getValue(Connection conn,String sql, Object... params) {Object count = null;try {// 调用queryRunner的query方法获取一个单一的值count = queryRunner.query(conn, sql, new ScalarHandler<>(), params);} catch (SQLException e) {e.printStackTrace();}return count;}}
BookDAO.java
import java.sql.Connection;import java.util.List;import com.atguigu.bookstore.beans.Book;import com.atguigu.bookstore.beans.Page;public interface BookDao {/*** 从数据库中查询出所有的记录** @return*/List<Book> getBooks(Connection conn);/*** 向数据库中插入一条记录** @param book*/void saveBook(Connection conn,Book book);/*** 从数据库中根据图书的id删除一条记录** @param bookId*/void deleteBookById(Connection conn,String bookId);/*** 根据图书的id从数据库中查询出一条记录** @param bookId* @return*/Book getBookById(Connection conn,String bookId);/*** 根据图书的id从数据库中更新一条记录** @param book*/void updateBook(Connection conn,Book book);}
BookDaoImpl.java
import java.sql.Connection;import java.util.List;import com.atguigu.bookstore.beans.Book;import com.atguigu.bookstore.beans.Page;import com.atguigu.bookstore.dao.BaseDao;import com.atguigu.bookstore.dao.BookDao;public class BookDaoImpl extends BaseDao<Book> implements BookDao {@Overridepublic List<Book> getBooks(Connection conn) {// 调用BaseDao中得到一个List的方法List<Book> beanList = null;// 写sql语句String sql = "select id,title,author,price,sales,stock,img_path imgPath from books";beanList = getBeanList(conn,sql);return beanList;}@Overridepublic void saveBook(Connection conn,Book book) {// 写sql语句String sql = "insert into books(title,author,price,sales,stock,img_path) values(?,?,?,?,?,?)";// 调用BaseDao中通用的增删改的方法update(conn,sql, book.getTitle(), book.getAuthor(), book.getPrice(), book.getSales(), book.getStock(),book.getImgPath());}@Overridepublic void deleteBookById(Connection conn,String bookId) {// 写sql语句String sql = "DELETE FROM books WHERE id = ?";// 调用BaseDao中通用增删改的方法update(conn,sql, bookId);}@Overridepublic Book getBookById(Connection conn,String bookId) {// 调用BaseDao中获取一个对象的方法Book book = null;// 写sql语句String sql = "select id,title,author,price,sales,stock,img_path imgPath from books where id = ?";book = getBean(conn,sql, bookId);return book;}@Overridepublic void updateBook(Connection conn,Book book) {// 写sql语句String sql = "update books set title = ? , author = ? , price = ? , sales = ? , stock = ? where id = ?";// 调用BaseDao中通用的增删改的方法update(conn,sql, book.getTitle(), book.getAuthor(), book.getPrice(), book.getSales(), book.getStock(), book.getId());}}
