





1. 简介
Apache Spark 社区于 2021 年 10 月 13 日发布了 Spark 3.2.0。他们在 Spark 上包含了一个 Pandas API,作为他们主要更新的一部分。Pandas 是数据科学家中一个功能强大且众所周知的软件包。但是,Pandas 在处理大数据方面有其自身的局限性,因为它是在一台机器上处理数据。为了弥合这一差距,databricks 几年前发布了一个库 Koalas(参见我之前的文章,如何从pandas轻松过渡到PySpark?)。
Spark 3.2.0 增加了 Pandas API,避免了使用第三方库。现在,Pandas 用户仍然可以保留他们的 Pandas,并将流程扩展到多节点 Spark 集群。Spark 3.2.0 上的 Pandas API的实现如下,
为 pandas-on-Spark 启用 mypy 实现 CategoricalDtype 支持 完成 Series 和 Index 的基本操作 将行为匹配到 Pandas 1.3 将带有 NaN 的 Series 上的行为与 Pandas 匹配 实现整数系列和索引的一元运算符“反转” 实现 CategoricalIndex.map 和 DatetimeIndex.map 实施 Index.map
2. 目的
本文专门介绍了如何使用 Spark 上的 Pandas API 来:
将数据读取为 pandas-spark 数据帧 (df) 将数据读取为 spark df 并转换为 pandas-spark df 创建 Pandas Spark df 直接使用 SQL 查询到 pandas-spark df 使用 plot 函数绘制 pandas-spark df Spark 上从考拉到 Pandas API 的转换
3. 数据
您可以从我的GitHub 页面获取[1]本文中使用的 CSV 文件和 Jupyter Notebook 。然而,这是一个小数据集,这里说明的方法可以很容易地用于大型数据集。
4. 安装
快速安装 pyspark 3.2.0
!conda install -y -c conda-forge pyspark openjdk pandas=1.3.4 matplotlib plotly ipython-autotime
5. 导入库并启动 Spark 会话
在这里,我们开始使用如下所示的代码块导入 PySpark 和 spark session。
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('spark3.2show').getOrCreate()
print('Spark info :')
spark
spark 信息显示使用的版本是 3.2.0。

您还可以检查 python 和 pyspark 的版本,如下所示。我使用的 spark 版本是 3.2.0 和 python 3.9.6。
print('python version:')
!python -V
print('pyspark version:', pyspark.__version__)
返回
python version:
Python 3.9.6
pyspark version:3.2.0
好的!让我们导入read_csv函数以使用pyspark.pandas将 CSV 数据读取为 pandas-spark df 。
如果我们得到如图 3 所示的警告,我们可以在运行from pyspark.pandas import read_csv之前将环境变量即PYARROW_IGNORE_TIMEZON 设置为 1 。
from pyspark.pandas import read_csv
WARNING:root:'PYARROW_IGNORE_TIMEZONE' environment variable was not set. It is required to set this environment variable to '1' in both driver and executor sides if you use pyarrow>=2.0.0. pandas-on-Spark will set it for you but it does not work if there is a Spark context already launched.
# 为了消除错误,设置环境变量如下
os.environ["PYARROW_IGNORE_TIMEZONE"]="1"
from pyspark.pandas import read_csv
6.1 从 csv 读取数据为 pandas-spark df
我们使用“example_csv.csv”文件来说明 pandas spark API 的各种用例。该read_csv函数返回的 Pandas SparkDF (称之为:psdf )。
# 定义数据路径
# 在 spark 上读取为Pandas df
!wget -q https://raw.githubusercontent.com/ShresthaSudip/PandasPySpark_3_2_0/master/example_csv.csv
import pathlib
path = pathlib.Path("example_csv.csv").absolute().as_posix()
psdf = read_csv(path)
psdf.head(3)
输出:
| id | firstname | lastname | age | gender | salary | |
|---|---|---|---|---|---|---|
| 0 | 1 | jam | rose | 22 | m | 50000 |
| 1 | 2 | linda | gee | 24 | f | 100000 |
| 2 | 3 | robert | william | 25 | m | 100000 |
伟大的!我们刚刚创建了 pandas-spark df,现在我们可以使用 pandas 函数来执行下游任务。例如,psdf.head(2) 和 psdf.shape可分别用于获取数据的前 2 行和维度。在这里,与标准 python pandas df 不同,您可以获得并行化的好处。
print('数据类型:',type(psdf))
print('数据维度:',psdf.shape)
print('数据列:\n',psdf.columns)
输出:
数据类型: <class 'pyspark.pandas.frame.DataFrame'>
数据维度: (10, 6)
数据列:
Index(['id', 'firstname', 'lastname', 'age', 'gender', 'salary'], dtype='object')
不仅如此,如果您想将 pandas-spark df 转换为 spark df,也可以通过简单地使用to_spark()函数来实现。这将返回 spark 数据帧 (称为:sdf )并且所有 pyspark 函数现在都可以在此 df 上使用。例如,sdf.show(5)和sdf.printSchema() 分别输出 spark df 的前 5 行和数据模式。
#从spark上的pandas转换为spark数据帧
sdf = psdf.to_spark()
# 显示来自 spark 的前 5 行 df
sdf.show(3)
输出:
+---+---------+--------+---+------+------+
| id|firstname|lastname|age|gender|salary|
+---+---------+--------+---+------+------+
| 1| jam| rose| 22| m| 50000|
| 2| linda| gee| 24| f|100000|
| 3| robert| william| 25| m|100000|
+---+---------+--------+---+------+------+
only showing top 3 rows
# 打印模式
sdf.printSchema()
输出:
root
|-- id: integer (nullable = true)
|-- firstname: string (nullable = true)
|-- lastname: string (nullable = true)
|-- age: integer (nullable = true)
|-- gender: string (nullable = true)
|-- salary: integer (nullable = true)
6.2 从 csv 读取为 spark df 并转换为 pandas-spark df
我们还可以使用to_pandas_on_spark()命令将 spark df 转换为 pandas-spark df 。这将输入作为 spark df 并输出 pandas-spark df。下面,我们将数据读取为 spark df (称为:sdf1 )。为了确认它是一个 spark df,我们可以使用type(sdf1)*这表明它是一个 spark df,即。'pyspark.sql.dataframe.DataFrame'。
# 使用 spark 读取数据
sdf1 = spark.read.csv( path, header=True,inferSchema=True)
type(sdf1)
输出:
pyspark.sql.dataframe.DataFrame
而在转换为 pandas-spark df (psdf1) 后,类型为 pandas-spark df 即“pyspark.pandas.frame.DataFrame”。我们可以通过使用 pandas 函数来进一步确认它是 pandas-spark df,例如.head()。
# 转换为pandas-spark df
psdf1 = sdf1.to_pandas_on_spark()
# 打印 top 3
psdf1.head(3)
输出:
| id | firstname | lastname | age | gender | salary | |
|---|---|---|---|---|---|---|
| 0 | 1 | jam | rose | 22 | m | 50000 |
| 1 | 2 | linda | gee | 24 | f | 100000 |
| 2 | 3 | robert | william | 25 | m | 100000 |
# 检查 psdf1 的类型
type(psdf1)
输出:
pyspark.pandas.frame.DataFrame
6.3 创建 pandas-spark df
在本节中,我们可以通过将pyspark.pandas 作为 ps导入来直接创建它,而不是从 CSV 创建 pandas-spark df 。下面,我们使用ps.DataFrame()创建了 psdf2 作为 pandas-spark df 。psdf2 有 2 个特征和 3 行。
import pandas as pd
import pyspark.pandas as ps
# 在 spark 上创建 Pandas df
psdf2 = ps.DataFrame({'id': [1,2,3], 'score': [89, 97, 79]})
psdf2.head()
输出:
| id | score | |
|---|---|---|
| 0 | 1 | 89 |
| 1 | 2 | 97 |
| 2 | 3 | 79 |
如果我们想将 pandas-spark df (psdf2) 转换回 spark df,那么我们有一个现成的函数,如前所述,to_spark()可以完成这项工作。语法提供了交换数据帧类型的灵活性。这可能会有所帮助,具体取决于您要在分析中使用的函数 (来自 pandas 或来自 spark )。
# 再次我们可以从pandas-spark df 转换为spark df
sdf2 = psdf2.to_spark()
sdf2.show(2)
+---+-----+
| id|score|
+---+-----+
| 1| 89|
| 2| 97|
+---+-----+
only showing top 2 rows
7.直接使用 SQL 查询 spark df 上的 pandas
关于 pandas-spark API 的另一个重要话题是它的sql函数。好的,让我们在之前创建的 pandas-spark df (psdf2) 上使用该函数来从中提取信息。实际上,我们只需要在 pandas-spark df 之上使用ps.sql()函数来运行 SQL 查询。如下所示,count(*)函数在 psdf2 数据中返回总共 3 个观察值。同样,第二个查询输出分数大于 80 的过滤数据。
# 使用SQL查询数据。输入数据是spark df (psdf)上的
pandas ps.sql("SELECT count(*) as num FROM {psdf2}")
+---+-----+
| |num |
+---+-----+
| 0| 3|
+---+-----+
# 在 Spark上返回Pandas df
selected_data = ps.sql("SELECT id, score FROM {psdf2} WHERE score>80")
selected_data.head()
输出:
+---+---+-----+
| | id|score|
+---+---+-----+
| 0| 1| 89|
| 1| 2| 97|
+---+---+-----+
8.在 pandas df 和 pandas 上绘制 spark df
很棒!你已经走了这么远。现在,让我们简要介绍一下这个新的 pandas-spark API 的绘图功能。与标准 python pandas API 中的默认静态图不同,pandas-spark API 中的默认图是交互式的,因为它默认使用 plotly。下面,我们将数据作为 pandas df 和 pandas-spark df 导入,并在每种数据类型上绘制工资变量的直方图。
# 读取数据为Pandas数据帧
pddf = pd.read_csv(path)
type (pdf )
#pandas.core.frame.DataFrame
pdf.head(2)
下图显示了来自 pandas df 的薪水直方图。
# 在 spark 上读取数据为Pandas df
pdsdf = read_csv( path)类型 (pdsdf )
#pyspark.pandas.frame.DataFrame# 绘制Pandas直方图 df
pddf['salary'].hist(bins=3)
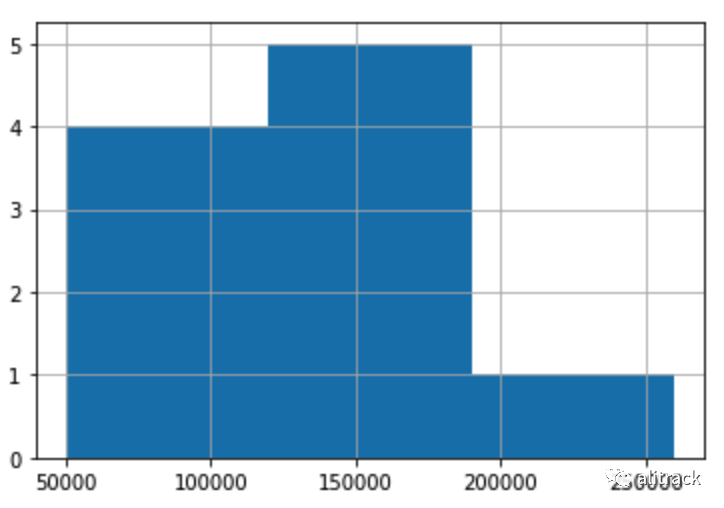
我已经在下面的 pandas-spark df 中展示了相同变量的直方图,这实际上是一个交互式绘图。
注意:下图粘贴为图像,因此它是静态的。如果您在 jupyter notebook 中运行以下语法,您应该能够放大/缩小 (使其具有交互性 )。
# 在 spark df 上绘制Pandas的直方图
import plotly
pdsdf['salary'].hist(bins=3)

参考资料
GitHub 页面获取: https://github.com/ShresthaSudip/PandasPySpark_3_2_0
原文:Work With Large Datasets Using Pandas on Spark3.2.0
链接:https://medium.com/@statistics.sudip/work-with-large-datasets-using-pandas-on-spark3-2-0-67713273118a
翻译:alitrack
欢迎关注公众号

有兴趣加群讨论数据挖掘和分析的朋友可以加我微信(witwall),暗号:入群

也欢迎投稿!
