




背景
温度而知新,可以为师矣!重读官方文档,本文深度解析Kafka高性能相关的所有特性:磁盘性能、顺序读写与零拷贝、网络模型等内容。
磁盘性能
Kafka严重依赖filesystem以存储和缓存messages。大家普通认为disk速度很慢。事实上,磁盘的速度比我们想象中慢得多、也快得多,这取决于磁盘的访问模式。关于磁盘性能的关键事实:JBOD配置的RAID-5阵列(7200rpm SATA),线性写入性能达600MB/s,而随机写入性能仅100k/s,差距近6000。现代操作系统对于线性读写进行了大量优化,提供预读和后写技术(以大数据块预取、将小逻辑写分组为大的物理写)。ACM文章有相关讨论,甚至某些场景顺序磁盘访问比随机内存访问速度更快!
现代操作系统尽可能地将所有可用内存用于缓存(PageCache),因为回收内存的性能损失很小。所有磁盘读写都基于PageCache而无法绕开,除非使用direct I/O(数据直接写到磁盘上而非缓存)。有关PageCache更加详细介绍见历史文章:
https://mp.weixin.qq.com/s/nCZHa3Ex8gXtcx8i58GJig
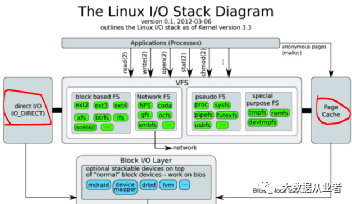
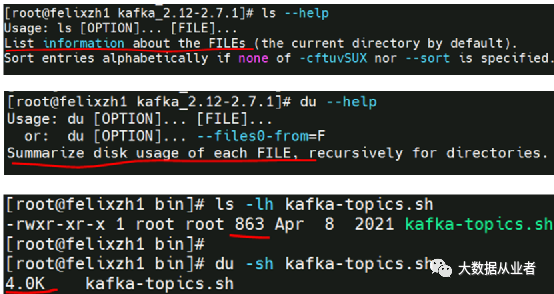
注意filesystem与disk的关系:filesystem中的一个文件的实际大小并不等于文件所占用的disk space。filesystem最小单元为block(1KBytes),disk最小单元为allocation units(4KBytes)。所以,大小为1Byte的文件,在filesystem占用1K,而在disk上占用4K。这也是为什么有些场景下ls命令和du命令查看同一个文件显示大小不同的原因。ls命令查看的是文件信息,而du命令查看的是文件所占磁盘的信息。
顺序读写与零拷贝
如上节所述,排除磁盘访问模式的影响因素,影响效率的因素为频繁小IO操作和大量低效率的字节复制。
首先,频繁小IO操作问题存在于client与server通信时、server持久化操作时。为了避免这种情况,Kafka协议抽象出message set消息集,抽象消息集将消息进行分组分批处理,分摊网络开销而不是一次发送一条消息。Server将消息块一次性追加到Log文件,消费者一次性获取大的线性块。批处理会导致更大网络数据包、更大顺序磁盘操作、连续内存块等。这种简单的优化可以产生几个数量级的加速。
其次,为了避免大量低效率的字节复制,Kafka的生产者、服务端、消费者使用相同的标准化二进制消息格式(因此数据块来回传输时无需修改)。服务端broker以文件目录维护消息集,每个文件由一系列消息集填充,这些消息集与生产者和消费者使用相同的格式。这种通用格式有利于持久化数据文件的网络传输。
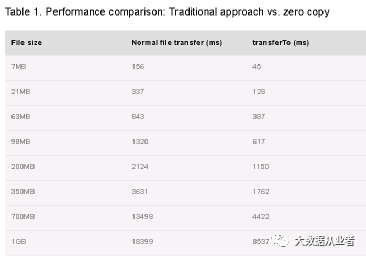
现代unix操作系统高度优化支持将数据从PageCache传输到socket,Linux系统通过调用sendfile可以实现将数据直接从PageCache数据发送到网络socket,一次数据拷贝以避免常规方式四次拷贝(磁盘->内核PageCache->user buffer->内核PageCache->socket)的低效率。这种技术就称之为零拷贝。
结合PageCache和零拷贝技术,Kafka集群消费者没有堆积时,数据直接从PageCache读取而不用读取磁盘。当然,如果消费者消费历史数据,就会先从磁盘读取到PageCache,然后再从PageCache读取到socket。
Java类库在Linux和UNIX系统上支持通过java.nio.channels.FileChannel类的transferTo()方法实现零拷贝(zero copy)技术。详细内容参见: https://developer.ibm.com/articles/j-zerocopy/
网络模型(Reactor架构)
Kafka使用Java NIO类库实现底层网络传输层和持久化数据到本地磁盘文件。NIO即Non-blocking IO,可以用来替代标准Java IO。
NIO提供了与标准IO不同的IO工作方式:
1.标准IO基于流(字节流和字符流)进行操作,而NIO基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区或者从缓冲区写入到通道。2.NIO可以非阻塞的使用IO,如:当线程从通道读取数据到缓冲区时,线程还是可以做其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也类似。3.NIO引入了选择器(selector)的概念,选择器用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个的线程可以监听多个数据通道。
NIO通道(Channel)分为四种:
1.FileChannel :读写文件数据。2.DatagramChannel:读写UDP网络数据。3.SocketChannel:读写TCP网络数据。4.ServerSocketChannel:监听TCP连接,类似于Web服务器。对于新建连接都会创建一个对应的SocketChannel。
JavaNIO可以详见系列文章: http://tutorials.jenkov.com/java-nio/index.html
Kafka网络模型使用到NIO Channel包括FileChannel、SocketChannel、ServerSocketChannel。结合源码中Kafka启动流程可以看到相关内容:
启动类kafka.Kafka关键源码:
val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps)kafkaServerStartable.startup()
对应服务类kafkaServerStartable关键源码:
private val server = new KafkaServer(staticServerConfig, kafkaMetricsReporters = reporters, threadNamePrefix = threadNamePrefix)server.startup()
对应服务类KafkaServer关键源码:
socketServer = new SocketServer(config, metrics, time, credentialProvider)socketServer.startup(startProcessingRequests = false)
对应服务类SocketServer关键源码:
def startup(startProcessingRequests: Boolean = true): Unit = {this.synchronized {connectionQuotas = new ConnectionQuotas(config, time, metrics)createControlPlaneAcceptorAndProcessor(config.controlPlaneListener)createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, config.dataPlaneListeners)if (startProcessingRequests) {this.startProcessingRequests()}}}
详细说明SocketServer服务类,主要处理broker之间以及broker与client之间的新建连接、处理请求、返回处理结果等。Kafka支持两种类型的request planes(data-plane、control-plane)。
data-plane处理clients和brokers之间的请求(注意:broker相对其他broker也是client)。线程模型是:一个listener(一个broker可能有多个listener)对应一个 Acceptor线程(处理连接请求,分配processor)、该Acceptor线程对应N个Processor线程(每个processor有自己的selector,从sockets读取请求数据)、M个Handler线程(处理Processors线程读取的请求数据,并返回处理结果给相应的processor线程)。
control-plane处理controller请求,这是可选的,通过配置control.plane.listener.name指定,如果不指定,controller请求将交由data-plane处理。线程模型是:一个Acceptor线程、一个Processor线程、一个Handler线程,线程功能与data-plane相应线程功能相同。
上述data-plane中Processors线程数由配置num.network.threads指定,见源码
createDataPlaneAcceptorsAndProcessors(config.numNetworkThreads, config.dataPlaneListeners)
将Processors线程关联到Acceptor线程和dataPlaneRequestChannel通道,见源码
private def addDataPlaneProcessors(acceptor: Acceptor, endpoint: EndPoint, newProcessorsPerListener: Int): Unit = {val listenerName = endpoint.listenerNameval securityProtocol = endpoint.securityProtocolval listenerProcessors = new ArrayBuffer[Processor]()for (_ <- 0 until newProcessorsPerListener) {val processor = newProcessor(nextProcessorId, dataPlaneRequestChannel, connectionQuotas, listenerName, securityProtocol, memoryPool)listenerProcessors += processordataPlaneRequestChannel.addProcessor(processor)nextProcessorId += 1}listenerProcessors.foreach(p => dataPlaneProcessors.put(p.id, p))acceptor.addProcessors(listenerProcessors, DataPlaneThreadPrefix)}
上述data-plane中Handler线程数由配置num.io.threads指定,见源码
dataPlaneRequestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.dataPlaneRequestChannel, dataPlaneRequestProcessor, time,config.numIoThreads, s"${SocketServer.DataPlaneMetricPrefix}RequestHandlerAvgIdlePercent", SocketServer.DataPlaneThreadPrefix)
KafkaRequestHandlerPool类内部会关联dataPlaneRequestChannel与Handlers线程,见源码
this.logIdent = "[" + logAndThreadNamePrefix + " Kafka Request Handler on Broker " + brokerId + "], "val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads)for (i <- 0 until numThreads) {createHandler(i)}def createHandler(id: Int): Unit = synchronized {runnables += new KafkaRequestHandler(id, brokerId, aggregateIdleMeter, threadPoolSize, requestChannel, apis, time)KafkaThread.daemon(logAndThreadNamePrefix + "-kafka-request-handler-" + id, runnables(id)).start()}
至此,一个Acceptor线程(即Acceptor类)、N个Processors线程(即Processor类)、M个Handlers线程(即KafkaRequestHandler类)构建并关联完成!
注意:Kafka服务启动的所有线程均是通过一个封装的KafkaThread线程包装类实现,毫无疑问,该类继承了Thread类。
/*** A wrapper for Thread that sets things up nicely*/public class KafkaThread extends Thread {private final Logger log = LoggerFactory.getLogger(getClass());public static KafkaThread daemon(final String name, Runnable runnable) {return new KafkaThread(name, runnable, true);}public static KafkaThread nonDaemon(final String name, Runnable runnable) {return new KafkaThread(name, runnable, false);}public KafkaThread(final String name, boolean daemon) {super(name);configureThread(name, daemon);}public KafkaThread(final String name, Runnable runnable, boolean daemon) {super(runnable, name);configureThread(name, daemon);}private void configureThread(final String name, boolean daemon) {setDaemon(daemon);setUncaughtExceptionHandler((t, e) -> log.error("Uncaught exception in thread '{}':", name, e));}}
