






全文 1.6万 字,阅读约需 40 分钟
文章结构
1. 前言 2. Spark整体介绍 2.1 Spark是什么 2.2 Spark与Hadoop的区别 2.3 三代大数据处理引擎 3. Spark集群的安装与介绍 3.1 服务器硬件与软件版本选择 3.2 集群整体架构说明 4. Spark集群手把手搭建步骤 4.1 配置集群间免密登陆 4.2 安装Java语言 4.3 安装Scala语言 4.4 配置Hadoop集群 4.5 启动Hadoop集群 4.6 配置及启动Spark集群 4.7 测试Spark任务 5. Spark任务执行过程 5.1 基本术语解释 5.2 任务执行过程
5.3 资源调度和任务调度过程 6. Spark的三种运行模式 6.1 本地模式 6.2 客户端模式 6.3 集群模式 7. SparkCore详解 7.1 深刻理解RDD 7.2 宽依赖与窄依赖 7.3 Shuffle过程 7.4 Stage的划分 8. RDD的操作 8.1 创建操作 8.2 转换操作 8.3 行动操作 8.4 控制操作 8.5 更多操作 9. 共享变量 9.1 广播变量 9.2 累加变量 10. Spark SQL 10.1 Spark SQL的前世今生
10.2 RDD、DataFrame与DataSet 10.3 Spark SQL代码示例
11. Spark Streaming 11.1 Spark Streaming代码示例
11.2 Spark Streaming原理
11.3 Spark Streaming读Kafka 12. Spark MLlib 12.1 MLlib与ML的区别 12.2 一些算法示例 13. Spark GraphX 13.1 GraphFrames与GraphX的区别
13.2 图计算简单代码示例 14. 总结
1. 前言
从事安全大数据分析有四年多了,期间很多地方需要写Spark应用,现将Spark的相关知识汇总整理成此文,一方面帮助初学者从0到1学习Spark这一重要的大数据分析工具,另一方面也作为个人阶段性的学习总结。
2. Spark整体介绍
Spark是用Scala
语言写的,其官网地址为:https://spark.apache.org/
2.1 Spark是什么
Spark是一种通用的大数据计算框架,它包含了大数据领域常见的各种计算模块,其组成及架构下图所示:
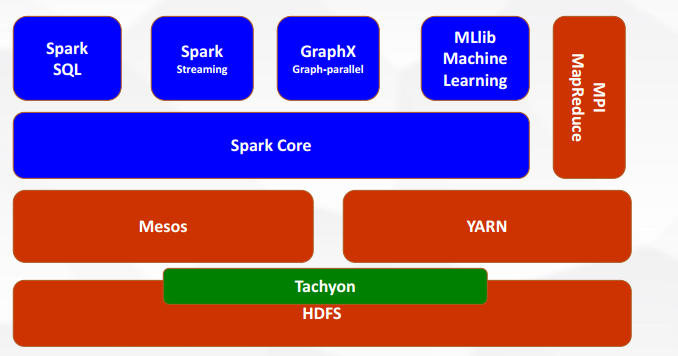
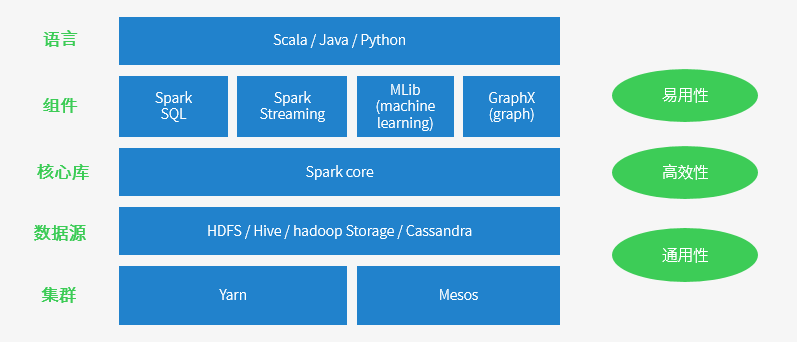
Spark的构成分为如下几个模块,作用分别如下:
Spark Core
是Spark接口的核心Spark SQL
用于交互式查询,与Hive作用一样Spark Streaming
用于实时流式计算,类比于流式计算平台FlinkSpark MLlib
用于机器学习,有SVM、神经网络、决策树等通用机器学习算法Spark GraphX
用于图计算,例如顶点与边的计算等
2.2 Spark与Hadoop的区别
Spark主要用于大数据的计算, 而Hadoop则主要用于大数据的存储( HDFS)以及资源调度( Yarn)。
Spark与Hadoop的组合,作为基础架构广泛应用于各互联网公司平台,是当下大数据领域最热门的组合,也是最有前景的组合。
Spark拥有Hadoop MapReduce所具有的优点,并且Spark Job的中间输出结果直接保存在内存中,在内存中使用弹性分布式数据集(RDD)来组织数据,RDD可以重用,支持重复的访问,不需要落盘读写HDFS,因此Spark能更好地应用于数据挖掘
与机器学习
等需要迭代的算法场景中,可以显著提升算法性能。
并且当RDD的大小超出集群的所有总内存时,Spark可以优雅的进行降级,将数据存储在磁盘上。
Spark摒弃了MapReduce先map再reduce这样的严格方式,Spark引擎可以执行更通用的有向无环图(DAG)算子。这就意味着,在MapReduce中需要将中间结果写入分布式文件系统时,Spark能将中间结果直接传到流水作业线的下一步。
在数据处理和ETL方面,Spark的目标是成为大数据界的Python,形成大数据处理一站式解决平台。
总结,以上内容可简单理解为:Spark比Hadoop更快,性能达到10倍以上的提升。
2.3 三代大数据处理引擎
个人认为,大数据技术的发展,到目前为止,一共产生了三代大数据的处理引擎,分别如下:
第一代大数据处理引擎是:MapReduce
第二代大数据处理引擎是:Spark
第三代大数据处理引擎是:Flink
3.Spark集群的安装与介绍
这一节将详细介绍如何从0开始搭建一个可以运行的Spark集群。
3.1 服务器硬件与软件版本选择
下面以三台阿里云服务器为例,讲解如何从0搭建一个Spark集群,每台服务器硬件配置如下:
内存:4G
物理CPU个数:1,逻辑CPU个数:2
系统盘:40G
有了硬件的配置之后,软件版本的选择也很重要,这里各个组件的版本一定要配套,不然会有各种莫名其妙的兼容错误,示例选择的配套软件版本如下:
操作系统版本:Centos 6.8
Java版本:1.8.0
Scala版本:2.11.12
Hadoop版本:2.7.3
Spark版本:2.2.0
Python版本:3.6 (非必须,但后期会被用到)
3.2 集群整体架构说明
整体架构:Java + Scala + HDFS + YARN + SPARK
底层语言依赖:Java + Scala
取Hadoop中的:
分布式文件系统HDFS
和集群管理器YARN取Spark中的计算框架
集群分配情况如下表所示:
| 主机编号 | 集群中的作用 | 运行进程 |
| jk01 | HDFS的主节点和备份节点,Yarn资源管理器节点,Spark主节点 | NameNode,ResourceManager,SecondaryNameNode,Master |
| jk02 | HDFS的数据节点,Spark工作节点 | DataNode,NodeManager,Worker |
| jk03 | HDFS的数据节点,Spark工作节点 | DataNode,NodeManager,Worker |
下面详细说明:
1. 分布式文件系统HDFS:估算集群最大数据存储能力
Web UI界面访问地址
NameNode:http://39.96.45.245:8810?user.name=xf_jike
SecondaryNameNode:http://39.96.45.245:8811/status.html
数据存储分配情况如下表所示(
hdfs-site.xml
)
| 磁盘 | 大小 | 所在目录 | 作用 | 配置参数 |
| /dev/vda1 | 40G | /home/work | 存放DataNode | dfs.datanode.data.dir |
总集群最大存储能力:40GB*2 = 80GB (DataNode)
2. 集群管理器Yarn:估算集群最大计算能力
UI界面访问地址:http://39.96.45.245:8188/cluster
最大计算内存:4GB * 2 = 8GB
最大计算逻辑核数:2 * 2 = 4
配置Hadoop中的
yarn-site.xml
文件如下:
| 参数 | 值 | 备注 |
yarn.nodemanager.resource.memory-mb | 1024*3(M) | 可用内存 |
yarn.nodemanager.resource.cpu-vcores | 2(个) | 可用核数 |
yarn.scheduler.maximum-allocation-mb | 1024(M) | 单任务最大可使用内存 |
3. 分布式计算框架Spark
UI界面访问地址:http://39.96.45.245:8080/
4. Spark集群手把手搭建步骤
有了以上Spark集群整体架构的规划之后,下面手把手的教大家如何将一个Spark平台搭建起来。
Step1:配置集群间免密登陆
这一步的原理是用SSH协议,产生一对公私密钥,然后把私钥留在自己电脑上,公钥发给别人,当电脑B想要登陆电脑A时,本来是需要输入用户名和密码的,但B有A的公钥的话,就不用输入这些了,而可以直接登陆。
因此在一个计算机集群上,这一步可以理解为让集群中的任意一台计算机拥有该集群里面其他所有计算机的公钥。
1号机器是主机,2、3号机器是从机。需要配置成1号机器可以免密访问2、3号机器。
1.# 在2号机器和3号机器上面分别产生一对公私密钥
2.ssh-keygen -t rsa
3.# 将2号和3号机器产生的公钥都发送给1号机器并重命名
4.scp ~/.ssh/id_rsa.pub work@jkqc01:~/.ssh/id_rsa.pub.02
5.# 在1号机器上将收到的公钥都写入一个认证文件里面去
6.cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
打开ssh服务的配置文件:
1.sudo vim etc/ssh/sshd_config
将以下三项的注释去掉:
1.RSAAuthentication yes
2.PubkeyAuthentication yes
3.AuthorizedKeysFile .ssh/authorized_keys
修改配置文件后,重启服务:
1.sudo service sshd restart
保证
authorized_keys
文件权限只能是600:
1.chmod 600 authorized_keys
保证
.ssh
文件夹权限只能是700:
1.chmod 700 .ssh
直到1号机器能直接登录到2号机器和3号机器,说明这一步安装正确。
Step2:安装Java语言
1.export JAVA_HOME=/home/work/jdk1.8.0_201
2.export PATH=$JAVA_HOME/bin:$PATH
出现如下图所示的,说明这一步安装正确。

在三台机器上进行相同的安装和配置
Step3:安装Scala语言
Scala官网:https://www.scala-lang.org/
1.# 下载并解压
2.wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz
3.tar -zxvf scala-2.11.7.tgz
在环境变量
~/.bashrc
里面设置
1.export SCALA_HOME=/home/work/scala-2.11.12
2.export PATH=$PATH:$SCALA_HOME/bin
3.# 并使其生效
4.source ~/.bashrc
检测是否安装成功:
1.scala -version
如果出现下图所示的,说明这一步正确。

在三台机器上进行相同的安装和配置。
Step4:配置Hadoop集群
下载Hadoop安装包并解压:
1.wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
2.tar -zxvf hadoop-2.7.3.tar.gz
在环境变量里面设置:
1.export HADOOP_HOME=/home/work/hadoop-2.7.3
2.export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
需要设置如下四个配置文件:
core-site.xml
:核心配置hdfs-site.xml
:分布式文件系统的配置mapred-site.xml
:指定资源管理器yarn-site.xml
:资源管理器配置slaves
:从节点的配置配置
core-site.xml
文件,如下:
1.<configuration>
2. <property>
3. # 指定NameNode主机名和请求端口号,如果端口被占用,换其他端口
4. <name>fs.defaultFS</name>
5. <value>hdfs://172.17.132.103:8085</value>
6. </property>
7. <property>
8. # 文件系统依赖的基础配置,需要配置到持久化目录
9. <name>hadoop.tmp.dir</name>
10. <value>/home/work/hadoop/tmp</value>
11. </property>
12. <property>
13. <name>hadoop.http.filter.initializers</name>
14. <value>org.apache.hadoop.security.AuthenticationFilterInitializer</value>
15. </property>
16. <property>
17. <name>hadoop.http.authentication.type</name>
18. <value>simple</value>
19. </property>
20. <property>
21. <name>hadoop.http.authentication.token.validity</name>
22. <value>3600</value>
23. </property>
24. <property>
25. <name>hadoop.http.authentication.signature.secret.file</name>
26. <value>/home/work/hadoop-2.7.3/hadoop-http-auth-signature-secret</value>
27. </property>
28. <property>
29. <name>hadoop.http.authentication.cookie.domain</name>
30. <value></value>
31. </property>
32. <property>
33. <name>hadoop.http.authentication.simple.anonymous.allowed</name>
34. <value>false</value>
35. </property>
36. <property>
37. # 回收站机制
38. <name>fs.trash.interval</name>
39. <value>120</value>
40. </property>
41.</configuration>
配置
hdfs-site.xml
文件,如下:
1. <configuration>
2. <property>
3. # NameNode Web访问地址
4. <name>dfs.namenode.http-address</name>
5. <value>172.17.132.103:8810</value>
6. </property>
7. <property>
8. # Secondary Name Node Web访问地址
9. <name>dfs.namenode.secondary.http-address</name>
10. <value>172.17.132.103:8811</value>
11. </property>
12. <property>
13. <name>dfs.namenode.name.dir</name>
14. # NameNode存储命名空间和相关元数据信息的本地文件系统目录
15. <value>file://${hadoop.tmp.dir}/dfs/name</value>
16. </property>
17. <property>
18. <name>dfs.datanode.data.dir</name>
19. # DataNode节点存储HDFS文件的本地文件系统目录
20. <value>file://${hadoop.tmp.dir}/dfs/data</value>
21. </property>
22. <property>
23. # 文件备份数量
24. <name>dfs.replication</name>
25. <value>3</value>
26. </property>
27. </configuration>
配置文件
mapred-site.xml
,如下:
1. <configuration>
2. <property>
3. # 目的是指定框架名,告诉MapReduce它将作为YARN的应用程序运行。
4. <name>mapreduce.framework.name</name>
5. <value>yarn</value>
6. </property>
7. <property>
8. <name>mapreduce.jobhistory.address</name>
9. <value>172.17.132.103:8012</value>
10. </property>
11. <property>
12. <name>mapreduce.jobhistory.webapp.address</name>
13. <value>172.17.132.103:8013</value>
14. </property>
15. </configuration>
配置文件
yarn-site.xml
,如下:
前面两个是告诉NodeManger需要实现一个名为mapreduce.shuffle的辅助服务,并给它一个类名作为实现该服务的方法。这个特定的配置告诉MapReduce怎么去shuffle。后面五个配置的是相应的一些地址。
1.<configuration>
2. <property>
3. <name>yarn.nodemanager.aux-services</name>
4. # 告诉NodeManager需要实现一个名为mapreduce.shuffle的辅助服务
5. <value>mapreduce_shuffle</value>
6. </property>
7. <property>
8. # 特定的类名实现该方法
9. <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
10. <value>org.apache.hadoop.mapred.ShuffleHandler</value>
11. </property>
12. <property>
13. <name>yarn.resourcemanager.address</name>
14. <value>172.17.132.103:8132</value>
15. </property>
16. <property>
17. <name>yarn.resourcemanager.scheduler.address</name>
18. <value>172.17.132.103:8139</value>
19. </property>
20. <property>
21. <name>yarn.resourcemanager.resource-tracker.address</name>
22. <value>172.17.132.103:8135</value>
23. </property>
24. <property>
25. <name>yarn.resourcemanager.admin.address</name>
26. <value>172.17.132.103:8133</value>
27. </property>
28. <property>
29. # Yarn集群的管理Web访问地址
30. <name>yarn.resourcemanager.webapp.address</name>
31. <value>172.17.132.103:8188</value>
32. </property>
33. <property>
34. <name>yarn.nodemanager.pmem-check-enabled</name>
35. <value>false</value>
36. </property>
37. <property>
38. <name>yarn.nodemanager.vmem-check-enabled</name>
39. <value>false</value>
40. </property>
41. <property>
42. <description>Whether to enable log aggregation</description>
43. <name>yarn.log-aggregation-enable</name>
44. <value>true</value>
45. </property>
46. <property>
47. <name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
48. <value>true</value>
49. </property>
50.</configuration>
配置
slaves
文件如下:
1.# 将两台从节点的IP地址写入
2.172.17.132.104 # 02号机器
3.172.17.132.105 # 03号机器
以上分发到三台机器,进行同样的安装和配置
Step5:启动Hadoop集群
第一次启动先进行格式化:
1.hdfs namenode -format
启动Hadoop命令:
1.start-dfs.sh
2.start-yarn.sh
查看相应节点的进程是否存在:
管理节点:NameNode,RecourceManager,SecondaryNameNode
数据节点:DataNode,NodeManager
访问NameNode的地址:http://39.96.45.245:8810/

访问NameNode的地址:http://39.96.45.245:8810?user.name=xf_jike
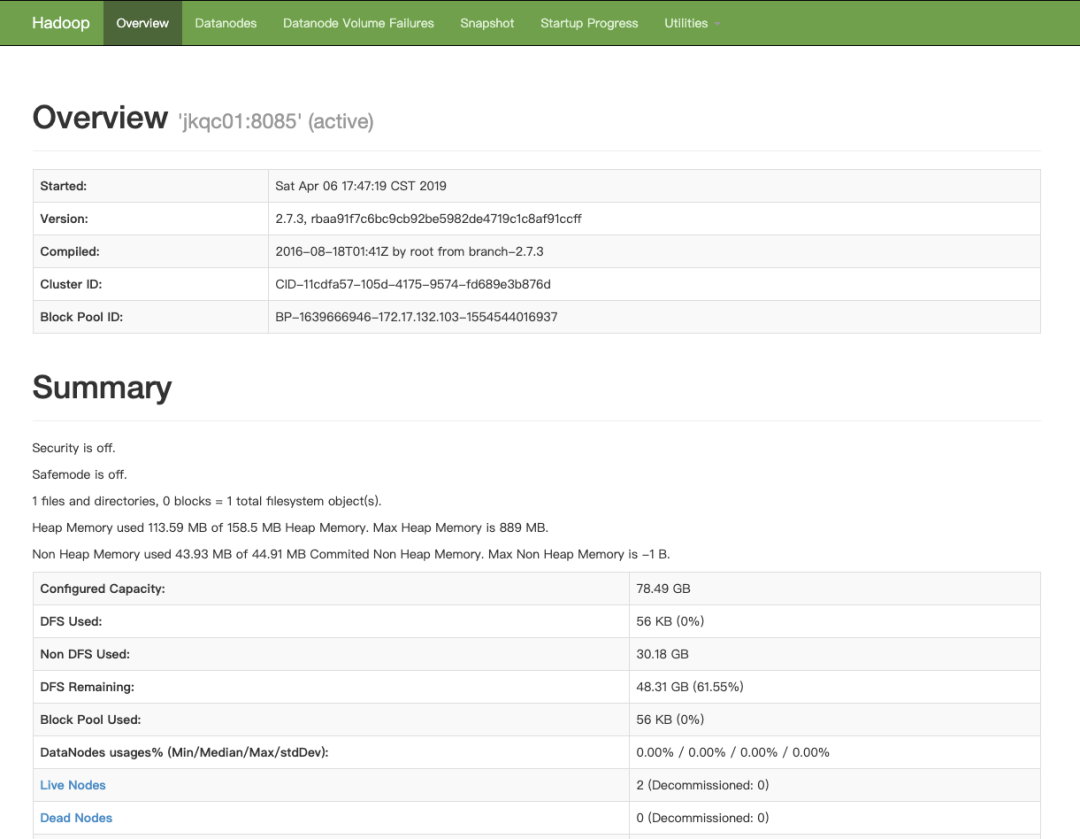
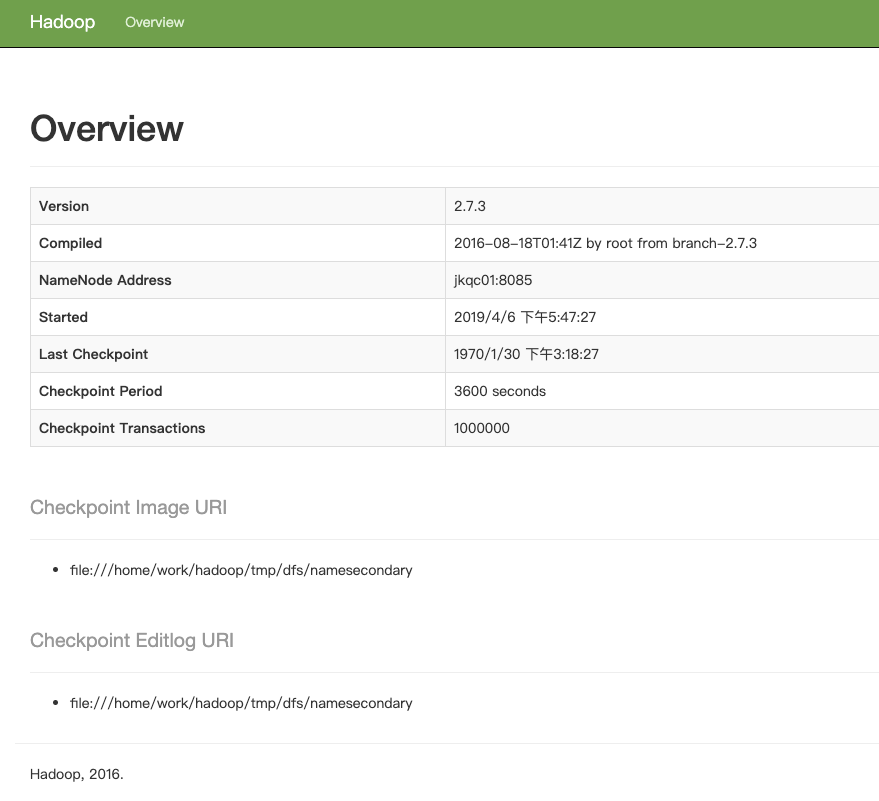
访问secondnamenode的地址:http://39.96.45.245:8811/status.html
访问Hadoop集群的地址:http://39.96.45.245:8188/cluster?user.name=xf_jike
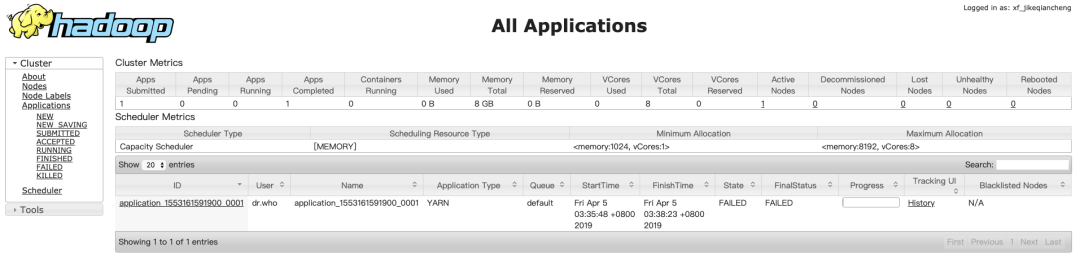
以上三个地址正确,并且相应进程都存在,说明Hadoop集群的安装和启动正确。
如果启动之后发现只有SecondaryNameNode,没有NameNode,先 stop-all.sh,删除文件,再重新格式化一次,再start-all.sh。
如果启动失败,注意查看相应Hadoop目录logs文件下的日志文件,里面会显示失败的原因。
Step6:配置及启动Spark集群
下载Spark集群安装包
1.# 下载
2.wget https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
3.# 解压缩
4.tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
修改配置文件
conf/spark-env.sh
,加上如下内容:
1.export HADOOP_HOME=/home/work/hadoop-2.7.3
2.export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
3.export JAVA_HOME=/home/work/jdk1.8.0_201
4.export SCALA_HOME=/home/work/scala-2.11.12
5.export SPARK_MASTER_IP=172.17.132.103
6.export SPARK_WORKER_MEMORY=4g
7.export SPARK_WORKER_CORES=1
8.export SPARK_WORKER_INSTANCES=1
9.export PYSPARK_PYTHON=/usr/local/bin/python3
修改
salves
文件:
1.172.17.132.104 # 02号机器
2.172.17.132.105 # 03号机器
分发到三台机器,进行同样的安装和配置
启动Spark,在master结点上面运行以下命令:
1./home/work/spark-2.2.0-bin-hadoop2.7/sbin/start-all.sh
查看相应节点的进程是否存在:
主:Master
从:Worker
访问Spark地址:http://39.96.45.245:8080/
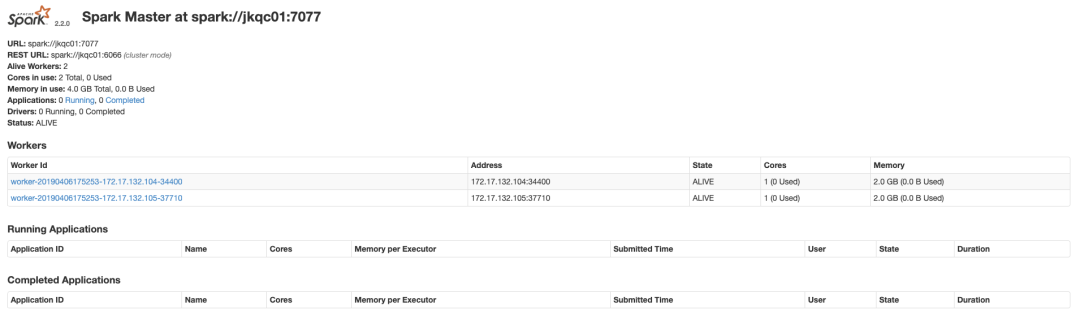
以上地址正确,并且相应进程都存在,说明Spark集群正确安装部署和启动。
Step7:测试Spark任务
测试命令:用蒙特卡洛方法模拟计算圆周率的值
1.# 本地模式提交测试,单机伪分布式
2../bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
3.# 客户端模式提交测试,交互式方便调试
4../bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
5.# 集群模式提交测试,用于生产环境
6../bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
查看日志示例:
1../yarn logs -applicationId application_1467776900158_0099
5. Spark任务执行过程
以上搭建了Spark集群并将其运行起来之后,下面详细讲解Spark的基本原理。
5.1 基本术语解释
为了搞清楚Spark任务的执行过程,一定要先了解一下术语和定义:
Application:用户基于Spark写的应用程序叫Application,一个Application实际包含了driver程序和运行在集群上的executor程序
Job:提交到Spark集群上的一个计算任务就是一个Job
Stage:一个Job会被拆分成很多组任务,每一组任务被称为一个Stage(类比与MapReduce任务被拆分为map task和reduce task)
Task:被送到executor上被执行的工作单元叫做Task
Executor:在worker进程所在的结点上为某一个Application启动的一个进程,该进程负责运行任务,并且负责将数据存储在内存或磁盘上。每个Application都有各自独立的executors。
Driver:用来连接工作进程(worker)的程序
Master:资源管理节点的主节点
Worker:资源管理节点的从节点
5.2 任务执行过程
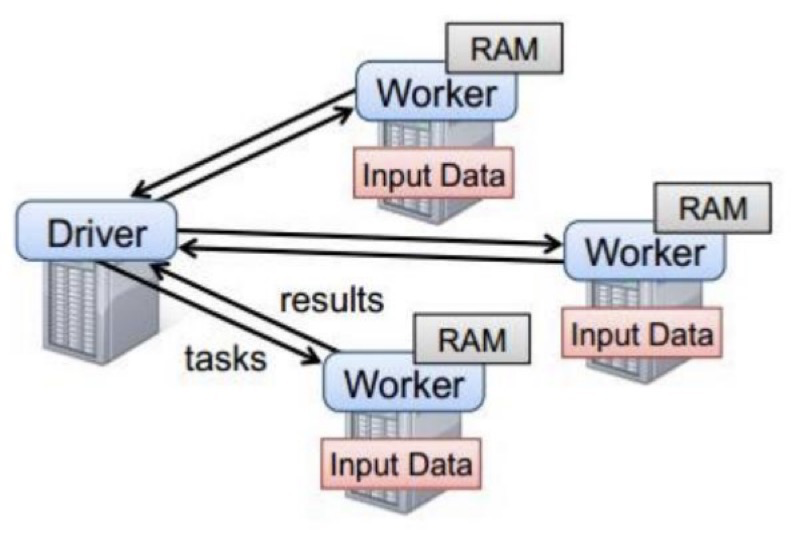
Driver和Worker是启动在节点上的进程,运行在JVM中
Driver与集群工作节点Worker之间有频繁的通信
Driver负责任务(tasks)的分发和结果的回收
Woker是从节点
Master是主节点
5.3 资源调度和任务调度过程
Spark资源调度和任务调度的流程:
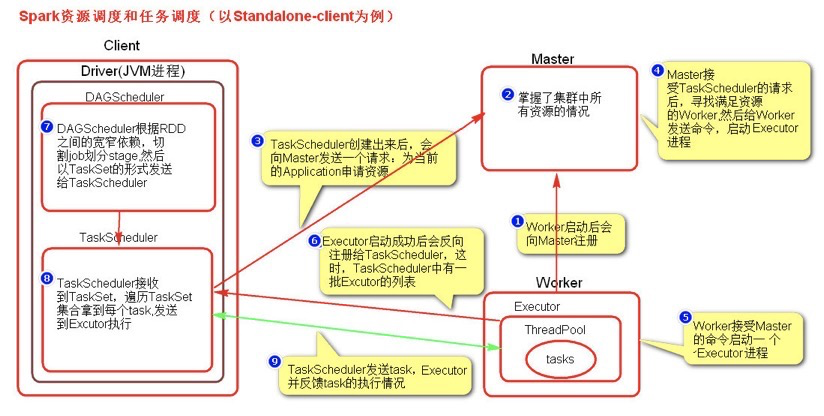
启动Spark集群后,Worker节点会向Master节点汇报资源情况,Master就掌握集群的整体资源情况。
当用户在Spark上提交一个Application后,Spark会根据RDD之间的依赖关系将一个Application分解成一个DAG的有向无环图的作业组(每一步称为一个stage)。
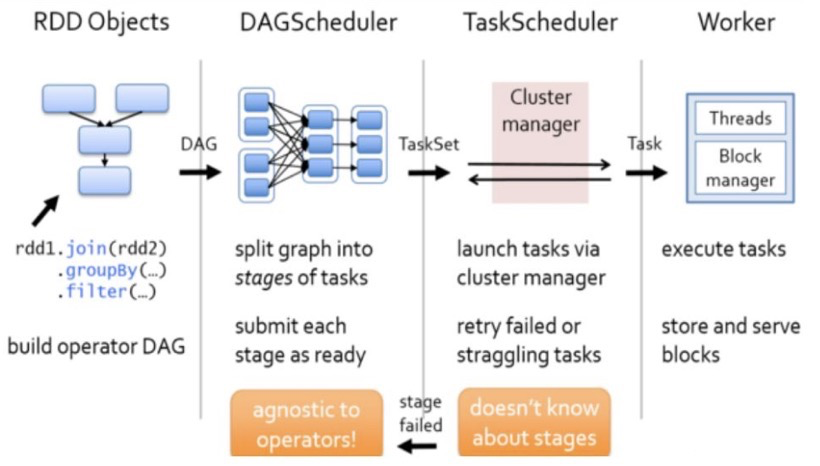
任务提交后,Spark会在Driver端创建两个对象:DAGScheduler和TaskScheduler。
DAGScheduler是任务调度的高层调度器,是一个对象。DAGScheduler的主要作用就是将DAG根据RDD之间的宽窄依赖关系划分为一个个的Stage,然后将这些Stage以TaskSet的形式提交给TaskScheduler
这里TaskSet其实就是一个集合,里面封装的就是一个个的task任务,也就是stage中的并行度task任务,TaskScheduler是任务调度的底层调度器,TaskSchedule会遍历TaskSet集合,拿到每个task后会将task发送到计算节点Executor中去执行(其实就是发送到Executor中的线程池ThreadPool去执行)。
task在Executor线程池中的运行情况会向TaskScheduler反馈,当task执行失败时,则由TaskScheduler负责重试,将task重新发送给Executor去执行,默认重试3次。如果重试3次依然失败,那么这个task所在的stage就失败了。
stage失败了则由DAGScheduler来负责重试,重新发送TaskSet到TaskSchdeuler,Stage默认重试4次。
如果重试4次以后依然失败,那么这个job就失败了。job失败了,Application就失败了。
TaskScheduler不仅能重试失败的task,还会重试straggling task(也就是执行速度比其他task慢太多的task会被重试)。如果有运行缓慢的task,那么TaskScheduler会启动一个新的task来与这个运行缓慢的task执行相同的处理逻辑。两个task哪个先执行完,就以哪个task的执行结果为准。
这就是Spark的推测执行机制。在Spark中推测执行默认是关闭的。推测执行可以通过
spark.speculation
属性来配置。
以上内容有两点需要注意:
对于要入数据库的业务要关闭推测执行机制,不然会有重复的数据入库
如果遇到数据倾斜的情况,开启推测执行可能导致一直会有task重新启动处理相同的逻辑,任务可能一直处于处理不完的状态
粗粒度资源申请(Spark)
在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源。
优点:在Application执行之前,所有的资源都申请完毕,每一个task直接使用资源就可以了,不需要task在执行前自己去申请资源,task启动就快了,task执行快了,stage执行就快了,job就快了,application执行就快了。
缺点:直到最后一个task执行完成才会释放资源,集群的资源无法充分利用。细粒度资源申请(MapReduce)
Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源。
优点:集群的资源可以充分利用。
缺点:task自己去申请资源,task启动变慢,Application的运行就响应的变慢了。
6. Spark的三种运行模式
理解了Spark的任务执行过程之后,下面讲解Spark三种提交任务的模式。
6.1 本地模式(local)
1.# 本地模式提交测试,单机伪分布式
2../bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
本地模式不运行在集群上,运行在当前执行的机器上
本地模式的任务不会在web页面显示
本地模式是采用线程来模拟集群的worker进程
6.2 客户端模式(client)
1.# 客户端模式提交
2../bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
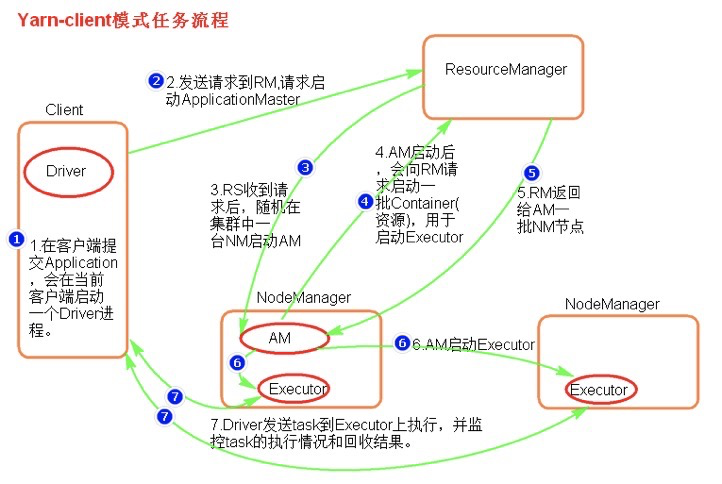
执行流程:
客户端提交一个Application,在客户端启动一个Driver进程
应用程序启动后会向ResourceManager发送请求,启动ApplicationMaster的资源
ResourceManager收到请求,随机选择一台NodeManager启动ApplicationMaster
ApplicationMaster启动后,会向ResourceManager请求一批container资源,用于启动Executor
ResourceManager会找到一批NodeManager返回给ApplicationMaster,用于启动Executor
ApplicationMaster向NodeManager发送命令启动Executor
Executor启动后,会反向注册给Driver,Driver发送task到Executor,将执行情况和结果返回给Driver端
总结:客户端模式适用于测试,因为Driver运行在本地,有输出可以在屏幕看见。但是由于Driver与集群中的Executor有大量的网络通信,会造成客户机网卡流量的增加。
ApplicationMaster的作用:
为当前的Application申请资源
给NameNode发送消息启动Executor
没有任务调度的功能
6.3 集群模式(cluster)
1../bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
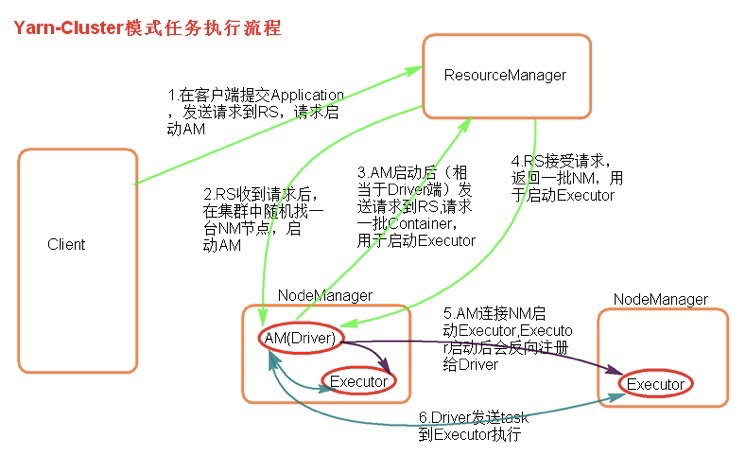
执行流程:
客户机提交Application应用程序,发送请求到ResourceManager,请求启动ApplicationMaster。
ResourceManager收到请求后随机在一台NodeManager上启动ApplicationMaster(相当于Driver端)。
ApplicationMaster启动,ApplicationMaster发送请求到ResourceManager,请求一批container用于启动Excutor。
ResourceManager返回一批NodeManager节点给ApplicationMaster。
ApplicationMaster连接到NodeManager,发送请求到NodeManager启动Excutor。
Excutor反向注册到ApplicationMaster所在的节点的Driver。Driver发送task到Excutor。
总结:集群模式用于生产环境,因为Driver运行在Yarn集群中某一台NodeManager中,每次提交任务的Driver所在的机器都是随时的,不会产生某一台机器网卡流量激增的现象。缺点是任务提交后不能看到日志,只能通过yarn查看日志。
ApplicationMaster的作用:
为当前的Application申请资源
给NameNode发送消息启动Executor
任务调度
1.# 集群模式查看日志
2../yarn logs -applicationId application_1467776900158_0099
3.# 集群模式停止任务
4../yarn application -kill application_1467776900158_0099
7. SparkCore详解
前面介绍了Spark的三种运行模式之后,接下来是对Spark的核心内容进行理解,SparkCore是Spark里面最核心的部分,而SparkCore里面最重要的就是对RDD概念的深刻理解。
7.1 深刻理解RDD
RDD(Resilient Distributed Dateset):弹性分布式数据集
RDD有五大特性:
RDD由一系列的partition(分区)组成
函数是作用在每一个parition(分区)上面的
RDD之间有一系列的依赖关系
RDD是KV格式的(key,value)
RDD提供一系列最佳的计算位置
RDD理解图:
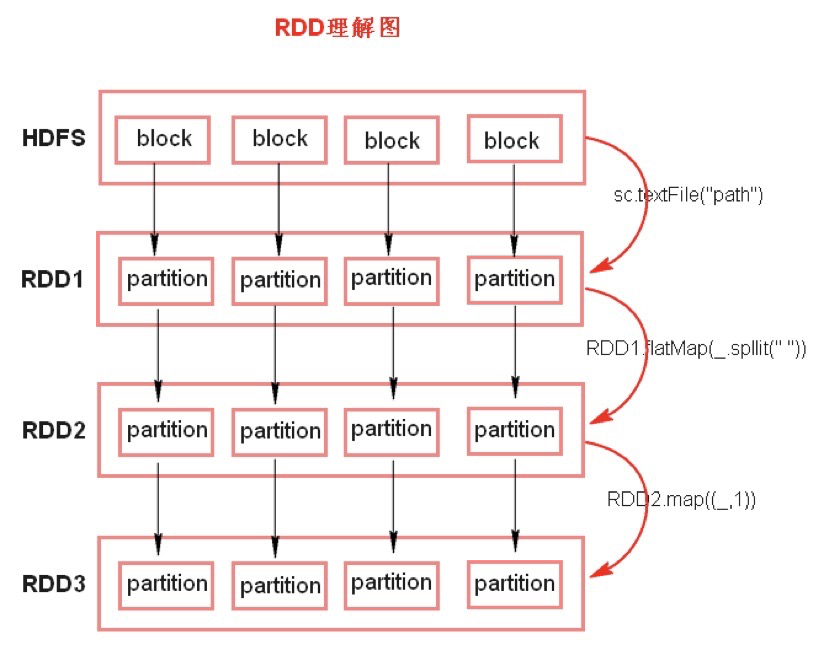
textFile方法底层封装的是MR读取文件的方法,默认split大小是一个block大小
RDD实际上不存储数据,也就是中间的每一步操作并不是真正的落地
KV格式的RDD指的是二元组对象
RDD之间存在一定的依赖关系(数据血缘)
RDD的弹性(容错)表现在:
partition数量,大小没有限制,体现了RDD的弹性
RDD之间的依赖关系,可以基于上一个RDD重新计算出RDD
RDD的分布式表现在:
RDD由partition组成,partition分布在不同的节点上
RDD提供计算最佳位置,体现了数据本地化,体现了大数据中”计算移动数据不移动”的理念
7.2 宽依赖与窄依赖
RDD之间有一系列的依赖关系,依赖关系又分为宽依赖和窄依赖。
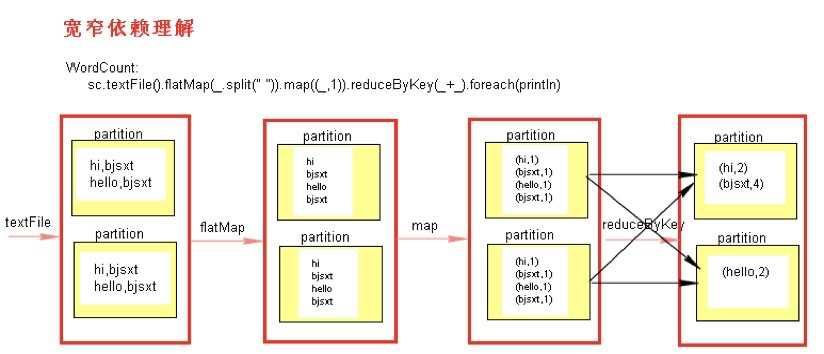
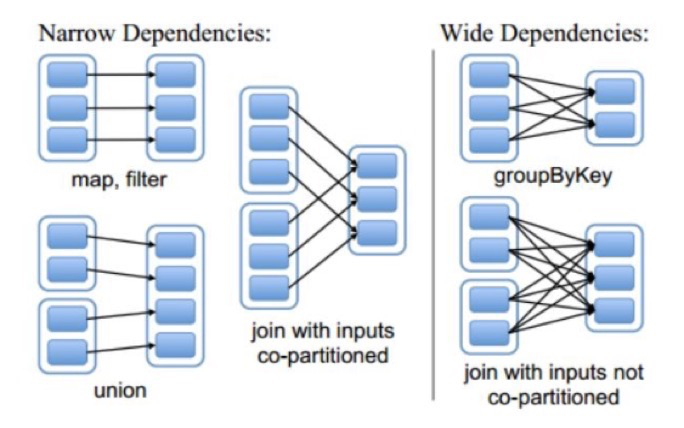
窄依赖:父RDD和子RDD partition之间是一对一的关系,或者父RDD一个partition只对应一个子RDD的partition。这种情况下不会有shuffle的产生。
宽依赖:父RDD与子RDD partition之间的关系是一对多。这种情况下会有shuffle的产生。
7.3 Shuffle过程
Shuffle是将相同的key落地磁盘,有几个分区就形成几个文件
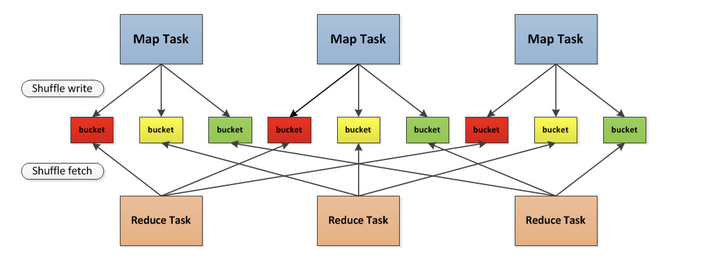
shuffle是连接Map和Reduce之间的桥梁,Map的输出要到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整个程序的性能和吞吐量,spark作为mapreduce框架的一种实现,自然也实现了shuffle的逻辑。
分为两个过程,分为shuffle write和shuffle fetch,中间有一个抽象概念bucket,bucket数量个数是M x R,早期是先全部存储到内存中,然后写入磁盘,这对内存是一个非常大的开销。后来变为逐渐写入。
spark任务中会发生数据倾斜或数据偏移。
7.4 Stage的划分
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
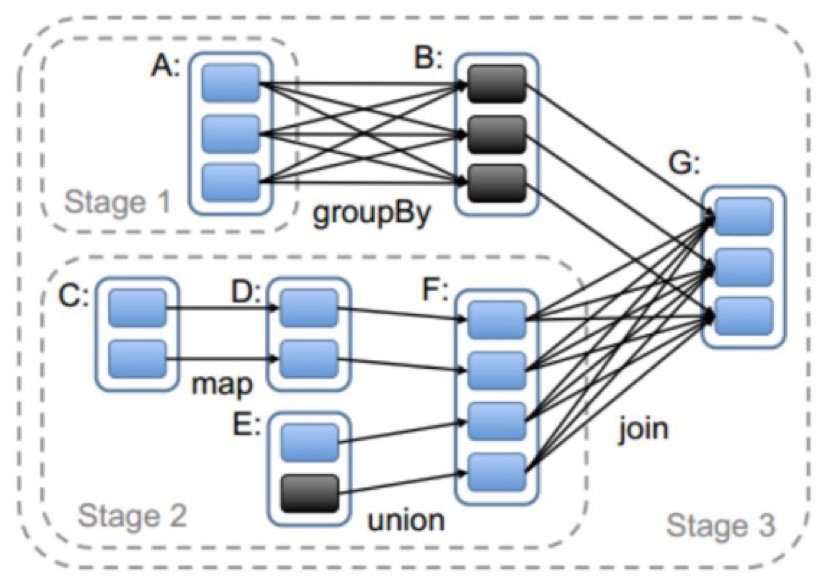
stage是由一组并行的task组成
stage切割原则:从后往前,遇到宽依赖就切割stage
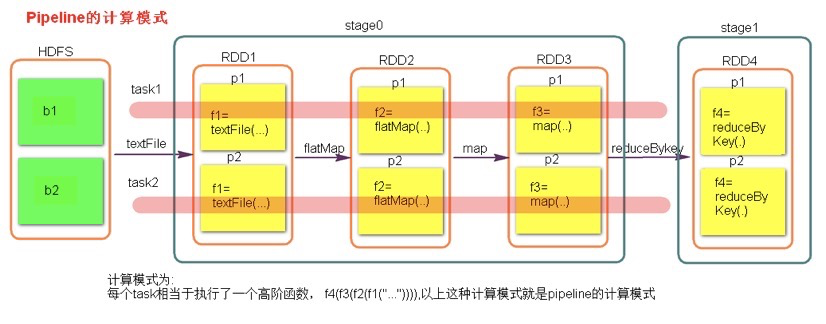
数据一直在管道里面什么时候会落地?
对RDD进行持久化的时候
shuffle write的时候
8. RDD的操作
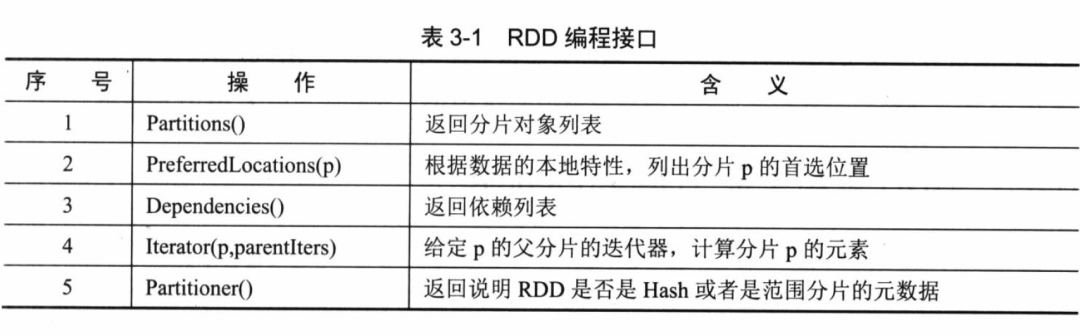

8.1 创建操作
用于RDD创建工作。RDD创建只有两种方法,一种是来自于内存集合和外部存储系统,另一种是通过转换操作生成的RDD。
1.# pyspark
2.# 对集合进行并行化
3.>>> lines = sc.parallelize(["pandas", "i like pandas"])
4.# 读取外部数据集
5.>>> lines = sc.textFile("/path/to/README.md")
8.2 转换操作
将RDD通过一定的操作变换成新的RDD,RDD的转换操作是惰性操作,并没有立即执行。
1.# pyspark
2.>>> rdd = sc.parallelize([1, 2, 3, 4, 5])
3.>>> rdd.filter(lambda x: x % 2 == 0).collect()
8.3 行动操作
能够触发Spark运行的操作,例如,对RDD进行collect就是行动操作。
Spark中行动操作分为两类:一类的操作结果变成内存的集合或变量;另一类将RDD保存到外部文件系统或者数据库中。
1.>>> rdd = sc.parallelize([1, 2, 3, 4, 5])
2.# 获取第一个元素
3.>>> rdd.first()
4.# 获取前两个元素
5.>>> rdd.take(2)
8.4 控制操作
进行RDD持久化,可以让RDD按不同的存储策略保存在磁盘或者内存中。
1.# pyspark
2.>>> rdd = sc.parallelize(["b", "a", "c"])
3.>>> rdd.persist().is_cached
4.True
8.5 更多操作
map:
1.# pyspark
2.>>> rdd = sc.parallelize(["spark rdd example", "sample example"])
3.>>> rdd.map(lambda x: x.split(" ")).collect()
4.[["spark", "rdd", "example"], ["sample", "example"]]
flatmap
1.# pyspark
2.>>> rdd = sc.parallelize(["spark rdd example", "sample example"])
3.>>> rdd.flatMap(lambda x: x.split(" ")).collect()
4.["spark", "rdd", "example", "sample", "example"]
mapPartitions
1.# pyspark
2.>>> rdd = sc.parallelize([1, 2, 3, 4], 2)
3.>>> def f(iterator): yield sum(iterator)
4.>>> rdd.mapPartitions(f).collect()
flatMap函数可以将一条记录转换成多条记录(一对多关系),map函数将一条记录转换为另一条记录(一对一关系)
flatMap与map类似,但每个元素输入项都可以被映射0个或多个的输出项,最终将结果“扁平化”后输出。
map的输入变换函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区
sortBy
1.# pyspark
2.>>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
3.>>> sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()
4.[('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
5.>>> sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()
6.[('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
reduce
1.# pyspark
2.>>> from operator import add
3.>>> sc.parallelize([1, 2, 3, 4, 5]).reduce(add)
4.15
reduceByKey
1.# pyspark
2.>>> from operator import add
3.>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
4.>>> sorted(rdd.reduceByKey(add).collect())
5.[('a', 2), ('b', 1)]
reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个为止。
reduceByKey对元素为KV对的RDD中Key相同的元素Value进行reduce,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
join
1.# pyspark
2.>>> x = sc.parallelize([("a", 1), ("b", 4)])
3.>>> y = sc.parallelize([("a", 2), ("a", 3)])
4.>>> sorted(x.join(y).collect())
5.[('a', (1, 2)), ('a', (1, 3))]
leftOuterJoin
1.# pyspark
2.>>> x = sc.parallelize([("a", 1), ("b", 4)])
3.>>> y = sc.parallelize([("a", 2)])
4.>>> sorted(x.leftOuterJoin(y).collect())
5.[('a', (1, 2)), ('b', (4, None))]
saveAsText
1.# pyspark
2.>>> sc.parallelize(range(10)).saveAsTextFile(tempFile.name)
9. 共享变量
Spark程序的大部分操作都是RDD操作,通过传入函数给各执行器上的RDD操作函数来计算。这些函数在不同的物理结点上是并发执行的,因此其内部的变量有不同的作用域,之间不能相互访问,所以Spark提供了两类共享变量供编程使用——广播变量和累加变量。
9.1 广播变量
Executor端用到了Driver端的变量,Driver会将变量发送至Executor内存。
使用广播变量前:
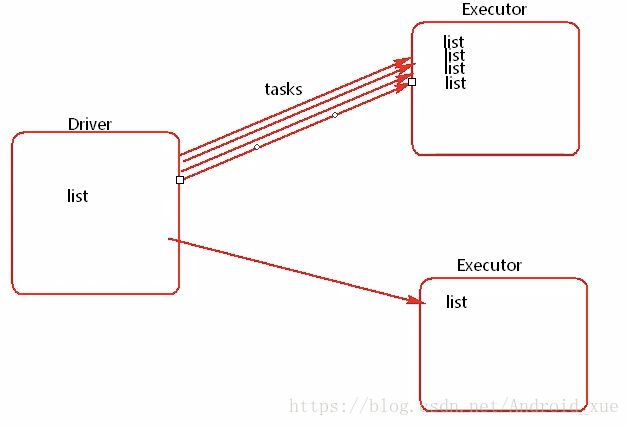
如果一个list比较大,占用内存比较多,多个执行器,会导致OOM。
使用广播变量后:
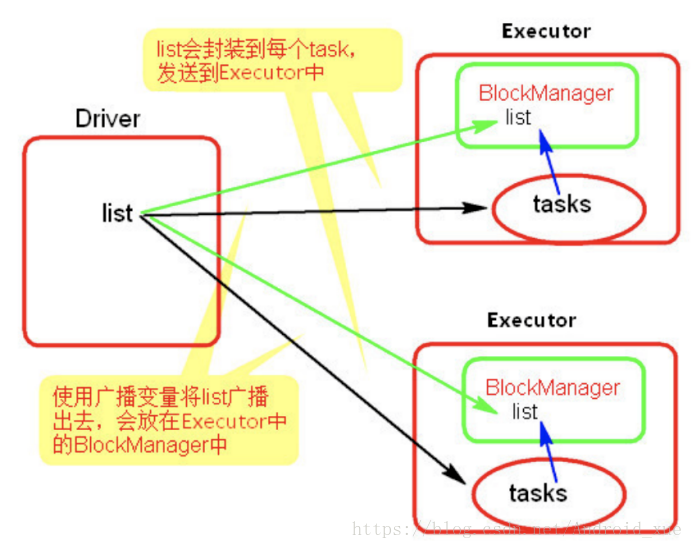
广播变量示例如下:
1.# scala版本
2.# 广播变量的使用
3.val conf = new SparkConf().setMaster("local").setAppName("broadcast")
4.val sc = new SparkContext(conf)
5.val list = List("hello java")
6.val broadcast = sc.broadcast(list)
7.val linesRDD = sc.textFile("./word")
8.linesRDD.filter(line => {broadcast.value.contains(line)}).foreach(println)
9.sc.stop()
1.# pyspark版本
2.>>> rdd = sc.parallelize(["dog", "cat", "dog", "cat"], 4)
3.>>> mapper = {"dog":1, "cat":2}
4.# 将mapper转变为广播变量
5.>>> broadcatVar = sc.broadcast(mapper)
6.# 通过value获得广播变量的值
7.>>> broadcatVar.value
8.# 通过get函数取得key对应的value值
9.>>> broadcatVar.value.get("dog")
10.# 在rdd中使用广播变量
11.>>> rdd.map(lambda x: broadcatVar.value.get(x)).collect()
RDD不能作为广播变量广播出去,因为RDD是不存数据的,但是可以将RDD的结果广播出去
广播变量只能在driver端定义,不能在executor端定义
在driver端可以修改广播变量的值,在executor无法修改广播变量的值
9.2 累加变量
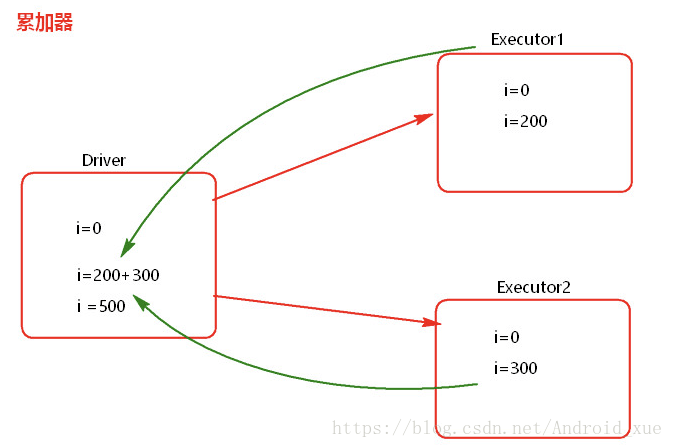
累加器错误用法:
1.// scala
2.// 错误用法
3.val accum= sc.accumulator(0, "Error Accumulator")
4.val data = sc.parallelize(1 to 10)
5.//用accumulator统计偶数出现的次数,同时偶数返回0,奇数返回1
6.val newData = data.map{x => {
7. if(x%2 == 0){
8. accum += 1
9. }else 1
10.}}
11.//使用action操作触发执行
12.newData.count
13.//此时accum的值为5,是我们要的结果
14.accum.value
15.//继续操作,查看刚才变动的数据,foreach也是action操作
16.newData.foreach(println)
17.//上个步骤没有进行累计器操作,可是累加器此时的结果已经是10了
18.//这并不是我们想要的结果
19.accum.value
累加器正确用法:
1.// scala
2.// 在driver中定义
3.val accum = sc.accumulator(0, "Example Accumulator")
4.//在task中进行累加
5.sc.parallelize(1 to 10).foreach(x=> accum += 1)
6.//在driver中输出
7.accum.value
8.//结果将返回10
9.res: 10
累加器代码示例:
1.// scala
2.// 累加器的用法
3.val conf = new SparkConf()
4.conf.setMaster("local").setAppName("accumulator")
5.val sc = new SparkContext(conf)
6.val accumulator = sc.accumulator(0)
7.sc.textFile("./words.txt").foreach { x =>{accumulator.add(1)}}
8.println(accumulator.value)
9.sc.stop()
1.# pyspark
2.>>> rdd = sc.parallelize(range(100))
3.# 创建累加器
4.>>> counter = sc.accumulator(0)
5.### 定义一个计算有多少个偶数的函数
6.>>> def conditional_counter(x):
7. global counter
8. if x % 2 == 0:
9. counter += 1
10. return x
11.>>> rdd_count = rdd.map(lambda x:conditional_counter(x))
12.### 在转换阶段不触发
13.>>> counter.value
14.>>> rdd_count.count()
15.>>> counter.value
16.# 如果再执行一次,数值会变
17.>>> counter.value
18.# 用persist()解决
19.>>> rdd_count.persist()
累加器在Driver端定义赋初始值,并且只能在Dirver端读取,在Excutor端更新
10. Spark SQL
Spark SQL的官网地址为:https://spark.apache.org/docs/2.2.0/sql-programming-guide.html
10.1 Spark SQL的前世今生
最早期Hive是构建在Hadoop之上的一个开源查询系统
后来发展出了Spark,比Hadoop运行更快,于是有人提出能不能hive on spark,于是诞生了shark,shark仅仅是把物理执行计划从mapreduce作业替换成spark作业,所以导致shark对hive的依赖很大
于是shark项目被终止,最终诞生了Spark SQL
10.2 RDD、DataFrame与Dataset
Spark的API三剑客:RDD、DataFrame、Dataset
如果你是 Python 语言使用者,就用 DataFrame,在需要更细致的控制时就退回去使用 RDD;
Dataframe是Dataset的子集,也就是Dataset[Row]
Dataset的底端是RDD。Dataset对RDD进行了更深一层的优化
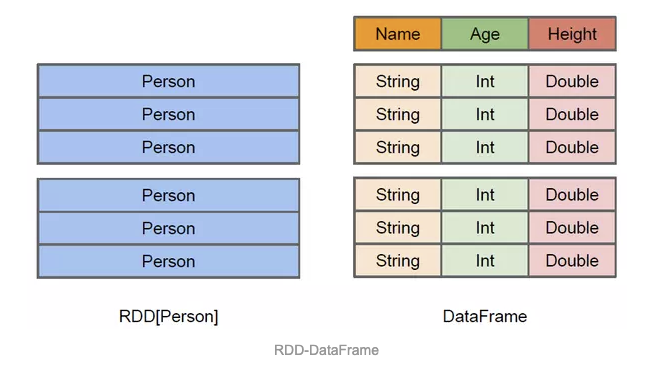
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame多了数据的结构信息,即schema。
RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
10.3 Spark SQL代码示例
Spark SQL示例
1.# pyspark
2.# 入口:SparkSession available as 'spark'
3.# 创建DataFrame
4.df = spark.read.json("file:///home/work/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.json")
5.df.show()
6.# 打印数据结构
7.df.printSchema()
8.# 数据变换与选择
9.df.select("name").show()
10.df.select("age").show()
11.df.select(df['name'], df['age'] + 1).show()
12.df.filter(df['age'] > 21).show()
13.df.groupBy("age").count().show()
14.# 创建全局会话视图
15.df.createGlobalTempView("people")
16.# sql查询
17.spark.sql("SELECT * FROM global_temp.people").show()
18.# 跨会话的
19.spark.newSession().sql("SELECT * FROM global_temp.people").show()
DataFrame与RDD的相互转换
1.lines = sc.textFile("file:///home/work/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.txt")
2.lines.collect()
3.parts = lines.map(lambda l: l.split(","))
4.parts.collect()
5.from pyspark.sql import Row
6.people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
7.people.collect()
8.# 注册为一个表,RDD转DataFrame
9.schemaPeople = spark.createDataFrame(people)
10.schemaPeople.createOrReplaceTempView("people")
11.type(people)
12.type(schemaPeople)
13.# 执行Spark SQL
14.teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
15.type(teenagers)
16.teenagers.show()
17.# DataFrame转RDD
18.teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name)
11. Spark Streaming
Spark Streaming官网地址为:https://spark.apache.org/docs/2.2.0/streaming-programming-guide.html

中间可以用机器学习或者图计算进行处理,如下图所示:
11.1 Spark Streaming代码示例
CentOS安装Netcat:
1.sudo yum install nc
1.# pyspark
2.from pyspark.streaming import StreamingContext
3.# 创建入口ssc,创建一个1秒钟一个批次的stream
4.ssc = StreamingContext(sc, 2)
5.# 创建一个DStream,监听本机端口
6.lines = ssc.socketTextStream("172.17.132.103", 9996)
7.words = lines.flatMap(lambda line: line.split(" "))
8.pairs = words.map(lambda word: (word, 1))
9.wordCounts = pairs.reduceByKey(lambda x, y: x + y)
10.wordCounts.pprint()
11.# 开始流式计算
12.ssc.start()
在另一个窗口新建发送消息:
1.nc -lk 9996
11.2 Spark Streaming原理
翻转窗口
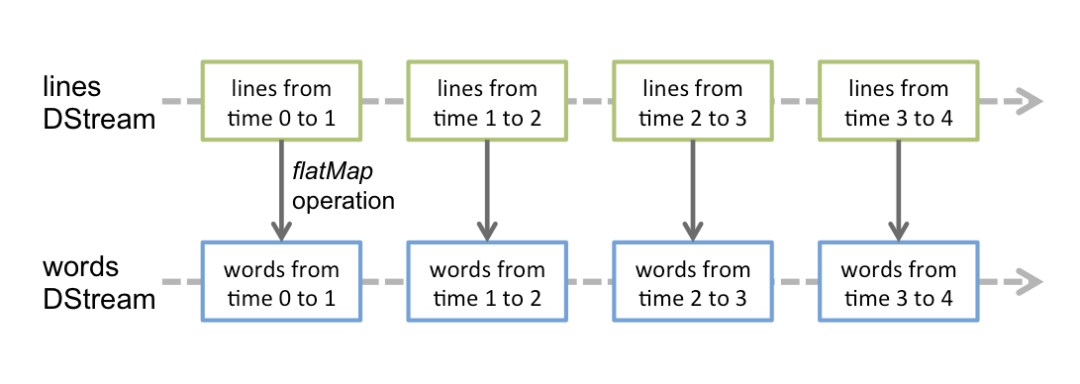
滑动窗口
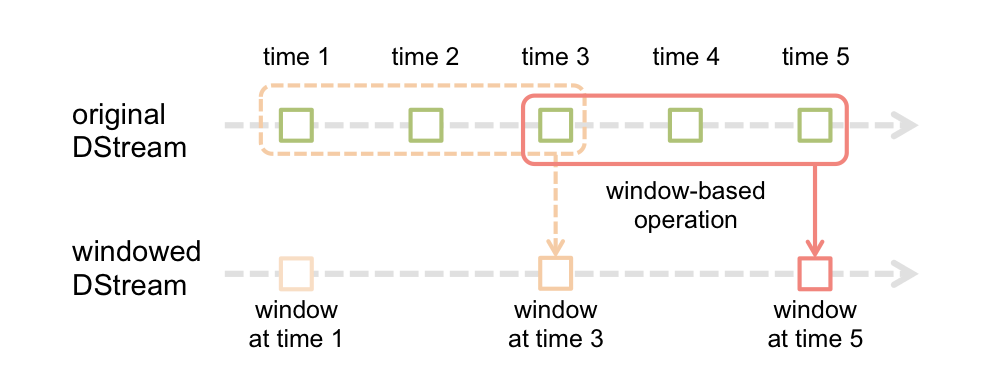
11.3 Spark Streaming读Kafka
第三方包下载地址:https://spark.apache.org/docs/2.2.0/streaming-kafka-integration.html
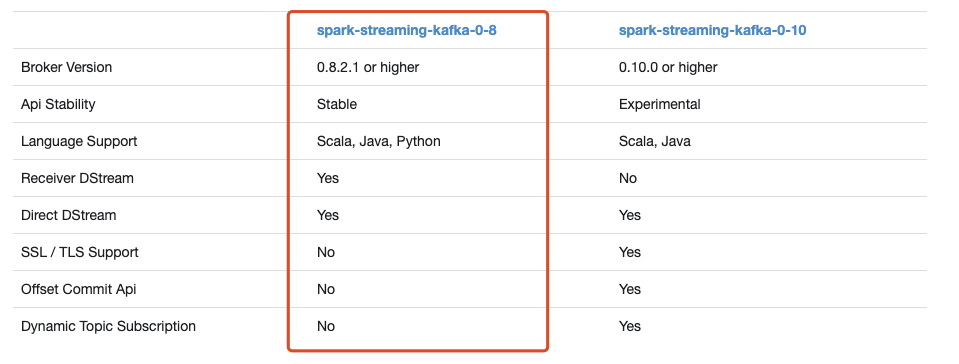
采用端到端直接相连的方法:
简单并行化
高效
完全一次语义(Exactly-once)
开启pyspark
的方法:
方法一:
1.# 开启pyspark
2.bin/pyspark --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0
方法二:
下载地址页面:https://search.maven.org/search?q=a:spark-streaming-kafka-0-8-assembly_2.11%20AND%20v:2.2.0
1.wget https://search.maven.org/remotecontent?filepath=org/apache/spark/spark-streaming-kafka-0-8-assembly_2.11/2.2.0/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar
2.bin/pyspark --jars spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar
在pyspark里面输入如下代码:
1.# pyspark
2.from pyspark.streaming.kafka import KafkaUtils
3.from pyspark.streaming import StreamingContext
4.ssc=StreamingContext(sc, 5)
5.brokers = "172.17.132.103:9092,172.17.132.104:9092,172.17.132.105:9092"
6.topic = "test01"
7.# 连接上kafka
8.directKafkaStream = KafkaUtils.createDirectStream(ssc, [topic], {"metadata.broker.list": brokers})
9.# 处理数据
10.# line是元组形式:(None, 'hello world')
11.words = directKafkaStream.flatMap(lambda line: line[1].split(" "))
12.pairs = words.map(lambda word: (word, 1))
13.wordCounts = pairs.reduceByKey(lambda x, y: x + y)
14.wordCounts.pprint()
15.# 开始流式计算
16.ssc.start()
利用命令行向Kafka写入数据:
1.bin/kafka-console-producer.sh --broker-list 172.17.132.103:9092 --topic test01
12. Spark MLlib
Spark MLlib官网地址为:https://spark.apache.org/docs/2.2.0/ml-guide.html
MLlib:Machine Learning Library
12.1 MLlib与ML的区别
从Spark2.0开始,ML是主要的机器学习库,ML对DataFrame进行操作,而不是像MLlib对RDD进行操作。
ML是升级版的MLlib
ML支持DataFrame数据结构和Pipelines,MLlib仅支持RDD
ML明确区分了分类模型和回归模型,而MLlib并未区分
总而言之,spark.ml更好更牛逼,推荐用spark.ml,下面主要讲解ML库:
主要分为三部分:转换器、评估器与管道。涉及到的一些基本概念如下:
DataFrame
一种新的数据格式,除了支持ML本身的数据格式外,还支持Spark SQL的数据格式
Transformers
把一种数据格式转变为另一种数据格式,例如一个模型就是一个transformer,它能把带标记的数据转变为带预测的数据
Estimators
接收DataFrame并产生Model,例如一个机器学习算法就是一个Estimator
Pipeline
一个管道链由多个Transformer和Estimators组成。
Parameter
通过指定参数,其共享同样的API。
12.2 一些算法示例
这部分主要是一些分类和回归的算法。
工程上用的比较多的是两个:GBDT(迭代决策树)和随机森林。
随机森林是通过把很多决策树弄在一起,降低了过拟合的风险,spark.ml提供随机森林的二分类和多分类,其代码示例如下:
1.from pyspark.ml import Pipeline
2.from pyspark.ml.classification import RandomForestClassifier
3.from pyspark.ml.feature import StringIndexer, VectorIndexer
4.from pyspark.ml.evaluation import MulticlassClassificationEvaluator
5.
6.# Load and parse the data file, converting it to a DataFrame.
7.data = sqlContext.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
8.
9.# Index labels, adding metadata to the label column.
10.# Fit on whole dataset to include all labels in index.
11.labelIndexer = StringIndexer(inputCol="label", outputCol="indexedLabel").fit(data)
12.# Automatically identify categorical features, and index them.
13.# Set maxCategories so features with > 4 distinct values are treated as continuous.
14.featureIndexer =\
15. VectorIndexer(inputCol="features", outputCol="indexedFeatures", maxCategories=4).fit(data)
16.
17.# Split the data into training and test sets (30% held out for testing)
18.(trainingData, testData) = data.randomSplit([0.7, 0.3])
19.
20.# Train a RandomForest model.
21.rf = RandomForestClassifier(labelCol="indexedLabel", featuresCol="indexedFeatures")
22.
23.# Chain indexers and forest in a Pipeline
24.pipeline = Pipeline(stages=[labelIndexer, featureIndexer, rf])
25.
26.# Train model. This also runs the indexers.
27.model = pipeline.fit(trainingData)
28.
29.# Make predictions.
30.predictions = model.transform(testData)
31.
32.# Select example rows to display.
33.predictions.select("prediction", "indexedLabel", "features").show(5)
34.
35.# Select (prediction, true label) and compute test error
36.evaluator = MulticlassClassificationEvaluator(
37. labelCol="indexedLabel", predictionCol="prediction", metricName="precision")
38.accuracy = evaluator.evaluate(predictions)
39.print("Test Error = %g" % (1.0 - accuracy))
40.
41.rfModel = model.stages[2]
42.print(rfModel) # summary only
其对应的参数:
numTrees:森林中数的个数,增加该数会减少预测值的方差,提高模型的准确率,训练时间与树的个数保持线性增长。
maxDepth:森林中树的最大深度,
1.from pyspark.mllib.tree import RandomForest, RandomForestModel
2.from pyspark.mllib.util import MLUtils
3.
4.# Load and parse the data file into an RDD of LabeledPoint.
5.data = MLUtils.loadLibSVMFile(sc, 'data/mllib/sample_libsvm_data.txt')
6.# Split the data into training and test sets (30% held out for testing)
7.(trainingData, testData) = data.randomSplit([0.7, 0.3])
8.
9.# Train a RandomForest model.
10.# Empty categoricalFeaturesInfo indicates all features are continuous.
11.# Note: Use larger numTrees in practice.
12.# Setting featureSubsetStrategy="auto" lets the algorithm choose.
13.model = RandomForest.trainClassifier(trainingData, numClasses=2, categoricalFeaturesInfo={},
14. numTrees=3, featureSubsetStrategy="auto",
15. impurity='gini', maxDepth=4, maxBins=32)
16.
17.# Evaluate model on test instances and compute test error
18.predictions = model.predict(testData.map(lambda x: x.features))
19.labelsAndPredictions = testData.map(lambda lp: lp.label).zip(predictions)
20.testErr = labelsAndPredictions.filter(lambda (v, p): v != p).count() float(testData.count())
21.print('Test Error = ' + str(testErr))
22.print('Learned classification forest model:')
23.print(model.toDebugString())
24.
25.# Save and load model
26.model.save(sc, "target/tmp/myRandomForestClassificationModel")
27.sameModel = RandomForestModel.load(sc, "target/tmp/myRandomForestClassificationModel")
13. Spark GraphX
Databricks 属于 Spark 的商业化公司,由美国伯克利大学 AMP 实验室著名的 Spark 大数据处理系统多位创始人联合创立。Databricks 致力于提供基于 Spark 的云服务,可用于数据集成,数据管道等任务。
官网地址为:https://spark.apache.org/docs/2.2.0/graphx-programming-guide.html
GraphX目前只提供scala
语言的API
本节我们主要讲解GraphFrames。
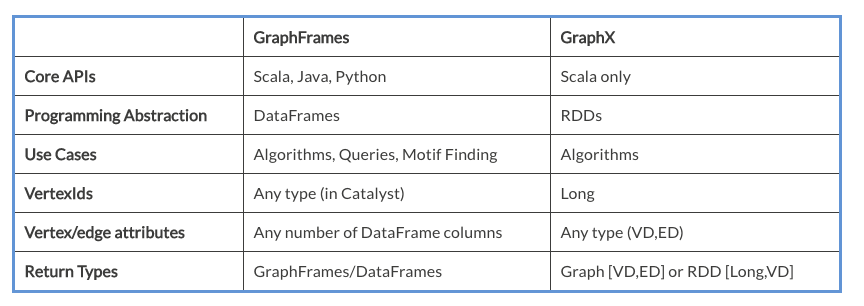
13.1 GraphFrames与GraphX的区别
GraphFrames可以理解为是GraphX的扩展包。
graphframes官网地址为:https://github.com/graphframes/graphframes
其下载包地址为:https://spark-packages.org/package/graphframes/graphframes
1.wget http://dl.bintray.com/spark-packages/maven/graphframes/graphframes/0.6.0-spark2.2-s_2.11/graphframes-0.6.0-spark2.2-s_2.11.jar
2.bin/pyspark --jars graphframes-0.6.0-spark2.2-s_2.11.jar
1.bin/pyspark --packages graphframes:graphframes:0.6.0-spark2.2-s_2.11
GraphFrames提供Python、Java、Scala三种语言的API
底层基于DataFrame数据结构
13.2 图计算简单代码示例
定义如下图所示的一幅图,代码示例如下:
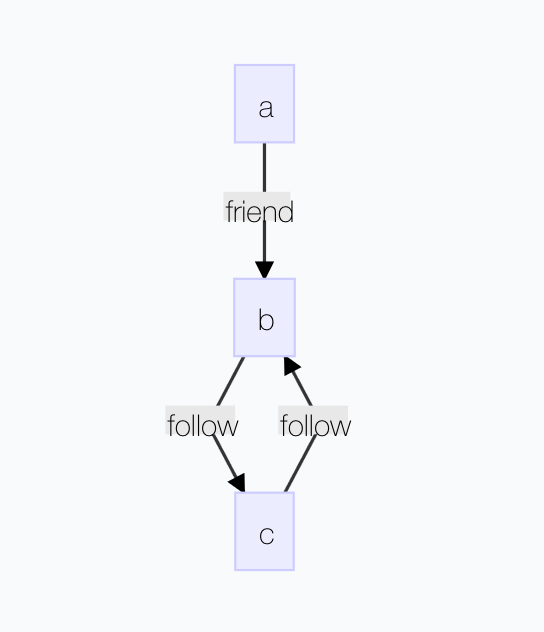
1.# pyspark
2.# 创建顶点
3.v = sqlContext.createDataFrame([
4. ("a", "Alice", 34),
5. ("b", "Bob", 36),
6. ("c", "Charlie", 30),
7.], ["id", "name", "age"])
8.# 创建边
9.e = sqlContext.createDataFrame([
10. ("a", "b", "friend"),
11. ("b", "c", "follow"),
12. ("c", "b", "follow"),
13.], ["src", "dst", "relationship"])
14.# 创建图
15.from graphframes import *
16.g = GraphFrame(v, e)
17.# 计算每个顶点的入度
18.g.inDegrees.show()
19.# 计算关系为follow的边的数目
20.g.edges.filter("relationship = 'follow'").count()
21.
22.# Run PageRank algorithm, and show results.
23.results = g.pageRank(resetProbability=0.01, maxIter=20)
24.results.vertices.select("id", "pagerank").show()
14. 总结
这篇文章把Spark相关的基本概念和用法,以及初步的代码示例都给出来了,涵盖了Spark的方方面面,并且尽量从初学者的视角,用较通俗的方式手把手去介绍,希望能对初学者所有帮助。
同时行文过程参考了非常多的资料,并结合自己的理解与实践,最终总结成此文。这篇文章是【一文彻底搞懂】系列的第二篇,第一篇是《一文彻底搞懂Kafka》。
当然由于个人水平有限,如有疏漏和错误之处,敬请联系我及时告知。
相关阅读:《一文彻底搞懂Kafka》

