




微信公众号:进击的大杂烩
欢迎关注我,一起学习,一起进步!
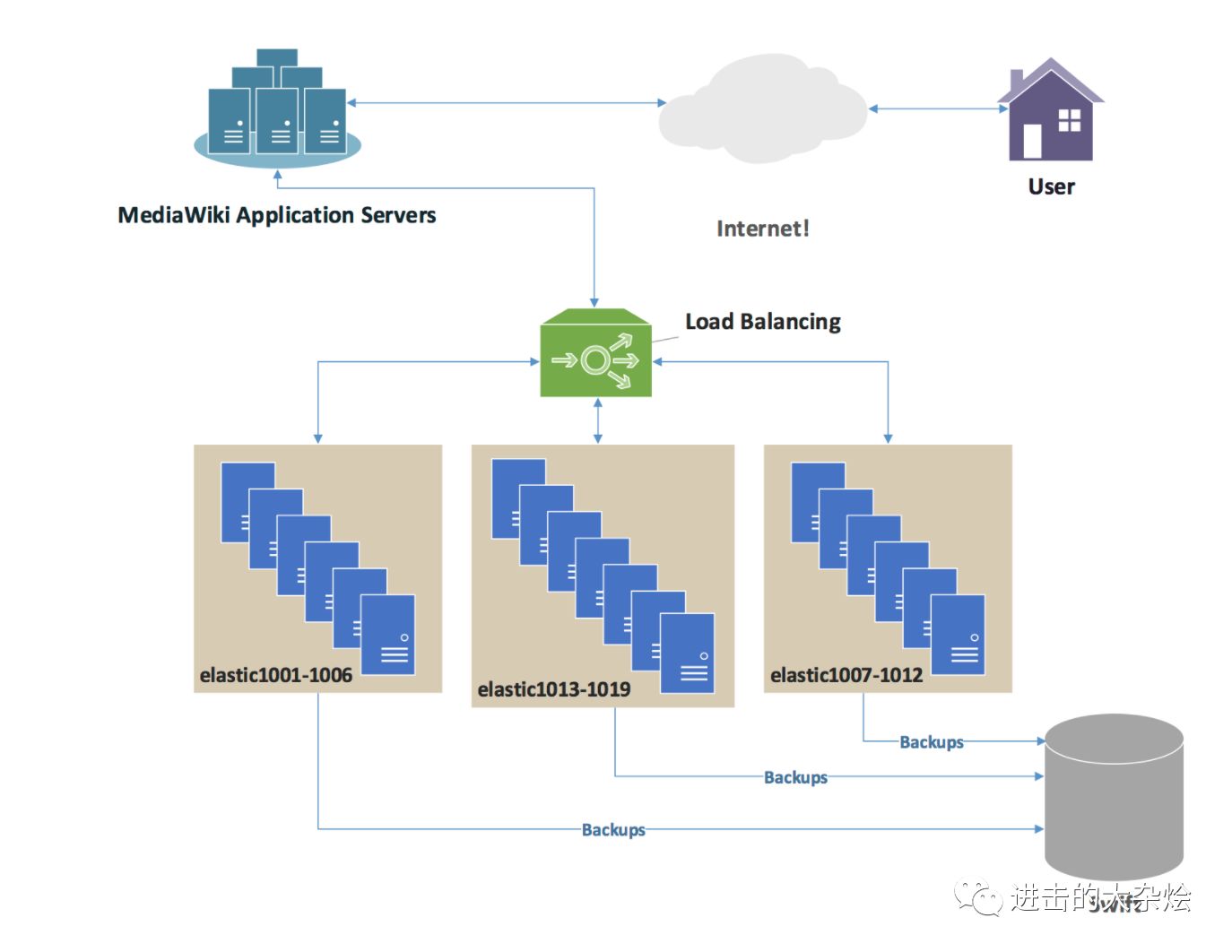
什么是负载均衡
负载平衡(Load balancing)是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。 使用带有负载平衡的多个服务器组件,取代单一的组件,可以通过冗余提高可靠性。负载平衡服务通常是由专用软体和硬件来完成。负载均衡往往配合健康检查使用。
C/S模型的演变
1.单一 server 模型
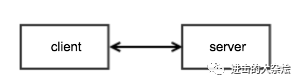
优点:
简单缺点:
服务端单点
单机吞吐量有限适用场景
非重要业务
测试环境
产品初期
2.多 server 模型
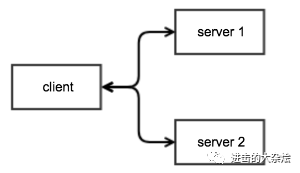
优点:
最基础的负载均衡缺点:
轮询算法由客户端决定
客户端无法实时掌控服务端状态适用场景:
大量外部客户端(如浏览器)接入
客户端可控
3.多 server 进阶模型
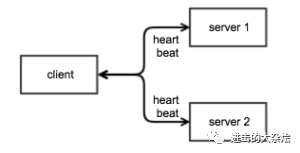
优点:
可用性变高缺点
客户端复杂度高更高
轮询算法由客户端决定
多客户端时,心跳会造成额外负担适用场景
高时效性
客户端可控
4.代理模型
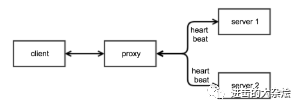
优点
客户端开发简单
扩展/收缩对客户端透明缺点
代理维护成本
可能带来长连接问题
代理自身局限性适用场景
适用于大多数场景
逻辑解耦代理基本模型种类
1.四层负载均衡
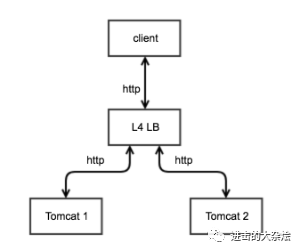
基于ip + port的负载均衡 如:
LVS,f5/haproxy/nginx的四层模式
优点:
理论上可应用于任何应用层协议
某些场景下可突破端口数限制
缺点:
无法理解应用层协议
仅能通过4层信息分流
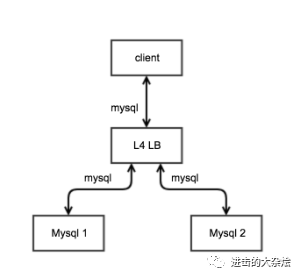
2.七层负载均衡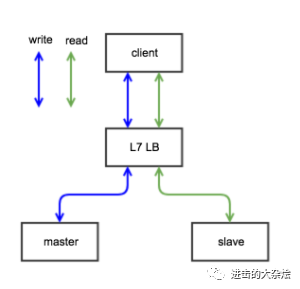
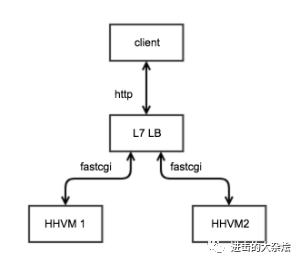
基于应用层信息的负载均衡 如:
f5/haproxy/nginx的7层模式,mysql-proxy
优点:
可理解应用层信息
可根据应用层信息进行分流
可作为网关使用
缺点:
仅支持特定的应用层协议
负载均衡-Nginx
Nginx简介:
nginx [engine x] is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP/UDP proxy server, originally written by Igor Sysoev.
概述:
七层协议支持http, mail(imap | pop3 | smtp)
新版本支持四层负载均衡(since 1.9.0)为什么要用nginx:
高性能静态文件 负载均衡
协议支持完善(gzip, keepalived等)
功能强大(缓存,安全等)
稳定
模块 扩展丰富
其它(平滑重启)
Nginx 为什么性能好?
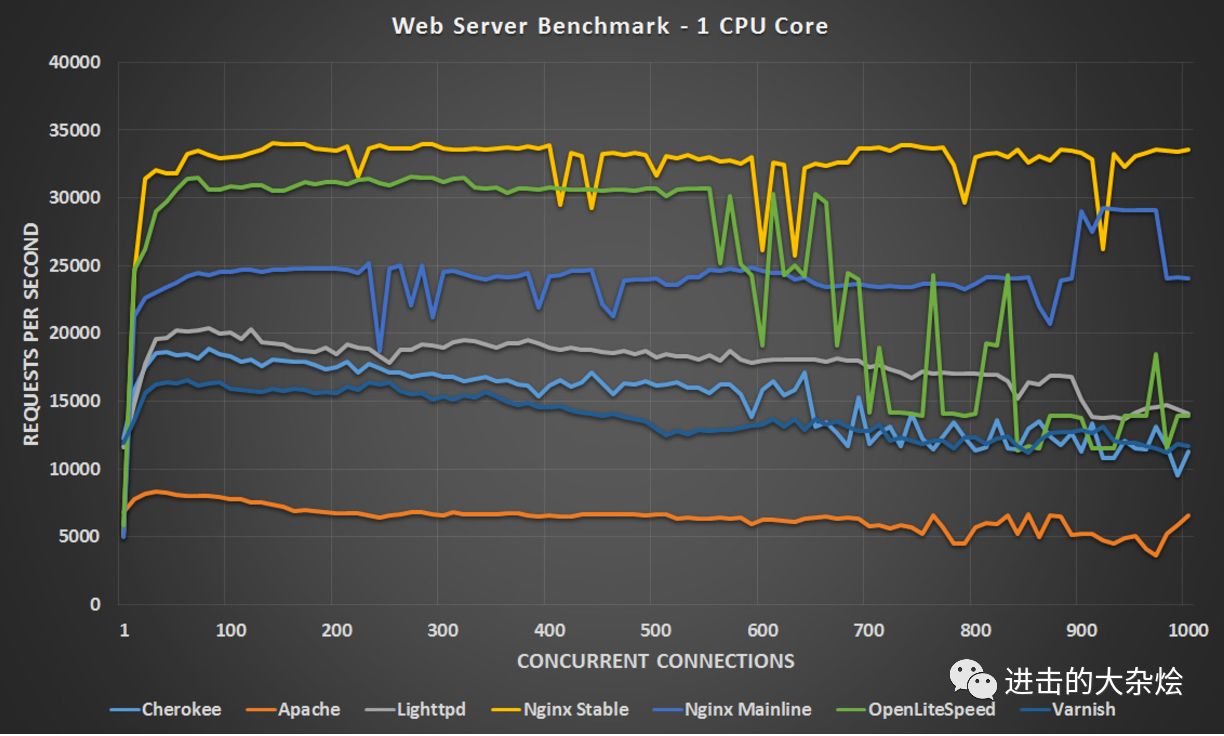
Nginx采用的是IO多路复用的IO模型(根据操作系统选择使用epoll或select模型)
下面一节会简单的讲解一下什么是IO模型Nginx的缺点
| 缺点 | 如何突破 |
| 自身无法支持动态语言 | Fastcgi, uswgi等中间件 |
| 配置语法有局限性(如不支持if else) | Nginx_lua扩展 |
| 做代理时受端口数限制 | 多机部署 |
| 自身高可用问题 | keepalived |
| 做代理时候无主动健康检查 | nginx_upstream_check_module扩展 |
Nginx的常用场景(接入 分流 缓存 动静分离 CDN)
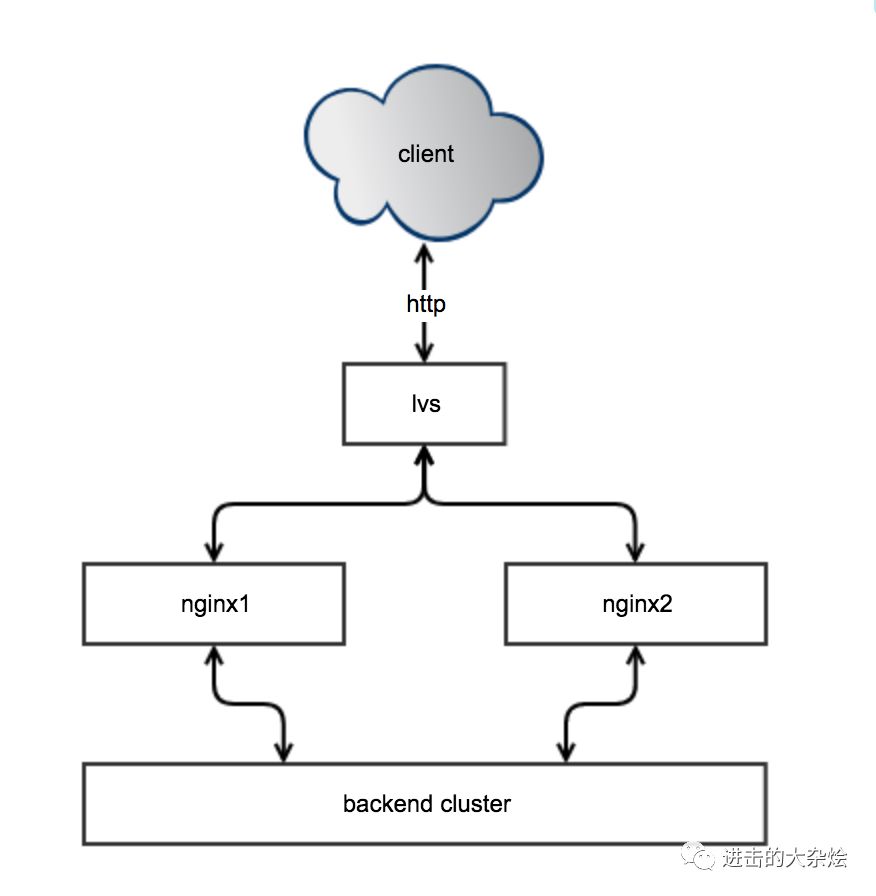
1.常规架构
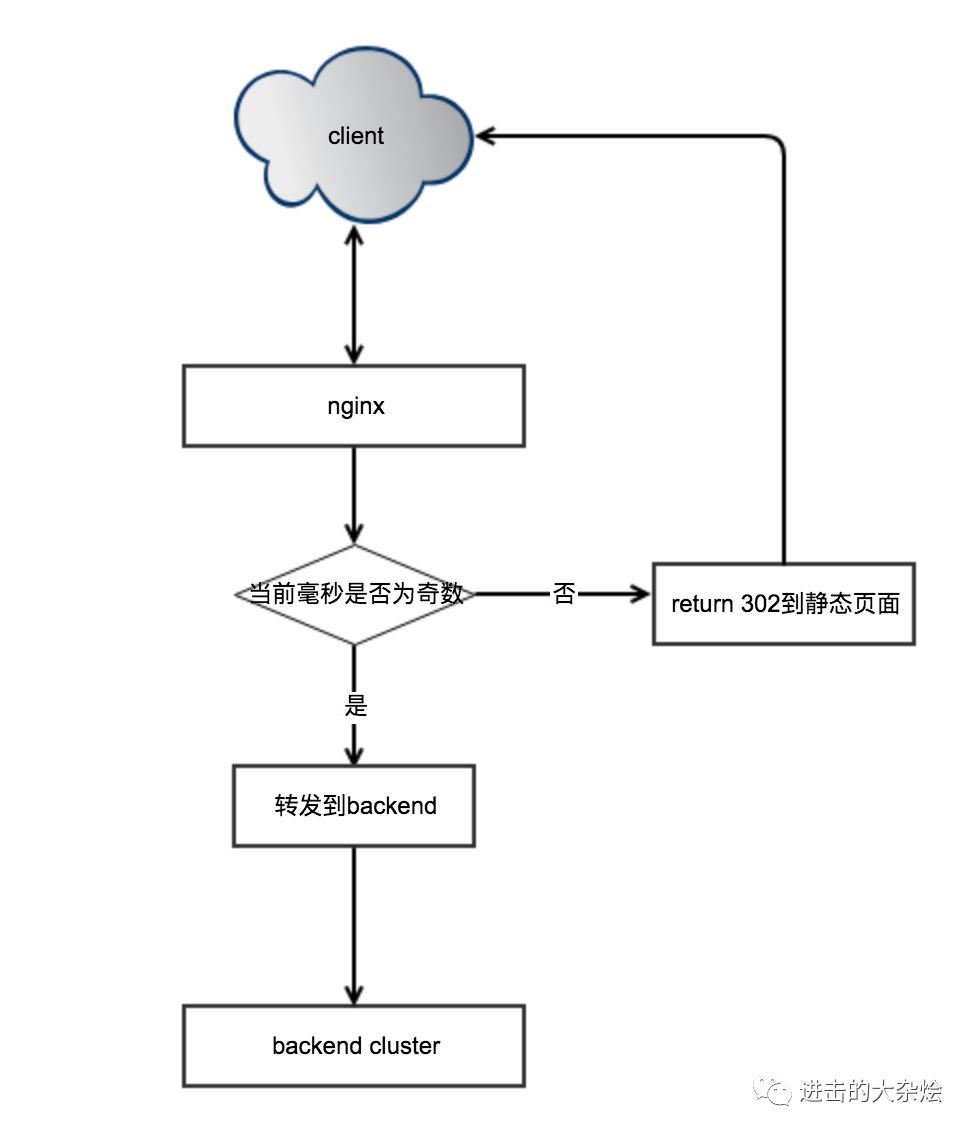
2.产品应用实例
3.使用注意事项
Nginx的配置文件是声明型(declarative),而非过程型的(procedural)
Nginx指令执行顺序的13个阶段 http://openresty.org/download/agentzh-nginx-tutorials-zhcn.html#02-NginxDirectiveExecOrder01
location test {
set $a 32;
echo $a;
set $a 56;
echo $a;
}
curl 'http://localhost:8080/test
56
56
实际的执行顺序
set $a 32;
set $a 56;
echo $a;
echo $a;
proxy_next_upstream双刃剑,可能会造成系统雪崩,可能会导致多次写库。
检索系统应关闭 Error,Timeout,4xx,5xx
http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_next_upstream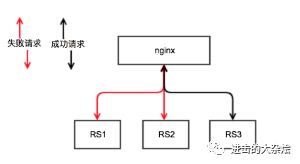
注入问题
location {
rewrite ^ https://$host/$uri;
}
GET test%0d%0aSet-Cookie:%20malicious%3d1 HTTP/1.0
Host: yourserver.com
HTTP/1.1 302 Moved Temporarily
Server:
Location: https://yourserver.com/test
Set-Cookie: malicious=1
原因:
$uri在使用时会url_decode
解决方案:
跳转时候使用$request_uri
IO模型
CPU告诉我们,它自己很快,而上下文切换慢、内存读数据慢、磁盘寻址与取数据慢、网络传输慢……总之,离开CPU 后的一切,除了一级高速缓存,都很慢。我们观察计算机的组成可以知道,主要由运算器、控制器、存储器、输入设备、输出设备五部分组成。运算器和控制器主要集成在CPU中,除此之外全是I/O,包括读写内存、读写磁盘、读写网卡全都是I/O。I/O成了最大的瓶颈。
| 操作 | 真实延迟 | cpu的感觉 |
| 执行指令 | 0.38纳秒 | 1秒 |
| 读L1缓存 | 0.5纳秒 | 1.3秒 |
| 分支纠错 | 5纳秒 | 13秒 |
| 读L2缓存 | 7纳秒 | 18.2秒 |
| 加/解锁 | 25纳秒 | 1分5秒 |
| 内存寻址 | 100纳秒 | 4分20秒 |
| 上下文切换/系统调用 | 1.5微秒 | 1小时5分钟 |
| 1Gbps网络上传输2KB数据 | 20微秒 | 14.4小时 |
| 从内存读1M连续数据 | 250微秒 | 7.5天 |
| ping同idc两台主机 | 0.5毫秒 | 15天 |
| 从ssd读取1M连续数据 | 1毫秒 | 1个月 |
| 从硬盘读取1M连续数据 | 20毫秒 | 20个月 |
| ping不同城市主机 | 150毫秒 | 12.5年 |
| 虚拟机重启 | 4秒 | 300年 |
| 服务器重启 | 5分钟 | 2万5千年 |
1.阻塞IO模型IO模型种类
阻塞IO模型:
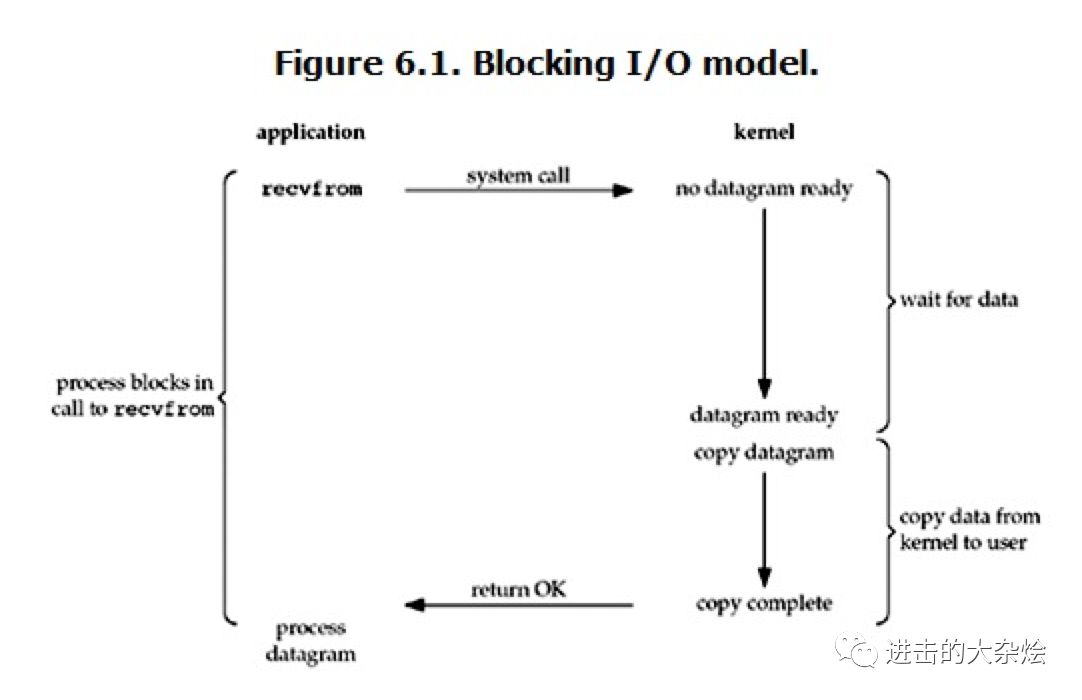
在linux中,默认情况下所有的socket都是blocking。
当内核未准备好数据时,进程只能block,傻傻等待。
食堂打饭:
管食堂大妈要一份饭,之后傻等,待大妈准备好饭后,拿饭走人。
rv = ''
while True:
# block io
data = sock.recv(1024)
if not data:
sock.close()
break
rv += data
return rv
2.非阻塞IO模型
非阻塞IO模型
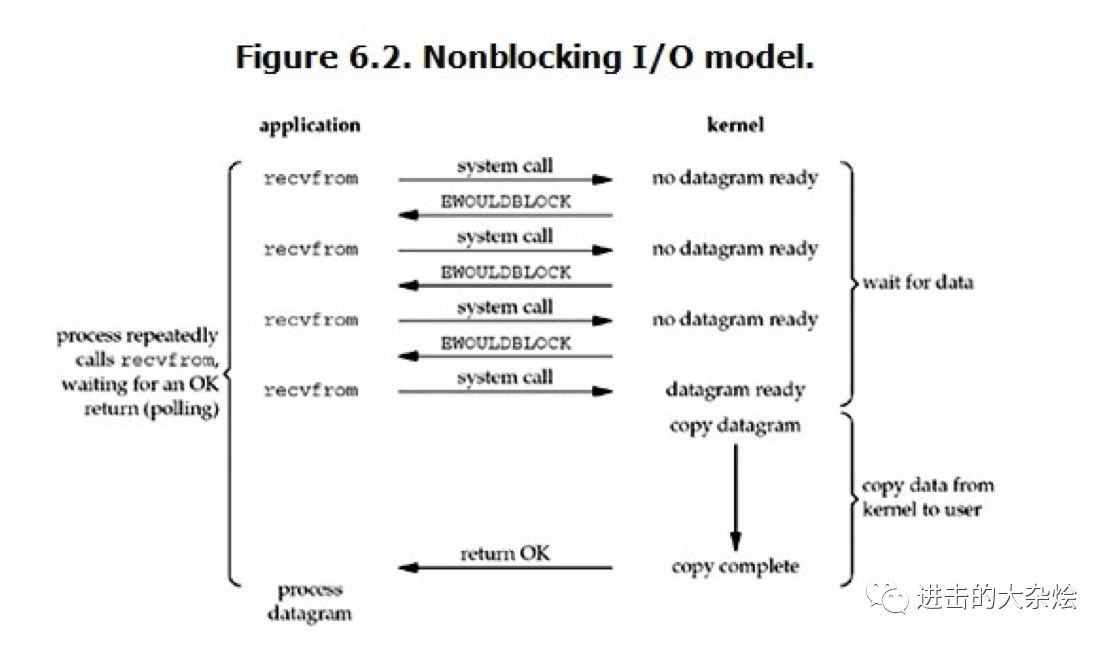
用户进程需要不断的主动询问kernel数据好了没有
效率可能更低下
食堂打饭:
管食堂大妈要一份饭,到座位玩手机,之后每过一段时间来问一下饭准备好没,直到饭好了,拿饭走人。
rv = ''
while True:
sock.setblocking(False)
try:
data = sock.recv(1024)
if not data:
sock.close()
break
rv += data
except OSError:
do_something_else
return rv
3.IO多路复用
IO多路复用
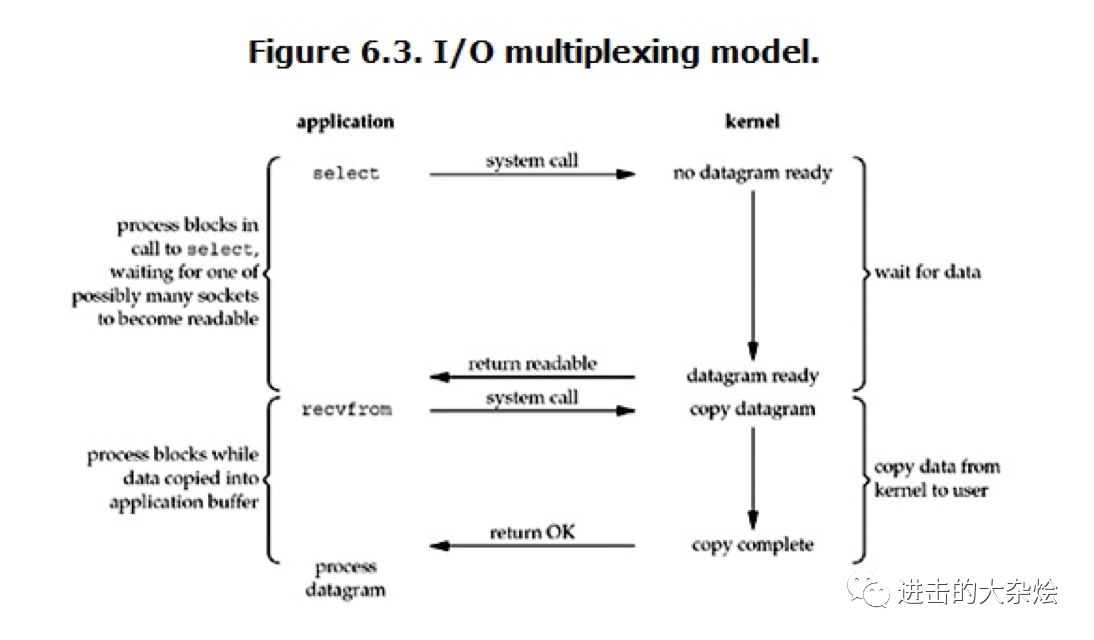
用户进程通过某些系统调用(select, epoll)监听在多个fd上
当fd可读/写时,内核将通知用户进程,用户进程再读取
避免了无意义的block
食堂打饭:
管食堂大妈要一份饭(系统调用),到座位玩手机,直到大妈喊你,再去拿饭走人。
while sockets:
# this select call blocks until one or more of the
# sockets is ready for read I/O
rlist, _, _ = select(sockets, [], [])
# rlist is the list of sockets with data ready to read
for sock in rlist:
data = ''
while True:
new_data = sock.recv(1024)
else:
if not new_data:
break
else:
data += new_data
IO 模型的应用
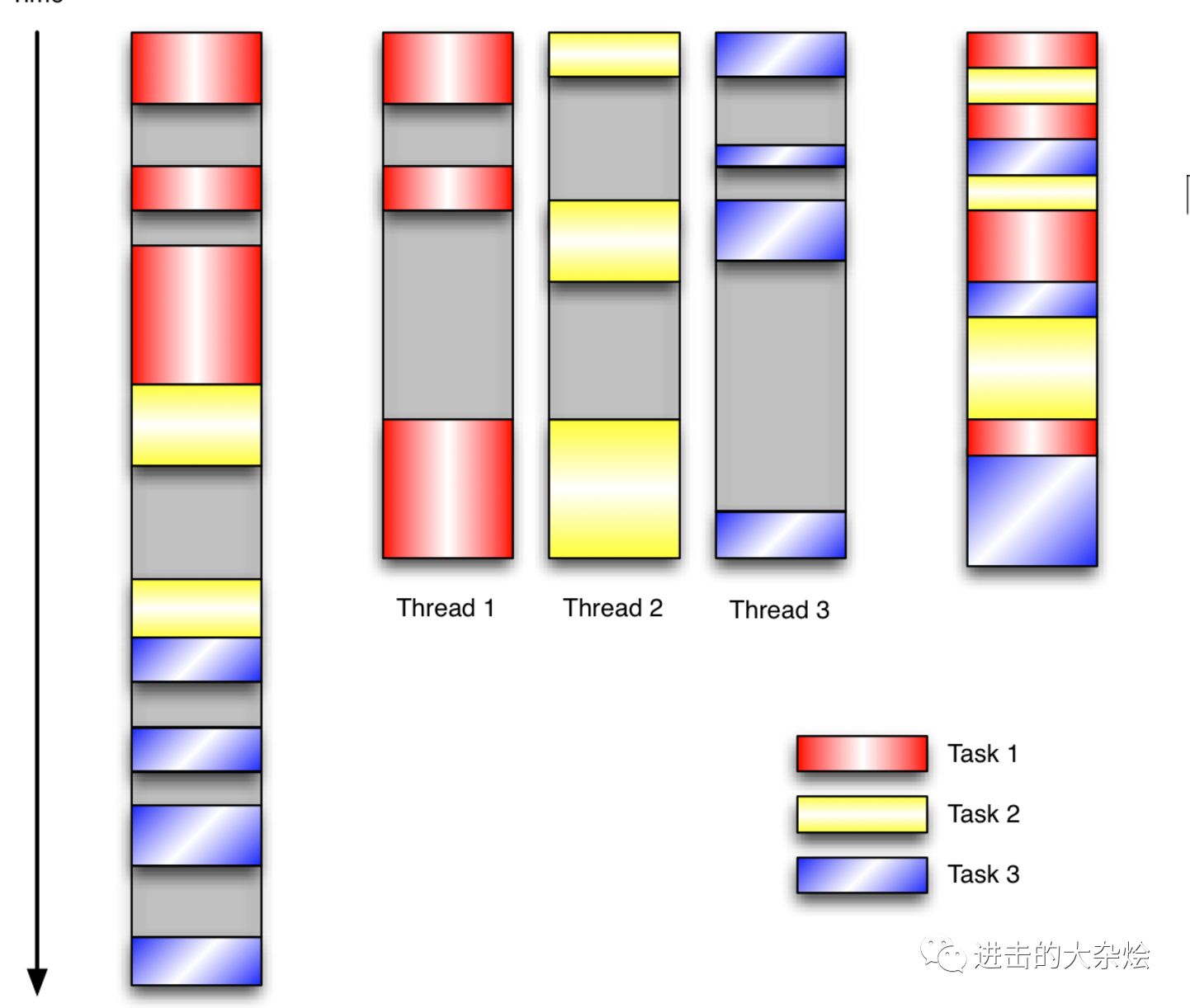
1.进程模型:
单线程
多线程
单线程IO多路复用
2.高并发模型:
多线程:
并发达到一定量时内存首先将耗尽 因为在 linux 系统中,线程数是有限的,每个线程必须预分配8m大小的栈,不论是否使用!所以,线程增加时,内存首先成为瓶颈即使挺过内存问题,当并发请求足够多时,cpu 争用线程的调度问题又成为系統瓶颈单线程IO多路复用:
只有相关事件发生时,才处理具体数据 如果当前接口没有数据时,就会立即切换出去,处理其它请求,所以,虽然只有一个线程,但是,可以同时处理很多很多的請求处理 那么,这种形式的 web 系統,可以很轻易的将 cpu 跑满,即使带宽没有跑满的情况下; 而 apache 这类多进程多线程模型的服务器,则很难将 cpu 跑满。
参考&阅读补充
章亦春的nginx教程 http://openresty.org/download/agentzh-nginx-tutorials-zhcn.html
Nginx_lua手册 https://github.com/openresty/lua-nginx-module
Taobao nginx手册 http://tengine.taobao.org/book/
Nginx wiki http://nginx.org/
