




1、目录简介
目录提供元数据,例如数据库、表、分区、视图以及访问存储在数据库或其他外部系统中的数据所需的功能和信息。
数据处理最重要的方面之一是管理元数据。它可能是临时元数据,如临时表,或针对表环境注册的 UDF。或永久元数据,如 Hive Metastore 中的元数据。目录提供统一的 API 来管理元数据并使其可从表 API 和 SQL 查询访问。
Catalog 使用户能够引用其数据系统中现有的元数据,并自动将它们映射到 Flink 对应的元数据。例如,Flink 可以自动将 JDBC 表映射到 Flink 表,用户不必在 Flink 中手动重写 DDL。Catalog 极大地简化了在用户现有系统上开始使用 Flink 所需的步骤,并极大地增强了用户体验。
2、目录类型
2.1 内存目录
GenericInMemoryCatalog
是一个目录的内存实现。所有对象仅在会话的生命周期内可用。
2.2 Jdbc 目录
在JdbcCatalog
使用户能够用flink连接到过JDBC协议关系数据库。PostgresCatalog
是目前 JDBC Catalog 的唯一实现。有关设置目录的更多详细信息,请参阅JdbcCatalog 文档。
2.3 hive 目录
有HiveCatalog
两个目的;作为纯 Flink 元数据的持久存储,以及读写现有 Hive 元数据的接口。Flink 的Hive 文档提供了有关设置目录和与现有 Hive 安装接口的完整详细信息。
+Hive Metastore 以小写形式存储所有元对象名称。这与
GenericInMemoryCatalog
区分大小写的不同
2.4 用户自定义目录
目录是可插入的,用户可以通过实现Catalog
接口来开发自定义目录。
为了在 Flink SQL 中使用自定义目录,用户应该通过实现CatalogFactory
接口来实现相应的目录工厂。工厂是使用 Java 的服务提供者接口 (SPI) 发现的。实现此接口的类可以添加到 META_INF/services/org.apache.flink.table.factories.Factory
JAR 文件中。提供的工厂标识符将用于匹配type
SQL CREATE CATALOG
DDL 语句中的所需属性。
3、如何创建和注册 Flink 表到目录
3.1 flink 创建hive catalog环境
export HADOOP_CLASSPATH=`hadoop classpath`flink目录下面
flink-sql-connector-hive-3.1.2_2.11-1.13.2.jar
hive-exec-3.1.2.jar
antlr-runtime-3.5.2.jar<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>1.13.2</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-bridge -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.13.2</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>在idea中开发的时候还得把这个hive-site.xml给放到里面去
3.2 案例
package com.wmy.flink.sql.flinksql.catalog.hive;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
/**
* @project_name: flinkDemo
* @package_name: com.wmy.flink.sql.flinksql.catalog.hive
* @Author: wmy
* @Date: 2021/10/10
* @Major: 数据科学与大数据技术
* @Post:大数据实时开发
* @Email:wmy_2000@163.com
* @Desription: flink 连接hive第一个案例
* @Version: wmy-version-01
*/
public class Flink_Hive_Catalog_Demo01 {
public static void main(String[] args) {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建HiveCatalog
HiveCatalog hiveCatalog = new HiveCatalog("myHive", "wmy", "src/main/resources/");
//3.注册HiveCatalog
tableEnv.registerCatalog("myHive", hiveCatalog);
//4.使用HiveCatalog
tableEnv.useCatalog("myHive");
//5.执行查询,查询Hive中已经存在的表数据
tableEnv.executeSql("select * from t_access").print();
}
}4、Flink-Hive理论
4.1 Flink-Hive介绍
在Flink 1.11
版本中,社区新增了一大功能是实时数仓,可以通过kafka
,将kafka sink
端的数据实时写入到Hive
中。
为实现这个功能、Flink1.11
版本主要做了以下改变:
将 FlieSystemStreaming Sink 重新修改,增加了分区提交和滚动策略机制。
让HiveStreaming sink 重新使用文件系统流作为接收器。
可以通过Flink社区,查看FLIP-85 Filesystem connector in Table
的设计思路。
4.2 Flink-Hive集成原理
Flink与Hive集成原理图如下:
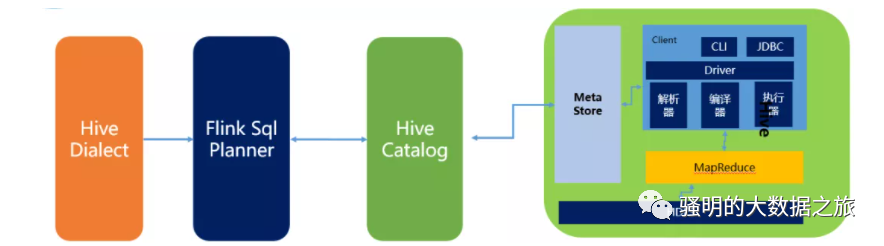
主要包含三部分内容:
HiveDialect。
Flink1.1
新引入了Hive
方言,所以在Flink SQL中可以编写HIve语法,即Hive Dialect。编写HIve SQL后,
FlinkSQL Planner
会将SQL
进行解析,验证,转换成逻辑计划,物理计划,最终变成Jobgraph
。HiveCatalog。
HiveCatalog
作为Flink
和Hive
的持久化介质,会将不同会话的Flink
元数据存储到Hive Metastore
中。
4.3 Flink-Hive版本支持
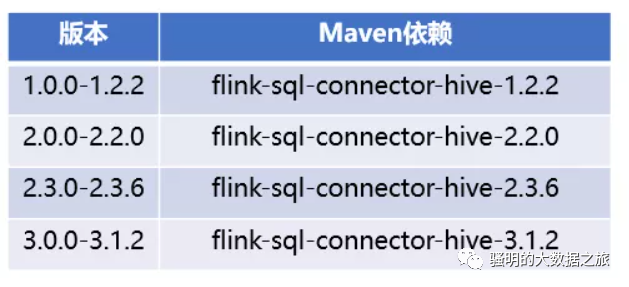
Flink目前支持Hive的1.x、2.x、3.x,每个大的版本对于的Flink依赖如下:
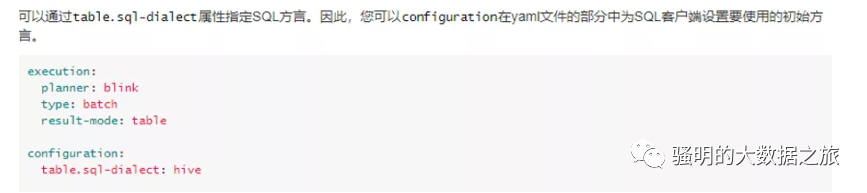
4.4 Flink SQL支持Hive语言
Flink SQL支持两种SQL语言,分别为default
和hive
。
配置方式也包含两种,配置如下图所示:
通过客户端配置。
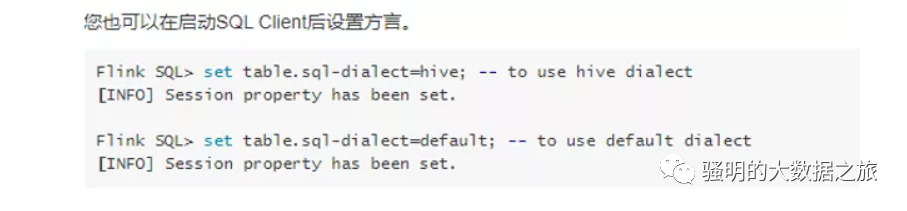
通过SQL配置。
5、kafka-Flink-Hive 集群配置
需求:实时将kafka中的数据通过flink Sql 计算 存储到hive数据仓库中。
5.1集群部署
配置信息如下:
Hadoop: hadoop3.1.4
Kafka: kafka_2.11-2.4.0
Flink: flink1.13.2
Hive: hive-3.1.2-bin
Zookeeper: zookeeper-3.5.7
5.2 查询结果要求
希望Flink Sql 查询kafka输入的数据的表结构如下:
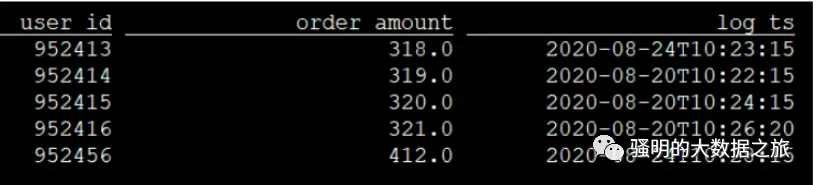
希望FlinkSQL实时将kafka中的数据插入Hive 查询的结果根据分区查询如下:

5.3 测试数据
{"user_id": "1", "order_amount":"124.5", "log_ts": "2020-08-24 10:20:15"}
{"user_id": "2", "order_amount":"38.4", "log_ts": "2020-08-24 11:20:15"}
{"user_id": "3", "order_amount":"176.9", "log_ts": "2020-08-25 13:20:15"}
{"user_id": "4", "order_amount":"302", "log_ts": "2020-08-25 14:20:15"}
{"user_id": "5", "order_amount":"124.5", "log_ts": "2020-08-26 14:26:15"}
{"user_id": "6", "order_amount":"38.4", "log_ts": "2020-08-26 15:20:15"}
{"user_id": "7", "order_amount":"176.9", "log_ts": "2020-08-27 16:20:15"}
{"user_id": "8", "order_amount":"302", "log_ts": "2020-08-27 17:20:15"}
{"user_id": "9", "order_amount":"124.5", "log_ts": "2020-08-24 10:20:15"}
{"user_id": "10", "order_amount":"124.6", "log_ts": "2020-08-24 10:21:15"}
{"user_id": "11", "order_amount":"124.7", "log_ts": "2020-08-24 10:22:15"}
{"user_id": "12", "order_amount":"124.8", "log_ts": "2020-08-24 10:23:15"}
{"user_id": "13", "order_amount":"124.9", "log_ts": "2020-08-24 10:24:15"}
{"user_id": "14", "order_amount":"125.5", "log_ts": "2020-08-24 10:25:15"}
{"user_id": "15", "order_amount":"126.5", "log_ts": "2020-08-24 10:26:15"}5.4 Hive集成Flink
hive安装 修改hive-env.sh
export HADOOP_HEAPSIZE=1024
export HADOOP_HOME=/opt/bigdata/platform/hadoop-3.1.3
export HIVE_CONF_DIR=/opt/bigdata/platform/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/opt/bigdata/platform/hive-3.1.2/lib由于hive的文件本身就在hdfs中保存的,所以需要指定Hadoop_Home的路径,同时指定配置文件路径和依赖包的路径。
5.5 hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://dm:3306/wmyHive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 这是连接hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>flink01</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://flink01:9820/spark-jars/*</value>
</property>
<!--Hive执行引擎 spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>1000000ms</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://flink01:9083</value>
</property>
</configuration>添加Flink与Hadoop的依赖 在flink-conf.yaml 中添加hadoop依赖.
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/config/
env.hadoop.conf.dir: opt/bigdata/platform/hadoop-3.1.3/etc/hadoop
env.hadoop.home.dir: /opt/bigdata/platform/hadoop-3.1.3flink1.13集成hive3.1.2还是有区别的,目前还是不太建议使用这种方式,现在目前流行的都是Flink Table API的方式来进行开发,目前这个社区正在弄,还是不太稳定。
欢迎大家关注我的公众号,我每天都会按时分享当天的学习心得,希望各位大佬能够多多带带我一起学习。
