




UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,其目的,是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其它人冲突的UUID。第一个通用唯一标识符是在网络计算机系统(NCS)中创建,并且随后成为开放软件基金会(OSF)的分布式计算环境(DCE)的组件。
组成
UUID 是一个 128 bit 的数字,我们通常见到的是它的32位16进制版本,表示为用连字符连接的5组数字:8-4-4-4-12,总共32个字母数字和4个连字符。
例如:7987bf11-078d-40fe-8191-7b41eab37f5a
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
其中的 M 表示 UUID version,N 留给不同的变体版本标志。
版本
Version 1 (date-time and MAC address)
version 1 UUID 由网卡的 mac 地址,60位时间戳,14位的防重复码和一些位数运算得出,它可以保证产生的 UUID 的全球唯一性,同时这也意味着可以根据 UUID 反溯生成它的节点地址信息,造成隐私泄露,而对于没有网卡的应用环境,也必须产生相应的随机数来代替 mac 地址,这些都是选择时需要考虑的因素。
严格来说即使 version 1 UUID 也有可能会产生碰撞的情况,如MAC 地址重复;同一台机器上两个UUID生成器在同一时间(小于10^-21s内)生成 UUID;没有mac地址时,两个生成器生成相同的随机数,并同时生成 UUID。
Version 2 (date-time and MAC address, DCE security version)
version 2 UUID 出现在 DCE 1.1 Authentication and Security Services specification 里,组成和 version 1 保持一致,只是加入了40位域信息用于安全认证(用户、组、使用域等等),时间戳减少到了28位,这样也导致了version 2 UUID 可能产生碰撞的时间单位变成了秒级,所以它不适合用在基于同一个 node/domain/identifier 而且产生 UUID 速率大于7秒一个的场景。
Versions 3 and 5 (namespace name-based)
Version 3 and 5 UUID 通过 hash 算法编码一个已有并且唯一的 namespace 标志和名称(如URL,域名,对象标识符,UUID等)来生成新的 UUID, version 3 使用 MD5 算法, version 5 使用 SHA1,这样对于 version 3 和 5 来说,同样的 namespace 和 name 组合总能找到同一个 UUID,反过来却不行。
在给定 namespace 的情况下,version 3 和 5 的碰撞几率就取决于它们使用的 hash 算法碰撞概率,从这点上来说 SHA1 要比 MD5 安全性更高,但是由于最后生成的散列值都要截取到 UUID 的128 位长度,再替换掉固定位置的 4 位版本号和 2 位变体标志,实际只有 122 位用来保证 UUID 的唯一性。
Version 4 (random)
version 4 UUID 除了 4 位版本号和 2 位变体标志以外,其他的 122 位都是随机生成,理论上可以生成 2^122 ≈ 5.3x10^36 个 唯一的 UUID,实际可以产生的数量还需要考虑随机函数的影响。
碰撞几率
以 version 4 为例,利用生日悖论,可计算出两个UUID拥有相同值的机率约为:
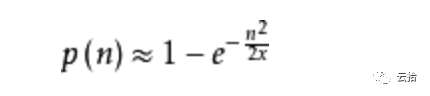
以 x = 2^122 计算出 n 个UUID后产生碰撞的机率:
| n | 机率 |
| 68,719,476,736 = 2^36 | 0.0000000000000004 (4 x 10^-16) |
| 2,199,023,255,552 = 2^41 | 0.0000000000004 (4 x 10^-13) |
| 70,368,744,177,664 = 2^46 | 0.0000000004 (4 x 10^-10) |
与被陨石击中的机率比较的话,一个人每年被陨石击中的机率估计为170亿分之1,机率大约是0.00000000006 (6 x 10^-11),换算成 UUID 的话,得连续生成 2^44 ≈ 1.76 x 10^13 个UUID ,才会得到有可能被陨石砸中的机会。
如果想要达到 50% 的碰撞几率,要产生的 UUID 数量大约为:
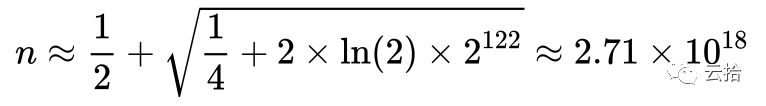
相当于每秒产生10亿个 UUID,连续运行85年。以一个 UUID 16 byte 算,加起来超过 45 exabytes,已经远远超过了数据库最大 百PB 级的容量,对大多数系统来说完全可以放心使用了。
在日渐复杂的计算机系统中,任何事物都不是单独存在的,只有结合业务和场景深入分析,才可能得到离真实最近的答案。
