




在介绍C++ Actor Framework(CAF):
https://github.com/actor-framework/actor-framework
之前需要先对actor mode的一些概念做一个简单的介绍。
什么是actor mode
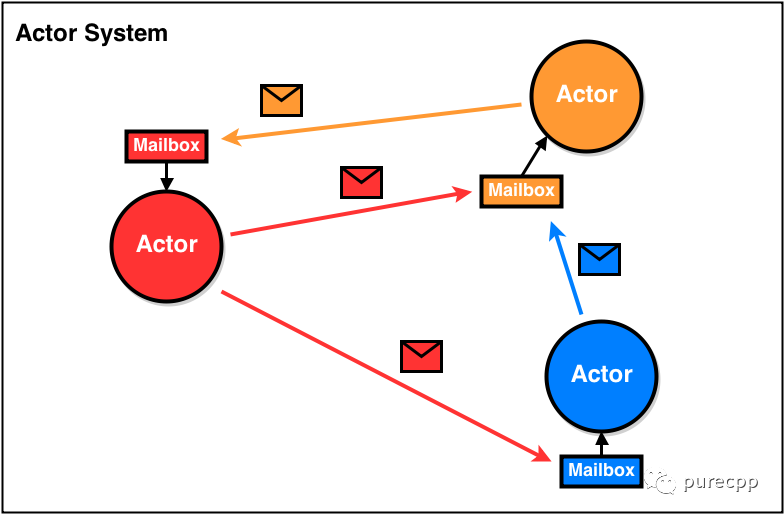
actor是基本的计算单元,它接收一条消息并基于它进行计算。每个actor有自己的信箱(mailbox),actor之间通过发消息通信,避免了并发多线程操作。
CAF的一点历史
CAF第一个版本于2012年,至今仍然在发展当中,该库作者曾经希望CAF能作为boost.actor进入boost库,可惜boost社区对其不感兴趣,后来CAF独立发展。
CAF中的actor
CAF中的actor和actor模型是对应的,它是一个基本的计算单元,具体来说是一个函数或者一个类。
作为函数的actor
behavior adder() {return {[](int x, int y) {return x + y;},[](double x, double y) {return x + y;}};}
在CAF中返回类型为behavior的函数就是一个函数式actor。
作为类的actor
class calculator : public event_based_actor {public:calculator(actor_config& cfg) : event_based_actor(cfg) {// nop}behavior make_behavior() override {return {[](int x, int y) {return x + y;},[](double x, double y) {return x + y;}};}};
重写了make_behavior的类就是一个类类型的actor。
dynamic actor和static actor
behavior dynamic_actor_func() {return {[](int x, int y) {return x + y;}};}using calculator_actor= typed_actor<result<int32_t>(int32_t, int32_t)>;calculator_actor::behavior_type typed_calculator_fun() {return {[](int32_t a, int32_t b) { return a + b; }};}
static typed actor和动态actor的差别在于它可以做编译期类型检查。
进程内actor之间通信
behavior adder() {return {[](int x, int y) {return x + y;},[](double x, double y) {return x + y;}};}int main() {actor_system_config cfg;actor_system sys{cfg};// Create (spawn) our actor.auto a = sys.spawn(adder);// Send it a message.scoped_actor self{sys};self->send(a, 40, 2);// Block and wait for reply.self->receive([](int result) {cout << result << endl; // prints “42”});}
actor_system spawn创建了一个actor,后面调用send方法向actor发消息,recieve则打印actor执行的结果, scoped_actor保证出了作用域之后释放actor。上面的例子是阻塞执行的,因为receive是同步阻塞的,非阻塞执行:
auto a = sys.spawn(adder);sys.spawn([=](event_based_actor* self) -> behavior {self->send(a, 40, 2);return {[=](int result) {cout << result << endl;self->quit();}};});
另外一种非阻塞调用的方式是使用request-then链式调用的api:
auto a = sys.spawn(adder);sys.spawn([=](event_based_actor* self) {self->request(a, seconds(1), 40, 2).then([=](int result) {cout << result << endl;self->quit();}};});
进程间actor通信
server
int main(int argc, char** argv) {// Defaults.auto host = "localhost"s;auto port = uint16_t{42000};auto server = false;actor_system sys{...}; // Parse command line and setup actor system.auto& middleman = sys.middleman();actor a;a = sys.spawn(adder);auto bound = middleman.publish(a, port);if (bound == 0)return 1;}
client
int main(int argc, char** argv) {// Defaults.auto host = "localhost"s;auto port = uint16_t{42000};auto server = false;actor_system sys{...}; // Parse command line and setup actor system.auto& middleman = sys.middleman();actor a;auto r = middleman.remote_actor(host, port);if (!r)return 1;a = *r;sys.spawn([=](event_based_actor* self) {self->request(a, seconds(1), 40, 2).then([=](int result) {cout << result << endl;self->quit();}};);}
caf通过middleman去创建server/client actor,publish接口监听一个端口,middleman.remote_actor则通过ip和端口去连接,返回actor,后面actor通信和之前进程内actor通信一样。
caf线程模型
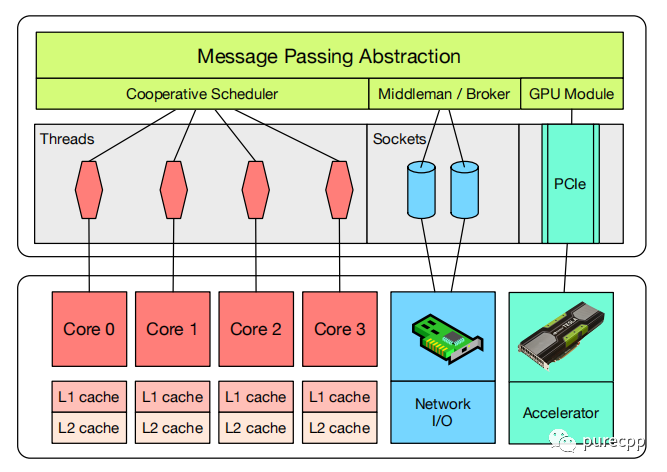
caf actor_system初始化时会根据核数创建对应的worker,每个worker一个线程和一个队列,创建的actor会放到队列中,线程去消费队列,每个线程先消费自己的队列,当队列为空时会做work steal去消费其他线程的队列的actor。

caf消息模型
caf内置了大量的基础类型,在初始化的时候会去注册这些类型,以便actor处理消息的时候做序列化/反序列化。对于自定义消息则需要通过几个宏去定义并添加到caf的类型系统中,这里稍显麻烦。
定义custom消息类型
// --(rst-type-id-block-begin)--struct foo;struct foo2;CAF_BEGIN_TYPE_ID_BLOCK(custom_types_1, first_custom_type_id)CAF_ADD_TYPE_ID(custom_types_1, (foo))CAF_ADD_TYPE_ID(custom_types_1, (foo2))CAF_ADD_TYPE_ID(custom_types_1, (std::pair<int32_t, int32_t>) )CAF_END_TYPE_ID_BLOCK(custom_types_1)// --(rst-type-id-block-end)--
先定义了一个父类型custom_types_1,在它下面添加一个或多个具体的消息类型。自定义类型由父类型和子类型组成,允许定义多个具体的消息子类型,父类型用于类型注册用。
在main中注册自定义消息(不注册会编译不过或crash)
caf::exec_main_init_meta_objects<custom_types_1>();
发送指针
如果要向多个actor发送一个长消息的时候可以发送caf的智能指针避免消息的拷贝。
auto heavy = vector<char>(1024 * 1024);auto msg = make_message(move(heavy));for (auto& r : receivers)self->send(r, msg);
这里通过make_message创建了一个msg的智能指针(caf内部实现了引用计数)。
copy-on-write
caf提供了消息的copy-on-write机制,语义就是在需要修改消息内容的时候才copy,caf是怎么实现copy on write的呢?
caf的copy on write有两个条件:
消息的引用计数大于1
以非常量引用方式从msg中取值
为什么是这两个条件呢,因为引用计数大于一表明其他actor也在引用这个消息,只有在有多个对象引用该消息时copy才有意义,没有其它对象引用则永远不需要copy了。另外以非常量引用从msg中取值的时候表明用户的意图是想修改数据,这时候就需要copy了。当然你也可以认为这是caf的一个约定,也许用户不小心漏掉了const那就会自动copy了,这也算是copy on write的一个坑。
那么caf具体是怎么实现copy on write的呢?
auto heavy = vector<char>(1024 * 1024);auto msg = make_message(move(heavy));for (auto& r : receivers)self->send(r, msg);behavior reader() {return {[=](const vector<char>& buf) {f(buf);}};}//copy on writebehavior writer() {return {[=](vector<char>& buf) {f(buf);}};}
caf会先判断actor参数是否为非常量引用类型,如果是非常量引用类型就会构造一个非常量引用的msg view,反之则会创建一个const msg view,当解析发送的消息时会调用对应的msg view构造函数,非常量引用的msg view则会调用msg的ptr()函数,在该函数中做copy,如果是const msg view则不会做copy。
///message.hppdetail::message_data* ptr() noexcept {return data_.unshared_ptr();}/// @privateconst detail::message_data* ptr() const noexcept {return data_.get();}/// intrusive_cow_ptr.hpp/// Returns a mutable pointer to the managed object.pointer unshared_ptr() {return intrusive_cow_ptr_unshare(ptr_.ptr_);}template <class T>T* default_intrusive_cow_ptr_unshare(T*& ptr) {if (!ptr->unique()) {auto new_ptr = ptr->copy();intrusive_ptr_release(ptr);ptr = new_ptr;}return ptr;}
总结
caf通过behavior定义actor,actor systm可以创建大量的actor放到线程的队列中,通过worksteal提升actor的处理效率;actor通过发消息避免了并发的竞争,actor之间发送消息支持copy on write。节点间的actor通过middleman来发消息,需要监听端口和显式ip,port去连接。
caf在进程内之间发消息处理得比较好(支持worker steal,copy-on-write),但是在分布式方面比较弱,如:的分布式actor目前没有处理actor计算调度,也没有处理fail over,这些需要上层应用去处理。
本文对caf做了一个简要的介绍,如果希望更深入去了解这个框架可以查看caf的源码。
后续还会介绍另外一个知名的c++ 分布式计算框架:ray,也会将ray和caf做一些对比。
