排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
Python高性能空间数据计算包:PyGEOS(1):对比
Python高性能空间数据计算包:PyGEOS(1):对比
虾神说D
2021-01-27
419
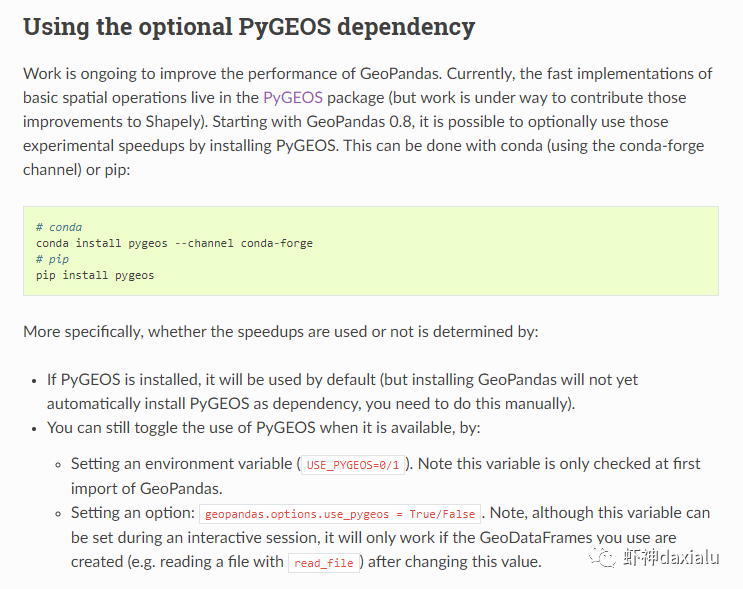
今天早上在查阅
GeoPandas
文档的时候,发现从
0.8版本
开始,多了一个新特性:可以在GeoPandas进行空间运算的时候,选用
PyGEOS
包来实现了。
算法渣渣虾看见这个选项的时候,当时的表情那是:
好吧,有同学不知道为什么虾神会如此惊讶,因为这个库实在是太流弊了……今天我们就来介绍一下这个神奇的
高性能空间数据计算包
:
PyGEOS
话说,对速度的追求,是人类的本能:当然,你可以追求更快,
自然也可以追求更慢
……
但是在对数据进行计算的时候,无疑我们是追求更高更快更强的……而这个包,敢叫做“高性能”,自然有它的两把刷子。
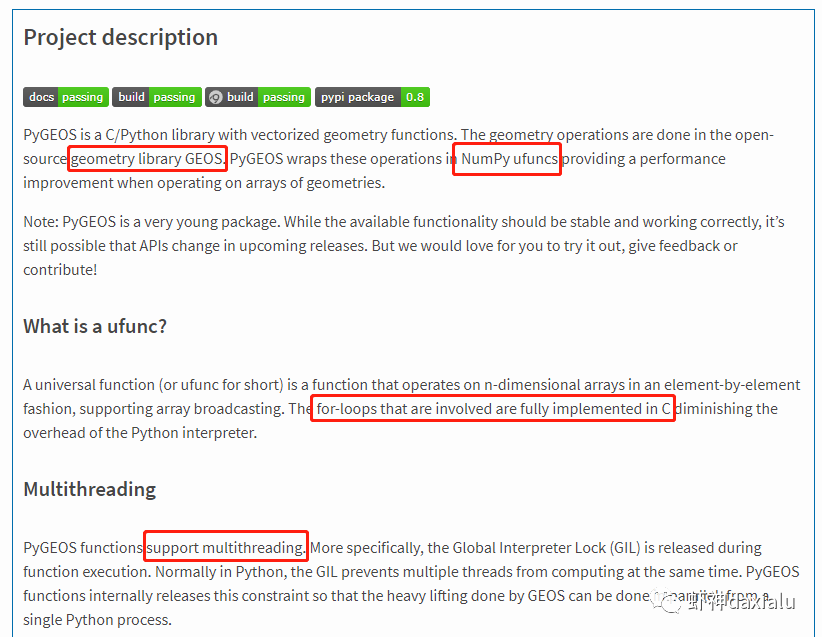
我们先来看看官方文档对它的描述:
虾神大白话解释如下(英文好的同学自行去读官方文档):
第一点
,PyGEOS这个包,底层的计算,用的
GEOS
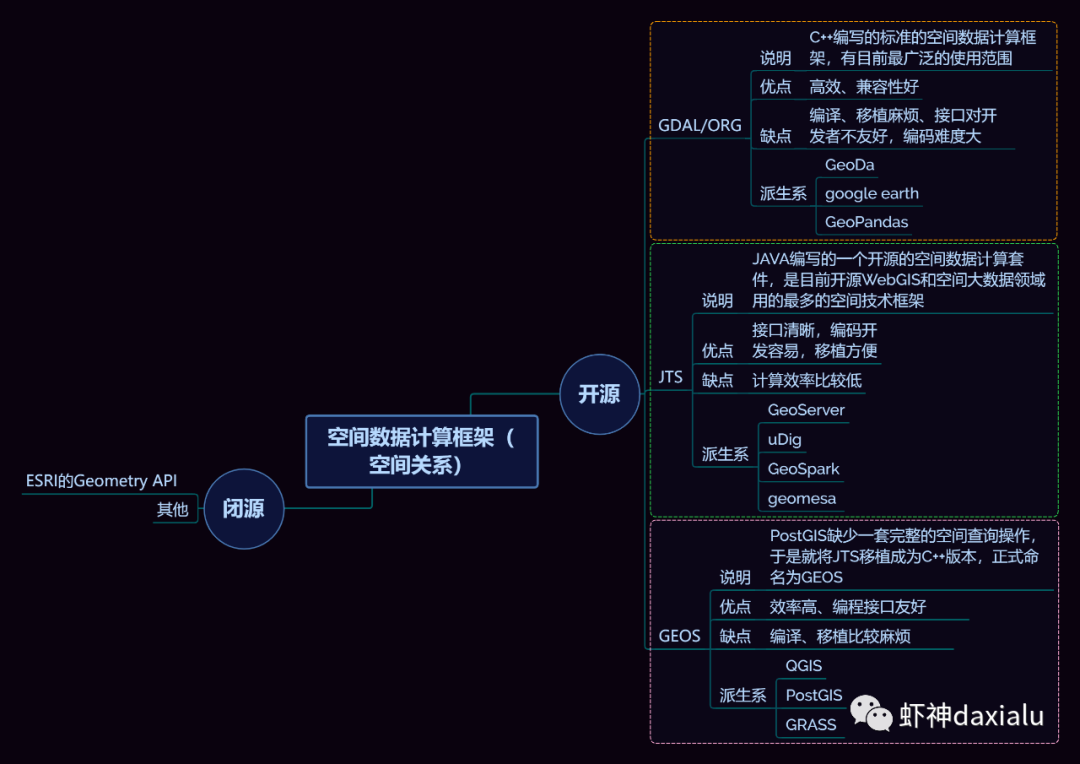
的空间关系来进行计算,好吧,我知道有同学继续会问,啥是GEOS呢?这个说来就话长了,看下面这张图:
闭源的先不看,主要看开源的部分,通常说的就是C/C++写的速度快,但是对于码农来说很不友好,反之JAVA写的,对码农友好,但是速度效率又不咋地……
所以,综合了二者的优点以及缺点之和,就出现Geos这个东西……它有着C++底层的运行速度,但是在API保留了JAVA编码友好的特点——but,二者的缺点也一并保留了。目前用
GEOS比较出名GIS软件,就是QGIS平台。
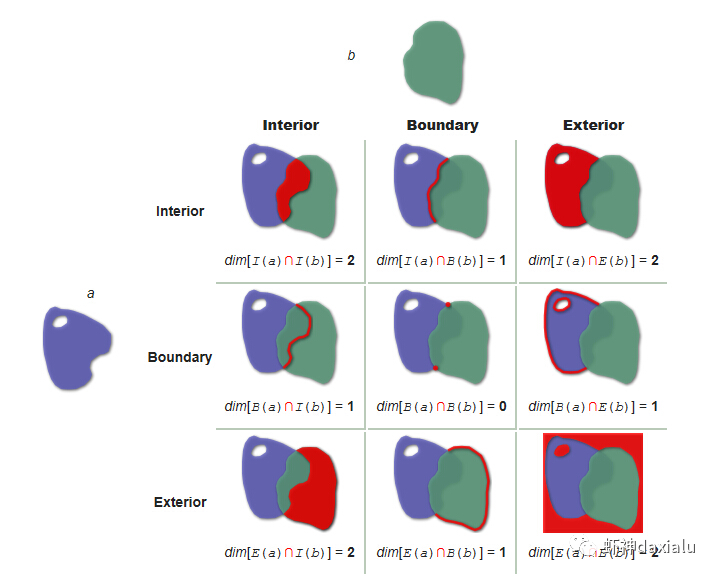
GEOS搞出了空间关系计算里面最出名的入门图
DE-9IM
(Dimensionally Extended nine-Intersection Model (DE-9IM),用于描述两个几何图形空间关系:
——言归正传,回到PyGeos。
因为PyGEOS底层用的是GEOS,所以它具备了空间计算的各种基本以及标准的功能。
第二点
,PyGEOS计算操作,利用的是numpy的
ufunc模式
进行编码——所谓的ufunc模式,是一种在n维数组上,以逐个元素处理的方式运行的函数,支持数组广播(广播是指 NumPy 在算术运算期间处理不同形状的数组的能力)。它的机制是使用
C语言
对底层
for循环进行了重写
,从而减少了Python解释器的开销。
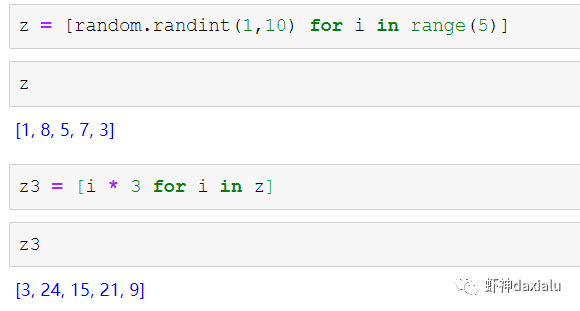
举个例子:传统的迭代计算,比如我这有一个5个元素组成的数组,要把每个元素扩大3倍,正常的代码写法应该是通过for循环,一个个元素来处理:
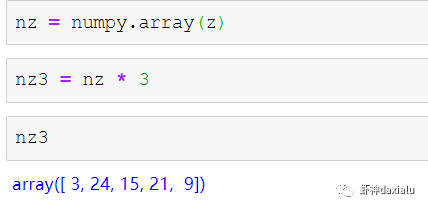
但是在Numpy里面,直接用ufunc方式来实现,直接在数组上乘以3,得到的结果是每个元素依此乘以3了:
numpy的速度之所以比传统Python数组快那么多,有个核心原理就是他的ufunc,采用的是C重写了底层,不需要在Python那个蜗牛一样的
解释器
里面去运行,而
PyGEOS
也用了这个原理,来实现快速计算。
第三点
就是
PyGEOS
支持多线程
。原理就是它在函数执行期间主动干掉了GIL(Global Interpreter Lock :全局解释器锁定)。
GIL这个东东是C语言里面的一个特性,而我们的CPython天生就带着这个东西出现了(相对的Jython就么有GIL),它主要的作用就是一个全局排他锁,主要是防止多线程并发执行机器码(C语言官方的解释是为了
解决线程间数据一致性和状态同步的困难
,而解决思路很粗暴:特么我加一把锁
锁起来
,你们之间就
无法同步了
,自己跑自己的进程完事——完美解决)。
而在 PyGeos中,因为用的是C语言重新写的底层,所以在底层函数在
内部释放了此约束
,带来的结果就是通过单个Python进程就可以并行完成GEOS计算的任务。
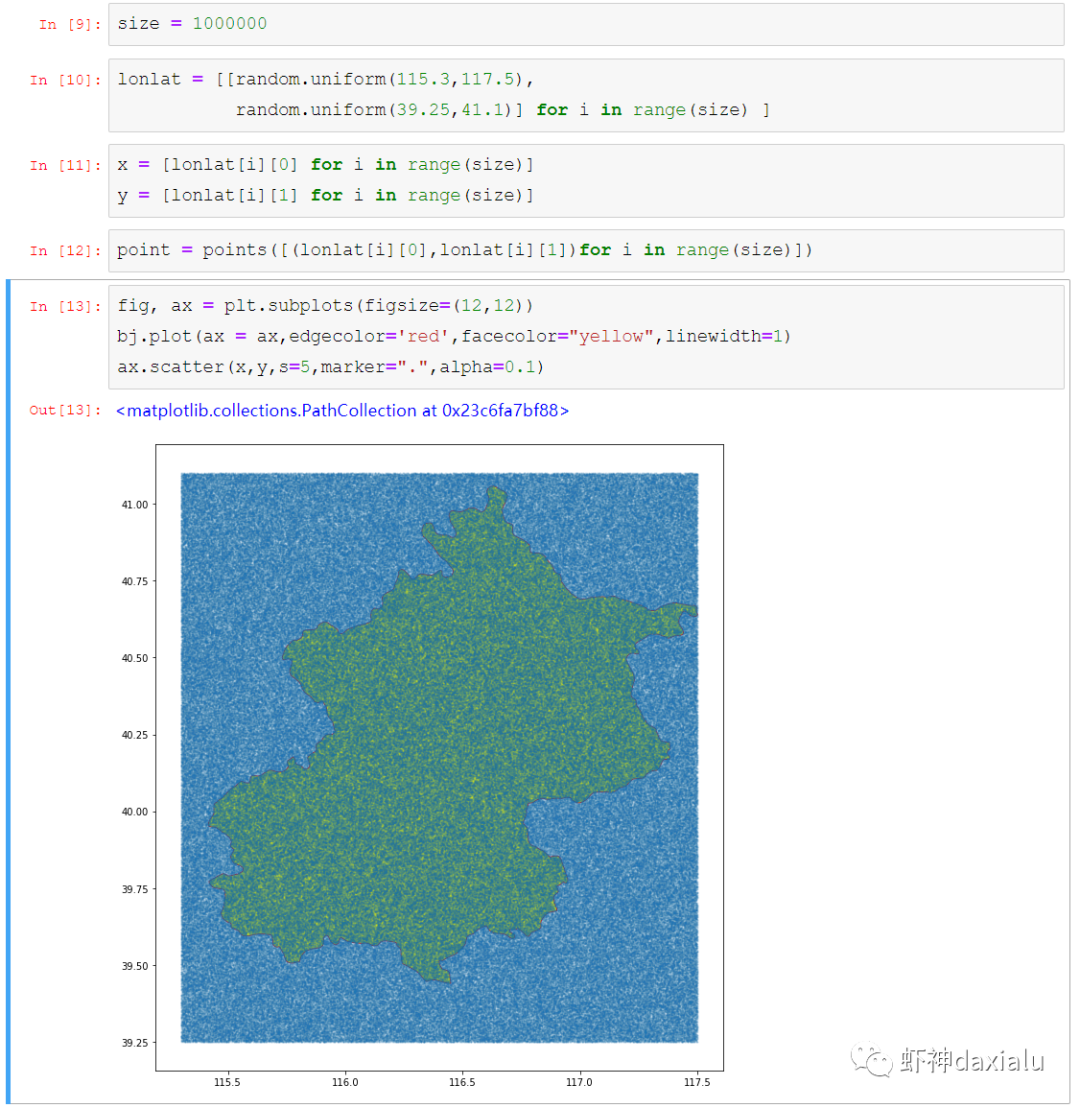
下面我们来看看PyGEOS的车速到底有多快:
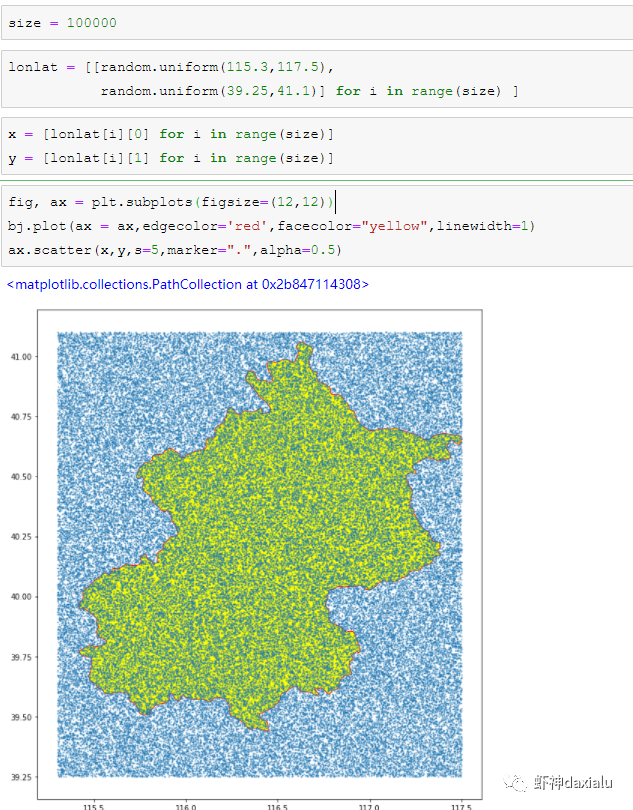
首先,以北京周边为范围,生成了
10万
个随机点:
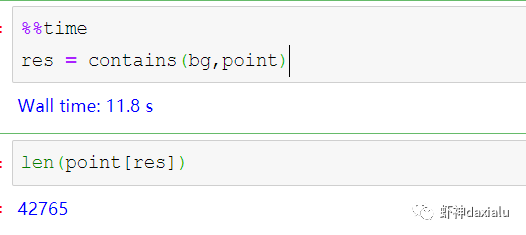
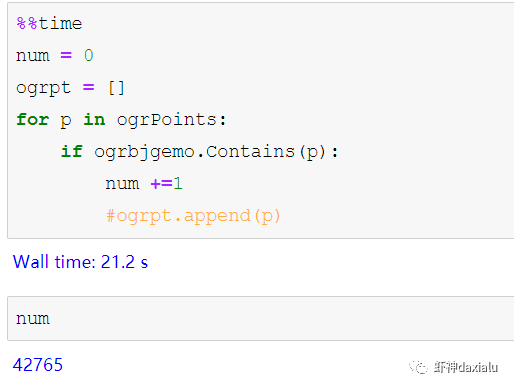
然后我们分别用PyGEOS和GDAL迭代的方式,来进行一个包含查询:
恩,花了
11秒
,查出来了42765个——好像不怎么快嘛。
接下去,我们用GDAL/OGR的方式来做一下:
在
OGR
下面,用了差不多要
比PyGEOS多用2倍
的时间!!效果卓然拔群!
恩,Python本来就比较慢……这个是共识,但是这才10万个点,就算快也得11秒,那也
太慢
了……还有快点的方法么?
做为程序员,当然不能说有问题:
下面我们来看,空间数据计算加速的主要方法之一:空间索引——
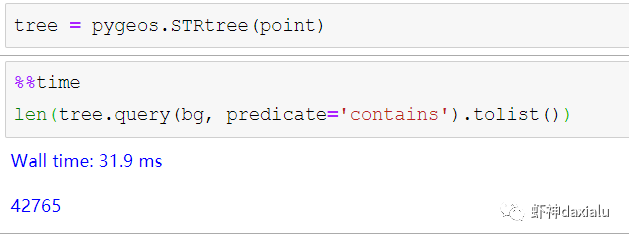
PyGEOS的空间索引能力:
——见证奇迹的时刻:
只用了39ms!
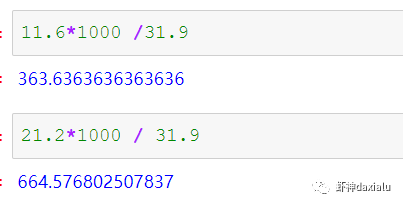
比自身直接查询快了363倍,而比用GDAL/OGR迭代快了664倍。
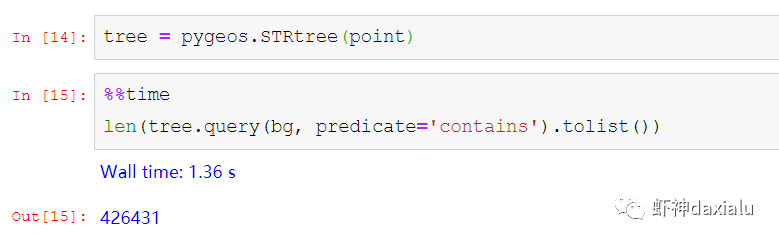
我们来弄个大点的数据,比如
100万
个点:
完成了
100万点
的包含查询,查询出来了42万6431条数据,耗时为
1.36秒
(好吧,我觉得有这个速度已经很快,但是还有同学说有些慢,因为我们在这里不是对标以快为标准的数据库——如果是
空间数据库
,千万点级别的查询,可以控制在
零点几秒
以内……这个我们就不对标了——别忘记了,我们这是在以慢出名的Python里面)
本节打完收工,下一节我们看看在GeoPandas里面怎么用PyGEOS
python
文章转载自
虾神说D
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨