




1、BitMap学习
1.1 BitMap
Bit-map的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。(PS:划重点 节省存储空间)
假设有这样一个需求:在20亿个随机整数中找出某个数m是否存在其中,并假设32位操作系统,4G内存
在Java中,int占4字节,1字节=8位(1 byte = 8 bit)
如果每个数字用int存储,那就是20亿个int,因而占用的空间约为 (2000000000*4/1024/1024/1024)≈7.45G
如果按位存储就不一样了,20亿个数就是20亿位,占用空间约为 (2000000000/8/1024/1024/1024)≈0.233G
高下立判,无需多言,那么,问题来了,如何表示一个数呢?
刚才说了,每一位表示一个数,0表示不存在,1表示存在,这正符合二进制这样我们可以很容易表示{1,2,4,6}这几个数:

计算机内存分配的最小单位是字节,也就是8位,那如果要表示{12,13,15}怎么办呢?
当然是在另一个8位上表示了:
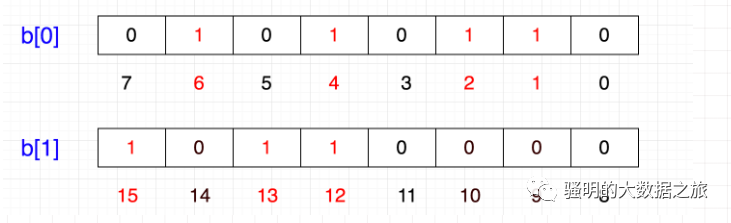
这样的话,好像变成一个二维数组了
1个int占32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32] 即可存储,其中N表示要存储的这些数中的最大值,于是乎:
tmp[0]:可以表示0~31
tmp[1]:可以表示32~63
tmp[2]:可以表示64~95
。。。
如此一来,给定任意整数M,那么M/32就得到下标,M%32就知道它在此下标的哪个位置
添加
这里有个问题,我们怎么把一个数放进去呢?例如,想把5这个数字放进去,怎么做呢?
首先,5/32=0,5%32=5,也是说它应该在tmp[0]的第5个位置,那我们把1向左移动5位,然后按位或
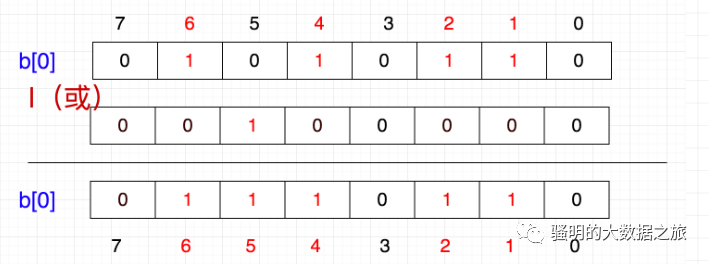
换成二进制就是

这就相当于 86 | 32 = 118
86 | (1<<5) = 118
b[0] = b[0] | (1<<5)
也就是说,要想插入一个数,将1左移带代表该数字的那一位,然后与原数进行按位或操作
化简一下,就是 86 + (5/8) | (1<<(5%8))
因此,公式可以概括为:p + (i/8)|(1<<(i%8)) 其中,p表示现在的值,i表示待插入的数
清除
以上是添加,那如果要清除该怎么做呢?
还是上面的例子,假设我们要6移除,该怎么做呢?
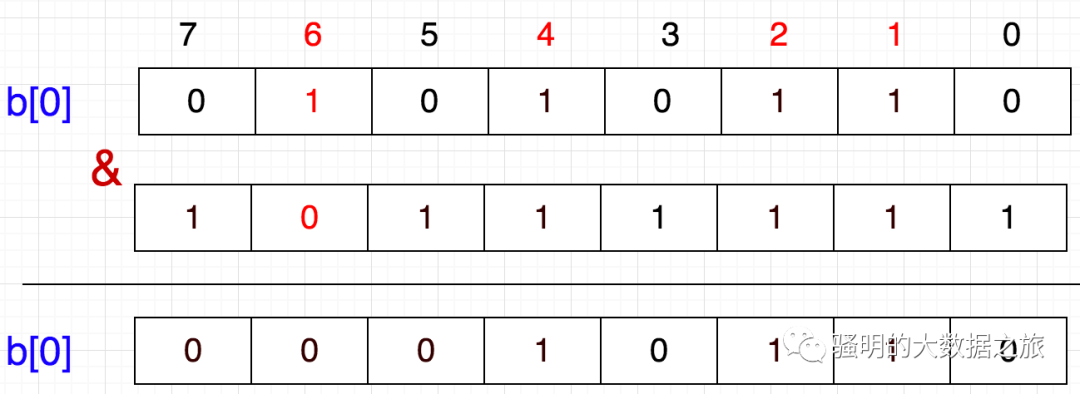
从图上看,只需将该数所在的位置为0即可
1左移6位,就到达6这个数字所代表的位,然后按位取反,最后与原数按位与,这样就把该位置为0了
b[0] = b[0] & (~(1<<6))
b[0] = b[0] & (~(1<<(i%8)))
查找
前面我们也说了,每一位代表一个数字,1表示有(或者说存在),0表示无(或者说不存在)。通过把该为置为1或者0来达到添加和清除的小伙,那么判断一个数存不存在就是判断该数所在的位是0还是1
假设,我们想知道3在不在,那么只需判断 b[0] & (1<<3) 如果这个值是0,则不存在,如果是1,就表示存在
1.1 Bitmap有什么用
大量数据的快速排序、查找、去重
快速排序
假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复),我们就可以采用Bit-map的方法来达到排序的目的。
要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,然后将对应位置为1。
最后,遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的,时间复杂度O(n)。
优点:
运算效率高,不需要进行比较和移位;
占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
只有当数据比较密集时才有优势
快速去重
20亿个整数中找出不重复的整数的个数,内存不足以容纳这20亿个整数。
首先,根据“内存空间不足以容纳这05亿个整数”我们可以快速的联想到Bit-map。下边关键的问题就是怎么设计我们的Bit-map来表示这20亿个数字的状态了。其实这个问题很简单,一个数字的状态只有三种,分别为不存在,只有一个,有重复。因此,我们只需要2bits就可以对一个数字的状态进行存储了,假设我们设定一个数字不存在为00,存在一次01,存在两次及其以上为11。那我们大概需要存储空间2G左右。
接下来的任务就是把这20亿个数字放进去(存储),如果对应的状态位为00,则将其变为01,表示存在一次;如果对应的状态位为01,则将其变为11,表示已经有一个了,即出现多次;如果为11,则对应的状态位保持不变,仍表示出现多次。
最后,统计状态位为01的个数,就得到了不重复的数字个数,时间复杂度为O(n)。
快速查找
这就是我们前面所说的了,int数组中的一个元素是4字节占32位,那么除以32就知道元素的下标,对32求余数(%32)就知道它在哪一位,如果该位是1,则表示存在。
小结&回顾
Bitmap主要用于快速检索关键字状态,通常要求关键字是一个连续的序列(或者关键字是一个连续序列中的大部分), 最基本的情况,使用1bit表示一个关键字的状态(可标示两种状态),但根据需要也可以使用2bit(表示4种状态),3bit(表示8种状态)。
Bitmap的主要应用场合:表示连续(或接近连续,即大部分会出现)的关键字序列的状态(状态数/关键字个数 越小越好)。
32位机器上,对于一个整型数,比如int a=1 在内存中占32bit位,这是为了方便计算机的运算。但是对于某些应用场景而言,这属于一种巨大的浪费,因为我们可以用对应的32bit位对应存储十进制的0-31个数,而这就是Bit-map的基本思想。Bit-map算法利用这种思想处理大量数据的排序、查询以及去重。
补充1
在数字没有溢出的前提下,对于正数和负数,左移一位都相当于乘以2的1次方,左移n位就相当于乘以2的n次方,右移一位相当于除2,右移n位相当于除以2的n次方。
<< 左移,相当于乘以2的n次方,例如:1<<6 相当于1×64=64,3<<4 相当于3×16=48
>> 右移,相当于除以2的n次方,例如:64>>3 相当于64÷8=8
^ 异或,相当于求余数,例如:48^32 相当于 48%32=16
补充2
不使用第三方变量,交换两个变量的值
// 方式一
a = a + b;
b = a - b;
a = a - b;
// 方式二
a = a ^ b;
b = a ^ b;
a = a ^ b;1.3 BitSet
BitSet实现了一个位向量,它可以根据需要增长。每一位都有一个布尔值。一个BitSet的位可以被非负整数索引(PS:意思就是每一位都可以表示一个非负整数)。可以查找、设置、清除某一位。通过逻辑运算符可以修改另一个BitSet的内容。默认情况下,所有的位都有一个默认值false。
package java.util;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.LongBuffer;
import java.util.stream.IntStream;
import java.util.stream.StreamSupport;
/**
* This class implements a vector of bits that grows as needed. Each
* component of the bit set has a {@code boolean} value. The
* bits of a {@code BitSet} are indexed by nonnegative integers.
* Individual indexed bits can be examined, set, or cleared. One
* {@code BitSet} may be used to modify the contents of another
* {@code BitSet} through logical AND, logical inclusive OR, and
* logical exclusive OR operations.
*
* <p>By default, all bits in the set initially have the value
* {@code false}.
*
* <p>Every bit set has a current size, which is the number of bits
* of space currently in use by the bit set. Note that the size is
* related to the implementation of a bit set, so it may change with
* implementation. The length of a bit set relates to logical length
* of a bit set and is defined independently of implementation.
*
* <p>Unless otherwise noted, passing a null parameter to any of the
* methods in a {@code BitSet} will result in a
* {@code NullPointerException}.
*
* <p>A {@code BitSet} is not safe for multithreaded use without
* external synchronization.
*
* @author Arthur van Hoff
* @author Michael McCloskey
* @author Martin Buchholz
* @since JDK1.0
*/
public class BitSet implements Cloneable, java.io.Serializable {
/*
* BitSets are packed into arrays of "words." Currently a word is
* a long, which consists of 64 bits, requiring 6 address bits.
* The choice of word size is determined purely by performance concerns.
*/
private final static int ADDRESS_BITS_PER_WORD = 6;
private final static int BITS_PER_WORD = 1 << ADDRESS_BITS_PER_WORD;
private final static int BIT_INDEX_MASK = BITS_PER_WORD - 1;
/* Used to shift left or right for a partial word mask */
private static final long WORD_MASK = 0xffffffffffffffffL;
/**
* @serialField bits long[]
*
* The bits in this BitSet. The ith bit is stored in bits[i/64] at
* bit position i % 64 (where bit position 0 refers to the least
* significant bit and 63 refers to the most significant bit).
*/
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("bits", long[].class),
};
/**
* The internal field corresponding to the serialField "bits".
*/
private long[] words;
/**
* The number of words in the logical size of this BitSet.
*/
private transient int wordsInUse = 0;
/**
* Whether the size of "words" is user-specified. If so, we assume
* the user knows what he's doing and try harder to preserve it.
*/
private transient boolean sizeIsSticky = false;
/* use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 7997698588986878753L;
/**
* Given a bit index, return word index containing it.
*/
private static int wordIndex(int bitIndex) {
return bitIndex >> ADDRESS_BITS_PER_WORD;
}
/**
* Every public method must preserve these invariants.
*/
private void checkInvariants() {
assert(wordsInUse == 0 || words[wordsInUse - 1] != 0);
assert(wordsInUse >= 0 && wordsInUse <= words.length);
assert(wordsInUse == words.length || words[wordsInUse] == 0);
}
/**
* Sets the field wordsInUse to the logical size in words of the bit set.
* WARNING:This method assumes that the number of words actually in use is
* less than or equal to the current value of wordsInUse!
*/
private void recalculateWordsInUse() {
// Traverse the bitset until a used word is found
int i;
for (i = wordsInUse-1; i >= 0; i--)
if (words[i] != 0)
break;
wordsInUse = i+1; // The new logical size
}
/**
* Creates a new bit set. All bits are initially {@code false}.
*/
public BitSet() {
initWords(BITS_PER_WORD);
sizeIsSticky = false;
}
/**
* Creates a bit set whose initial size is large enough to explicitly
* represent bits with indices in the range {@code 0} through
* {@code nbits-1}. All bits are initially {@code false}.
*
* @param nbits the initial size of the bit set
* @throws NegativeArraySizeException if the specified initial size
* is negative
*/
public BitSet(int nbits) {
// nbits can't be negative; size 0 is OK
if (nbits < 0)
throw new NegativeArraySizeException("nbits < 0: " + nbits);
initWords(nbits);
sizeIsSticky = true;
}
private void initWords(int nbits) {
words = new long[wordIndex(nbits-1) + 1];
}
/**
* Creates a bit set using words as the internal representation.
* The last word (if there is one) must be non-zero.
*/
private BitSet(long[] words) {
this.words = words;
this.wordsInUse = words.length;
checkInvariants();
}
/**
* Returns a new bit set containing all the bits in the given long array.
*
* <p>More precisely,
* <br>{@code BitSet.valueOf(longs).get(n) == ((longs[n/64] & (1L<<(n%64))) != 0)}
* <br>for all {@code n < 64 * longs.length}.
*
* <p>This method is equivalent to
* {@code BitSet.valueOf(LongBuffer.wrap(longs))}.
*
* @param longs a long array containing a little-endian representation
* of a sequence of bits to be used as the initial bits of the
* new bit set
* @return a {@code BitSet} containing all the bits in the long array
* @since 1.7
*/
public static BitSet valueOf(long[] longs) {
int n;
for (n = longs.length; n > 0 && longs[n - 1] == 0; n--)
;
return new BitSet(Arrays.copyOf(longs, n));
}
/**
* Returns a new bit set containing all the bits in the given long
* buffer between its position and limit.
*
* <p>More precisely,
* <br>{@code BitSet.valueOf(lb).get(n) == ((lb.get(lb.position()+n/64) & (1L<<(n%64))) != 0)}
* <br>for all {@code n < 64 * lb.remaining()}.
*
* <p>The long buffer is not modified by this method, and no
* reference to the buffer is retained by the bit set.
*
* @param lb a long buffer containing a little-endian representation
* of a sequence of bits between its position and limit, to be
* used as the initial bits of the new bit set
* @return a {@code BitSet} containing all the bits in the buffer in the
* specified range
* @since 1.7
*/
public static BitSet valueOf(LongBuffer lb) {
lb = lb.slice();
int n;
for (n = lb.remaining(); n > 0 && lb.get(n - 1) == 0; n--)
;
long[] words = new long[n];
lb.get(words);
return new BitSet(words);
}
/**
* Returns a new bit set containing all the bits in the given byte array.
*
* <p>More precisely,
* <br>{@code BitSet.valueOf(bytes).get(n) == ((bytes[n/8] & (1<<(n%8))) != 0)}
* <br>for all {@code n < 8 * bytes.length}.
*
* <p>This method is equivalent to
* {@code BitSet.valueOf(ByteBuffer.wrap(bytes))}.
*
* @param bytes a byte array containing a little-endian
* representation of a sequence of bits to be used as the
* initial bits of the new bit set
* @return a {@code BitSet} containing all the bits in the byte array
* @since 1.7
*/
public static BitSet valueOf(byte[] bytes) {
return BitSet.valueOf(ByteBuffer.wrap(bytes));
}
/**
* Returns a new bit set containing all the bits in the given byte
* buffer between its position and limit.
*
* <p>More precisely,
* <br>{@code BitSet.valueOf(bb).get(n) == ((bb.get(bb.position()+n/8) & (1<<(n%8))) != 0)}
* <br>for all {@code n < 8 * bb.remaining()}.
*
* <p>The byte buffer is not modified by this method, and no
* reference to the buffer is retained by the bit set.
*
* @param bb a byte buffer containing a little-endian representation
* of a sequence of bits between its position and limit, to be
* used as the initial bits of the new bit set
* @return a {@code BitSet} containing all the bits in the buffer in the
* specified range
* @since 1.7
*/
public static BitSet valueOf(ByteBuffer bb) {
bb = bb.slice().order(ByteOrder.LITTLE_ENDIAN);
int n;
for (n = bb.remaining(); n > 0 && bb.get(n - 1) == 0; n--)
;
long[] words = new long[(n + 7) / 8];
bb.limit(n);
int i = 0;
while (bb.remaining() >= 8)
words[i++] = bb.getLong();
for (int remaining = bb.remaining(), j = 0; j < remaining; j++)
words[i] |= (bb.get() & 0xffL) << (8 * j);
return new BitSet(words);
}
/**
* Returns a new byte array containing all the bits in this bit set.
*
* <p>More precisely, if
* <br>{@code byte[] bytes = s.toByteArray();}
* <br>then {@code bytes.length == (s.length()+7)/8} and
* <br>{@code s.get(n) == ((bytes[n/8] & (1<<(n%8))) != 0)}
* <br>for all {@code n < 8 * bytes.length}.
*
* @return a byte array containing a little-endian representation
* of all the bits in this bit set
* @since 1.7
*/
public byte[] toByteArray() {
int n = wordsInUse;
if (n == 0)
return new byte[0];
int len = 8 * (n-1);
for (long x = words[n - 1]; x != 0; x >>>= 8)
len++;
byte[] bytes = new byte[len];
ByteBuffer bb = ByteBuffer.wrap(bytes).order(ByteOrder.LITTLE_ENDIAN);
for (int i = 0; i < n - 1; i++)
bb.putLong(words[i]);
for (long x = words[n - 1]; x != 0; x >>>= 8)
bb.put((byte) (x & 0xff));
return bytes;
}
/**
* Returns a new long array containing all the bits in this bit set.
*
* <p>More precisely, if
* <br>{@code long[] longs = s.toLongArray();}
* <br>then {@code longs.length == (s.length()+63)/64} and
* <br>{@code s.get(n) == ((longs[n/64] & (1L<<(n%64))) != 0)}
* <br>for all {@code n < 64 * longs.length}.
*
* @return a long array containing a little-endian representation
* of all the bits in this bit set
* @since 1.7
*/
public long[] toLongArray() {
return Arrays.copyOf(words, wordsInUse);
}
/**
* Ensures that the BitSet can hold enough words.
* @param wordsRequired the minimum acceptable number of words.
*/
private void ensureCapacity(int wordsRequired) {
if (words.length < wordsRequired) {
// Allocate larger of doubled size or required size
int request = Math.max(2 * words.length, wordsRequired);
words = Arrays.copyOf(words, request);
sizeIsSticky = false;
}
}
/**
* Ensures that the BitSet can accommodate a given wordIndex,
* temporarily violating the invariants. The caller must
* restore the invariants before returning to the user,
* possibly using recalculateWordsInUse().
* @param wordIndex the index to be accommodated.
*/
private void expandTo(int wordIndex) {
int wordsRequired = wordIndex+1;
if (wordsInUse < wordsRequired) {
ensureCapacity(wordsRequired);
wordsInUse = wordsRequired;
}
}
/**
* Checks that fromIndex ... toIndex is a valid range of bit indices.
*/
private static void checkRange(int fromIndex, int toIndex) {
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);
if (toIndex < 0)
throw new IndexOutOfBoundsException("toIndex < 0: " + toIndex);
if (fromIndex > toIndex)
throw new IndexOutOfBoundsException("fromIndex: " + fromIndex +
" > toIndex: " + toIndex);
}
/**
* Sets the bit at the specified index to the complement of its
* current value.
*
* @param bitIndex the index of the bit to flip
* @throws IndexOutOfBoundsException if the specified index is negative
* @since 1.4
*/
public void flip(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] ^= (1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}
/**
* Sets each bit from the specified {@code fromIndex} (inclusive) to the
* specified {@code toIndex} (exclusive) to the complement of its current
* value.
*
* @param fromIndex index of the first bit to flip
* @param toIndex index after the last bit to flip
* @throws IndexOutOfBoundsException if {@code fromIndex} is negative,
* or {@code toIndex} is negative, or {@code fromIndex} is
* larger than {@code toIndex}
* @since 1.4
*/
public void flip(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
if (fromIndex == toIndex)
return;
int startWordIndex = wordIndex(fromIndex);
int endWordIndex = wordIndex(toIndex - 1);
expandTo(endWordIndex);
long firstWordMask = WORD_MASK << fromIndex;
long lastWordMask = WORD_MASK >>> -toIndex;
if (startWordIndex == endWordIndex) {
// Case 1: One word
words[startWordIndex] ^= (firstWordMask & lastWordMask);
} else {
// Case 2: Multiple words
// Handle first word
words[startWordIndex] ^= firstWordMask;
// Handle intermediate words, if any
for (int i = startWordIndex+1; i < endWordIndex; i++)
words[i] ^= WORD_MASK;
// Handle last word
words[endWordIndex] ^= lastWordMask;
}
recalculateWordsInUse();
checkInvariants();
}
/**
* Sets the bit at the specified index to {@code true}.
*
* @param bitIndex a bit index
* @throws IndexOutOfBoundsException if the specified index is negative
* @since JDK1.0
*/
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] |= (1L << bitIndex); // Restores invariants
checkInvariants();
}
/**
* Sets the bit at the specified index to the specified value.
*
* @param bitIndex a bit index
* @param value a boolean value to set
* @throws IndexOutOfBoundsException if the specified index is negative
* @since 1.4
*/
public void set(int bitIndex, boolean value) {
if (value)
set(bitIndex);
else
clear(bitIndex);
}
/**
* Sets the bits from the specified {@code fromIndex} (inclusive) to the
* specified {@code toIndex} (exclusive) to {@code true}.
*
* @param fromIndex index of the first bit to be set
* @param toIndex index after the last bit to be set
* @throws IndexOutOfBoundsException if {@code fromIndex} is negative,
* or {@code toIndex} is negative, or {@code fromIndex} is
* larger than {@code toIndex}
* @since 1.4
*/
public void set(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
if (fromIndex == toIndex)
return;
// Increase capacity if necessary
int startWordIndex = wordIndex(fromIndex);
int endWordIndex = wordIndex(toIndex - 1);
expandTo(endWordIndex);
long firstWordMask = WORD_MASK << fromIndex;
long lastWordMask = WORD_MASK >>> -toIndex;
if (startWordIndex == endWordIndex) {
// Case 1: One word
words[startWordIndex] |= (firstWordMask & lastWordMask);
} else {
// Case 2: Multiple words
// Handle first word
words[startWordIndex] |= firstWordMask;
// Handle intermediate words, if any
for (int i = startWordIndex+1; i < endWordIndex; i++)
words[i] = WORD_MASK;
// Handle last word (restores invariants)
words[endWordIndex] |= lastWordMask;
}
checkInvariants();
}
/**
* Sets the bits from the specified {@code fromIndex} (inclusive) to the
* specified {@code toIndex} (exclusive) to the specified value.
*
* @param fromIndex index of the first bit to be set
* @param toIndex index after the last bit to be set
* @param value value to set the selected bits to
* @throws IndexOutOfBoundsException if {@code fromIndex} is negative,
* or {@code toIndex} is negative, or {@code fromIndex} is
* larger than {@code toIndex}
* @since 1.4
*/
public void set(int fromIndex, int toIndex, boolean value) {
if (value)
set(fromIndex, toIndex);
else
clear(fromIndex, toIndex);
}
/**
* Sets the bit specified by the index to {@code false}.
*
* @param bitIndex the index of the bit to be cleared
* @throws IndexOutOfBoundsException if the specified index is negative
* @since JDK1.0
*/
public void clear(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
if (wordIndex >= wordsInUse)
return;
words[wordIndex] &= ~(1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}
/**
* Sets the bits from the specified {@code fromIndex} (inclusive) to the
* specified {@code toIndex} (exclusive) to {@code false}.
*
* @param fromIndex index of the first bit to be cleared
* @param toIndex index after the last bit to be cleared
* @throws IndexOutOfBoundsException if {@code fromIndex} is negative,
* or {@code toIndex} is negative, or {@code fromIndex} is
* larger than {@code toIndex}
* @since 1.4
*/
public void clear(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
if (fromIndex == toIndex)
return;
int startWordIndex = wordIndex(fromIndex);
if (startWordIndex >= wordsInUse)
return;
int endWordIndex = wordIndex(toIndex - 1);
if (endWordIndex >= wordsInUse) {
toIndex = length();
endWordIndex = wordsInUse - 1;
}
long firstWordMask = WORD_MASK << fromIndex;
long lastWordMask = WORD_MASK >>> -toIndex;
if (startWordIndex == endWordIndex) {
// Case 1: One word
words[startWordIndex] &= ~(firstWordMask & lastWordMask);
} else {
// Case 2: Multiple words
// Handle first word
words[startWordIndex] &= ~firstWordMask;
// Handle intermediate words, if any
for (int i = startWordIndex+1; i < endWordIndex; i++)
words[i] = 0;
// Handle last word
words[endWordIndex] &= ~lastWordMask;
}
recalculateWordsInUse();
checkInvariants();
}
/**
* Sets all of the bits in this BitSet to {@code false}.
*
* @since 1.4
*/
public void clear() {
while (wordsInUse > 0)
words[--wordsInUse] = 0;
}
/**
* Returns the value of the bit with the specified index. The value
* is {@code true} if the bit with the index {@code bitIndex}
* is currently set in this {@code BitSet}; otherwise, the result
* is {@code false}.
*
* @param bitIndex the bit index
* @return the value of the bit with the specified index
* @throws IndexOutOfBoundsException if the specified index is negative
*/
public boolean get(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
checkInvariants();
int wordIndex = wordIndex(bitIndex);
return (wordIndex < wordsInUse)
&& ((words[wordIndex] & (1L << bitIndex)) != 0);
}
/**
* Returns a new {@code BitSet} composed of bits from this {@code BitSet}
* from {@code fromIndex} (inclusive) to {@code toIndex} (exclusive).
*
* @param fromIndex index of the first bit to include
* @param toIndex index after the last bit to include
* @return a new {@code BitSet} from a range of this {@code BitSet}
* @throws IndexOutOfBoundsException if {@code fromIndex} is negative,
* or {@code toIndex} is negative, or {@code fromIndex} is
* larger than {@code toIndex}
* @since 1.4
*/
public BitSet get(int fromIndex, int toIndex) {
checkRange(fromIndex, toIndex);
checkInvariants();
int len = length();
// If no set bits in range return empty bitset
if (len <= fromIndex || fromIndex == toIndex)
return new BitSet(0);
// An optimization
if (toIndex > len)
toIndex = len;
BitSet result = new BitSet(toIndex - fromIndex);
int targetWords = wordIndex(toIndex - fromIndex - 1) + 1;
int sourceIndex = wordIndex(fromIndex);
boolean wordAligned = ((fromIndex & BIT_INDEX_MASK) == 0);
// Process all words but the last word
for (int i = 0; i < targetWords - 1; i++, sourceIndex++)
result.words[i] = wordAligned ? words[sourceIndex] :
(words[sourceIndex] >>> fromIndex) |
(words[sourceIndex+1] << -fromIndex);
// Process the last word
long lastWordMask = WORD_MASK >>> -toIndex;
result.words[targetWords - 1] =
((toIndex-1) & BIT_INDEX_MASK) < (fromIndex & BIT_INDEX_MASK)
? /* straddles source words */
((words[sourceIndex] >>> fromIndex) |
(words[sourceIndex+1] & lastWordMask) << -fromIndex)
:
((words[sourceIndex] & lastWordMask) >>> fromIndex);
// Set wordsInUse correctly
result.wordsInUse = targetWords;
result.recalculateWordsInUse();
result.checkInvariants();
return result;
}
/**
* Returns the index of the first bit that is set to {@code true}
* that occurs on or after the specified starting index. If no such
* bit exists then {@code -1} is returned.
*
* <p>To iterate over the {@code true} bits in a {@code BitSet},
* use the following loop:
*
* <pre> {@code
* for (int i = bs.nextSetBit(0); i >= 0; i = bs.nextSetBit(i+1)) {
* // operate on index i here
* if (i == Integer.MAX_VALUE) {
* break; // or (i+1) would overflow
* }
* }}</pre>
*
* @param fromIndex the index to start checking from (inclusive)
* @return the index of the next set bit, or {@code -1} if there
* is no such bit
* @throws IndexOutOfBoundsException if the specified index is negative
* @since 1.4
*/
public int nextSetBit(int fromIndex) {
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return -1;
long word = words[u] & (WORD_MASK << fromIndex);
while (true) {
if (word != 0)
return (u * BITS_PER_WORD) + Long.numberOfTrailingZeros(word);
if (++u == wordsInUse)
return -1;
word = words[u];
}
}
/**
* Returns the index of the first bit that is set to {@code false}
* that occurs on or after the specified starting index.
*
* @param fromIndex the index to start checking from (inclusive)
* @return the index of the next clear bit
* @throws IndexOutOfBoundsException if the specified index is negative
* @since 1.4
*/
public int nextClearBit(int fromIndex) {
// Neither spec nor implementation handle bitsets of maximal length.
// See 4816253.
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex < 0: " + fromIndex);
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return fromIndex;
long word = ~words[u] & (WORD_MASK << fromIndex);
while (true) {
if (word != 0)
return (u * BITS_PER_WORD) + Long.numberOfTrailingZeros(word);
if (++u == wordsInUse)
return wordsInUse * BITS_PER_WORD;
word = ~words[u];
}
}
/**
* Returns the index of the nearest bit that is set to {@code true}
* that occurs on or before the specified starting index.
* If no such bit exists, or if {@code -1} is given as the
* starting index, then {@code -1} is returned.
*
* <p>To iterate over the {@code true} bits in a {@code BitSet},
* use the following loop:
*
* <pre> {@code
* for (int i = bs.length(); (i = bs.previousSetBit(i-1)) >= 0; ) {
* // operate on index i here
* }}</pre>
*
* @param fromIndex the index to start checking from (inclusive)
* @return the index of the previous set bit, or {@code -1} if there
* is no such bit
* @throws IndexOutOfBoundsException if the specified index is less
* than {@code -1}
* @since 1.7
*/
public int previousSetBit(int fromIndex) {
if (fromIndex < 0) {
if (fromIndex == -1)
return -1;
throw new IndexOutOfBoundsException(
"fromIndex < -1: " + fromIndex);
}
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return length() - 1;
long word = words[u] & (WORD_MASK >>> -(fromIndex+1));
while (true) {
if (word != 0)
return (u+1) * BITS_PER_WORD - 1 - Long.numberOfLeadingZeros(word);
if (u-- == 0)
return -1;
word = words[u];
}
}
/**
* Returns the index of the nearest bit that is set to {@code false}
* that occurs on or before the specified starting index.
* If no such bit exists, or if {@code -1} is given as the
* starting index, then {@code -1} is returned.
*
* @param fromIndex the index to start checking from (inclusive)
* @return the index of the previous clear bit, or {@code -1} if there
* is no such bit
* @throws IndexOutOfBoundsException if the specified index is less
* than {@code -1}
* @since 1.7
*/
public int previousClearBit(int fromIndex) {
if (fromIndex < 0) {
if (fromIndex == -1)
return -1;
throw new IndexOutOfBoundsException(
"fromIndex < -1: " + fromIndex);
}
checkInvariants();
int u = wordIndex(fromIndex);
if (u >= wordsInUse)
return fromIndex;
long word = ~words[u] & (WORD_MASK >>> -(fromIndex+1));
while (true) {
if (word != 0)
return (u+1) * BITS_PER_WORD -1 - Long.numberOfLeadingZeros(word);
if (u-- == 0)
return -1;
word = ~words[u];
}
}
/**
* Returns the "logical size" of this {@code BitSet}: the index of
* the highest set bit in the {@code BitSet} plus one. Returns zero
* if the {@code BitSet} contains no set bits.
*
* @return the logical size of this {@code BitSet}
* @since 1.2
*/
public int length() {
if (wordsInUse == 0)
return 0;
return BITS_PER_WORD * (wordsInUse - 1) +
(BITS_PER_WORD - Long.numberOfLeadingZeros(words[wordsInUse - 1]));
}
/**
* Returns true if this {@code BitSet} contains no bits that are set
* to {@code true}.
*
* @return boolean indicating whether this {@code BitSet} is empty
* @since 1.4
*/
public boolean isEmpty() {
return wordsInUse == 0;
}
/**
* Returns true if the specified {@code BitSet} has any bits set to
* {@code true} that are also set to {@code true} in this {@code BitSet}.
*
* @param set {@code BitSet} to intersect with
* @return boolean indicating whether this {@code BitSet} intersects
* the specified {@code BitSet}
* @since 1.4
*/
public boolean intersects(BitSet set) {
for (int i = Math.min(wordsInUse, set.wordsInUse) - 1; i >= 0; i--)
if ((words[i] & set.words[i]) != 0)
return true;
return false;
}
/**
* Returns the number of bits set to {@code true} in this {@code BitSet}.
*
* @return the number of bits set to {@code true} in this {@code BitSet}
* @since 1.4
*/
public int cardinality() {
int sum = 0;
for (int i = 0; i < wordsInUse; i++)
sum += Long.bitCount(words[i]);
return sum;
}
/**
* Performs a logical <b>AND</b> of this target bit set with the
* argument bit set. This bit set is modified so that each bit in it
* has the value {@code true} if and only if it both initially
* had the value {@code true} and the corresponding bit in the
* bit set argument also had the value {@code true}.
*
* @param set a bit set
*/
public void and(BitSet set) {
if (this == set)
return;
while (wordsInUse > set.wordsInUse)
words[--wordsInUse] = 0;
// Perform logical AND on words in common
for (int i = 0; i < wordsInUse; i++)
words[i] &= set.words[i];
recalculateWordsInUse();
checkInvariants();
}
/**
* Performs a logical <b>OR</b> of this bit set with the bit set
* argument. This bit set is modified so that a bit in it has the
* value {@code true} if and only if it either already had the
* value {@code true} or the corresponding bit in the bit set
* argument has the value {@code true}.
*
* @param set a bit set
*/
public void or(BitSet set) {
if (this == set)
return;
int wordsInCommon = Math.min(wordsInUse, set.wordsInUse);
if (wordsInUse < set.wordsInUse) {
ensureCapacity(set.wordsInUse);
wordsInUse = set.wordsInUse;
}
// Perform logical OR on words in common
for (int i = 0; i < wordsInCommon; i++)
words[i] |= set.words[i];
// Copy any remaining words
if (wordsInCommon < set.wordsInUse)
System.arraycopy(set.words, wordsInCommon,
words, wordsInCommon,
wordsInUse - wordsInCommon);
// recalculateWordsInUse() is unnecessary
checkInvariants();
}
/**
* Performs a logical <b>XOR</b> of this bit set with the bit set
* argument. This bit set is modified so that a bit in it has the
* value {@code true} if and only if one of the following
* statements holds:
* <ul>
* <li>The bit initially has the value {@code true}, and the
* corresponding bit in the argument has the value {@code false}.
* <li>The bit initially has the value {@code false}, and the
* corresponding bit in the argument has the value {@code true}.
* </ul>
*
* @param set a bit set
*/
public void xor(BitSet set) {
int wordsInCommon = Math.min(wordsInUse, set.wordsInUse);
if (wordsInUse < set.wordsInUse) {
ensureCapacity(set.wordsInUse);
wordsInUse = set.wordsInUse;
}
// Perform logical XOR on words in common
for (int i = 0; i < wordsInCommon; i++)
words[i] ^= set.words[i];
// Copy any remaining words
if (wordsInCommon < set.wordsInUse)
System.arraycopy(set.words, wordsInCommon,
words, wordsInCommon,
set.wordsInUse - wordsInCommon);
recalculateWordsInUse();
checkInvariants();
}
/**
* Clears all of the bits in this {@code BitSet} whose corresponding
* bit is set in the specified {@code BitSet}.
*
* @param set the {@code BitSet} with which to mask this
* {@code BitSet}
* @since 1.2
*/
public void andNot(BitSet set) {
// Perform logical (a & !b) on words in common
for (int i = Math.min(wordsInUse, set.wordsInUse) - 1; i >= 0; i--)
words[i] &= ~set.words[i];
recalculateWordsInUse();
checkInvariants();
}
/**
* Returns the hash code value for this bit set. The hash code depends
* only on which bits are set within this {@code BitSet}.
*
* <p>The hash code is defined to be the result of the following
* calculation:
* <pre> {@code
* public int hashCode() {
* long h = 1234;
* long[] words = toLongArray();
* for (int i = words.length; --i >= 0; )
* h ^= words[i] * (i + 1);
* return (int)((h >> 32) ^ h);
* }}</pre>
* Note that the hash code changes if the set of bits is altered.
*
* @return the hash code value for this bit set
*/
public int hashCode() {
long h = 1234;
for (int i = wordsInUse; --i >= 0; )
h ^= words[i] * (i + 1);
return (int)((h >> 32) ^ h);
}
/**
* Returns the number of bits of space actually in use by this
* {@code BitSet} to represent bit values.
* The maximum element in the set is the size - 1st element.
*
* @return the number of bits currently in this bit set
*/
public int size() {
return words.length * BITS_PER_WORD;
}
/**
* Compares this object against the specified object.
* The result is {@code true} if and only if the argument is
* not {@code null} and is a {@code Bitset} object that has
* exactly the same set of bits set to {@code true} as this bit
* set. That is, for every nonnegative {@code int} index {@code k},
* <pre>((BitSet)obj).get(k) == this.get(k)</pre>
* must be true. The current sizes of the two bit sets are not compared.
*
* @param obj the object to compare with
* @return {@code true} if the objects are the same;
* {@code false} otherwise
* @see #size()
*/
public boolean equals(Object obj) {
if (!(obj instanceof BitSet))
return false;
if (this == obj)
return true;
BitSet set = (BitSet) obj;
checkInvariants();
set.checkInvariants();
if (wordsInUse != set.wordsInUse)
return false;
// Check words in use by both BitSets
for (int i = 0; i < wordsInUse; i++)
if (words[i] != set.words[i])
return false;
return true;
}
/**
* Cloning this {@code BitSet} produces a new {@code BitSet}
* that is equal to it.
* The clone of the bit set is another bit set that has exactly the
* same bits set to {@code true} as this bit set.
*
* @return a clone of this bit set
* @see #size()
*/
public Object clone() {
if (! sizeIsSticky)
trimToSize();
try {
BitSet result = (BitSet) super.clone();
result.words = words.clone();
result.checkInvariants();
return result;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
/**
* Attempts to reduce internal storage used for the bits in this bit set.
* Calling this method may, but is not required to, affect the value
* returned by a subsequent call to the {@link #size()} method.
*/
private void trimToSize() {
if (wordsInUse != words.length) {
words = Arrays.copyOf(words, wordsInUse);
checkInvariants();
}
}
/**
* Save the state of the {@code BitSet} instance to a stream (i.e.,
* serialize it).
*/
private void writeObject(ObjectOutputStream s)
throws IOException {
checkInvariants();
if (! sizeIsSticky)
trimToSize();
ObjectOutputStream.PutField fields = s.putFields();
fields.put("bits", words);
s.writeFields();
}
/**
* Reconstitute the {@code BitSet} instance from a stream (i.e.,
* deserialize it).
*/
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField fields = s.readFields();
words = (long[]) fields.get("bits", null);
// Assume maximum length then find real length
// because recalculateWordsInUse assumes maintenance
// or reduction in logical size
wordsInUse = words.length;
recalculateWordsInUse();
sizeIsSticky = (words.length > 0 && words[words.length-1] == 0L); // heuristic
checkInvariants();
}
/**
* Returns a string representation of this bit set. For every index
* for which this {@code BitSet} contains a bit in the set
* state, the decimal representation of that index is included in
* the result. Such indices are listed in order from lowest to
* highest, separated by ", " (a comma and a space) and
* surrounded by braces, resulting in the usual mathematical
* notation for a set of integers.
*
* <p>Example:
* <pre>
* BitSet drPepper = new BitSet();</pre>
* Now {@code drPepper.toString()} returns "{@code {}}".
* <pre>
* drPepper.set(2);</pre>
* Now {@code drPepper.toString()} returns "{@code {2}}".
* <pre>
* drPepper.set(4);
* drPepper.set(10);</pre>
* Now {@code drPepper.toString()} returns "{@code {2, 4, 10}}".
*
* @return a string representation of this bit set
*/
public String toString() {
checkInvariants();
int numBits = (wordsInUse > 128) ?
cardinality() : wordsInUse * BITS_PER_WORD;
StringBuilder b = new StringBuilder(6*numBits + 2);
b.append('{');
int i = nextSetBit(0);
if (i != -1) {
b.append(i);
while (true) {
if (++i < 0) break;
if ((i = nextSetBit(i)) < 0) break;
int endOfRun = nextClearBit(i);
do { b.append(", ").append(i); }
while (++i != endOfRun);
}
}
b.append('}');
return b.toString();
}
/**
* Returns a stream of indices for which this {@code BitSet}
* contains a bit in the set state. The indices are returned
* in order, from lowest to highest. The size of the stream
* is the number of bits in the set state, equal to the value
* returned by the {@link #cardinality()} method.
*
* <p>The bit set must remain constant during the execution of the
* terminal stream operation. Otherwise, the result of the terminal
* stream operation is undefined.
*
* @return a stream of integers representing set indices
* @since 1.8
*/
public IntStream stream() {
class BitSetIterator implements PrimitiveIterator.OfInt {
int next = nextSetBit(0);
@Override
public boolean hasNext() {
return next != -1;
}
@Override
public int nextInt() {
if (next != -1) {
int ret = next;
next = nextSetBit(next+1);
return ret;
} else {
throw new NoSuchElementException();
}
}
}
return StreamSupport.intStream(
() -> Spliterators.spliterator(
new BitSetIterator(), cardinality(),
Spliterator.ORDERED | Spliterator.DISTINCT | Spliterator.SORTED),
Spliterator.SIZED | Spliterator.SUBSIZED |
Spliterator.ORDERED | Spliterator.DISTINCT | Spliterator.SORTED,
false);
}
}
1.4 BitSetDemo
package com.wmy.java.arithmetic.binarySearch;
import java.util.BitSet;
/**
* @project_name: flinkDemo
* @package_name: com.wmy.java.arithmetic.binarySearch
* @Author: wmy
* @Date: 2021/10/30
* @Major: 数据科学与大数据技术
* @Post:大数据实时开发
* @Email:wmy_2000@163.com
* @Desription: BitSetTestDemo
* @Version: wmy-version-01
*/
public class BitSetTest {
public static void main(String[] args) {
// 创建一个数组
int[] arr = {1, 2, 3, 4, 5, 6};
// 创建一个BitSet
BitSet bitSet = new BitSet(6);
// 添加元素
for (int i = 0; i < arr.length; i++) {
bitSet.set(arr[i], true);
}
// 打印测试
System.out.println(bitSet.size()); // 64
System.out.println(bitSet.get(7)); // false
System.out.println(bitSet.get(3)); // true
}
}可以看到,跟我们前面想的差不多
用一个long数组来存储,初始长度64,set值的时候首先右移6位(相当于除以64)计算在数组的什么位置,然后更改状态位
别的看不懂不要紧,看懂这两句就够了:
int wordIndex = wordIndex(bitIndex);
words[wordIndex] |= (1L << bitIndex);1.5 Bloom Filters

Bloom filter 是一个数据结构,它可以用来判断某个元素是否在集合内,具有运行快速,内存占用小的特点。
而高效插入和查询的代价就是,Bloom Filter 是一个基于概率的数据结构:它只能告诉我们一个元素绝对不在集合内或可能在集合内。
Bloom filter 的基础数据结构是一个 比特向量(可理解为数组)。
主要应用于大规模数据下不需要精确过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(哈希表)等等数据结构都是这种思路,但是随着集合中元素的增加,需要的存储空间越来越大;同时检索速度也越来越慢,检索时间复杂度分别是O(n)、O(log n)、O(1)。
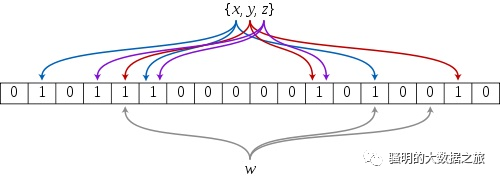
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
BloomFilter 流程
首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中对应的比特位置为 1;
判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependenccom.google.common.hash.BloomFilter
1.5 BitMap参考文档
http://llimllib.github.io/bloomfilter-tutorial/zh_CN/
https://www.cnblogs.com/geaozhang/p/11373241.html
https://www.cnblogs.com/huangxincheng/archive/2012/12/06/2804756.html
https://www.cnblogs.com/DarrenChan/p/9549435.html
2、Clickhouse的RoaringBitmap介绍
2.1 流程图
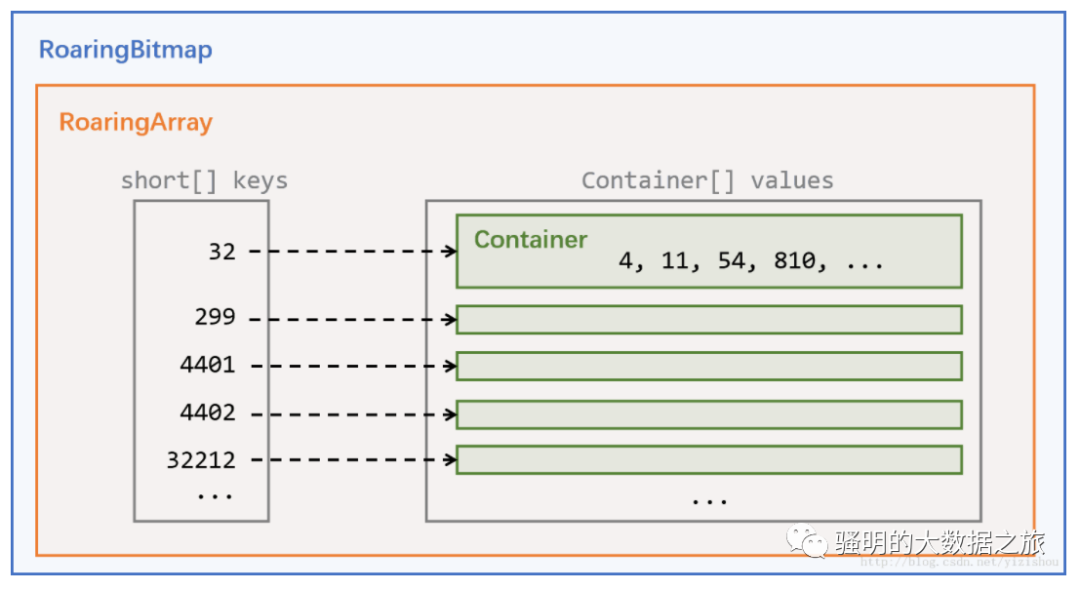
每个RoaringBitmap(GitHub链接)中都包含一个RoaringArray,名字叫highLowContainer。highLowContainer存储了RoaringBitmap中的全部数据。
RoaringArray highLowContainer;这个名字意味着,会将32位的整形(int)拆分成高16位和低16位两部分(两个short)来处理。
RoaringArray的数据结构很简单,核心为以下三个成员:
short[] keys;
Container[] values;
int size;每个32位的整形,高16位会被作为key存储到short[] keys中,低16位则被看做value,存储到Container[] values中的某个Container中。keys和values通过下标一一对应。size则标示了当前包含的key-value pair的数量,即keys和values中有效数据的数量。
keys数组永远保持有序,方便二分查找。
2.2 三种Container
下面介绍到的是RoaringBitmap的核心,三种Container。
通过上面的介绍我们知道,每个32位整形的高16位已经作为key存储在RoaringArray中了,那么Container只需要处理低16位的数据。
2.3 ArrayContainer
static final int DEFAULT_MAX_SIZE = 4096
short[] content;结构很简单,只有一个short[] content,将16位value直接存储。
short[] content始终保持有序,方便使用二分查找,且不会存储重复数值。
因为这种Container存储数据没有任何压缩,因此只适合存储少量数据。
ArrayContainer占用的空间大小与存储的数据量为线性关系,每个short为2字节,因此存储了N个数据的ArrayContainer占用空间大致为2N字节。存储一个数据占用2字节,存储4096个数据占用8kb。
根据源码可以看出,常量DEFAULT_MAX_SIZE值为4096,当容量超过这个值的时候会将当前Container替换为BitmapContainer。
2.4 BitmapContainer
final long[] bitmap;这种Container使用long[]存储位图数据。我们知道,每个Container处理16位整形的数据,也就是0~65535,因此根据位图的原理,需要65536个比特来存储数据,每个比特位用1来表示有,0来表示无。每个long有64位,因此需要1024个long来提供65536个比特。
因此,每个BitmapContainer在构建时就会初始化长度为1024的long[]。这就意味着,不管一个BitmapContainer中只存储了1个数据还是存储了65536个数据,占用的空间都是同样的8kb。
2.5 RunContainer
private short[] valueslength;
int nbrruns = 0;RunContainer中的Run指的是行程长度压缩算法(Run Length Encoding),对连续数据有比较好的压缩效果。
它的原理是,对于连续出现的数字,只记录初始数字和后续数量。即:
对于数列11,它会压缩为11,0;
对于数列11,12,13,14,15,它会压缩为11,4;
对于数列11,12,13,14,15,21,22,它会压缩为11,4,21,1;
源码中的short[] valueslength中存储的就是压缩后的数据。
这种压缩算法的性能和数据的连续性(紧凑性)关系极为密切,对于连续的100个short,它能从200字节压缩为4字节,但对于完全不连续的100个short,编码完之后反而会从200字节变为400字节。
如果要分析RunContainer的容量,我们可以做下面两种极端的假设:
最好情况,即只存在一个数据或只存在一串连续数字,那么只会存储2个short,占用4字节
最坏情况,0~65535的范围内填充所有的奇数位(或所有偶数位),需要存储65536个short,128kb
2.6 Container性能总结
2.6.1 读取时间
只有BitmapContainer可根据下标直接寻址,复杂度为O(1),ArrayContainer和RunContainer都需要二分查找,复杂度O(log n)
2.6.2 内存占用
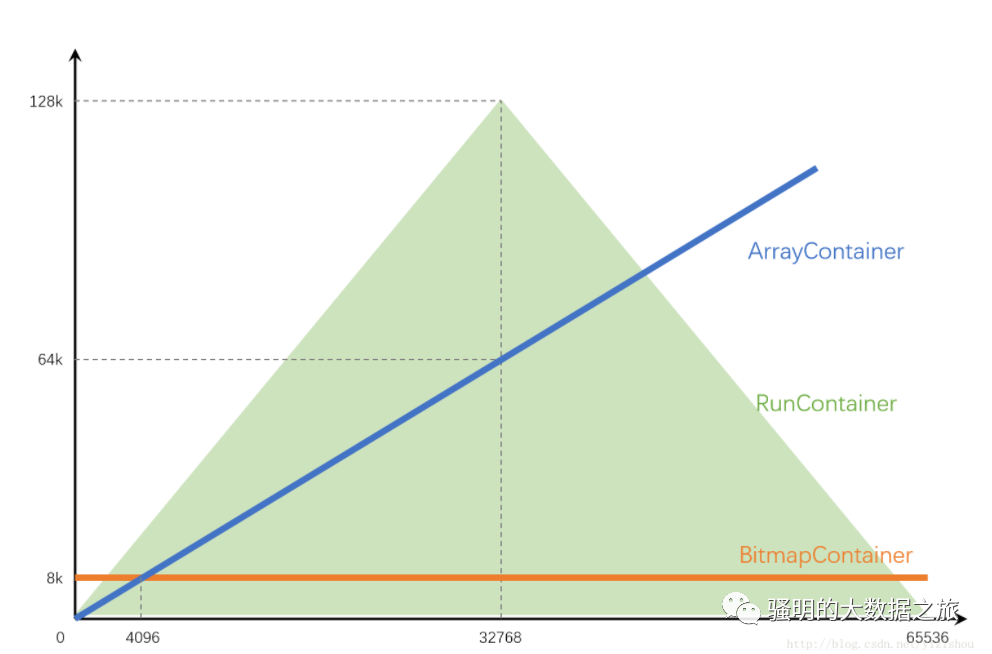
这是我画的一张图,大致描绘了各Container占用空间随数据量的趋势。
其中,
ArrayContainer一直线性增长,在达到4096后就完全比不上BitmapContainer了
BitmapContainer是一条横线,始终占用8kb
RunContainer比较奇葩,因为和数据的连续性关系太大,因此只能画出一个上下限范围。不管数据量多少,下限始终是4字节;上限在最极端的情况下可以达到128kb。
2.6.3 RoaringBitmap针对Container的优化策略
创建时:
创建包含单个值的Container时,选用ArrayContainer
创建包含一串连续值的Container时,比较ArrayContainer和RunContainer,选取空间占用较少的
转换:
针对ArrayContainer:
如果插入值后容量超过4096,则自动转换为BitmapContainer。因此正常使用的情况下不会出现容量超过4096的ArrayContainer。
调用runOptimize()方法时,会比较和RunContainer的空间占用大小,选择是否转换为RunContainer。
针对BitmapContainer:
如果删除某值后容量低至4096,则会自动转换为ArrayContainer。因此正常使用的情况下不会出现容量小于4096的BitmapContainer。
调用runOptimize()方法时,会比较和RunContainer的空间占用大小,选择是否转换为RunContainer。
针对RunContainer:
只有在调用runOptimize()方法才会发生转换,会分别和ArrayContainer、BitmapContainer比较空间占用大小,然后选择是否转换。
3、基于bitmap实现业务需求
我们的需求场景是:任意时间段, 求关注的人群基数(去重)
如果使用传统数仓按天分区做法,成本会非常高,而且无法做到在线查询出结果的
简单解释下:
2021-01-01这一天 关注的iphone12的人是 : [张三、王五、赵六]
2021-01-02这一天 关注的iphone12的人是 : [王五、赵六、陈七]
求这两天关注过iphone12的人数量:
[张三、王五、赵六]
or
[王五、赵六、陈七]
然后去重,得到:
[[张三、王五、赵六、陈七]求2021-01-01到2021-01-02的留存人数:
[张三、王五、赵六]
and
[王五、赵六、陈七]
相交得到:
[王五、赵六]求2021-01-02 相比 2021-01-01的新增人数
[王五、赵六、陈七]
andNot
[张三、王五、赵六]
在2021-01-02出现过,但没有在2021-01-01出现过的人
[陈七]以上的操作如果要通过Clickhouse实现,需要如下几步:
第一步:在clickhouse形成满足需求的宽表
第二步:基于宽表实现bitmap表
第三步:实现需求查询的sql
3.1、实现业务宽表
我们实现宽表的方式是:Hive加工处理,得到业务宽表,然后经过Datax将数据同步到Clickhouse里面,比如,按照上面的逻辑,实现的宽表就是(clickhouse的表):
{
dt string 时间
brand 品牌 手机品牌
phone_model 手机型号
device_id String 设备号
}3.2、基于宽表实现bitmap表
lickhouse的bitmap函数页面:https://clickhouse.com/docs/zh/sql-reference/functions/bitmap-functions/
简单分析下需求,我们要取品牌、型号、天维度下的人群基数
那么Clickhouse的bitmap表可以做成如下结构:
{
dt LowCardinality(String) 时间
dim_type LowCardinality(String) 维度类型(1:品牌维度、2:手机型号维度)
dim_value LowCardinality(String) 每个dim_type维度下对应的品牌或者手机型号值
bitmap_dvid AggregateFunction(groupBitmap, UInt32) 明细
}然后通过jdbc或者sparkSQL,实现如下操作,向clickhouse的bitmap表插入数据:
1):插入数据前,删除分区
alter table bitmap的表 on cluster default_cluster drop partition 时间分区2):分别插入不同维度的bitmap
插入品牌维度:
INSERT INTO bitmap表 select dt , 1 , brand , groupBitmapState(toUInt32(dvid)) as dvid from 宽表 where dt = 日期
group by brand
插入型号维度
INSERT INTO bitmap表 select dt , 2 , phone_model , groupBitmapState(toUInt32(dvid)) as dvid from 宽表 where dt = 日期
group by phone_model3):查询新增、留存等
查询iphone12品牌在当前周期(2021-07-01~2021-09-29)相比上周期(2021-05-01 ~ 2021-06-30)的留存人数
select bitmapCardinality(
bitmapAnd(
select groupBitmapOrState(devid_bmp) from(
select devid_bmp from bitmap表 where dt >= '2021-07-01' and dt <= '2021-09-29' and dim_type = 1 and dim_value = 'iphone12'
) , -- 当期周期关注过iphone12的人
select groupBitmapOrState(devid_bmp) from(
select devid_bmp from bitmap表 where dt >= '2021-05-01' and dt <= '2021-06-30' and dim_type = 1 and dim_value = 'iphone12'
) -- 上周期关注过iphone12的人
)
)经过测验:一个月的人群数量大约是:1亿
通过bitmap查询留存,一个月的情况,不到2s
4、优化bitmap在clickhouse上的使用
4.1、引擎上的选择
首先是引擎上的选择,实际压测,发现两种引擎在bitmap场景下效率最高,分别是:
1、MergeTree
2、ReplicatedMergeTree
其中使用MergeTree性能会更好
4.2、缩减bitmap的大小
我们的设备明细一般是64位的,经过hash散列后,占用的bitmap空间其实是非常大的
所以我们对所有的设备明细维护了一套数字(其实就是hive的row_number)
这样bitmao大大缩减,极大提升查询速度,减小了每次查询使用的CPU和内存
欢迎大佬和各位学习的同伴们多多提建议,非常感谢。。。
