点击蓝字 关注我们
在Cassandra中文社区2021年开年活动中,来自阿里云的刘军民老师介绍了Cassandra的典型应用场景、回顾了Cassandra中文社区2020大事件,并且分享了他对Cassandra中文社区发展思考。
由于篇幅限制,本文仅截取了演讲的重点段落,点击文末“阅读原文”查看完整活动视频录像以获取更多详细信息。
演讲嘉宾

刘军民
阿里云数据库产品经理。目前在阿里云负责云Cassandra数据库的产品规划相关工作。曾在19年与多位小伙伴共同发起Cassandra中文社区,期望更多的伙伴加入到社区建设,期待Cassandra在中国区可以生机勃勃,大放异彩。
我们刚开始接触Cassandra时,发现这是一个不错的产品,但问题是国内没有中文社区。所以我们联合了阿里云的小伙伴以及其他公司的开发者发起了一些建设工作。
现在,越来越多的公司已经加入进来了,尤其像DataStax的孔令子和邓为老师。他们在社区中做了很多的布道工作,非常感谢他们的付出。
我今天会首先对社区2020年大事件进行回顾,其次会讲一下阿里云客户中典型的应用场景。我们在和客户的交流中,发现很多开发者,甚至CTO都不是很了解Cassandra。不知道Cassandra能应用在什么场景,所以我今天针对这个做一个专门的分享。
01
社区大事件年度回顾
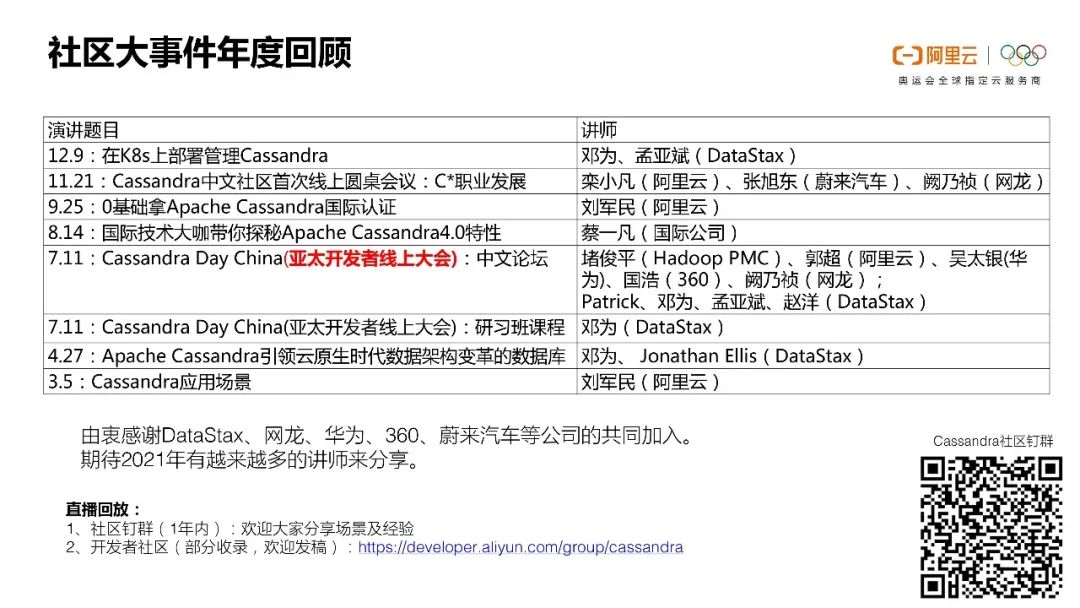
我们前年就在北京开展过线下的meet up。今年本来也想组织线下的meet up,但因为疫情的反复,所以最终改成了线上。
2020年我们也做了很多的技术直播,包括关于应用场景的。这些所有直播都可以在我们社区的钉钉群和DataStax B站主页上找到回放。
我们其实依然希望各个公司的这种开发人员和讲师来我们社区讲课,分享他们在某些应用场景上面的心得,做一些类似于建模或者是各种各样的分享。我们很欢迎大家来联系我们做一个这样的技术直播。
02
社区的流行度情况
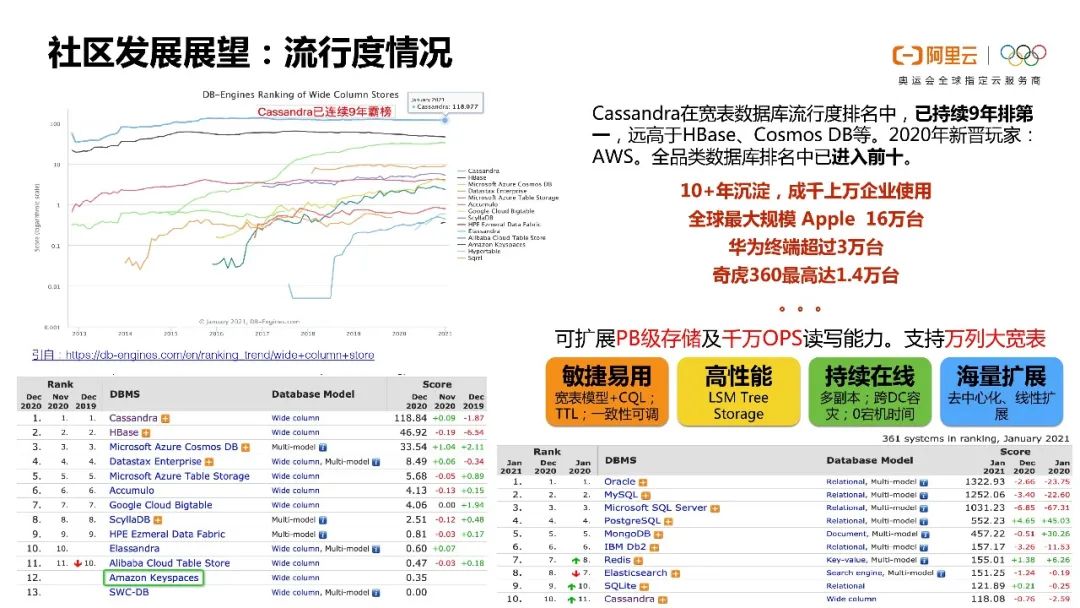
接下来是展望,其实Cassandra在宽表数据库领域其实已经连续9年霸榜了。大家可以看到这个数据库本身是一个非常好的非常优秀的数据库产品,它从2012年开始到现在流行一直都是第一的。所以大家可以看到它在国际上的地位,它其实是非常流行的一个数据库。
我个人觉得有如下4个方面是值得大家选Cassandra的数据库的:
第一点就是Cassandra对我们开发者是非常易用的。它有CQL语法的支持,这其实就是一个简化版的SQL语句。如果是MySQL开发者切换到Cassanda上,其实不用花太多的精力,很快便可以上手。它还有表级TTL、行级TTL、列级TTL的支持,这可以简化我们数据的处理。
第二点是高性能,大家可以去测一下数据库,你可以发现它数据库的性能表现是非常好的。
第三点就是持续在线能力,它其实有一个非常好的功能。比如我在3副本QUORUM读写这种模式下,单节点故障和单节点下线其实对整个集群没有一个太大的影响,应用甚至都感知不到这个故障,这是它很好的在线能力。同时它还有原生的跨DC容灾的能力,这些都是非常好用的一些特性。
最后就是它的海量扩展能力,单个节点就可以起配,它是没有任何起配门槛的。随着你整个集群慢慢扩大,单个集群可以扩大到几百上千节点的规模。
我觉得这一个很好的大数据的数据库。在2020年,AWS也加入了Cassandra玩家的阵列,它在4月份时发布了一个Amazon Keyspaces云产品,这其实就是一个Cassandra云产品。
所以现在大家可以看到,整个Cassandra的发展应该是呈现一个越来越成熟、越来越丰富的趋势。
03
中文社区发展展望
其实我希望和大家一起来立一个新年的 flag。
全球:
现在全球有数千万开发者,我们希望可以联手包括DataStax和其它的一些公司,在东南亚甚至是在欧美这些比较发达的一些国家建设生态、建设社区。这样能把更多国际上的一些优秀的案例,包括一些最佳实践,回流到中国区,然后给国内的开发者带来参考和便利。
包括海外的一些嘉宾,我们也希望社区里一些非常优秀的讲师能来中国区给我们国内的开发者做一些布道, 这是我们在全球区的期望。
国内:
在中国区,我们也希望把Cassabdra社区建设成一个开放性的社区,然后每个月都定期组织这种技术直播。
我们也希望在各个行业,包括整个的一些应用场景上面,有一个比较成熟的最佳实践来分享给大家。比如说我们的互联网、车联网、IoT场景、包括我们现在正在新兴的智能制造等行业,我们都希望有对应Cassandra的最佳实践。
我们也希望能把这些案例同步到我们社区里面来,给大家做更多各种各样的参考。这样其实就可以指导我们的开发者更好地去用好Cassandra数据库。
我们希望在2021年能够把这些事情做的更完善。包括我们线下meet up,等疫情过去的话,我们依然想坚持把线下meet up活动一直做下去,然后从线上走到线下,和大家面对面做一些交流或讨论。
因为我最近其实也没有时间去写博客了,但我也希望大家能够把自己的一些心得,包括把自己的一些在Cassandra上的一些应用实践,以博客的方式投稿到开发者社区来。然后给大家所有的这些周边的一些团队、同行去做一些这种交流,这我觉得是非常好的一个事情。
所以我们在2021年的话,我们依然会推动去做这些事情。
最后,我们也希望和中国区的Cassandra开发者,包括我们的一些领域行业专家一起联手去出一本书。那么这本书是属于我们中国开发者自己的Cassandra技术书籍。我们期望行业内顶级Cassandra技术的专家,甚至国际上的一些专家都能够加入进来,把这本书做成一个高质量的输出。
接下来是关于我们社区的组织,目前我们社区的一个理事会其实还并没有非常完善,我们希望在2021年能让社区理事会更较正式地、更加健康地运行下去。
接着,我们也是希望拿到一些商业公司或一些社会的赞助,比如我们能有资金来组织或启动一些线下活动。
第三点,我们希望每半年或每一年评选优秀讲师,包括一些社区贡献比较突出的贡献者。我们希望能够激励,这包括颁发一些纪念碑或者是纪念奖章,类似于这些事情。我们希望在2021年把这个事情做的更好。其实2020年我们也邀请了很多公司里面的专家给我们做一些讲座,这些老师目前也都是无偿的,我们也希望能够给一些纪念品。
第四点,其实我们也是希望能够在一线城市,包括一些二线城市,甚至于这些Cassandra可能比较流行的一些区域,创立一些社区的分部,通过这些分部去定期或不定期的组织一些社区的督导工作。
那么这是我个人期望2021年在Cassandra社区的一些工作,或是团队建设上的一些思考。
04
Cassandra典型应用场景
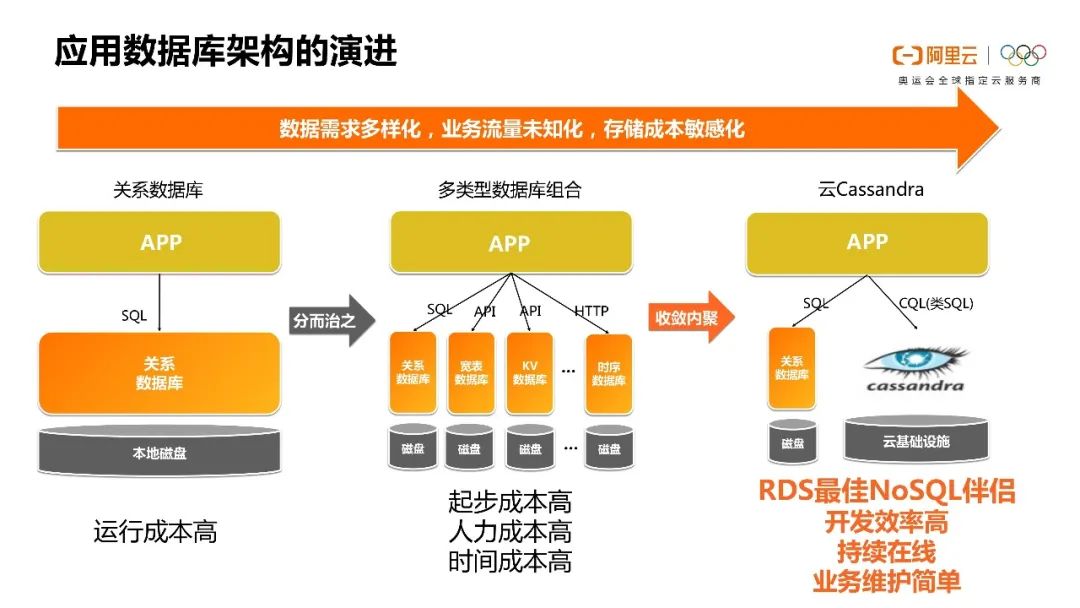
现在让我们进入比较关键的一个话题,Cassandra到底在哪些场景可以使用。或者先让我们聊一下为什么像Cassandra或HBase这种宽表数据库会出现。
我觉得这也是因为数据的爆炸式增长,对数据的需求变得多样化。流量,包括现在各种APP、各种场景的丰富度,导致原先传统的SQL关系数据库很难覆盖所有的使用场景。
随着技术的发展,其实越到后面你就会发现除了要一个RDS之外,还需要一个NoSQL的大数据的数据库。我们Cassandra就是为了这种场景而诞生的。
05
云上典型应用场景
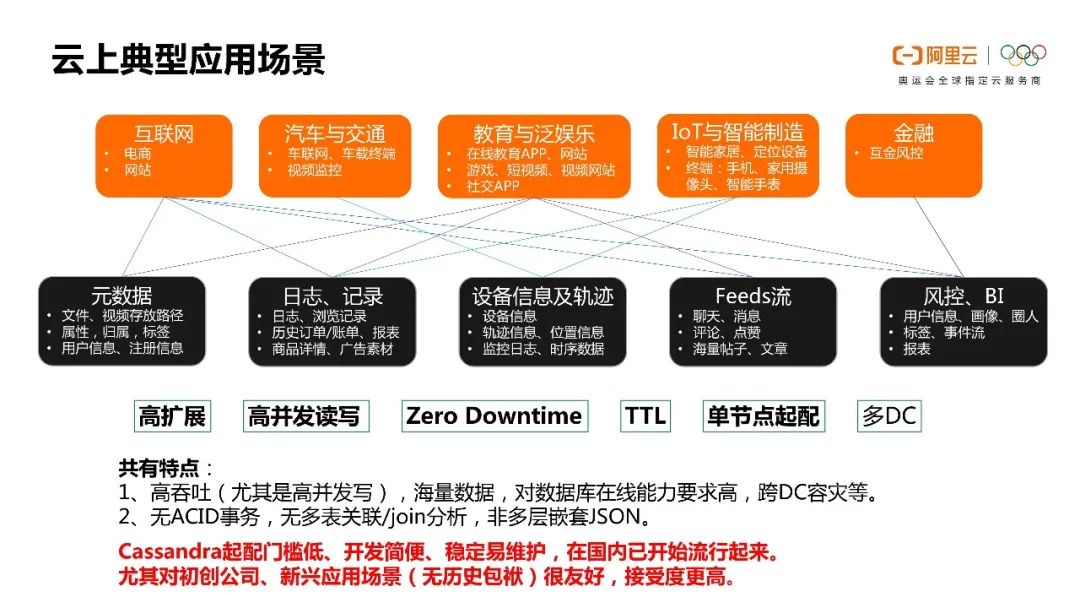
那它具体可以应用到哪些场景?下图中我将阿里云的一些客户做了一个大致的汇总。
汇总下来,我们发现主要的使用场景可以分在以下五个方面。
上面的是我们用到的行业,下面是具体的应用场景。
其实我们对Cassandra的特性的认识主要是高扩展和高并发的读写能力、零宕机时间(Always Online)、TTL特性,还有单节点起配。Cassandra是没有起配门槛的,很多有新兴应用场景的初创公司是非常喜欢这种数据库的。
因为用起来非常简单,开发起来也非常简单,成本也非常低,并且没有起配的门槛。最后Cassandra还有一个特点就是多DC,大家也都很认可它原生的多DC的容灾能力。
总结起来的话就是Cassandra的起配门槛非常低,有开发简单、非常稳定、比较容易维护的特点。所以在国内其实也开始慢慢的变得流行起来。
尤其是前面提到过的一些初创公司和有新兴应用场景的公司,他们其实是没有历史包袱的,而且这些公司的一些开发人员也更加open一些,当他们去选数据库时,也会优先去考虑这种优秀的数据库。所以我们就会发现Cassandra在这些公司中的接受度其实比那些传统行业的接受度会更高一些。
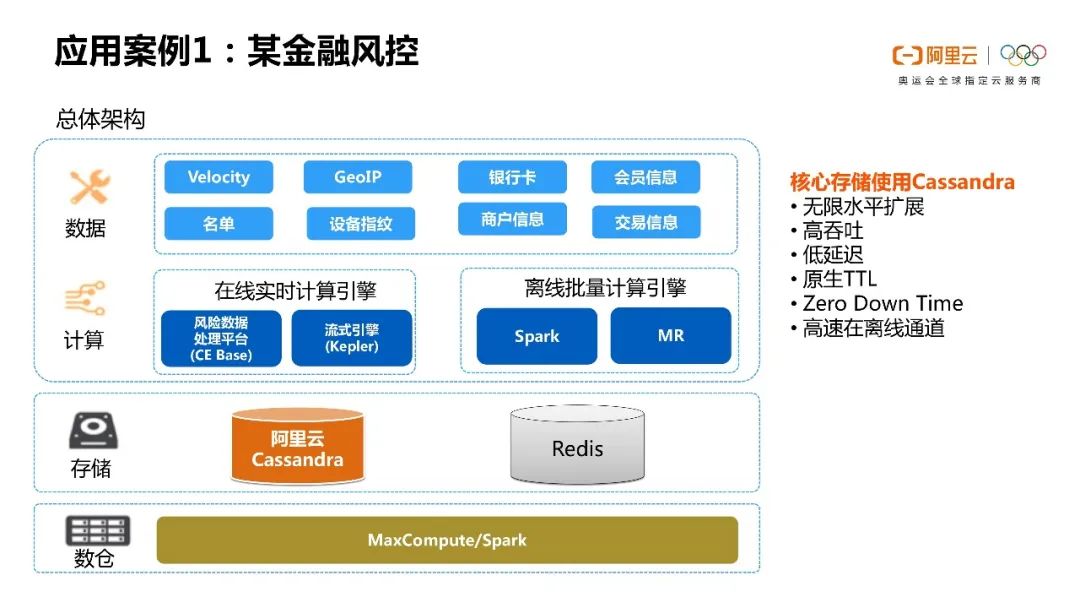
接下来就是一些具体的场景了,比如说金融风控和Spark的联合应用。比如说可以通过spark分析Cassandra里面的数据,然后做一些离/在线分析。类似于这种应用其实可以用到一些分工的场景。
从我们这类客户会反馈来说,他们欣赏Cassandra数据库的良好的水平拓展性,有原生的TTL以及零宕机时间。
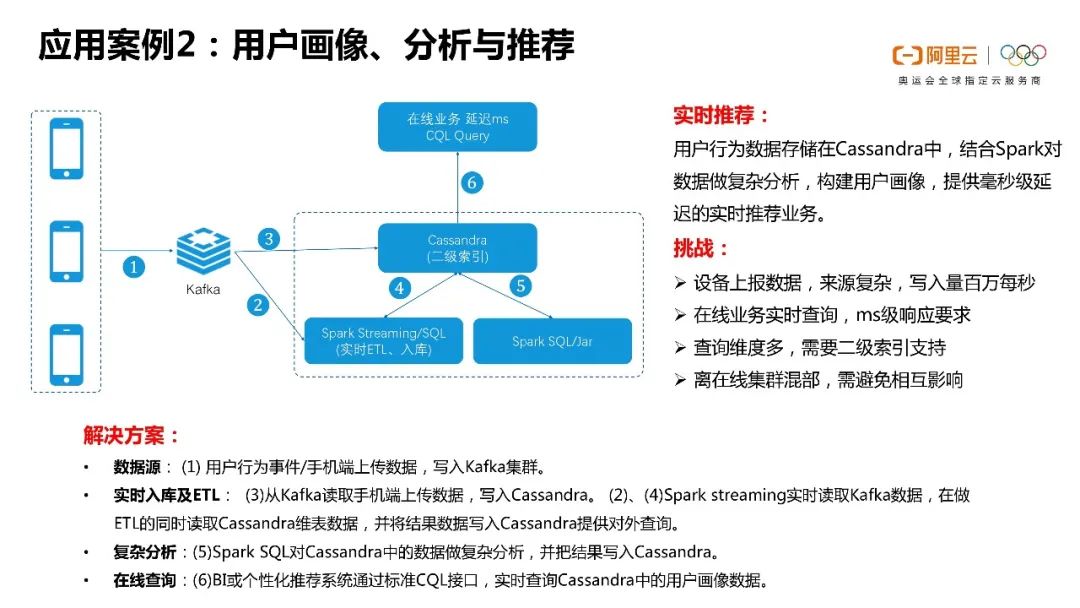
第二包括Kafka、Spark Streaming/SQL和Crystal,这些其实也有客户慢慢地和Cassandra一起联合应用起来了。
这其实也是看中了Cassandra的高并发的写入以及强扩展等能力。
第三点就是IoT物联网和车联网。他们其实也是看中了Cassandra完全在线的扩展能力以及高并发的写入。
IoT有一个特点:前端的终端设备非常庞大。这么庞大的设备量对后端数据库高并发写入的要求是非常高的,那这就是Cassandra的优势场景了。因为Cassandra主要就是为了应对这种高并发写入的数据库。
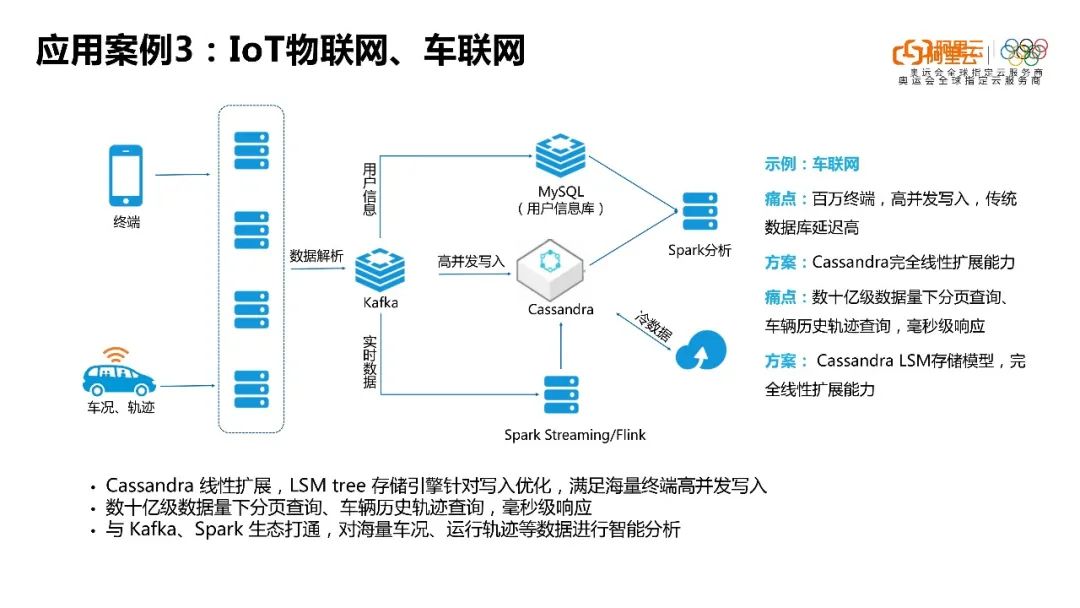
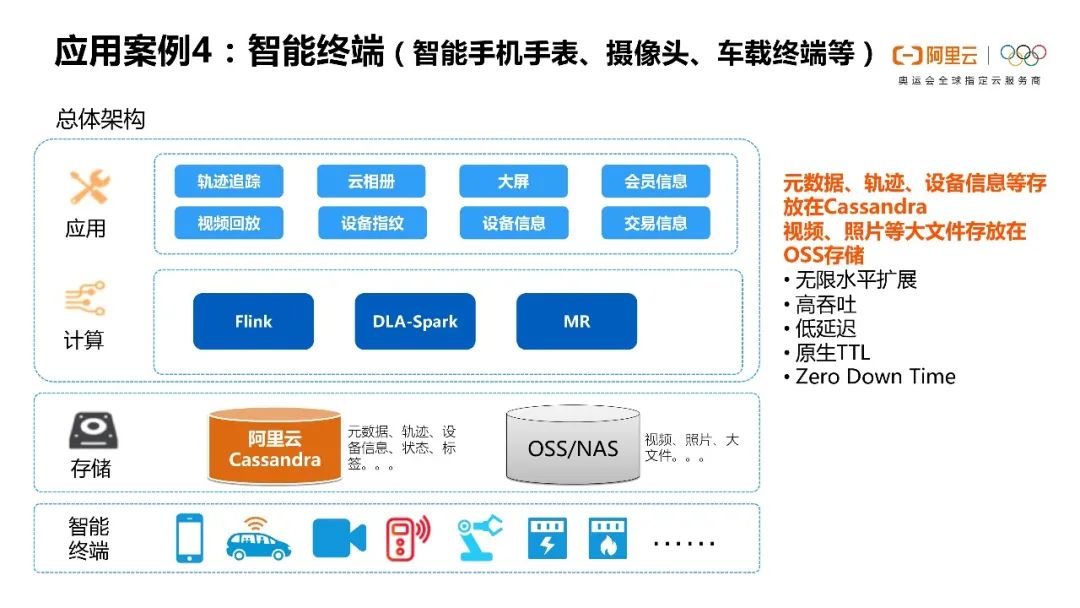
第四点是智能终端,比如说现在很多儿童手表有定位功能,包括家用摄像头以及车载终端。
其实这些终端都有一个共同的特点,它们的终端数量是非常庞大的,终端信息也非常庞大。所以这些场景其实也是有高并发写入的需求的,而Cassandra就非常适合于满足这种需求。
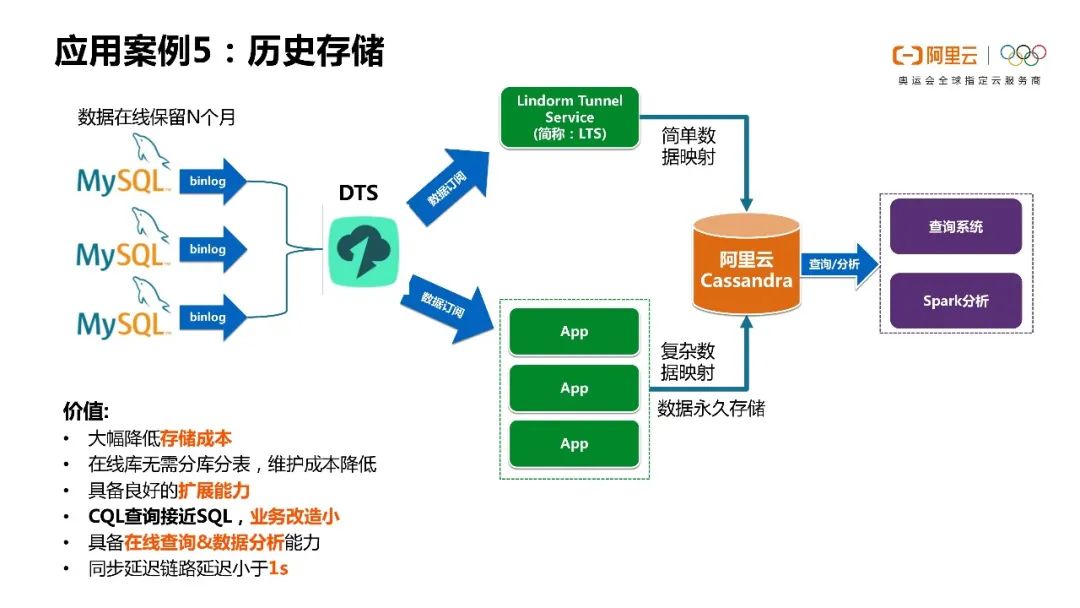
还有用户会把Cassandra用于历史存储。比如说我有一些其它系统的日志,我就可以把它们存到Cassandra里做一个长期归档。然后这些大量的数据还可以用来和spark做分析,然后可以提供报表或者是数据挖掘的能力。
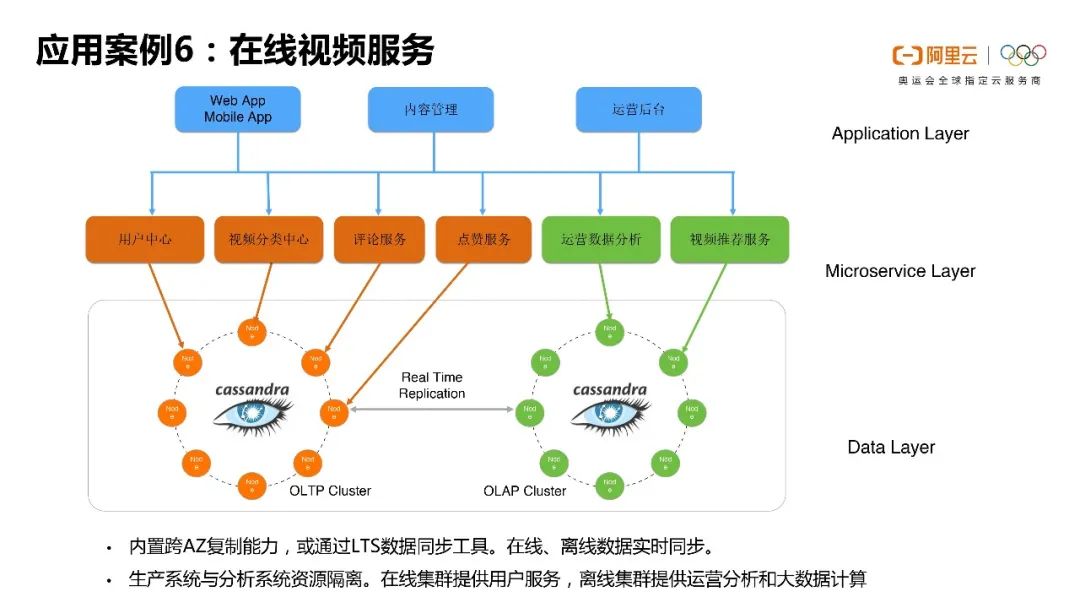
第六个场景是现在国内慢慢开始出现的视频业务的应用,其实就是会用到Cassandra多逻辑DC的能力。
因为Cassandra本身可以多逻辑DC部署的,我们不需要通过额外的数据传输工具实现多逻辑DC的数据传输,那么我们就可以非常容易构建存算分离或读写分离的模式。
如果我有专门的生产逻辑DC,这些集群资源就可供我的生产系统来用。然后如果我的再扩一个逻辑DC出来,那么用这个DC的资源,我就可以专门去跑这种高并发分析任务。那么这样的话它就可以在两个逻辑DC之间实现每个DC里的工作负载对资源独占,但互不影响。这种用法其实是推荐的。
第七个场景就是社交场景。我们现在国内的APP越来越多,大家可能在国内是非常有体感的,各种各样的APP。它们其实都有这种类似于海量的帖子、文章、聊天,包括一些评论点赞。这些信息其实都可以用Cassandra就去做一个完美的实现。
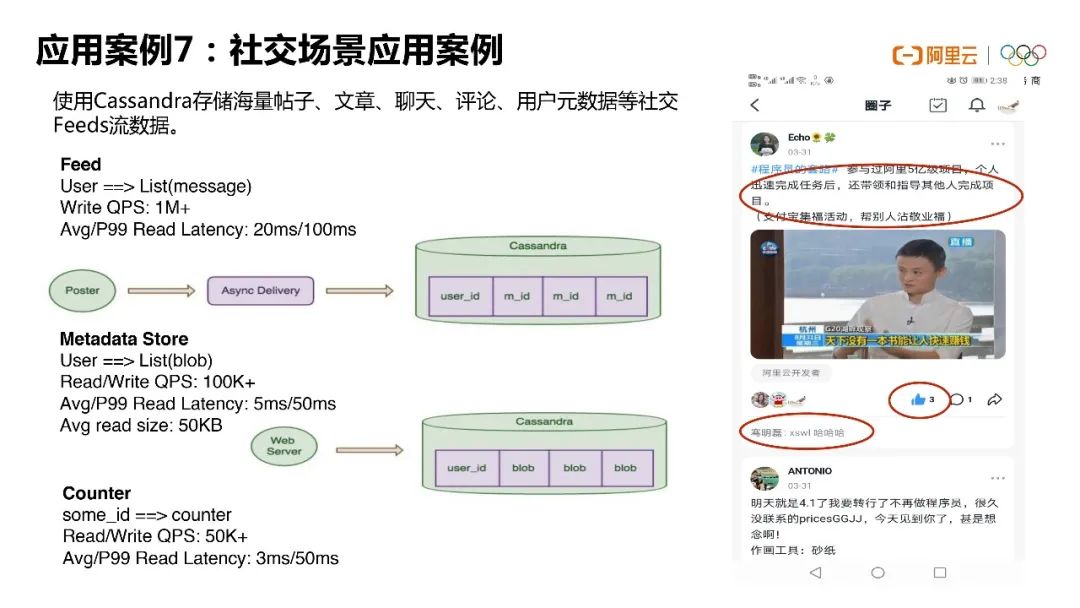
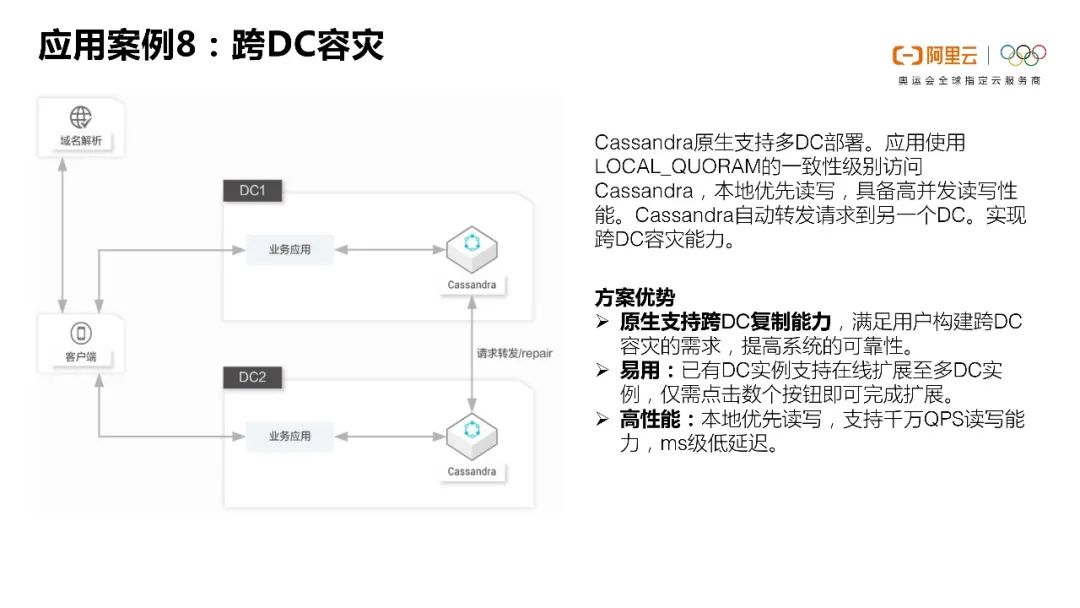
第八点前面提到过了的跨DC容灾,这里就不重复了。
由于篇幅限制,本文仅截取部分演讲内容。
点击文末“阅读原文”查看本次演讲的完整视频录像。
本文内容版权归DataStax所有
未经书面允许禁止转载
本文图片均来自网络,版权归原作者所有
推荐阅读

DataStax在中国
技术资讯 | 行业动态 | 活动信息
阅读这篇文章有收获?
请通过点赞、分享和在看告诉我们