点击蓝字 关注我们
在Cassandra中文社区2021年开年活动中,来自DataStax的邓为老师分享了与Cassandra相关的历史故事、DataStax在Cassandra的发展进程中所扮演的角色以及Cassandra国际社区的现状。
由于篇幅限制,本文仅截取了演讲的重点段落,点击文末“阅读原文”查看完整活动视频录像以获取更多详细信息。
演讲嘉宾

邓为
现任DataStax领航架构师总监。深耕分布式数据库系统十余年,曾经参与Amazon RedShift分布式云数据仓库前身的核心技术研发,七年前加入DataStax,主要负责为财富500强大客户和战略合作伙伴提供咨询服务。对SQL和NoSQL数据库,以及相关的大数据产品都有比较丰富的实战经验。
谢谢前面Patrick、王锋、刘腾和米诺的精彩演讲。今天我们的其他几位嘉宾可以说是代表了中国互联网大厂里最具代表性的几家公司了。干货实在是太多了。我理解大家脑力消耗得差不多了,所以我尽量把最后的这四十分钟内容以讲故事的形式带给大家。希望大家能够在听故事的同时也得到一些收获。
我们这些故事里的几个主人公,有一些人要不就是曾经在我们Cassandra中文社区去年的活动里露脸过,要不就是跟我们去年活动里请来的嘉宾有过交集。我会在后面的故事里一一指出。请大家不要错过。
好了,闲话少说,我们一起来听故事!
01
极简Cassandra史
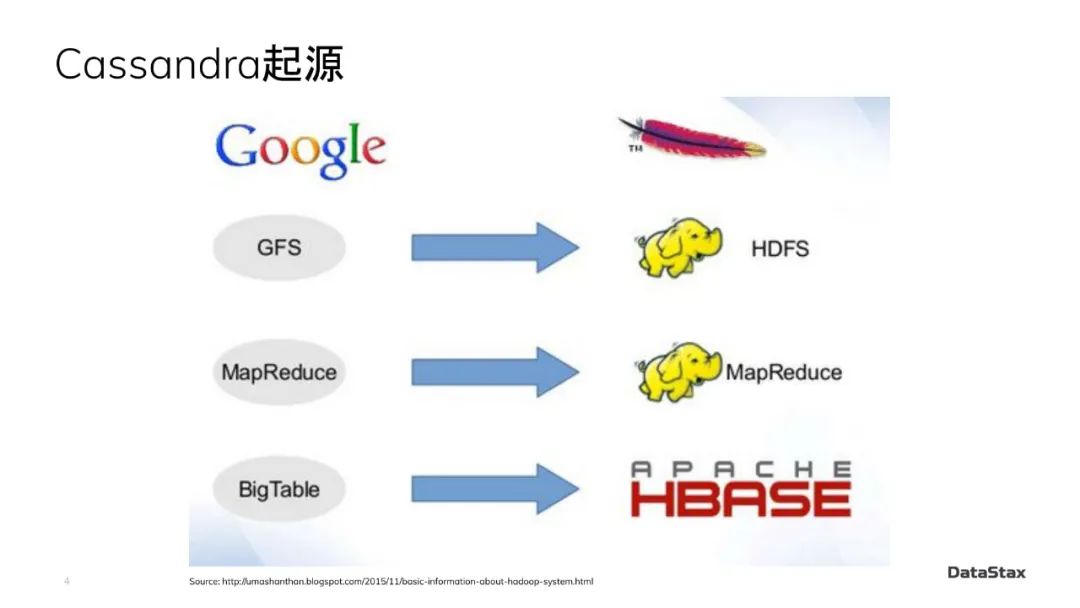
读过一些大数据相关文章的同学们可能都知道,在大数据发展历史上,谷歌有一个著名的“三驾马车”:GFS(Google File System)——谷歌文件系统,MapReduce——也就是Hadoop曾经最核心的计算框架(它在Hadoop的生态里面占据了如此重要的地位,以至于当年三大Hadoop商业公司,有一个就起名为MapR),然后就是我们今天故事的主角之一——BigTable。
这三驾马车都曾经扮演了非常重要的角色,但是有一点要指出的是,Google的这三驾马车,当年能给公众访问到的都只是研究论文,并没有把Google的具体实现发布出来。后来Apache Hadoop 开源生态圈里有对应的 Hadoop 文件系统 HDFS、Hadoop MapReduce 和 HBase,才终于把这些文章的威力在工业界充分发挥,带来了最近这十多年整个大数据产业的繁荣。
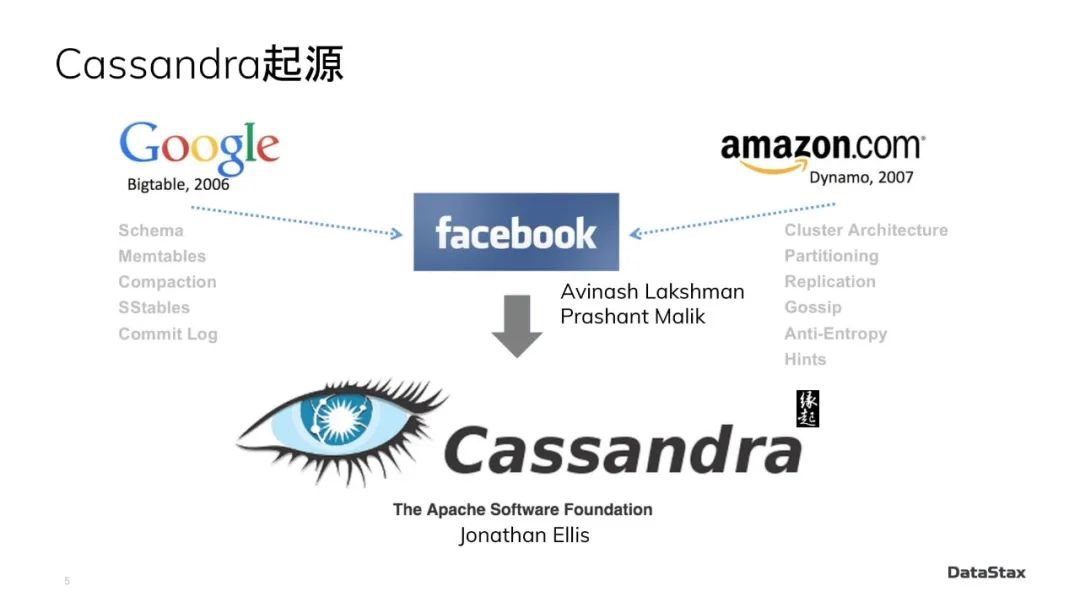
这张图里,只保留了Google BigTable放在左边,因为它仍然是我们这第一个故事的主角之一。如果熟悉Cassandra的同学,可能一眼就看出来了,左边它下面列出来的这些概念都是Cassandra里熟悉得不能再熟悉的东西了。Schema、Memtable、Compaction(也就是压实操作)、SSTable、Commitlog,等等。
其实这里还有一个大名鼎鼎的数据结构忘了写了,叫做LSM树,也就是Log Structured Merge Tree。在座的如果最近几年参加过面试的同学可能会记得,LSM树几乎是大厂一个必考的面试题。LSM树是1996年发明的,那这个十年之后的Bigtable文章提到它,也算是慧眼独具了。
因为之后有很多现在流行的数据库技术,包括Google自己的LevelDB,SQLite4, HBase, RocksDB, MongoDB 2014年收购的Wired Tiger,当然还有我们大名鼎鼎的今天的主角Cassandra,都是把LSM树作为核心的存储引擎使用的数据结构。我个人觉得,学好了LSM树,Cassandra运维方面就精通了一半。
对了,前面一张幻灯片里我提到BigTable一直都是Google的纸上谈兵,公众能接触到的只是论文。但是2015年Google云平台终于把BigTable作为一个大众可以购买的托管服务开放出来了。所以现在提到BigTable,已经不再只是一篇研究论文了。但是在我们这个示意图里,我们仍然默认它是2006年发表的那篇著名论文。
在大数据发展史上,还有一篇影响力几乎等同于谷歌“三驾马车”的论文。它就是亚马逊发布的Dynamo论文。右边下面列出来的概念,cluster peer-to-peer architecture, partitioning, replication, gossip, anti-entropy, hints对Cassandra运维比较熟悉的同学可能也是耳熟能详。
Dynamo是亚马逊2007的论文,在分布式系统领域非常有影响力,比如Eventual Consistency这个概念就是那篇文章里首次提出,更准确的说,就是通过它的宣传才流行起来的。因为2007年的年底 亚马逊的CTO Werner Vogels就发表了一篇叫 Eventually Consistent 的博文,应该算是互联网历史上访问量最大的博文之一吧,把这个概念在分布式系统的圈子里继续发扬光大了。
2008 年,Dynamo论文的作者之一Avinash Lakshman,从亚马逊跳槽去了Facebook。跳槽的Avinash和Facebook网站的另外一个工程师Prashant Malik,一起开发出来了Cassandra。而它的所有设计思想就像你在这个图里看到的一样,完完全全来自左边BigTable的论文再加上右边Dynamo的论文。这在当时是一个非常小清新的组合。
后来110多个NoSQL数据库里,只有Riak跟Cassandra的设计理念比较接近。可惜的是,Riak因为背后商业公司的倒闭,现在已经几乎没什么人用了。所以这个LSM树加上peer-to-peer,evntual consistency的组合,现在仍然还是Cassandra的一个比较独到的架构。同时你也可以看到Cassandra作为一个数据库,它的血统是非常纯正的,有着非常浓厚的学术背景。这也是为什么多伦多大学数据库研究组(算得上是数据库学术圈里的头牌了)当年对Cassandra也是非常青睐,2012年左右发表了很多Cassandra的研究文章。
Cassandra开发出来之后很快就被Facebook开源了。这个时候的Cassandra在Facebook还是被重用的,曾经是Facebook最核心网站背后的数据库。
我这里有一个小故事哦,Jonathan Ellis,也就是DataStax的现任CTO,当年曾经是开源Cassandra除了Avinash和Prashant两个发明人之外的主力程序员,尽管他并不是Facebook的雇员。他曾经因为一次Cassandra代码提交带来的兼容问题 直接把Facebook网站搞瘫痪。
这要放在现在可就是各大媒体争相报道的事故了,可能Facebook的市值都会一下蒸发掉几亿美金。十多年前Facebook还没有现在这么大,但是网站瘫痪了也至少会影响几千万的用户。
Jonathan现在跟我聊起这个故事,还是觉得很骄傲。因为如果他是Facebook雇员的话,也许就被开除了,但是他并没有为Facebook工作,是个社会青年。所以他很骄傲他自己应该是Facebook的非雇员里唯一一个成功把Facebook网站搞瘫的吧。
不过Avinash离开Facebook出来创业,给开源的Cassandra带来了一次非常重大的打击。这个打击甚至可以说是差点致命的。2008年的Facebook对于上图左边谷歌技术非常崇拜,但对于上图右边亚马逊的技术却有点缺乏信心。
于是当Facebook准备开发他们最重要的手机App “Facebook Messenger”的时候,因为Avinash已经人在曹营心在汉了,对技术决策不再有影响力,他们决定改用谷歌的技术架构。也就是说,Facebook抛弃了自己开发的数据库Cassandra,选择了当时在Hadoop系统里开源实现了BigTable设计的HBase。
Cassandra被亲手发明自己的公司抛弃,Facebook剩下的人也没什么兴趣继续开发了。我记得当时国内的知乎上也有一篇高赞的文章,把这个被Facebook弃用的事情作为Cassandra的一大罪状,还是影响了国内很多人技术选型的时候不再考虑Cassandra的。
那个时候HBase背靠着Hadoop这个高大上的平台,Cassandra就是一个乞丐版的宽表数据库。Cassandra的前景比较暗淡。不过,如果故事到此为止的话,那么Cassandra 然后估计也就没有然后了。故事到了这里,就该DataStax公司出场了。
02
DataStax的传奇故事
我们现在呢把这个故事的时间往前回到2008年,当时Jonathan Ellis和Matt Pfeil都已经在Rackspace工作了,对美国IT公司不太了解的同学,不一定听过这个公司。其实十多年前,公有云还没怎么起来的时候,Rackspace在工业界的地位比AWS还要高,它最为著名的就是OpenStack的那一套构建私有云的系统,跟Cassandra这套NoSQL的东西多少也有点关系。
DataStax官方的故事是这样的:Jonathan当时三十出头,是个很有能力的工程师,因为看到了Cassandra的巨大前景,决定辞职去创业。Matt作为Jonathan的经理,代表Rackspace去挽留他,于是两个人约了去一个廉价的泰国餐馆吃午餐;不过结局有点戏剧化,Matt没有说服Jonathan留下来继续为Rackspace工作,而当Jonathan告诉Matt他还缺一个CEO,Matt被说服了跟他一起创业。公司于2010年4月成立。
自从2010年大力开发和推广开源Cassandra以后,在很长一段时间里,DataStax在社区一直是推进Cassandra新功能和bug修复的主要力量。对Cassandra贡献的代码量,占据了整个Cassandra数据库内核代码主线提交量的85%以上。可以说,正是因为DataStax对这个开源项目的推动,才最终让Cassandra在遭受了Facebook弃用的重大打击以后也挺了过来,并且在一年之内成为了Apache软件基金会的TLP顶级开源项目。
说到这里,我还要解释一个国内IT届写的博客文章里经常搞错的概念,说Cassandra的一部分起源是DynamoDB。这是因为很多人经常会把Dynamo和DynamoDB混淆起来,其实这是两个完全不一样的东西。也就是说 Cassandra并不是从DynamoDB衍生出来的。大家现在听说的Amazon DynamoDB作为一个数据库产品,其实比Cassandra都晚了好几年。
这里还有一个比较好玩的小故事,2012年亚马逊发布DynamoDB的时候(注意这是原来的Dynamo2007那篇论文发表5年以后),Jonathan Ellis曾经写了一篇文章,现在你都还能在我们公司的官网上找到。他主要比较了新诞生的DynamoDB跟当时Cassandra功能完备程度,还有数据类型支持,当然那时候Cassandra是完爆DynamoDB了。
好玩的是,他在文章最后宣称:以一个极客的眼光来看,我很高兴看到这么多的Cassandra的设计考量都被Amazon的这个新的NoSQL产品模仿了。I feel like a proud uncle!说很自豪自己是DynamoDB的叔叔。妥妥的占了一把DynamoDB的便宜。西方有一句谚语:模仿是最好的表扬。他大概是因为这个感到自豪吧。
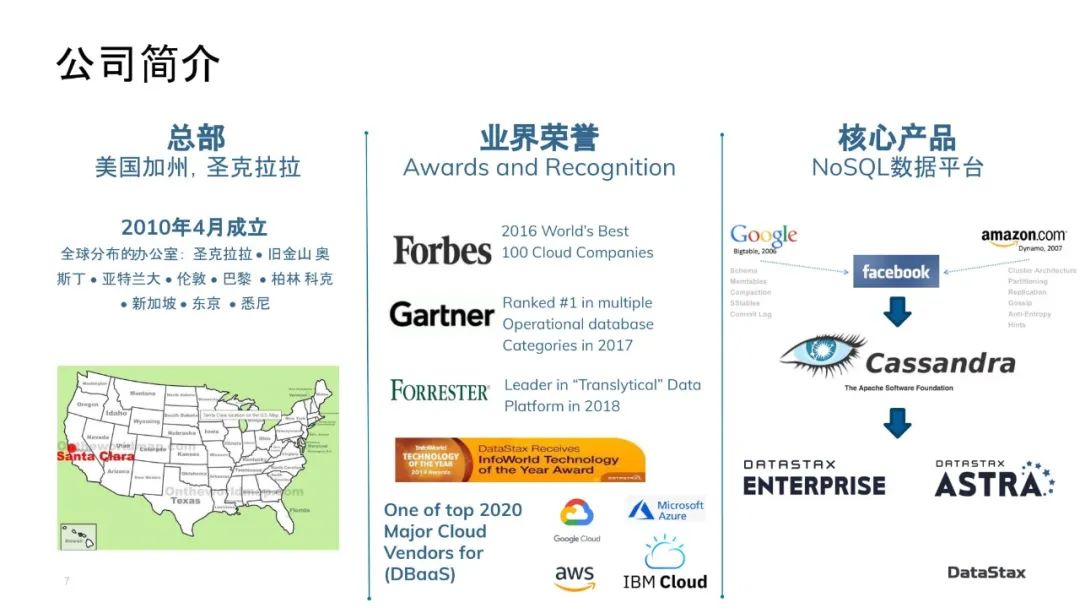
我刚才提过,DataStax是2010年4月成立的。我们现在的总部是在美国加州Santa Clara,但是在全世界四大洲十一个城市都有办公室。
DataStax是一个优先照顾远程办公的公司,除了在这十一个办公室上班的同事,我们其实超过70%的人都是在家上班的。这个remote working作为公司的文化和传统是从当年Jonathan创建公司的时候就流传下来的,已经延续了十多年了,所以去年年初疫情席卷了全球的时候,我们公司的正常运营基本上没有受到影响。只是安排了原来去办公室的一小部分同事开始全时在家上班。
至于我们这些经常出差跟客户打交道的,当我们分布全球的客户也开始转向线上会议、几乎所有的商业会谈都能正常进行以后,正常的工作也就完全恢复了。公司的运转就跟之前十年里的任何一年没有什么区别了。
我们的核心产品是基于Cassandra的NoSQL数据平台。首先我们在开源Apache Cassandra的代码里贡献量最大,下一张幻灯片我会提到一些统计数据;并且我们为整个Cassandra开源社区提供了很多的免费工具、文档、培训内容。
然后我们在开源Cassandra内核的基础之上为我们的客户提供商业版的DataStax Enterprise,从多模、安全、自动管理运维和监控方面提供了很多企业需要的功能。
去年我们也正式发布了DataStax Astra,也就是我们的云原生Cassandra托管平台,让所有想要在Cassandra基础上开发应用程序的开发人员非常容易就能上手使用。作为开发人员,这个平台可以免费开始使用free-tier,只要你有一个电子邮箱注册账号;作为企业,如果需要我们在我们的托管平台上帮你自动化运维你生产环境的Cassandra数据库,我们也可以发挥我们的规模效应,很经济的帮你托管。
DataStax财务上的表现,有很多具体的数据我不能说,但是可以提一些公开的资料。Crunchbase网站上几乎可以查到所有初创公司的公开的财务数据。这里大家可以看到,DataStax是E轮的startup,总共VC funding的额度是1.9亿美金。
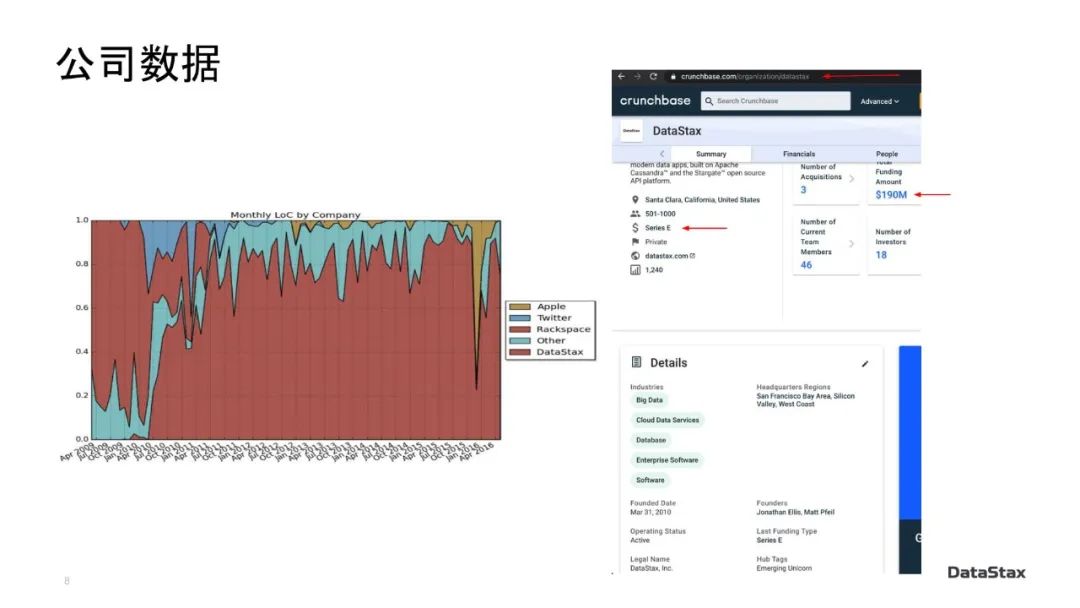
但是我们属于已经不再需要风险投资烧钱支持下去的公司,因为,大家可能会注意到我们的E轮是2014年拿到的,也就是说在过去的6年多的时间里,我们再也没有需要从VC拿钱,所以财务状况上是非常稳健的。至于右下角这个unicorn的标注呢,我就不方便发表意见了。

DataStax提供的企业版的Cassandra其实在全世界很多知名品牌都在使用,设计了很多不同的行业,包括:能源、金融服务、运输/物流、媒体/电信、零售/餐饮、科技/互联网,等等。这里面有很多财富前100强的跨国大公司。Cassandra数据库的不少优秀特质使得这些世界知名品牌都把Cassandra使用在最关键的生产环境中。
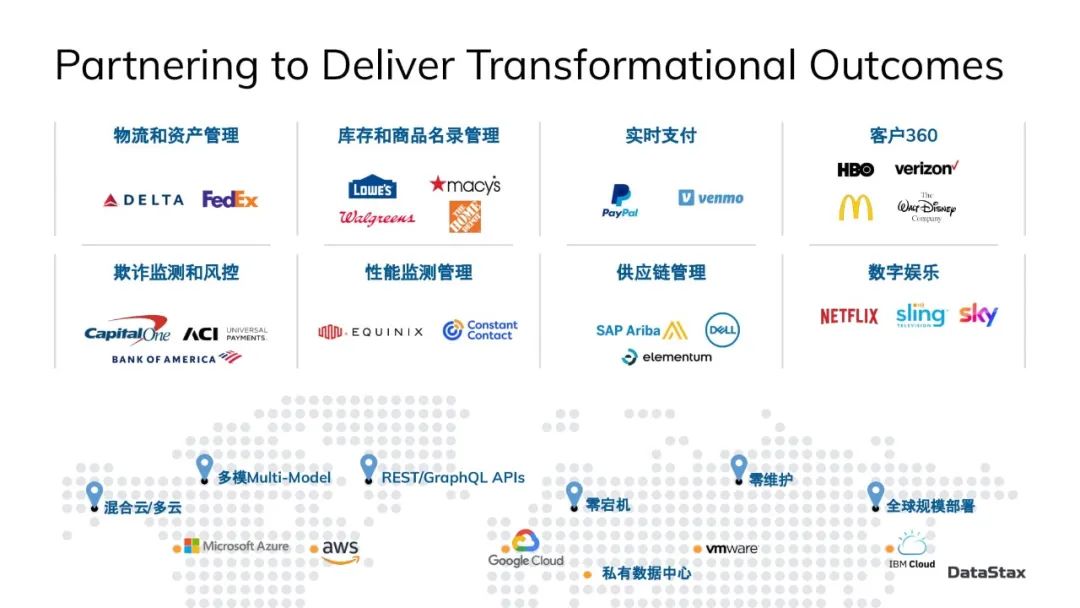
这张幻灯片里是DataStax的大客户里使用Cassandra比较典型的一些应用场景:物流和资产管理、库存和商品名录管理、实时支付、客户360、欺诈监测和风控、性能监测管理、供应链管理、数字娱乐。这里有很多在中国的朋友也耳熟能详的品牌,比如联邦快递、梅西百货、麦当劳、迪士尼、美洲银行、戴尔、网飞 等等。
03
国际社区现状
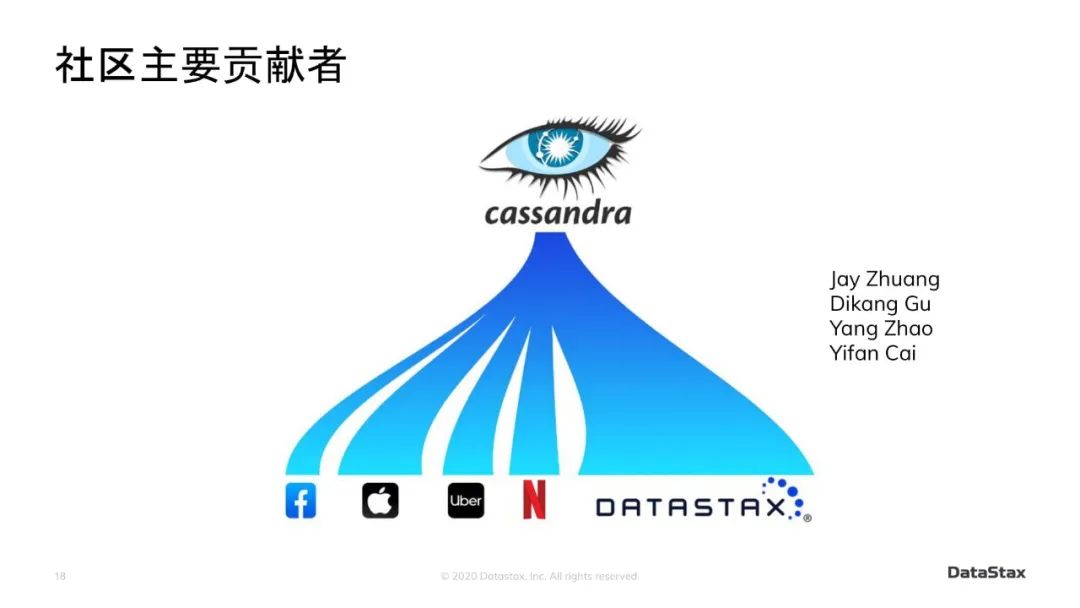
我现在再来讲一下Cassandra国际社区的现状。现在Cassandra内核源码方面主要的贡献者为这几个公司工作:DataStax、苹果、Netflix、Facebook / Instagram、Uber、Twitter、Yahoo Japan等等。
前面“公司数据”那张ppt中的左图,是2016年时有人在github的Apache Cassandra repository上根据提交人的公司归属做的一个统计。你在这里可以看到DataStax、苹果、推特、Rackspace的雇员贡献了大多数代码提交,但是DataStax员工的贡献(以红色标记)占据了最大的比例。超过85%的代码提交是由DataStax员工完成的。
开发一个分布式数据库并熟知它的内核的复杂性的资深开发人员并不容易找到,当时做这个统计的时候他们一共算出了140个代码贡献者,其中为DataStax工作的只有20人(也就是15%左右),但是这20人是85%的最终被接受的代码的直接作者。
作为我个人在DataStax工作了七年多的感受,这也是我觉得非常幸运的地方。很多时候我为客户做咨询和排除故障的时候,如果碰到疑难杂症,我有信心可以找到我们的开发同事帮我排查源码中的问题,最终一定能解决。
而也正是因为身边随时能找到非常优秀的同事这一点,在DataStax只要你在技术上肯学,即使你一开始从一个很初级的客服工程师做起,也可以在很短时间内成为客户眼里的专家。因为我们的技术团队聚集了很多这样的同事。
财富前一百强里有超过40%的大型跨国公司都是我们的客户,因为他们可以信赖我们公司在Cassandra方面的专业知识。
值得一提的是,我们在Apache Cassandra Committer里已经有了好几个中国人了,比如Uber的Jay Zhuang(现在去了Facebook),Facebook/Instagram的Dikang Gu,苹果的Yifan Cai,还有DataStax的Yang Zhao。希望将来能看到中国对Cassandra有深入研究的专家也能加入到Committer的行列,在国际社区带来更多的影响。
另外,除了刚刚讲的这些对Cassandra已经非常精通的个人和公司给社区带来的活力和贡献,另一方面,不断的拓展Cassandra在整个世界的开发者群体中的知名度和影响力,让更多的人知道Cassandra,新手能够学到最新的Cassandra的知识,也是DataStax去年的一个着重发力的方向。
这里是我们去年夏天的一个8周的Cassandra Bootcamp的一些统计数据,虽然没有包括去年全年的社区活动的数据,但是管中窥豹,可见一斑。
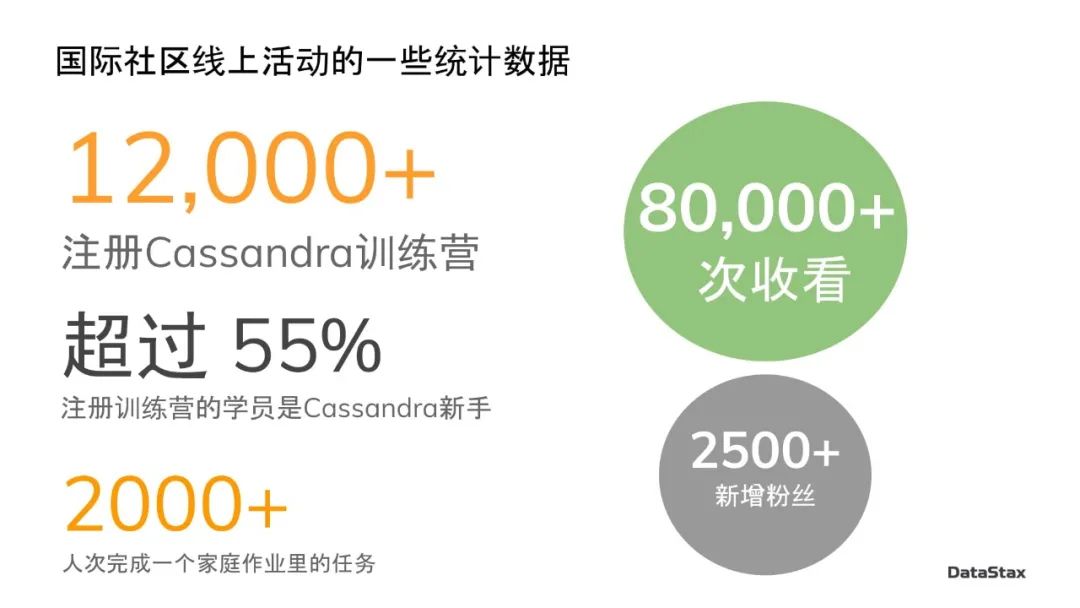
由于篇幅限制,本文仅截取部分演讲内容。
点击文末“阅读原文”查看本次演讲的完整视频录像。
本文内容版权归DataStax所有
未经书面允许禁止转载
推荐阅读

DataStax在中国
技术资讯 | 行业动态 | 活动信息
阅读这篇文章有收获?
请通过点赞、分享和在看告诉我们