




开源之夏公众号持续欢迎大家分享项目经验,开源心得!
投稿方式:
E-mail :summer@iscas.ac.cn
or 关注公众号,后台回复“投稿”

基于MindSpore的实现在线手写汉字识别,主要包括手写汉字检测和手写汉字识别,能较准确的对标准字体的手写文字进行识别,识别后通过人工干预对文本进行适当修正。需要有一定的创新特性,代码达到合入社区标准及规范。
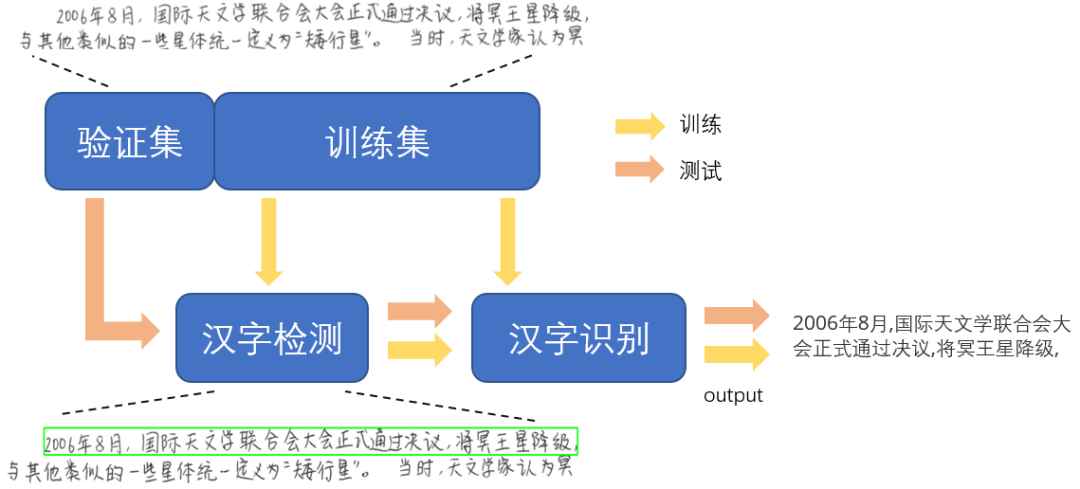
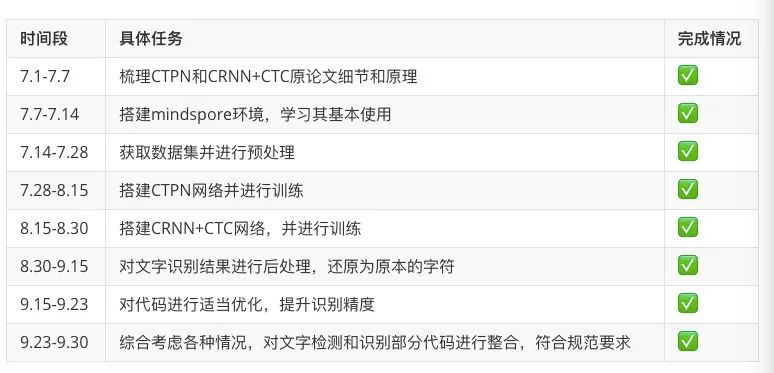
按照时间进度安排,圆满完成任务,通过CTPN网络实现文本检测,CRNN+CTCLoss实现文本识别,并将两者结合, 实现端到端的汉字识别。最后并将代码合并到社区。

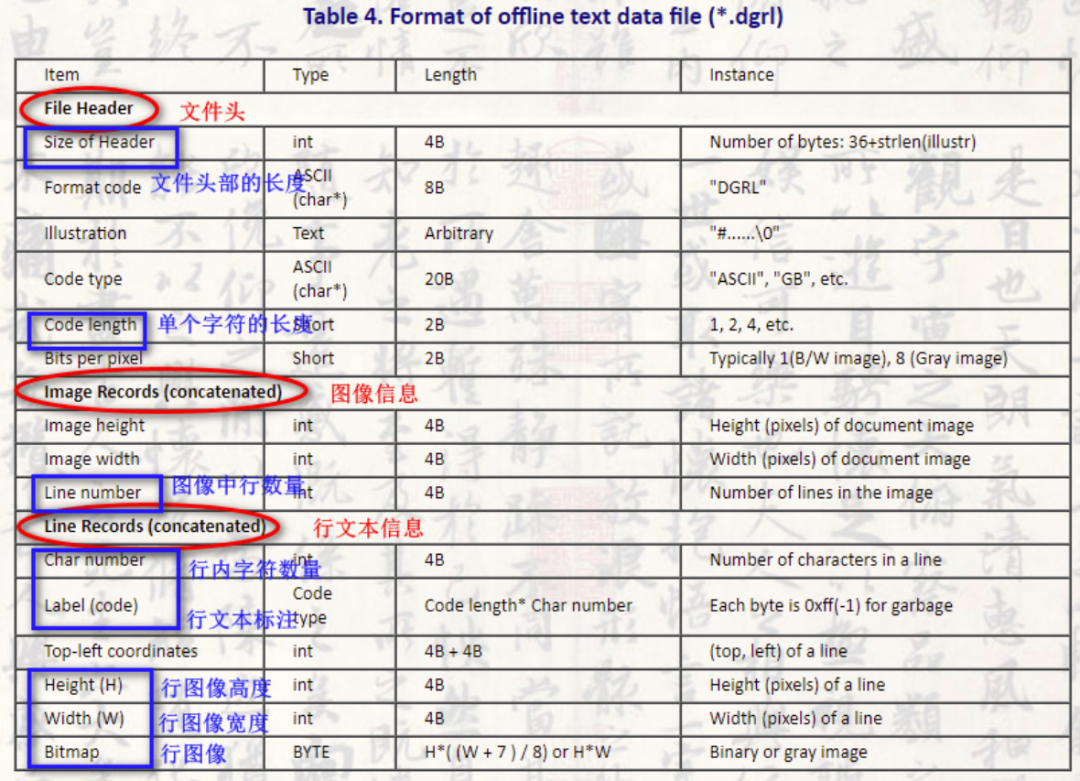
.dgrl需要对该文本进行解析,转换为训练需要的图片格式和label格式。此外,由于该数据集保存的是每一行的文本图片,为了进行文本检测任务我们需要将每一行拼接成一页的文本图片。
f = open(dgrl, 'rb')
之后使用numpy进行依次读取,注意是一个一个Byte依次读取,需要指定读取的格式和数量
import numpy as npnp.fromfile(f, dtype='uint8', count=4)
一般 dtype 都选择 uint8,count 需要根据上图结构中的长度 Length 做相应变化。
要注意的一个地方是:行文本标注读取出来以后,是一个 int 列表,要把它还原成汉字,一个汉字占用两个字节(具体由 code_length 决定),使用 struct 将其还原:
struct.pack('I', i).decode('gbk', 'ignore')[0]
上面的 i
就是提取出来的汉字编码,解码格式为 gbk
,有些行文本会有空格,解码可能会出错,使用 ignore
忽略。
得到的坐标为每个矩形框的坐标。保存文件为 .jpg
的图像格式
import structimport osimport cv2 as cvimport numpy as npdef read_from_dgrl(dgrl):if not os.path.exists(dgrl):print('DGRL not exis!')returndir_name,base_name = os.path.split(dgrl)label_dir = dir_name+'_label'image_dir = dir_name+'_images'if not os.path.exists(label_dir):os.makedirs(label_dir)if not os.path.exists(image_dir):os.makedirs(image_dir)with open(dgrl, 'rb') as f:# 读取表头尺寸header_size = np.fromfile(f, dtype='uint8', count=4)header_size = sum([j<<(i*8) for i,j in enumerate(header_size)])# print(header_size)# 读取表头剩下内容,提取 code_lengthheader = np.fromfile(f, dtype='uint8', count=header_size-4)code_length = sum([j<<(i*8) for i,j in enumerate(header[-4:-2])])# print(code_length)# 读取图像尺寸信息,提取图像中行数量image_record = np.fromfile(f, dtype='uint8', count=12)height = sum([j<<(i*8) for i,j in enumerate(image_record[:4])])width = sum([j<<(i*8) for i,j in enumerate(image_record[4:8])])line_num = sum([j<<(i*8) for i,j in enumerate(image_record[8:])])print('图像尺寸:')print(height, width, line_num)# 读取每一行的信息for k in range(line_num):print(k+1)# 读取该行的字符数量char_num = np.fromfile(f, dtype='uint8', count=4)char_num = sum([j<<(i*8) for i,j in enumerate(char_num)])print('字符数量:', char_num)# 读取该行的标注信息label = np.fromfile(f, dtype='uint8', count=code_length*char_num)label = [label[i]<<(8*(i%code_length)) for i in range(code_length*char_num)]label = [sum(label[i*code_length:(i+1)*code_length]) for i in range(char_num)]label = [struct.pack('I', i).decode('gbk', 'ignore')[0] for i in label]print('合并前:', label)label = ''.join(label)label = ''.join(label.split(b'\x00'.decode())) # 去掉不可见字符 \x00,这一步不加的话后面保存的内容会出现看不见的问题print('合并后:', label)# 读取该行的位置和尺寸pos_size = np.fromfile(f, dtype='uint8', count=16)y = sum([j<<(i*8) for i,j in enumerate(pos_size[:4])])x = sum([j<<(i*8) for i,j in enumerate(pos_size[4:8])])h = sum([j<<(i*8) for i,j in enumerate(pos_size[8:12])])w = sum([j<<(i*8) for i,j in enumerate(pos_size[12:])])# print(x, y, w, h)# 读取该行的图片bitmap = np.fromfile(f, dtype='uint8', count=h*w)bitmap = np.array(bitmap).reshape(h, w)# 保存信息label_file = os.path.join(label_dir, base_name.replace('.dgrl', '_'+str(k)+'.txt'))with open(label_file, 'w') as f1:f1.write(label)bitmap_file = os.path.join(image_dir, base_name.replace('.dgrl', '_'+str(k)+'.jpg'))cv.imwrite(bitmap_file, bitmap)

根据上一步得到的数据可以发现,每一完整页的汉字前缀为 006-P16_*
的形式,下划线后表示每行,如果需要拼接为整页只要将相同前缀按照顺序拼接即可。下面对于图片和label的拼接和生成进行分别说明。
006-P16_*的形式,下划线后表示每行,如果需要拼接为整页只要将相同前缀按照顺序拼接即可。下面对于图片和label的拼接和生成进行分别说明。

import numpy as npimport cv2import osfrom glob import globimport refrom tqdm import tqdmdef get_char_nums(segments):nums = []chars = []for seg in segments:label_head = seg.split('.')[0]label_name = label_head + '.txt'with open(os.path.join(label_root,label_name), 'r', encoding='utf-8') as f:lines = f.readlines()nums.append(len(lines[0]))chars.append(lines[0])return nums, charsdef addZeros(s_):head, tail = s_.split('_')num = ''.join(re.findall(r'\d',tail))head_num = '0'*(4-len(num)) + numreturn head + '_' + head_num + '.jpg'def strsort(alist):alist.sort(key=lambda i:addZeros(i))return alistdef pad(img, headpad, padding):assert padding>=0if padding>0:logi_matrix = np.where(img > 255*0.95, np.ones_like(img), np.zeros_like(img))ids = np.where(np.sum(logi_matrix, 0) == img.shape[0])if ids[0].tolist() != []:pad_array = np.tile(img[:,ids[0].tolist()[-1],:], (1, padding)).reshape((img.shape[0],-1,3))else:pad_array = np.tile(np.ones_like(img[:, 0, :]) * 255, (1, padding)).reshape((img.shape[0], -1, 3))if headpad:return np.hstack((pad_array, img))else:return np.hstack((img, pad_array))else:return imgdef pad_peripheral(img, pad_size):assert isinstance(pad_size,tuple)w, h = pad_sizeresult = cv2.copyMakeBorder(img, h, h, w, w, cv2.BORDER_CONSTANT, value=[255, 255, 255])return resultif __name__ == '__main__':label_roots = ['./labels']label_dets = ['./fulllabels']pages_roots = ['./images']pages_dets = ['./fullimages']for label_root, label_det, pages_root, pages_det in zip(label_roots, label_dets, pages_roots, pages_dets):os.makedirs(label_det, exist_ok=True)os.makedirs(pages_det, exist_ok=True)pages_for_set = os.listdir(pages_root)pages_set = set([pfs.split('_')[0] for pfs in pages_for_set])for ds in tqdm(pages_set):boxes = []pages = []seg_sorted = strsort([d for d in pages_for_set if ds in d])widths = [cv.imread(os.path.join(pages_root, d)).shape[1] for d in seg_sorted]heights = [cv.imread(os.path.join(pages_root, d)).shape[0] for d in seg_sorted]max_width = max(widths)seg_nums, chars = get_char_nums(seg_sorted)pad_size = (500, 1000)w, h = pad_sizelabel_name = ds + '.txt'with open(os.path.join(label_det, label_name), 'w') as f:for i, pg in enumerate(seg_sorted):headpad = True if i == 0 else True if seg_nums[i] - seg_nums[i - 1] > 5 else Falsepg_read = cv.imread(os.path.join(pages_root, pg))padding = max_width - pg_read.shape[1]page_new = pad(pg_read, headpad, padding)pages.append(page_new)if headpad:x1 = str(w + padding)x2 = str(w + max_width)y1 = str(h + sum(heights[:i + 1]) - heights[i])y2 = str(h + sum(heights[:i + 1]))box = np.array([int(x1), int(y1), int(x2), int(y1), int(x2), int(y2), int(x1), int(y2)])else:x1 = str(w)x2 = str(w + max_width - padding)y1 = str(h + sum(heights[:i + 1]) - heights[i])y2 = str(h + sum(heights[:i + 1]))box = np.array([int(x1), int(y1), int(x2), int(y1), int(x2), int(y2), int(x1), int(y2)])boxes.append(box.reshape((4, 2)))char = chars[i]f.writelines(x1 + ',' + y1 + ',' + x2 + ',' + y1 + ',' + x2 + ',' + y2 + ',' + x1 + ',' + y2 + ',' + char + '\n')pages_array = np.vstack(pages)pages_array = pad_peripheral(pages_array, pad_size)pages_name = ds + '.jpg'# cv.polylines(pages_array, [box.astype('int32') for box in boxes], True, (0, 0, 255))cv.imwrite(os.path.join(pages_det, pages_name), pages_array)
做完了以上准备工作,下面开始分别对手写汉字进行文本检测和文本识别的网络进行搭建和训练。
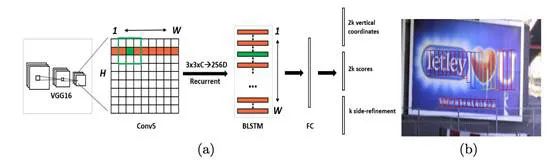
class CTPN(nn.Cell):"""Define CTPN networkArgs:input_size(int): Size of time sequence. Usually, the input_size is equal to three times of image height forcaptcha images.batch_size(int): batch size of input data, default is 64hidden_size(int): the hidden size in LSTM layers, default is 512"""def __init__(self, config, is_training=True):super(CTPN, self).__init__()self.config = configself.is_training = is_trainingself.num_step = config.num_stepself.input_size = config.input_sizeself.batch_size = config.batch_sizeself.hidden_size = config.hidden_sizeself.vgg16_feature_extractor = VGG16FeatureExtraction()self.conv = nn.Conv2d(512, 512, kernel_size=3, padding=0, pad_mode='same')self.rnn = BiLSTM(self.config, is_training=self.is_training).to_float(mstype.float16)self.reshape = P.Reshape()self.transpose = P.Transpose()self.cast = P.Cast()# rpn blockself.rpn_with_loss = RPN(config,self.batch_size,config.rpn_in_channels,config.rpn_feat_channels,config.num_anchors,config.rpn_cls_out_channels)self.anchor_generator = AnchorGenerator(config)self.featmap_size = config.feature_shapesself.anchor_list = self.get_anchors(self.featmap_size)self.proposal_generator_test = Proposal(config,config.test_batch_size,config.activate_num_classes,config.use_sigmoid_cls)self.proposal_generator_test.set_train_local(config, False)def construct(self, img_data, gt_bboxes, gt_labels, gt_valids, img_metas=None):x = self.vgg16_feature_extractor(img_data)x = self.conv(x)x = self.cast(x, mstype.float16)x = self.transpose(x, (0, 2, 1, 3))x = self.reshape(x, (-1, self.input_size, self.num_step))x = self.transpose(x, (2, 0, 1))x = self.rnn(x)rpn_loss, cls_score, bbox_pred, rpn_cls_loss, rpn_reg_loss = self.rpn_with_loss(x, gt_valids)if self.training:return rpn_loss, cls_score, bbox_pred, rpn_cls_loss, rpn_reg_lossproposal, proposal_mask = self.proposal_generator_test(cls_score, bbox_pred, self.anchor_list)return proposal, proposal_maskdef get_anchors(self, featmap_size):anchors = self.anchor_generator.grid_anchors(featmap_size)return Tensor(anchors, mstype.float16)class CTPN_Infer(nn.Cell):def __init__(self, config):super(CTPN_Infer, self).__init__()self.network = CTPN(config, is_training=False)self.network.set_train(False)def construct(self, img_data):output = self.network(img_data, None, None, None, None)return output
./ctpn.py中
class BiLSTM(nn.Cell):"""Define a BiLSTM network which contains two LSTM layersArgs:input_size(int): Size of time sequence. Usually, the input_size is equal to three times of image height forcaptcha images.batch_size(int): batch size of input data, default is 64hidden_size(int): the hidden size in LSTM layers, default is 512"""def __init__(self, config, is_training=True):super(BiLSTM, self).__init__()self.is_training = is_trainingself.batch_size = config.batch_size * config.rnn_batch_sizeprint("batch size is {} ".format(self.batch_size))self.input_size = config.input_sizeself.hidden_size = config.hidden_sizeself.num_step = config.num_stepself.reshape = P.Reshape()self.cast = P.Cast()k = (1 / self.hidden_size) ** 0.5self.rnn1 = P.DynamicRNN(forget_bias=0.0)self.rnn_bw = P.DynamicRNN(forget_bias=0.0)self.w1 = Parameter(np.random.uniform(-k, k, \(self.input_size + self.hidden_size, 4 * self.hidden_size)).astype(np.float32), name="w1")self.w1_bw = Parameter(np.random.uniform(-k, k, \(self.input_size + self.hidden_size, 4 * self.hidden_size)).astype(np.float32), name="w1_bw")self.b1 = Parameter(np.random.uniform(-k, k, (4 * self.hidden_size)).astype(np.float32), name="b1")self.b1_bw = Parameter(np.random.uniform(-k, k, (4 * self.hidden_size)).astype(np.float32), name="b1_bw")self.h1 = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.h1_bw = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.c1 = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.c1_bw = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.reverse_seq = P.ReverseV2(axis=[0])self.concat = P.Concat()self.transpose = P.Transpose()self.concat1 = P.Concat(axis=2)self.dropout = nn.Dropout(0.7)self.use_dropout = config.use_dropoutself.reshape = P.Reshape()self.transpose = P.Transpose()def construct(self, x):if self.use_dropout:x = self.dropout(x)x = self.cast(x, mstype.float16)bw_x = self.reverse_seq(x)y1, _, _, _, _, _, _, _ = self.rnn1(x, self.w1, self.b1, None, self.h1, self.c1)y1_bw, _, _, _, _, _, _, _ = self.rnn_bw(bw_x, self.w1_bw, self.b1_bw, None, self.h1_bw, self.c1_bw)y1_bw = self.reverse_seq(y1_bw)output = self.concat1((y1, y1_bw))return output
RPN与Faster-RCNN类似,便不再赘述
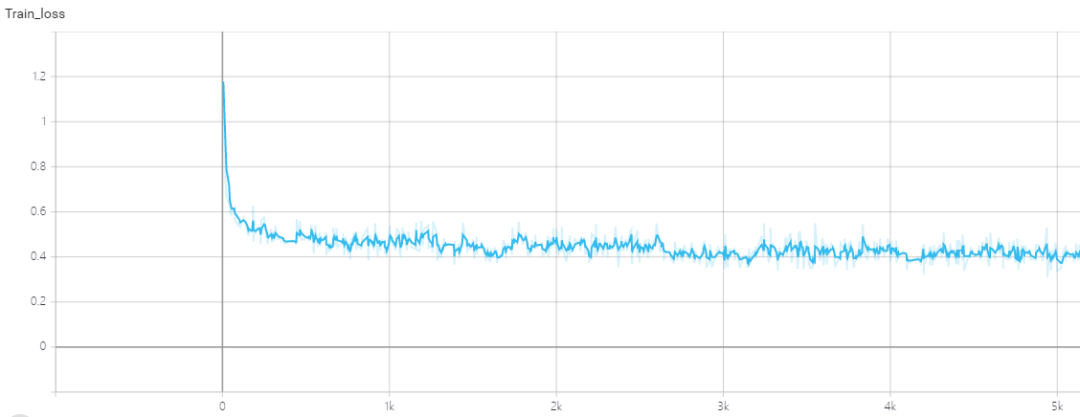
epoch: 100 step: 1467, rpn_loss: 0.02794, rpn_cls_loss: 0.01963, rpn_reg_loss: 0.01110

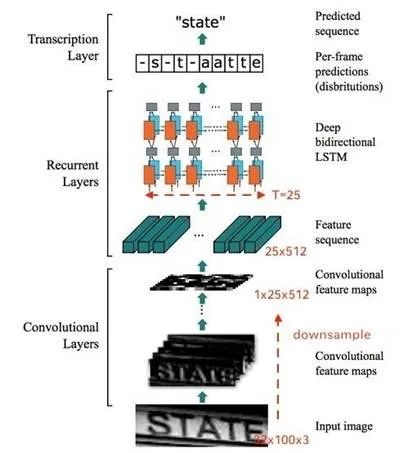
"""crnn_ctc network define"""import numpy as npimport mindspore.nn as nnfrom mindspore import Tensor, Parameterfrom mindspore.common import dtype as mstypefrom mindspore.ops import operations as Pfrom mindspore.ops import functional as Ffrom mindspore.common.initializer import TruncatedNormaldef _bn(channel):return nn.BatchNorm2d(channel, eps=1e-4, momentum=0.9, gamma_init=1, beta_init=0, moving_mean_init=0,moving_var_init=1)class Conv(nn.Cell):def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, use_bn=False, pad_mode='same'):super(Conv, self).__init__()self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=stride,padding=0, pad_mode=pad_mode, weight_init=TruncatedNormal(0.02))self.bn = _bn(out_channel)self.Relu = nn.ReLU()self.use_bn = use_bndef construct(self, x):out = self.conv(x)if self.use_bn:out = self.bn(out)out = self.Relu(out)return outclass VGG(nn.Cell):"""VGG Network structure"""def __init__(self, is_training=True):super(VGG, self).__init__()self.conv1 = Conv(3, 64, use_bn=True)self.conv2 = Conv(64, 128, use_bn=True)self.conv3 = Conv(128, 256, use_bn=True)self.conv4 = Conv(256, 256, use_bn=True)self.conv5 = Conv(256, 512, use_bn=True)self.conv6 = Conv(512, 512, use_bn=True)self.conv7 = Conv(512, 512, kernel_size=2, pad_mode='valid', use_bn=True)self.maxpool2d1 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='same')self.maxpool2d2 = nn.MaxPool2d(kernel_size=(2, 1), stride=(2, 1), pad_mode='same')# self.maxpool2d2 = nn.MaxPool2d(kernel_size=(1, 2), stride=(2, 1), pad_mode='same')self.bn1 = _bn(512)def construct(self, x):x = self.conv1(x)x = self.maxpool2d1(x)x = self.conv2(x)x = self.maxpool2d1(x)x = self.conv3(x)x = self.conv4(x)x = self.maxpool2d2(x)x = self.conv5(x)x = self.conv6(x)x = self.maxpool2d2(x)x = self.conv7(x)return xclass CRNN(nn.Cell):"""Define a CRNN network which contains Bidirectional LSTM layers and vgg layer.Args:input_size(int): Size of time sequence. Usually, the input_size is equal to three times of image height fortext images.batch_size(int): batch size of input data, default is 64hidden_size(int): the hidden size in LSTM layers, default is 512"""def __init__(self, config):super(CRNN, self).__init__()self.batch_size = config.batch_sizeself.input_size = config.input_sizeself.hidden_size = config.hidden_sizeself.num_classes = config.class_numself.reshape = P.Reshape()self.cast = P.Cast()k = (1 / self.hidden_size) ** 0.5self.rnn1 = P.DynamicRNN(forget_bias=0.0)self.rnn1_bw = P.DynamicRNN(forget_bias=0.0)self.rnn2 = P.DynamicRNN(forget_bias=0.0)self.rnn2_bw = P.DynamicRNN(forget_bias=0.0)w1 = np.random.uniform(-k, k, (self.input_size + self.hidden_size, 4 * self.hidden_size))self.w1 = Parameter(w1.astype(np.float32), name="w1")w2 = np.random.uniform(-k, k, (2 * self.hidden_size + self.hidden_size, 4 * self.hidden_size))self.w2 = Parameter(w2.astype(np.float32), name="w2")w1_bw = np.random.uniform(-k, k, (self.input_size + self.hidden_size, 4 * self.hidden_size))self.w1_bw = Parameter(w1_bw.astype(np.float32), name="w1_bw")w2_bw = np.random.uniform(-k, k, (2 * self.hidden_size + self.hidden_size, 4 * self.hidden_size))self.w2_bw = Parameter(w2_bw.astype(np.float32), name="w2_bw")self.b1 = Parameter(np.random.uniform(-k, k, (4 * self.hidden_size)).astype(np.float32), name="b1")self.b2 = Parameter(np.random.uniform(-k, k, (4 * self.hidden_size)).astype(np.float32), name="b2")self.b1_bw = Parameter(np.random.uniform(-k, k, (4 * self.hidden_size)).astype(np.float32), name="b1_bw")self.b2_bw = Parameter(np.random.uniform(-k, k, (4 * self.hidden_size)).astype(np.float32), name="b2_bw")self.h1 = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.h2 = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.h1_bw = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.h2_bw = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.c1 = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.c2 = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.c1_bw = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.c2_bw = Tensor(np.zeros(shape=(1, self.batch_size, self.hidden_size)).astype(np.float32))self.fc_weight = np.random.random((self.num_classes, self.hidden_size)).astype(np.float32)self.fc_bias = np.random.random((self.num_classes)).astype(np.float32)self.fc = nn.Dense(in_channels=self.hidden_size, out_channels=self.num_classes,weight_init=Tensor(self.fc_weight), bias_init=Tensor(self.fc_bias))self.fc.to_float(mstype.float32)self.expand_dims = P.ExpandDims()self.concat = P.Concat()self.transpose = P.Transpose()self.squeeze = P.Squeeze(axis=0)self.vgg = VGG()self.reverse_seq1 = P.ReverseSequence(batch_dim=1, seq_dim=0)self.reverse_seq2 = P.ReverseSequence(batch_dim=1, seq_dim=0)self.reverse_seq3 = P.ReverseSequence(batch_dim=1, seq_dim=0)self.reverse_seq4 = P.ReverseSequence(batch_dim=1, seq_dim=0)self.seq_length = Tensor(np.ones((self.batch_size), np.int32) * config.num_step, mstype.int32)self.concat1 = P.Concat(axis=2)self.dropout = nn.Dropout(0.5)self.rnn_dropout = nn.Dropout(0.9)self.use_dropout = config.use_dropoutdef construct(self, x):x = self.vgg(x)shape1 = x.shapex = self.reshape(x, (self.batch_size, self.input_size, -1))x = self.transpose(x, (2, 0, 1))bw_x = self.reverse_seq1(x, self.seq_length)y1, _, _, _, _, _, _, _ = self.rnn1(x, self.w1, self.b1, None, self.h1, self.c1)y1_bw, _, _, _, _, _, _, _ = self.rnn1_bw(bw_x, self.w1_bw, self.b1_bw, None, self.h1_bw, self.c1_bw)y1_bw = self.reverse_seq2(y1_bw, self.seq_length)y1_out = self.concat1((y1, y1_bw))if self.use_dropout:y1_out = self.rnn_dropout(y1_out)y2, _, _, _, _, _, _, _ = self.rnn2(y1_out, self.w2, self.b2, None, self.h2, self.c2)bw_y = self.reverse_seq3(y1_out, self.seq_length)y2_bw, _, _, _, _, _, _, _ = self.rnn2(bw_y, self.w2_bw, self.b2_bw, None, self.h2_bw, self.c2_bw)y2_bw = self.reverse_seq4(y2_bw, self.seq_length)y2_out = self.concat1((y2, y2_bw))if self.use_dropout:y2_out = self.dropout(y2_out)output = ()for i in range(F.shape(y2_out)[0]):y2_after_fc = self.fc(self.squeeze(y2[i:i+1:1]))y2_after_fc = self.expand_dims(y2_after_fc, 0)output += (y2_after_fc,)output = self.concat(output)return output# return output, shape1, x.shape, y1_out.shape, y2_out.shape, y2_after_fc.shapedef crnn(config, full_precision=False):"""Create a CRNN network with mixed_precision or full_precision"""net = CRNN(config)if not full_precision:net = net.to_float(mstype.float16)return net
'''Date: 2021-09-05 14:53:34LastEditors: xgyLastEditTime: 2021-09-25 22:45:07FilePath: \code\crnn_ctc\src\loss.py'''"""CTC Loss."""import numpy as npfrom mindspore.nn.loss.loss import _Lossfrom mindspore import Tensor, Parameterfrom mindspore.common import dtype as mstypefrom mindspore.ops import operations as Pclass CTCLoss(_Loss):"""CTCLoss definitionArgs:max_sequence_length(int): max number of sequence length. For text images, the value is equal to image widthmax_label_length(int): max number of label length for each input.batch_size(int): batch size of input logits"""def __init__(self, max_sequence_length, max_label_length, batch_size):super(CTCLoss, self).__init__()self.sequence_length = Parameter(Tensor(np.array([max_sequence_length] * batch_size), mstype.int32),name="sequence_length")labels_indices = []for i in range(batch_size):for j in range(max_label_length):labels_indices.append([i, j])self.labels_indices = Parameter(Tensor(np.array(labels_indices), mstype.int64), name="labels_indices")self.reshape = P.Reshape()self.ctc_loss = P.CTCLoss(ctc_merge_repeated=True)def construct(self, logit, label):labels_values = self.reshape(label, (-1,))loss, _ = self.ctc_loss(logit, self.labels_indices, labels_values, self.sequence_length)return loss

识别结果如图所示,能基本正确识别图像中的文本( ::
左边为label,右边为预测结果)

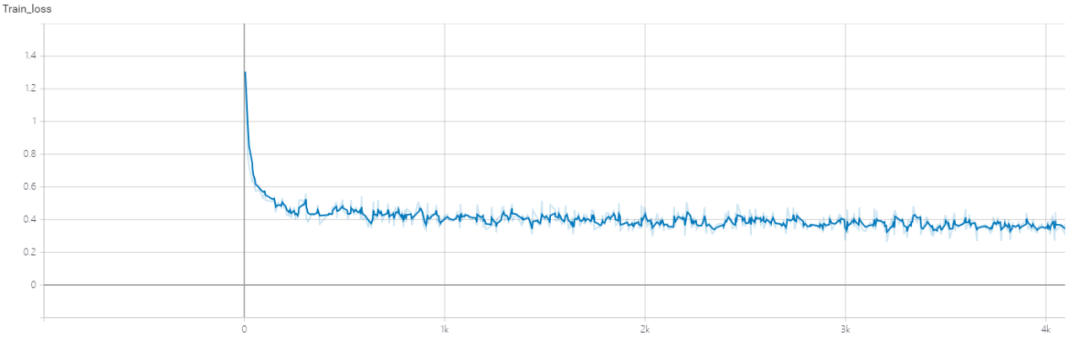
correct num: 8247 , total num: 10449Accracy in word: 0.879359924968553Accracy in sentence: 0.7892621303474017result: {'CRNNAccuracy': 0.7892621303474017}
查看官方文档、手册及论坛,检查对应函数和接口存在什么限制,检查自己编写代码过程中是否已经满足。 查看Github和Google中别人是否存在类似问题,进行参考,看能否解决可能存在的问题。 编写简单的案例进行尝试,考虑所有可能的情况,找出在什么条件下会出现类似的BUG。 对自己代码由浅到深一步步进行检查,可以采用二分法逐步缩小问题范围。

文章转载自开源之夏,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
