




暑期2021项目研发正在火热进行中,开源之夏公众号面向广大社区及项目承担学生征稿,欢迎大家热情分享:
发送投稿文章至官方联络邮箱:
summer@iscas.ac.cn
添加公众号小编微信投稿:

本期分享来自openEuler社区的郭子仪同学带来的项目(提供通用的软件故障注入工具)经验分享。
本文主要是梳理eBPF模块在verifier与jit阶段的主要流程。
对于理解eBPF程序在内核中的加载,检查,编译阶段等很有意义。
verifier:eBPF的一个验证器,实现了一个本模块下的CFI/CFG(控制流完整性)机制。
jit:Just-In-Time,即时编译,eBPF汇编会在内核中被规则替换成真正的x64的指令。
01
前情提要
eBPF汇编中有r0至r10一共11个寄存器,作用如下:
R0(rax),函数返回值
R1(rdi),arg1
R2(rsi),arg2
R3(rdx),arg3
R4(rcx),arg4
R5(r8),arg5
R6(rbx),callee保存
R7(r13),callee保存
R8(r14),callee保存
R9(r15),callee保存
R10(rbp),栈帧寄存器
所有的eBPF汇编在内核中定义为一个 struct bpf_insn ,当我们需要写的时候一般将连续的指令布置成一个结构体数组:
struct bpf_insn {__u8 code; /* opcode */__u8 dst_reg:4; /* dest register */__u8 src_reg:4; /* source register */__s16 off; /* signed offset */__s32 imm; /* signed immediate constant */};struct bpf_insn insn[] = {BPF_LD_MAP_FD(BPF_REG_1,3),......};
然后通过内核态的:bpf_prog_load 载入,编译,运行。
更具体的,在用户态可以定义辅助函数:
static int bpf_prog_load(enum bpf_prog_type prog_type,const struct bpf_insn *insns, int prog_len,const char *license, int kern_version){union bpf_attr attr = {.prog_type = prog_type,.insns = (uint64_t)insns,.insn_cnt = prog_len / sizeof(struct bpf_insn),.license = (uint64_t)license,.log_buf = (uint64_t)bpf_log_buf,.log_size = LOG_BUF_SIZE,.log_level = 1,};attr.kern_version = kern_version;bpf_log_buf[0] = 0;return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));}
而内核中对应的处理函数就是:
case BPF_PROG_LOAD:err = bpf_prog_load(&attr, uattr);break;
相应的,struct bpf_prog 此结构体用于维护一个内核中的eBPF程序:
struct bpf_prog {u16 pages; /* Number of allocated pages */u16 jited:1, /* Is our filter JIT'ed? */jit_requested:1,/* archs need to JIT the prog */gpl_compatible:1, /* Is filter GPL compatible? */cb_access:1, /* Is control block accessed? */dst_needed:1, /* Do we need dst entry? */blinded:1, /* Was blinded */is_func:1, /* program is a bpf function */kprobe_override:1, /* Do we override a kprobe? */has_callchain_buf:1, /* callchain buffer allocated? */enforce_expected_attach_type:1; /* Enforce expected_attach_type checking at attach time */enum bpf_prog_type type; /* Type of BPF program */enum bpf_attach_type expected_attach_type; /* For some prog types */u32 len; /* Number of filter blocks */u32 jited_len; /* Size of jited insns in bytes */u8 tag[BPF_TAG_SIZE];struct bpf_prog_aux *aux; /* Auxiliary fields */struct sock_fprog_kern *orig_prog; /* Original BPF program */unsigned int (*bpf_func)(const void *ctx,const struct bpf_insn *insn);/* Instructions for interpreter */union {struct sock_filter insns[0];struct bpf_insn insnsi[0];};};
02
bpf_prog_load
此函数中主要做了如下关键的事情:
首先有一系列的检查。(这部分我贴上来的代码中才剪掉了,主要涉及一些权限和标识)
通过 bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER) 为我们的prog分配空间,分配大小为struct bpf_prog加指令长度。返回一个 struct bpf_prog *
检测LSM hook。
将程序长度赋值为指令长度:prog->len = attr->insn_cnt;
将用户态的insn拷贝到内核态分配的空间。
通过prog的类型赋值 ops 虚表,里面定义了对应的绑定好的函数。
调用verifier检测控制流完整性等。(这一部分也很重要,但是本篇文章主要重点放在jit编译阶段)
单bpf函数调用
bpf_prog_select_runtime(prog,&err) jit编译prog。多bpf函数的prog调用jit_subprog。两者都会统一到针对do_jit的调用。
为编译后的prog分配一个唯一的id,bpftools会用到这个id。
static int bpf_prog_load(union bpf_attr *attr, union bpf_attr __user *uattr){enum bpf_prog_type type = attr->prog_type;struct bpf_prog *prog;int err;char license[128];bool is_gpl;....../* plain bpf_prog allocation */prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER);if (!prog)return -ENOMEM;......prog->len = attr->insn_cnt;err = -EFAULT;if (copy_from_user(prog->insns, u64_to_user_ptr(attr->insns),bpf_prog_insn_size(prog)) != 0)goto free_prog;prog->orig_prog = NULL;prog->jited = 0; //还没有jit编译....../* find program type: socket_filter vs tracing_filter *//*type = array_index_nospec(type, ARRAY_SIZE(bpf_prog_types));ops = bpf_prog_types[type];*/err = find_prog_type(type, prog);if (err < 0)goto free_prog;....../* run eBPF verifier */err = bpf_check(&prog, attr, uattr);if (err < 0)goto free_used_maps;prog = bpf_prog_select_runtime(prog, &err);if (err < 0)goto free_used_maps;err = bpf_prog_alloc_id(prog);if (err)goto free_used_maps;......}
03
verifier部分
入口位置在:
/* run eBPF verifier */err = bpf_check(&prog, attr, uattr);
bpf_check
本函数是verifier的主要函数,可以看作一个eBPF-扩展CFI机制
主要做了如下操作:
1. 首先对 struct bpf_verifier_env *env 进行一些设置。
2. 调用 replace_map_fd_with_map_ptr(env); 将对应的map_fd转换为map_ptr。
int bpf_check(struct bpf_prog **prog, union bpf_attr *attr,union bpf_attr __user *uattr){u64 start_time = ktime_get_ns();struct bpf_verifier_env *env;struct bpf_verifier_log *log;int i, len, ret = -EINVAL;bool is_priv;......len = (*prog)->len;env->insn_aux_data =vzalloc(array_size(sizeof(struct bpf_insn_aux_data), len));ret = -ENOMEM;if (!env->insn_aux_data)goto err_free_env;for (i = 0; i < len; i++)env->insn_aux_data[i].orig_idx = i;env->prog = *prog;env->ops = bpf_verifier_ops[env->prog->type];is_priv = capable(CAP_SYS_ADMIN);....../* 设置对齐 */env->strict_alignment = !!(attr->prog_flags & BPF_F_STRICT_ALIGNMENT);if (!IS_ENABLED(CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS))env->strict_alignment = true;if (attr->prog_flags & BPF_F_ANY_ALIGNMENT)env->strict_alignment = false;env->allow_ptr_leaks = is_priv;if (is_priv)env->test_state_freq = attr->prog_flags & BPF_F_TEST_STATE_FREQ;ret = replace_map_fd_with_map_ptr(env);if (ret < 0)goto skip_full_check;if (bpf_prog_is_dev_bound(env->prog->aux)) {ret = bpf_prog_offload_verifier_prep(env->prog);if (ret)goto skip_full_check;}env->explored_states = kvcalloc(state_htab_size(env),sizeof(struct bpf_verifier_state_list *),GFP_USER);ret = -ENOMEM;if (!env->explored_states)goto skip_full_check;ret = check_subprogs(env);if (ret < 0)goto skip_full_check;ret = check_btf_info(env, attr, uattr);if (ret < 0)goto skip_full_check;ret = check_attach_btf_id(env);if (ret)goto skip_full_check;ret = check_cfg(env);if (ret < 0)goto skip_full_check;ret = do_check_subprogs(env);ret = ret ?: do_check_main(env);if (ret == 0 && bpf_prog_is_dev_bound(env->prog->aux))ret = bpf_prog_offload_finalize(env);skip_full_check:kvfree(env->explored_states);if (ret == 0)ret = check_max_stack_depth(env);/* instruction rewrites happen after this point */if (is_priv) {if (ret == 0)opt_hard_wire_dead_code_branches(env);if (ret == 0)ret = opt_remove_dead_code(env);if (ret == 0)ret = opt_remove_nops(env);} else {if (ret == 0)sanitize_dead_code(env);}if (ret == 0)/* program is valid, convert *(u32*)(ctx + off) accesses */ret = convert_ctx_accesses(env);if (ret == 0)ret = fixup_bpf_calls(env);/* do 32-bit optimization after insn patching has done so those patched* insns could be handled correctly.*/if (ret == 0 && !bpf_prog_is_dev_bound(env->prog->aux)) {ret = opt_subreg_zext_lo32_rnd_hi32(env, attr);env->prog->aux->verifier_zext = bpf_jit_needs_zext() ? !ret: false;}if (ret == 0)ret = fixup_call_args(env);env->verification_time = ktime_get_ns() - start_time;print_verification_stats(env);if (log->level && bpf_verifier_log_full(log))ret = -ENOSPC;if (log->level && !log->ubuf) {ret = -EFAULT;goto err_release_maps;}if (ret == 0 && env->used_map_cnt) {/* if program passed verifier, update used_maps in bpf_prog_info */env->prog->aux->used_maps = kmalloc_array(env->used_map_cnt,sizeof(env->used_maps[0]),GFP_KERNEL);if (!env->prog->aux->used_maps) {ret = -ENOMEM;goto err_release_maps;}memcpy(env->prog->aux->used_maps, env->used_maps,sizeof(env->used_maps[0]) * env->used_map_cnt);env->prog->aux->used_map_cnt = env->used_map_cnt;/* program is valid. Convert pseudo bpf_ld_imm64 into generic* bpf_ld_imm64 instructions*/convert_pseudo_ld_imm64(env);}if (ret == 0)adjust_btf_func(env);err_release_maps:if (!env->prog->aux->used_maps)/* if we didn't copy map pointers into bpf_prog_info, release* them now. Otherwise free_used_maps() will release them.*/release_maps(env);*prog = env->prog;err_unlock:if (!is_priv)mutex_unlock(&bpf_verifier_lock);vfree(env->insn_aux_data);err_free_env:kfree(env);return ret;}
replace_map_fd_with_map_ptr
函数主要目的:
将map_fd,转换为map的地址。
将加载后的map_addr分高低32位在上下两条指令中存储。
简单的校验非加载map指令的操作码合法性。
主要流程如下:
1. 首先取出env中保存的insn指令和长度。
2. 调用 bpf_prog_calc_tag ,在其中算了一下SHA1,然后把算好的摘要放进env->prog->tag 中。值得注意的是函数中有这么几行:
int bpf_prog_calc_tag(struct bpf_prog *fp){......bool was_ld_map;struct bpf_insn *dst;u8 *raw, *todo;......raw = vmalloc(raw_size);if (!raw)return -ENOMEM;....../* We need to take out the map fd for the digest calculation* since they are unstable from user space side.*/dst = (void *)raw;for (i = 0, was_ld_map = false; i < fp->len; i++) {dst[i] = fp->insnsi[i];if (!was_ld_map &&dst[i].code == (BPF_LD | BPF_IMM | BPF_DW) &&(dst[i].src_reg == BPF_PSEUDO_MAP_FD ||dst[i].src_reg == BPF_PSEUDO_MAP_VALUE)) {was_ld_map = true;dst[i].imm = 0;} else if (was_ld_map &&dst[i].code == 0 &&dst[i].dst_reg == 0 &&dst[i].src_reg == 0 &&dst[i].off == 0) {was_ld_map = false;dst[i].imm = 0;} else {was_ld_map = false;}}psize = bpf_prog_insn_size(fp);memset(&raw[psize], 0, raw_size - psize);raw[psize++] = 0x80;......}
a. 扫描指令,将对应的指令(即insn结构体放入)dst[i]
b. 如果是加载map的指令,那么设置 was_ld_map = true ,设置立即数为0: dst[i].imm = 0
c. 如果检测到was_ld_map = true 已经设置,且对应的insn结构体都为空,即加载map指令的下一条指令。重新设置 was_ld_map = false 立即数为0 。
d. 也就是说,加载map指令和其下一条指令实际上是构成了一个整体,我们可以看一下对应的eBPF汇编:
/* pseudo BPF_LD_IMM64 insn used to refer to process-local map_fd */#define BPF_LD_MAP_FD(DST, MAP_FD) \BPF_LD_IMM64_RAW(DST, BPF_PSEUDO_MAP_FD, MAP_FD)#define BPF_LD_IMM64_RAW(DST, SRC, IMM) \((struct bpf_insn) { \.code = BPF_LD | BPF_DW | BPF_IMM, \.dst_reg = DST, \.src_reg = SRC, \.off = 0, \.imm = (__u32) (IMM) }), \((struct bpf_insn) { \.code = 0, /* zero is reserved opcode */ \.dst_reg = 0, \.src_reg = 0, \.off = 0, \.imm = ((__u64) (IMM)) >> 32 })
也就是说,加载map的指令后面是跟了一条空指令的。作为padding。
3. for循环中扫描每一条指令。
1)如果是内存加载(BPF_LDX),必须保证带有BPF_MEM,并且立即数为0 。
2)如果是内存存储(BPF_STX),必须保证带有BPF_MEM,并且立即数为0 。
3)如果是:BPF_LD_IMM64_RAW ,标志为:.code = BPF_LD | BPF_DW | BPF_IMM 。即 BPF_LD_MAP_FD ,此时的code是加载map的操作。
如果此时是最后一条指令 || 下一条指令不是空指令,abort。
如果当前load_map指令的src为0,即map_fd为0,跳过。
如果当前指令的src_reg,不是BPF_PSEUDO_MAP_FD,不是BPF_PSEUDO_MAP_VALUE;或者是BPF_PSEUDO_MAP_FD但下一条指令imm不为空。abort,其中BPF_PSEUDO_MAP_FD被条件define为1 。
check结束,通过 insn[0].imm 拿到fd,然__bpf_map_get转换为对应的bpf_map的地址。判断地址合法性。赋值给map。
check_map_prog_compatibility 检测与相应环境的兼容性。
如果设置了BPF_PSEUDO_MAP_FD标志,那么直接将刚刚iv.中取到的map赋值给addr。
否则,通过下一条指令的imm作为off,配合虚表中的 map_direct_value_addr 。
主要实现在:array_map_direct_value_addr ,被用于bpf_array中获取到第一个value。value的地址赋值给addr。然后addr+=off。
以上实际就是为了取addr。
重新设置当前指令的imm为addr的低32位。而addr的高32位存储在下一条指令中。
检查当前map是否处于used状态。
使用 bpf_map_inc(map) ,当前map引用计数+1 。主要是为了拿住map,如果此map被verifier拒绝,那么调用release_maps释放,或者此map被其他有效的程序使用,直到此map被卸载(所有的map都在free_used_maps()中被释放)
将此map标记为used,添加进 env->used_maps表中。同时used_map_cnt计数器+1 。
如果当前的map是一个cgroup存储。进行检测,是否每个type只有一个对应的cgroup stroge。
4)insn++,i++,开始扫描下一条指令。
4. 如果当前指令不是加载map的指令。调用 bpf_opcode_in_insntable 进行基本的指令unkown判断。
bool bpf_opcode_in_insntable(u8 code){#define BPF_INSN_2_TBL(x, y) [BPF_##x | BPF_##y] = true#define BPF_INSN_3_TBL(x, y, z) [BPF_##x | BPF_##y | BPF_##z] = truestatic const bool public_insntable[256] = {[0 ... 255] = false,/* Now overwrite non-defaults ... */BPF_INSN_MAP(BPF_INSN_2_TBL, BPF_INSN_3_TBL),/* UAPI exposed, but rewritten opcodes. cBPF carry-over. */[BPF_LD | BPF_ABS | BPF_B] = true,[BPF_LD | BPF_ABS | BPF_H] = true,[BPF_LD | BPF_ABS | BPF_W] = true,[BPF_LD | BPF_IND | BPF_B] = true,[BPF_LD | BPF_IND | BPF_H] = true,[BPF_LD | BPF_IND | BPF_W] = true,};#undef BPF_INSN_3_TBL#undef BPF_INSN_2_TBLreturn public_insntable[code];}
首先初始化一个16*16的bool矩阵 public_insntable
BPF_INSN_MAP中存储的是合法的指令。通过
BPF_INSN_MAP(BPF_INSN_2_TBL, BPF_INSN_3_TBL) 配合,相当于将合法的指令映射到public_insntable 矩阵(向量)的某个位置,然后将其设置为true。
然后再补充6条额外的合法指令,设置其在BPF_INSN_MAP上的位置位true。
返回当前的指令code,在BPF_INSN_MAP位置上的bool标志。如果为true则通过检查,如果为false就abort。
注意,此时进行的只是一个最简单的指令(操作码)合法性检查。
5. 返回。
check_subprogs
函数主要目的:
生成 env->subprog_info[] 数组,存储要跳转的函数的id。
检测JMP指令的跳转范围是否在subprog中。
函数主要流程:
1. 调用 add_subprog(env,0) ,首先在 env->subprog_info 数组中二分查找off=0,此时查找失败,return -ENOENT,因为此时数组中还没有任何元素。接下来将新的off=0,插入到数组第一项的start成员中:env->subprog_info[env-。>subprog_cnt++].start = off ,最后进行排序。
2. 通过for循环扫描insn[]。
找到所有的BPF_JMP、BPF_CALL指令,或者src_reg为BPF_PSEUDO_CALL的指令。如果设置了allow_ptr_leaks标志,那么abort,防止指针泄漏。
找到对应的JMP、CALL指令后,调用:add_subprog(env, i + insn[i].imm + 1) 。此时insn[i].imm存储的是对应的函数id。off = i + insn[i].imm + 1 ,我们将其进行二分查找。如果此时要插入off的是已经存在的,那么直接return 0 。否则将off插入到 env->subprog_info[env->subprog_cnt++].start 中,subprog_cnt计数加一。最后再对subprog_info中的元素进行排序。
此时已经通过add_subprog 插入完了所有的insn中的需要调用的函数信息(id)到env->subprog_info 数组中。
3. 在subprog[] 数组的最后一项补充一个insn_cnt。
subprog[env->subprog_cnt].start = insn_cnt;
4. 接下来检测所有的跳转指令都在同一个 subprog中。
/* now check that all jumps are within the same subprog */subprog_start = subprog[cur_subprog].start;subprog_end = subprog[cur_subprog + 1].start;for (i = 0; i < insn_cnt; i++) {u8 code = insn[i].code;if (BPF_CLASS(code) != BPF_JMP && BPF_CLASS(code) != BPF_JMP32)goto next;if (BPF_OP(code) == BPF_EXIT || BPF_OP(code) == BPF_CALL)goto next;off = i + insn[i].off + 1;if (off < subprog_start || off >= subprog_end) {verbose(env, "jump out of range from insn %d to %d\n", i, off);return -EINVAL;}next:if (i == subprog_end - 1) {if (code != (BPF_JMP | BPF_EXIT) &&code != (BPF_JMP | BPF_JA)) {verbose(env, "last insn is not an exit or jmp\n");return -EINVAL;}subprog_start = subprog_end;cur_subprog++;if (cur_subprog < env->subprog_cnt)subprog_end = subprog[cur_subprog + 1].start;}}
首先保证class必须是:BPF_JMP或者BPF_JMP32 。
op不是EXIT或者CALL,也就是不能是:BPF_JMP | BPF_CALL这样的。主要针对的是:
BPF_JMP_REG,BPF_JMP32_REG,BPF_JMP_IMM,BPF_JMP32_IMM
这样的。
获取到对应的off作为跳转的距离,检测off在当前的subprog之内。(主要是相对insn指令的距离)
如果已经是最后一条指令了,要保证最后一条是一个JMP或者ExiT。
ps:根据别的师傅的解释:
bpf指令支持两种call调用,一种bpf函数对bpf函数的调用,一种是bpf中对内核helper func的调用。前者是指令class为BPF_JMP,指令opcode位BPF_CALL,并且src寄存器为BPF_PSEUDO_CALL,指令imm为callee函数到本指令的距离。另外一种是对对内核helper func的调用,指令class为特征是BPF_JMP,指令opcode为BPF_CALL,并且src_reg=0,指令imm在jit之前位内核helper func id,jit之后为对应的func到本指令的距离。
我这里遇到的主要是第二种。
check_cfg
函数主要目的:
非递归的深度优先遍历检测是否存在有向无环图(循环)
检测控制流合法性。
struct {int *insn_state;int *insn_stack;int cur_stack;} cfg;
函数流程:
enum {DISCOVERED = 0x10,EXPLORED = 0x20,FALLTHROUGH = 1, //顺序执行BRANCH = 2, //条件跳转};
本函数中,首先通过DFS转换成执行流tree。在这里图上的边edge被分成四种情况:
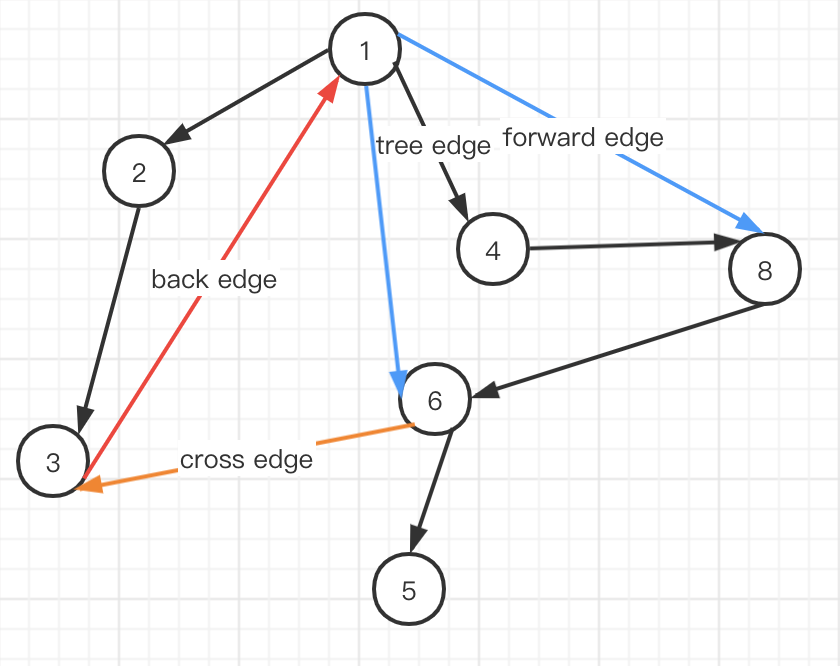
tree edge:最正常的顺序执行的边。
forward edge:在同一侧前向跨越的边,可能由jmp指令导致。
cross edge:跨越左右两侧的边。
back edge:后向边,检测到他代表出现了循环。
同样的,图中的点也有几种情况:
explored,代表一个已经被DFS完毕所有(出)边的结点。
discovered,代表一个结点w,在上一结点t通过边e可达。
fallthrough,代表一个结点w为顺序执行的可达点。
branch,代表一个结点是条件跳转的分支可达点。
非递归的DFS大致流程如下:
1. 首先标记第一个点v,压入栈S。
2. 如果S不空,进入while循环。
1)弹出栈顶第一个元素t。如果t是我们需要找的直接return。
2)如果t不是,那么通过for循环扫描t结点的每一个边edge。
如果边e已经被标记了,那么跳过,扫描t的下一个边。
扫描到t通过e到达的临近顶点w。
如果w未被标记。标记e为tree-edge。标记w为已经发现的点(discovered)。
压栈w,重新对w进行while循环。直到:
1. 发现w又是当前路径下一个已发现的点,此时则寻找到一条back-edge,说明存在loop
2. w已经是叶子结点或标记为探索完成explored。标记为cross或者forawrd。
此时t结点所有的边DFS完毕,标记结点t为explored。弹出栈。
函数实现如下:
/* non-recursive depth-first-search to detect loops in BPF program* loop == back-edge in directed graph*/static int check_cfg(struct bpf_verifier_env *env){struct bpf_insn *insns = env->prog->insnsi;int insn_cnt = env->prog->len;int *insn_stack, *insn_state;int ret = 0;int i, t;//分配空间//insn_state 用来记录指令的状态insn_state = env->cfg.insn_state = kvcalloc(insn_cnt, sizeof(int), GFP_KERNEL);if (!insn_state)return -ENOMEM;//insn_stack 是存储指令的栈insn_stack = env->cfg.insn_stack = kvcalloc(insn_cnt, sizeof(int), GFP_KERNEL);if (!insn_stack) {kvfree(insn_state);return -ENOMEM;}//首先将第一个结点的状态标记为 discoveredinsn_state[0] = DISCOVERED; /* mark 1st insn as discovered *///第一条指令为0insn_stack[0] = 0; /* 0 is the first instruction *///cfg_cur_stack指向指令栈中当前指令的位置(index)env->cfg.cur_stack = 1;peek_stack://如果栈中已经没有元素,全部退栈,检查所有指令的状态是否都为explored。//若有不是explored说明不可达。if (env->cfg.cur_stack == 0)goto check_state;//取当前的指令为结点t。t = insn_stack[env->cfg.cur_stack - 1];if (BPF_CLASS(insns[t].code) == BPF_JMP ||BPF_CLASS(insns[t].code) == BPF_JMP32){u8 opcode = BPF_OP(insns[t].code);if (opcode == BPF_EXIT) {//如果是exit,则标记为explored。//因为exit不可能再有出边了。goto mark_explored;} else if (opcode == BPF_CALL) {//当前指令如果是call调用函数//将下一条指令压栈,在push中做了loop detectret = push_insn(t, t + 1, FALLTHROUGH, env, false);//如果压栈成功,ret=1if (ret == 1)goto peek_stack;//如果压栈失败,ret<0else if (ret < 0)goto err_free;if (t + 1 < insn_cnt)init_explored_state(env, t + 1);//这里对应两种BPF_CALL//若果是bpf函数调用,将被调用函数入栈,标记结点为branch//如果src_reg = 0,说明是kernel func,不需要对被调用函数入栈的操作if (insns[t].src_reg == BPF_PSEUDO_CALL) {init_explored_state(env, t);ret = push_insn(t, t + insns[t].imm + 1, BRANCH,env, false);if (ret == 1)goto peek_stack;else if (ret < 0)goto err_free;}} else if (opcode == BPF_JA) {//如果是无条件跳转if (BPF_SRC(insns[t].code) != BPF_K) {ret = -EINVAL;goto err_free;}/* unconditional jump with single edge *///将跳转的对应跳转分支结点入栈ret = push_insn(t, t + insns[t].off + 1,FALLTHROUGH, env, true);if (ret == 1)goto peek_stack;else if (ret < 0)goto err_free;/* unconditional jmp is not a good pruning point,* but it's marked, since backtracking needs* to record jmp history in is_state_visited().*/init_explored_state(env, t + insns[t].off + 1);/* tell verifier to check for equivalent states* after every call and jump*/if (t + 1 < insn_cnt)init_explored_state(env, t + 1);} else {/* conditional jump with two edges *///有双分支结点的条件跳转指令//两个分支都进行压栈,模拟执行init_explored_state(env, t);//先压fasle分支ret = push_insn(t, t + 1, FALLTHROUGH, env, true);if (ret == 1)goto peek_stack;else if (ret < 0)goto err_free;//再压true分支ret = push_insn(t, t + insns[t].off + 1, BRANCH, env, true);if (ret == 1)goto peek_stack;else if (ret < 0)goto err_free;}} else {/* all other non-branch instructions with single* fall-through edge*///不存在分支的正常指令入栈ret = push_insn(t, t + 1, FALLTHROUGH, env, false);if (ret == 1)goto peek_stack;else if (ret < 0)goto err_free;}//exit指令,标记当前结点为explored状态。栈指针减一,退栈。mark_explored:insn_state[t] = EXPLORED;if (env->cfg.cur_stack-- <= 0) {verbose(env, "pop stack internal bug\n");ret = -EFAULT;goto err_free;}goto peek_stack;//检测是否最终所有指令结点都被扫描完了check_state:for (i = 0; i < insn_cnt; i++) {if (insn_state[i] != EXPLORED) {verbose(env, "unreachable insn %d\n", i);ret = -EINVAL;goto err_free;}}ret = 0; /* cfg looks good */err_free:kvfree(insn_state);kvfree(insn_stack);env->cfg.insn_state = env->cfg.insn_stack = NULL;return ret;}
值得注意的是其中有一个一直出现的函数:init_explored_state
我这里找到了一个commit。
https://zh.osdn.net/projects/android-x86/scm/git/kernel/commits/5762a20b11ef261ae8436868555fab4340cb3ca0
Convert explored_states array into hash table and use simple hash to reduce verifier peak memory consumption for programs with bpf2bpf calls. More details in patch 3.
为了减少bpf到bpf的函数调用的峰值内存消耗,设置了对应结点的prune_point为true。
push_insn
函数主要目的:
对指令结点t与t+1入栈(t+1也可能是其他的分支或者函数结点),模拟执行。
检测控制流合法性。
返回0,代表下一条指令w不压栈,当前为退栈流程。返回1代表成果压栈
函数实现如下:
/* t, w, e - match pseudo-code above:* t - index of current instruction* w - next instruction* e - edge*/static int push_insn(int t, int w, int e, struct bpf_verifier_env *env,bool loop_ok){int *insn_stack = env->cfg.insn_stack;int *insn_state = env->cfg.insn_state;//e是fallthrough代表顺序执行(t到w)if (e == FALLTHROUGH && insn_state[t] >= (DISCOVERED | FALLTHROUGH))return 0;//如果遇见分支跳转指令if (e == BRANCH && insn_state[t] >= (DISCOVERED | BRANCH))return 0;//判断下一条指令的范围if (w < 0 || w >= env->prog->len) {verbose_linfo(env, t, "%d: ", t);verbose(env, "jump out of range from insn %d to %d\n", t, w);return -EINVAL;}//如果当前的边是branch,分支。if (e == BRANCH)/* mark branch target for state pruning */init_explored_state(env, w);//如果下一条指令还没有入栈,没有设置标志if (insn_state[w] == 0) {//对下一条指令进行压栈操作。/* tree-edge */insn_state[t] = DISCOVERED | e; //补充标记当前结点状态insn_state[w] = DISCOVERED; //标记下一条结点状态为discovered//保证栈大小合法if (env->cfg.cur_stack >= env->prog->len)return -E2BIG;//下一条指令进入insn_stack栈中,栈指针后移。insn_stack[env->cfg.cur_stack++] = w;//返回1,压栈成功return 1;}//如果下一条指令已经处于discovered状态else if ((insn_state[w] & 0xF0) == DISCOVERED) {//如果设置了允许loop,且允许ptr leak,返回0if (loop_ok && env->allow_ptr_leaks)return 0;//否则,检测到back-edge,提示存在loopverbose_linfo(env, t, "%d: ", t);verbose_linfo(env, w, "%d: ", w);verbose(env, "back-edge from insn %d to %d\n", t, w);return -EINVAL;}//如果下一条指令结点已经是explored状态,说明是cross或者forward,正常标记当前结点else if (insn_state[w] == EXPLORED) {/* forward- or cross-edge */insn_state[t] = DISCOVERED | e;}else {verbose(env, "insn state internal bug\n");return -EFAULT;}return 0;}
do_check_common
在 do_check_subprogs中会对每个没有设置 BTF_FUNC_GLOBAL 的subprog调用do_check_common进行检查。
函数主要目的:
verifier通过调用此函数来检测每一个subprog的合法性。
函数中主要涉及的结构:
bpf_verifier_state
#define MAX_CALL_FRAMES 8struct bpf_verifier_state {struct bpf_func_state *frame[MAX_CALL_FRAMES]; //保存调用栈struct bpf_verifier_state *parent;/** 'branches' field is the number of branches left to explore:* 0 - all possible paths from this state reached bpf_exit or* were safely pruned* 1 - at least one path is being explored.* This state hasn't reached bpf_exit* 2 - at least two paths are being explored.* This state is an immediate parent of two children.* One is fallthrough branch with branches==1 and another* state is pushed into stack (to be explored later) also with* branches==1. The parent of this state has branches==1.* The verifier state tree connected via 'parent' pointer looks like:* 1* 1* 2 -> 1 (first 'if' pushed into stack)* 1* 2 -> 1 (second 'if' pushed into stack)* 1* 1* 1 bpf_exit.** Once do_check() reaches bpf_exit, it calls update_branch_counts()* and the verifier state tree will look:* 1* 1* 2 -> 1 (first 'if' pushed into stack)* 1* 1 -> 1 (second 'if' pushed into stack)* 0* 0* 0 bpf_exit.* After pop_stack() the do_check() will resume at second 'if'.** If is_state_visited() sees a state with branches > 0 it means* there is a loop. If such state is exactly equal to the current state* it's an infinite loop. Note states_equal() checks for states* equvalency, so two states being 'states_equal' does not mean* infinite loop. The exact comparison is provided by* states_maybe_looping() function. It's a stronger pre-check and* much faster than states_equal().** This algorithm may not find all possible infinite loops or* loop iteration count may be too high.* In such cases BPF_COMPLEXITY_LIMIT_INSNS limit kicks in.*/u32 branches;u32 insn_idx;u32 curframe;u32 active_spin_lock;bool speculative;/* first and last insn idx of this verifier state */u32 first_insn_idx;u32 last_insn_idx;/* jmp history recorded from first to last.* backtracking is using it to go from last to first.* For most states jmp_history_cnt is [0-3].* For loops can go up to ~40.*/struct bpf_idx_pair *jmp_history;u32 jmp_history_cnt;};
branch字段代表的是剩余探索的分支数量。
branch = 0,从这个状态出发的所有可能路径都达到了bpf_exit,或者已经被修剪了。
branch = 1,至少有一条路径正在被探索,这个状态还没有达到bpf_exit。
branch = 2,至少有两条路径正在被探索,这个状态是两个子节点的直接父节点。
其中一个是FALLTHROUGH也就是顺序执行的状态树边。另一个(稍后将被explored的)状态也被压入栈中,也有branch=1。他的父状态结点也有branch=1。
举个例子如果我们通过if的一条路径走到bpf_exit了,会调用update_branch_counts() 回溯更新每个状态树节点branches的值。if的分支节点之间通过 struct bpf_verifier_state *parent; 指针相连。
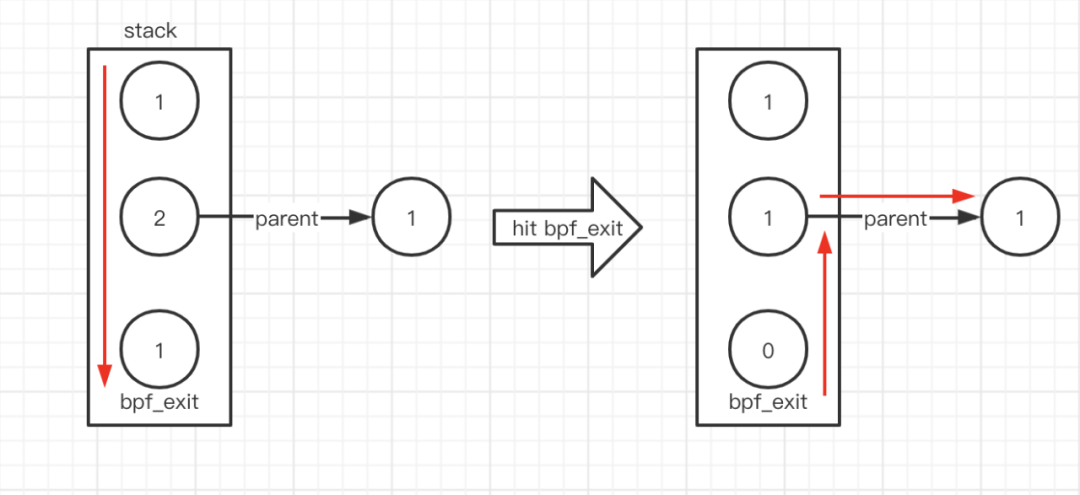
bpf_reg_state:维护了BPF寄存器的状态。
struct bpf_reg_state {/* Ordering of fields matters. See states_equal() */enum bpf_reg_type type;union {/* valid when type == PTR_TO_PACKET */u16 range;/* valid when type == CONST_PTR_TO_MAP | PTR_TO_MAP_VALUE |* PTR_TO_MAP_VALUE_OR_NULL*/struct bpf_map *map_ptr;u32 btf_id; /* for PTR_TO_BTF_ID *//* Max size from any of the above. */unsigned long raw;};/* Fixed part of pointer offset, pointer types only */s32 off;/* For PTR_TO_PACKET, used to find other pointers with the same variable* offset, so they can share range knowledge.* For PTR_TO_MAP_VALUE_OR_NULL this is used to share which map value we* came from, when one is tested for != NULL.* For PTR_TO_SOCKET this is used to share which pointers retain the* same reference to the socket, to determine proper reference freeing.*/u32 id;/* PTR_TO_SOCKET and PTR_TO_TCP_SOCK could be a ptr returned* from a pointer-cast helper, bpf_sk_fullsock() and* bpf_tcp_sock().** Consider the following where "sk" is a reference counted* pointer returned from "sk = bpf_sk_lookup_tcp();":** 1: sk = bpf_sk_lookup_tcp();* 2: if (!sk) { return 0; }* 3: fullsock = bpf_sk_fullsock(sk);* 4: if (!fullsock) { bpf_sk_release(sk); return 0; }* 5: tp = bpf_tcp_sock(fullsock);* 6: if (!tp) { bpf_sk_release(sk); return 0; }* 7: bpf_sk_release(sk);* 8: snd_cwnd = tp->snd_cwnd; // verifier will complain** After bpf_sk_release(sk) at line 7, both "fullsock" ptr and* "tp" ptr should be invalidated also. In order to do that,* the reg holding "fullsock" and "sk" need to remember* the original refcounted ptr id (i.e. sk_reg->id) in ref_obj_id* such that the verifier can reset all regs which have* ref_obj_id matching the sk_reg->id.** sk_reg->ref_obj_id is set to sk_reg->id at line 1.* sk_reg->id will stay as NULL-marking purpose only.* After NULL-marking is done, sk_reg->id can be reset to 0.** After "fullsock = bpf_sk_fullsock(sk);" at line 3,* fullsock_reg->ref_obj_id is set to sk_reg->ref_obj_id.** After "tp = bpf_tcp_sock(fullsock);" at line 5,* tp_reg->ref_obj_id is set to fullsock_reg->ref_obj_id* which is the same as sk_reg->ref_obj_id.** From the verifier perspective, if sk, fullsock and tp* are not NULL, they are the same ptr with different* reg->type. In particular, bpf_sk_release(tp) is also* allowed and has the same effect as bpf_sk_release(sk).*/u32 ref_obj_id;/* For scalar types (SCALAR_VALUE), this represents our knowledge of* the actual value.* For pointer types, this represents the variable part of the offset* from the pointed-to object, and is shared with all bpf_reg_states* with the same id as us.*/struct tnum var_off;/* Used to determine if any memory access using this register will* result in a bad access.* These refer to the same value as var_off, not necessarily the actual* contents of the register.*/s64 smin_value; /* minimum possible (s64)value */s64 smax_value; /* maximum possible (s64)value */u64 umin_value; /* minimum possible (u64)value */u64 umax_value; /* maximum possible (u64)value *//* parentage chain for liveness checking */struct bpf_reg_state *parent;/* Inside the callee two registers can be both PTR_TO_STACK like* R1=fp-8 and R2=fp-8, but one of them points to this function stack* while another to the caller's stack. To differentiate them 'frameno'* is used which is an index in bpf_verifier_state->frame[] array* pointing to bpf_func_state.*/u32 frameno;/* Tracks subreg definition. The stored value is the insn_idx of the* writing insn. This is safe because subreg_def is used before any insn* patching which only happens after main verification finished.*/s32 subreg_def;enum bpf_reg_liveness live;/* if (!precise && SCALAR_VALUE) min/max/tnum don't affect safety */bool precise;};
bpf_reg_type
/* types of values stored in eBPF registers *//* Pointer types represent:* pointer* pointer + imm* pointer + (u16) var* pointer + (u16) var + imm* if (range > 0) then [ptr, ptr + range - off) is safe to access* if (id > 0) means that some 'var' was added* if (off > 0) means that 'imm' was added*/enum bpf_reg_type {NOT_INIT = 0, /* nothing was written into register */SCALAR_VALUE, /* reg doesn't contain a valid pointer */PTR_TO_CTX, /* reg points to bpf_context */CONST_PTR_TO_MAP, /* reg points to struct bpf_map */PTR_TO_MAP_VALUE, /* reg points to map element value */PTR_TO_MAP_VALUE_OR_NULL,/* points to map elem value or NULL */PTR_TO_STACK, /* reg == frame_pointer + offset */PTR_TO_PACKET_META, /* skb->data - meta_len */PTR_TO_PACKET, /* reg points to skb->data */PTR_TO_PACKET_END, /* skb->data + headlen */PTR_TO_FLOW_KEYS, /* reg points to bpf_flow_keys */PTR_TO_SOCKET, /* reg points to struct bpf_sock */PTR_TO_SOCKET_OR_NULL, /* reg points to struct bpf_sock or NULL */PTR_TO_SOCK_COMMON, /* reg points to sock_common */PTR_TO_SOCK_COMMON_OR_NULL, /* reg points to sock_common or NULL */PTR_TO_TCP_SOCK, /* reg points to struct tcp_sock */PTR_TO_TCP_SOCK_OR_NULL, /* reg points to struct tcp_sock or NULL */PTR_TO_TP_BUFFER, /* reg points to a writable raw tp's buffer */PTR_TO_XDP_SOCK, /* reg points to struct xdp_sock */PTR_TO_BTF_ID, /* reg points to kernel struct */};
struct tnum
当reg是一个具体的数值(范围值),本结构代表真正的值。
当reg是一个指针,这代表了到被指向对象的偏移量。
struct tnum {u64 value;u64 mask;};#define TNUM(_v, _m) (struct tnum){.value = _v, .mask = _m}/* A completely unknown value */const struct tnum tnum_unknown = { .value = 0, .mask = -1 };
bpf_stack_slot_type
enum bpf_stack_slot_type {STACK_INVALID, /* nothing was stored in this stack slot */STACK_SPILL, /* register spilled into stack */STACK_MISC, /* BPF program wrote some data into this slot */STACK_ZERO, /* BPF program wrote constant zero */};
函数的主要流程:
1. 初始化当前state信息:
state = kzalloc(sizeof(struct bpf_verifier_state), GFP_KERNEL);state->curframe = 0; //当前在调用栈的最上层state->speculative = false;state->branches = 1; //当前节点branches = 1state->frame[0] = kzalloc(sizeof(struct bpf_func_state), GFP_KERNEL); //记录调用栈env->cur_state = state; //记录当前初始的state节点
2. 初始化函数状态与寄存器。
init_func_state(env, state->frame[0],BPF_MAIN_FUNC /* callsite */, 0 /* frameno */, subprog);
在 init_func_state 中,调用了 init_reg_state 来初始化寄存器。
static void init_reg_state(struct bpf_verifier_env *env,struct bpf_func_state *state){struct bpf_reg_state *regs = state->regs;int i;//挨个扫描当前state中的寄存器for (i = 0; i < MAX_BPF_REG; i++) {//将一个寄存器标识为unknownmark_reg_not_init(env, regs, i);regs[i].live = REG_LIVE_NONE; //生存期?regs[i].parent = NULL;regs[i].subreg_def = DEF_NOT_SUBREG;}/* frame pointer */regs[BPF_REG_FP].type = PTR_TO_STACK; //设置栈帧寄存器r10,指向BPF栈数据mark_reg_known_zero(env, regs, BPF_REG_FP); //将reg的信息都设置为0regs[BPF_REG_FP].frameno = state->frameno; //当前r10的栈帧号等于初始化的state栈帧号。}
3. 如果设置了 env->prog->type == BPF_PROG_TYPE_EXT 调用btf_prepare_func_args 对func的参数类型进行转换与检查。转换成PTR_TO_CTX or SCALAR_VALUE
转换后,如果参数是PTR_TO_CTX(指向bpf_context),标志regs为0 。否则如果是SCALAR_VALUE,标记reg为unknown。
4. 否则,直接标记r1的类型为PTR_TO_CTX,且标0 。然后检测参数类型。
5. 调用 do_check(env);
do_check
函数的主要目的:
刚刚那张图的分支检测等。
check寄存器,stack,bpf context,map等的可读写性。
更新栈内存,寄存器的状态。
1. 当遇见BPF_ALU、BPF_ALU64的指令。对多种可能的ALU操作,比如neg、add、xor、rsh等进行可能的合法性校验(源、目的操作数、寄存器等)。过度细节的校验就不贴上来了。
检验完之后调用 adjust_reg_min_max_vals(env, insn) 计算新的min/max范围与var_off
2. 如果是class==BPF_LDX。即加载指令。
a. 先调用 check_reg_arg(env, insn->src_reg, SRC_OP) 检测src_reg是否可读。
b.再调用 check_reg_arg(env, insn->dst_reg, DST_OP_NO_MARK) 检测dst_reg是否可写。
c. 调用 check_mem_access(env, env->insn_idx, insn->src_reg,insn->off, BPF_SIZE(insn->code),BPF_READ, insn->dst_reg, false); 检测真正要读取的位置:src_reg + off 是否可读。
3. 除了BPF_LDX以外。本函数还对其他的类型的指令进行了对应的检查。在每个子检查中都是使用的:
check_reg_arg check_mem_access 等进行组合检查。
check_mem_access
这个函数是check中用来检查内存访问非常重要的一个函数。
/* check whether memory at (regno + off) is accessible for t = (read | write)* if t==write, value_regno is a register which value is stored into memory* if t==read, value_regno is a register which will receive the value from memory* if t==write && value_regno==-1, some unknown value is stored into memory* if t==read && value_regno==-1, don't care what we read from memory*/static int check_mem_access(struct bpf_verifier_env *env, int insn_idx, u32 regno,int off, int bpf_size, enum bpf_access_type t,int value_regno, bool strict_alignment_once){struct bpf_reg_state *regs = cur_regs(env);struct bpf_reg_state *reg = regs + regno;struct bpf_func_state *state;int size, err = 0;size = bpf_size_to_bytes(bpf_size);if (size < 0)return size;/* alignment checks will add in reg->off themselves *///检查指针对齐err = check_ptr_alignment(env, reg, off, size, strict_alignment_once);if (err)return err;/* for access checks, reg->off is just part of off */off += reg->off;//如果reg指向的是map中的值if (reg->type == PTR_TO_MAP_VALUE) {......}//如果reg指向bpf_contextelse if (reg->type == PTR_TO_CTX) {......}//如果reg指向stackelse if (reg->type == PTR_TO_STACK) {off += reg->var_off.value; //err = check_stack_access(env, reg, off, size);if (err)return err;state = func(env, reg);err = update_stack_depth(env, state, off);if (err)return err;if (t == BPF_WRITE)err = check_stack_write(env, state, off, size,value_regno, insn_idx);elseerr = check_stack_read(env, state, off, size,value_regno);}......
我们主要看一个典型的,当reg是一个指向栈的指针时的情况。
首先我们通过 check_stack_access 检测栈的可访问状况。
static int check_stack_access(struct bpf_verifier_env *env,const struct bpf_reg_state *reg,int off, int size){/* Stack accesses must be at a fixed offset, so that we* can determine what type of data were returned. See* check_stack_read().*///tnum_is_const检测我们要访问的offset必须是一个常量if (!tnum_is_const(reg->var_off)) {char tn_buf[48];tnum_strn(tn_buf, sizeof(tn_buf), reg->var_off);verbose(env, "variable stack access var_off=%s off=%d size=%d\n",tn_buf, off, size);return -EACCES;}//我们访问的位置必须在合法范围内,最大offset不超过-512字节if (off >= 0 || off < -MAX_BPF_STACK) {verbose(env, "invalid stack off=%d size=%d\n", off, size);return -EACCES;}return 0;}
接下来通过func函数查找当前的调用栈。
然后通过 update_stack_depth 对每个函数的栈消耗进行维护。如果当前访问的地址超出当前函数的栈范围,那么对当前函数进行栈扩充。
接下来判断读or写操作。
写操作,调用 check_stack_write 检测栈的可写性。
未设置 allow_ptr_leaks不允许部分写STACK_SPILL类型的栈数据。
reg是STACK_SPILL,部分写不允许。
reg是非STACK_SPILL,根据reg和写入字节的情况设置栈相应的slot类型,支持部分写。
state->stack[spi].slot_type[]中低地址保存实际栈高地址的数据类型
/* check_stack_read/write functions track spill/fill of registers,* stack boundary and alignment are checked in check_mem_access()*/static int check_stack_write(struct bpf_verifier_env *env,struct bpf_func_state *state, /* func where register points to */int off, int size, int value_regno, int insn_idx){struct bpf_func_state *cur; /* state of the current function */int i, slot = -off - 1, spi = slot / BPF_REG_SIZE, err;u32 dst_reg = env->prog->insnsi[insn_idx].dst_reg;struct bpf_reg_state *reg = NULL;//由于栈扩展导致的需要重新申请空间放state跟踪stack状态err = realloc_func_state(state, round_up(slot + 1, BPF_REG_SIZE),state->acquired_refs, true);if (err)return err;/* caller checked that off % size == 0 and -MAX_BPF_STACK <= off < 0,* so it's aligned access and [off, off + size) are within stack limits*///不允许非特权用户由于部分写破坏栈上合法指针if (!env->allow_ptr_leaks &&state->stack[spi].slot_type[0] == STACK_SPILL &&size != BPF_REG_SIZE) {verbose(env, "attempt to corrupt spilled pointer on stack\n");return -EACCES;}cur = env->cur_state->frame[env->cur_state->curframe];if (value_regno >= 0)reg = &cur->regs[value_regno];//优化回溯if (reg && size == BPF_REG_SIZE && register_is_const(reg) &&!register_is_null(reg) && env->allow_ptr_leaks) {if (dst_reg != BPF_REG_FP) {/* The backtracking logic can only recognize explicit* stack slot address like [fp - 8]. Other spill of* scalar via different register has to be conervative.* Backtrack from here and mark all registers as precise* that contributed into 'reg' being a constant.*/err = mark_chain_precision(env, value_regno);if (err)return err;}save_register_state(state, spi, reg);}else if (reg && is_spillable_regtype(reg->type)) {/* register containing pointer is being spilled into stack *///源寄存器是STACK_SPILL,部分写不允许if (size != BPF_REG_SIZE) {verbose_linfo(env, insn_idx, "; ");verbose(env, "invalid size of register spill\n");return -EACCES;}if (state != cur && reg->type == PTR_TO_STACK) {verbose(env, "cannot spill pointers to stack into stack frame of the caller\n");return -EINVAL;}//引入sanitize,防止stack的重用,防范侧信道攻击?if (!env->allow_ptr_leaks){bool sanitize = false;if (state->stack[spi].slot_type[0] == STACK_SPILL &®ister_is_const(&state->stack[spi].spilled_ptr))sanitize = true;for (i = 0; i < BPF_REG_SIZE; i++)if (state->stack[spi].slot_type[i] == STACK_MISC) {sanitize = true;break;}if (sanitize) {int *poff = &env->insn_aux_data[insn_idx].sanitize_stack_off;int soff = (-spi - 1) * BPF_REG_SIZE;/* detected reuse of integer stack slot with a pointer* which means either llvm is reusing stack slot or* an attacker is trying to exploit CVE-2018-3639* (speculative store bypass)* Have to sanitize that slot with preemptive* store of zero.*/if (*poff && *poff != soff) {/* disallow programs where single insn stores* into two different stack slots, since verifier* cannot sanitize them*/verbose(env,"insn %d cannot access two stack slots fp%d and fp%d",insn_idx, *poff, soff);return -EINVAL;}*poff = soff;}}save_register_state(state, spi, reg);} else {//reg是非有效指针u8 type = STACK_MISC;/* regular write of data into stack destroys any spilled ptr */state->stack[spi].spilled_ptr.type = NOT_INIT;//标记栈为STACK_SPILL, 代表包含非指针、非0变量等/* Mark slots as STACK_MISC if they belonged to spilled ptr. */if (state->stack[spi].slot_type[0] == STACK_SPILL)for (i = 0; i < BPF_REG_SIZE; i++)state->stack[spi].slot_type[i] = STACK_MISC;/* only mark the slot as written if all 8 bytes were written* otherwise read propagation may incorrectly stop too soon* when stack slots are partially written.* This heuristic means that read propagation will be* conservative, since it will add reg_live_read marks* to stack slots all the way to first state when programs* writes+reads less than 8 bytes*/if (size == BPF_REG_SIZE)state->stack[spi].spilled_ptr.live |= REG_LIVE_WRITTEN;/* when we zero initialize stack slots mark them as such *///reg为0if (reg && register_is_null(reg)) {/* backtracking doesn't work for STACK_ZERO yet. */err = mark_chain_precision(env, value_regno);if (err)return err;type = STACK_ZERO; //设置为STACK_ZERO}/* Mark slots affected by this stack write. *///reg为0,标记所写栈的slot类型为设置为STACK_ZERO,否则仍然是一开始的MISCfor (i = 0; i < size; i++)state->stack[spi].slot_type[(slot - i) % BPF_REG_SIZE] =type;}return 0;}
读操作,检测可读性,这里就不展开了,比可写性简单一些。
check_max_stack_depth
我们重新回到上层的 bpf_check 中。
函数目的:
保证函数调用深度不超过 MAX_BPF_STACK
挑选出code为BPF_JMP , BPF_CALL ;src_reg为:BPF_PSEUDO_CALL,即eBPF2eBPF的函数调用。记录对应的深度与返回地址,调用完返回上层subprog。在这之间如果调用深度超过8或者最大栈消耗超过512字节,abort。
/* starting from main bpf function walk all instructions of the function* and recursively walk all callees that given function can call.* Ignore jump and exit insns.* Since recursion is prevented by check_cfg() this algorithm* only needs a local stack of MAX_CALL_FRAMES to remember callsites*/static int check_max_stack_depth(struct bpf_verifier_env *env){int depth = 0, frame = 0, idx = 0, i = 0, subprog_end;struct bpf_subprog_info *subprog = env->subprog_info;struct bpf_insn *insn = env->prog->insnsi;int ret_insn[MAX_CALL_FRAMES]; //函数返回地址int ret_prog[MAX_CALL_FRAMES]; //函数返回地址的indexprocess_func:/* round up to 32-bytes, since this is granularity* of interpreter stack size*/depth += round_up(max_t(u32, subprog[idx].stack_depth, 1), 32);//栈不能不超过512if (depth > MAX_BPF_STACK) {verbose(env, "combined stack size of %d calls is %d. Too large\n",frame + 1, depth);return -EACCES;}//subprog[0]为main函数,取下一个函数continue_func:subprog_end = subprog[idx + 1].start;for (; i < subprog_end; i++) {if (insn[i].code != (BPF_JMP | BPF_CALL))continue;if (insn[i].src_reg != BPF_PSEUDO_CALL)continue;/* remember insn and function to return to *///bpf fun之间的调用ret_insn[frame] = i + 1;//记录返回地址ret_prog[frame] = idx; //记录idx/* find the callee */i = i + insn[i].imm + 1;//找到callee的地址idx = find_subprog(env, i);//查找callee的idxif (idx < 0) {WARN_ONCE(1, "verifier bug. No program starts at insn %d\n",i);return -EFAULT;}frame++;//深度++//调用深度限制小于8if (frame >= MAX_CALL_FRAMES) {verbose(env, "the call stack of %d frames is too deep !\n",frame);return -E2BIG;}goto process_func;}/* end of for() loop means the last insn of the 'subprog'* was reached. Doesn't matter whether it was JA or EXIT*///深度为0说明之行结束,返回if (frame == 0)return 0;depth -= round_up(max_t(u32, subprog[idx].stack_depth, 1), 32);frame--;i = ret_insn[frame]; //弹出返回地址idx = ret_prog[frame]; //弹出上层函数idxgoto continue_func; //返回}
fixup_bpf_calls
本函数也很长,不过相对好理解,我们挑一部分关键的来说。
函数目的:
修复bpf_call指令的insn->imm字段,并将符合条件的helper func内联为明确的BPF指令序列。
首先,本函数对指令做了patch,修复一些不合法的指令。处理尾调用等。
{if (insn->code == (BPF_ALU64 | BPF_MOD | BPF_X) ||insn->code == (BPF_ALU64 | BPF_DIV | BPF_X) ||insn->code == (BPF_ALU | BPF_MOD | BPF_X) ||insn->code == (BPF_ALU | BPF_DIV | BPF_X)) {bool is64 = BPF_CLASS(insn->code) == BPF_ALU64;//将div指令扩展为4个指令。//如果源操作数为0,清零dst//跳转到下一条指令执行//类似一个security hook?struct bpf_insn mask_and_div[] = {BPF_MOV32_REG(insn->src_reg, insn->src_reg),/* Rx div 0 -> 0 */BPF_JMP_IMM(BPF_JNE, insn->src_reg, 0, 2),BPF_ALU32_REG(BPF_XOR, insn->dst_reg, insn->dst_reg),BPF_JMP_IMM(BPF_JA, 0, 0, 1),*insn,};//将mod指令扩展为两个指令//如果源操作数为0,目的操作数不变,跳到原指令的下一条执行struct bpf_insn mask_and_mod[] = {BPF_MOV32_REG(insn->src_reg, insn->src_reg),/* Rx mod 0 -> Rx */BPF_JMP_IMM(BPF_JEQ, insn->src_reg, 0, 1),*insn,};//用patch指令替换源指令。struct bpf_insn *patchlet;if (insn->code == (BPF_ALU64 | BPF_DIV | BPF_X) ||insn->code == (BPF_ALU | BPF_DIV | BPF_X)) {patchlet = mask_and_div + (is64 ? 1 : 0);cnt = ARRAY_SIZE(mask_and_div) - (is64 ? 1 : 0);} else {patchlet = mask_and_mod + (is64 ? 1 : 0);cnt = ARRAY_SIZE(mask_and_mod) - (is64 ? 1 : 0);}new_prog = bpf_patch_insn_data(env, i + delta, patchlet, cnt);if (!new_prog)return -ENOMEM;delta += cnt - 1;env->prog = prog = new_prog;insn = new_prog->insnsi + i + delta;continue;}......//修正跳转距离,imm为调用函数到当前指令的距离。//通过BPF_CAST_CALL获取该函数的地址直接减去内核的__bpf_call_base,做的实际只是部分修正。switch (insn->imm) {case BPF_FUNC_map_lookup_elem:insn->imm = BPF_CAST_CALL(ops->map_lookup_elem) -__bpf_call_base;continue;case BPF_FUNC_map_update_elem:insn->imm = BPF_CAST_CALL(ops->map_update_elem) -__bpf_call_base;continue;case BPF_FUNC_map_delete_elem:insn->imm = BPF_CAST_CALL(ops->map_delete_elem) -__bpf_call_base;continue;case BPF_FUNC_map_push_elem:insn->imm = BPF_CAST_CALL(ops->map_push_elem) -__bpf_call_base;continue;case BPF_FUNC_map_pop_elem:insn->imm = BPF_CAST_CALL(ops->map_pop_elem) -__bpf_call_base;continue;case BPF_FUNC_map_peek_elem:insn->imm = BPF_CAST_CALL(ops->map_peek_elem) -__bpf_call_base;continue;}goto patch_call_imm;}
04
jit部分
fixup_call_args 调用了 jit_subprogs
jit_subprogs
函数主要目的:
扫描prog,找到bpf2bpf函数调用,找到对应的subprog,存储。
为每个要jit的subprog申请空间。
bpf_int_jit_compile 每个subprog
修正bpf2bpf调用的函数距离(bpf_int_jit_compile)
这里实际上对于函数地址的修正经过了多轮jit,这里看了别的大佬的一种解释。
由于第一次不完全修正函数距离时
函数流程:
static int jit_subprogs(struct bpf_verifier_env *env){struct bpf_prog *prog = env->prog, **func, *tmp;int i, j, subprog_start, subprog_end = 0, len, subprog;struct bpf_insn *insn;void *old_bpf_func;int err;//判断subprog数量if (env->subprog_cnt <= 1)return 0;//扫描指令,找到bpf2bpf的调用for (i = 0, insn = prog->insnsi; i < prog->len; i++, insn++) {if (insn->code != (BPF_JMP | BPF_CALL) ||insn->src_reg != BPF_PSEUDO_CALL)continue;/* Upon error here we cannot fall back to interpreter but* need a hard reject of the program. Thus -EFAULT is* propagated in any case.*///根据调用地址找到被调用subprog的索引,保存索引到insn->off中。subprog = find_subprog(env, i + insn->imm + 1);if (subprog < 0) {WARN_ONCE(1, "verifier bug. No program starts at insn %d\n",i + insn->imm + 1);return -EFAULT;}/* temporarily remember subprog id inside insn instead of* aux_data, since next loop will split up all insns into funcs*/insn->off = subprog;/* remember original imm in case JIT fails and fallback* to interpreter will be needed*/env->insn_aux_data[i].call_imm = insn->imm;/* point imm to __bpf_call_base+1 from JITs point of view */insn->imm = 1;}//分配空间err = bpf_prog_alloc_jited_linfo(prog);if (err)goto out_undo_insn;err = -ENOMEM;func = kcalloc(env->subprog_cnt, sizeof(prog), GFP_KERNEL);if (!func)goto out_undo_insn;//为了每个subprog申请空间,然后根据prog来做初始化for (i = 0; i < env->subprog_cnt; i++) {subprog_start = subprog_end;subprog_end = env->subprog_info[i + 1].start;len = subprog_end - subprog_start;/* BPF_PROG_RUN doesn't call subprogs directly,* hence main prog stats include the runtime of subprogs.* subprogs don't have IDs and not reachable via prog_get_next_id* func[i]->aux->stats will never be accessed and stays NULL*/func[i] = bpf_prog_alloc_no_stats(bpf_prog_size(len), GFP_USER);if (!func[i])goto out_free;memcpy(func[i]->insnsi, &prog->insnsi[subprog_start],len * sizeof(struct bpf_insn));func[i]->type = prog->type;func[i]->len = len;if (bpf_prog_calc_tag(func[i]))goto out_free;func[i]->is_func = 1;func[i]->aux->func_idx = i;/* the btf and func_info will be freed only at prog->aux */func[i]->aux->btf = prog->aux->btf;func[i]->aux->func_info = prog->aux->func_info;/* Use bpf_prog_F_tag to indicate functions in stack traces.* Long term would need debug info to populate names*/func[i]->aux->name[0] = 'F';func[i]->aux->stack_depth = env->subprog_info[i].stack_depth;func[i]->jit_requested = 1; //开启jitfunc[i]->aux->linfo = prog->aux->linfo;func[i]->aux->nr_linfo = prog->aux->nr_linfo;func[i]->aux->jited_linfo = prog->aux->jited_linfo;func[i]->aux->linfo_idx = env->subprog_info[i].linfo_idx;func[i] = bpf_int_jit_compile(func[i]); //对该subprog做jitif (!func[i]->jited) { //如果没有jit成功err = -ENOTSUPP;goto out_free;}cond_resched();}/* at this point all bpf functions were successfully JITed* now populate all bpf_calls with correct addresses and* run last pass of JIT*///修正bpf2bpf调用的函数距离for (i = 0; i < env->subprog_cnt; i++) {insn = func[i]->insnsi;for (j = 0; j < func[i]->len; j++, insn++) {if (insn->code != (BPF_JMP | BPF_CALL) ||insn->src_reg != BPF_PSEUDO_CALL)continue;subprog = insn->off;//这里也只是部分修复,最后真正的修复在bpf_int_jit_compile中insn->imm = BPF_CAST_CALL(func[subprog]->bpf_func) -__bpf_call_base;}/* we use the aux data to keep a list of the start addresses* of the JITed images for each function in the program** for some architectures, such as powerpc64, the imm field* might not be large enough to hold the offset of the start* address of the callee's JITed image from __bpf_call_base** in such cases, we can lookup the start address of a callee* by using its subprog id, available from the off field of* the call instruction, as an index for this list*/func[i]->aux->func = func;func[i]->aux->func_cnt = env->subprog_cnt;}for (i = 0; i < env->subprog_cnt; i++) {old_bpf_func = func[i]->bpf_func;tmp = bpf_int_jit_compile(func[i]); //真正的修复bpf2bpf函数的调用距离if (tmp != func[i] || func[i]->bpf_func != old_bpf_func) {verbose(env, "JIT doesn't support bpf-to-bpf calls\n");err = -ENOTSUPP;goto out_free;}cond_resched();}/* finally lock prog and jit images for all functions and* populate kallsysm*/for (i = 0; i < env->subprog_cnt; i++) {bpf_prog_lock_ro(func[i]); //jit之后子函数内存只读bpf_prog_kallsyms_add(func[i]); //添加到kallsyms}/* Last step: make now unused interpreter insns from main* prog consistent for later dump requests, so they can* later look the same as if they were interpreted only.*/for (i = 0, insn = prog->insnsi; i < prog->len; i++, insn++) {if (insn->code != (BPF_JMP | BPF_CALL) ||insn->src_reg != BPF_PSEUDO_CALL)continue;insn->off = env->insn_aux_data[i].call_imm;subprog = find_subprog(env, i + insn->off + 1);insn->imm = subprog;}prog->jited = 1; //设置jit完成prog->bpf_func = func[0]->bpf_func; //prog在内核里的可执行地址prog->aux->func = func;prog->aux->func_cnt = env->subprog_cnt;bpf_prog_free_unused_jited_linfo(prog);return 0;out_free:for (i = 0; i < env->subprog_cnt; i++)if (func[i])bpf_jit_free(func[i]);kfree(func);out_undo_insn:/* cleanup main prog to be interpreted */prog->jit_requested = 0;for (i = 0, insn = prog->insnsi; i < prog->len; i++, insn++) {if (insn->code != (BPF_JMP | BPF_CALL) ||insn->src_reg != BPF_PSEUDO_CALL)continue;insn->off = 0;insn->imm = env->insn_aux_data[i].call_imm;}bpf_prog_free_jited_linfo(prog);return err;}
do_jit/bpf_int_jit_compile
这是最主要的jit函数。
内核中实际上有两条可以到达这里的有效jit路径:
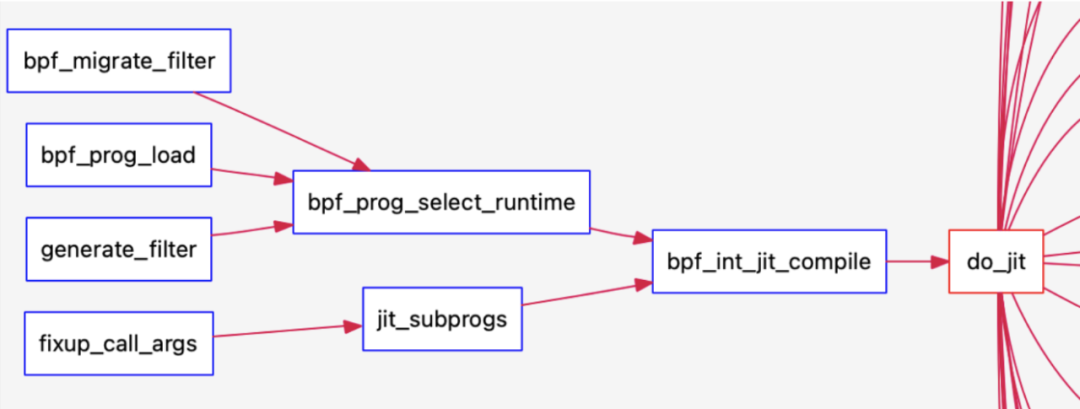
第一条是jit_subprogs(这里涉及到bpf2bpf函数调用等,所以是多函数的bpf jit路径)。
另一条是通过bpf_prog_select_runtime,即当bpf_check结束后,调用bpf_prog_select_runtime。
do_jit
调用:static int do_jit(struct bpf_prog *bpf_prog, int *addrs, u8 *image,int oldproglen, struct jit_context *ctx)
1. 首先通过 emit_prologue 构建栈初始化环境。为了符合x64的abi,主要涉及rsp,rbp的操作等。
/** Emit x86-64 prologue code for BPF program and check its size.* bpf_tail_call helper will skip it while jumping into another program*/static void emit_prologue(u8 **pprog, u32 stack_depth, bool ebpf_from_cbpf){u8 *prog = *pprog;int cnt = X86_PATCH_SIZE;/* BPF trampoline can be made to work without these nops,* but let's waste 5 bytes for now and optimize later*/memcpy(prog, ideal_nops[NOP_ATOMIC5], cnt);prog += cnt;EMIT1(0x55); /* push rbp */EMIT3(0x48, 0x89, 0xE5); /* mov rbp, rsp *//* sub rsp, rounded_stack_depth */EMIT3_off32(0x48, 0x81, 0xEC, round_up(stack_depth, 8));EMIT1(0x53); /* push rbx */EMIT2(0x41, 0x55); /* push r13 */EMIT2(0x41, 0x56); /* push r14 */EMIT2(0x41, 0x57); /* push r15 */if (!ebpf_from_cbpf) {/* zero init tail_call_cnt */EMIT2(0x6a, 0x00);BUILD_BUG_ON(cnt != PROLOGUE_SIZE);}*pprog = prog;}
2. 针对类似的普通指令,可以一对一的进行翻译,opcode、eBPF、寄存器相匹配:
/* ALU */case BPF_ALU | BPF_ADD | BPF_X:case BPF_ALU | BPF_SUB | BPF_X:case BPF_ALU | BPF_AND | BPF_X:case BPF_ALU | BPF_OR | BPF_X:case BPF_ALU | BPF_XOR | BPF_X:case BPF_ALU64 | BPF_ADD | BPF_X:case BPF_ALU64 | BPF_SUB | BPF_X:case BPF_ALU64 | BPF_AND | BPF_X:case BPF_ALU64 | BPF_OR | BPF_X:case BPF_ALU64 | BPF_XOR | BPF_X:switch (BPF_OP(insn->code)) {case BPF_ADD: b2 = 0x01; break;case BPF_SUB: b2 = 0x29; break;case BPF_AND: b2 = 0x21; break;case BPF_OR: b2 = 0x09; break;case BPF_XOR: b2 = 0x31; break;}if (BPF_CLASS(insn->code) == BPF_ALU64)EMIT1(add_2mod(0x48, dst_reg, src_reg));else if (is_ereg(dst_reg) || is_ereg(src_reg))EMIT1(add_2mod(0x40, dst_reg, src_reg));EMIT2(b2, add_2reg(0xC0, dst_reg, src_reg));break;
3.修正BPF_CALL,当前的imm32 = func_addr-__bpf_call_base
/* call */case BPF_JMP | BPF_CALL:func = (u8 *) __bpf_call_base + imm32;if (!imm32 || emit_call(&prog, func, image + addrs[i - 1])) /*!*/return -EINVAL;break;
最后调用:
static int emit_patch(u8 **pprog, void *func, void *ip, u8 opcode){u8 *prog = *pprog;int cnt = 0;s64 offset;offset = func - (ip + X86_PATCH_SIZE); /*!*/if (!is_simm32(offset)) {pr_err("Target call %p is out of range\n", func);return -ERANGE;}EMIT1_off32(opcode, offset);*pprog = prog;return 0;}
计算出真正的bpf2bpf的调用地址。
4. 如果是exit指令,那么按照x64的方式回复栈空间。leave销毁局部栈
......case BPF_JMP | BPF_EXIT:if (seen_exit) {jmp_offset = ctx->cleanup_addr - addrs[i];goto emit_jmp;}seen_exit = true;/* Update cleanup_addr */ctx->cleanup_addr = proglen;if (!bpf_prog_was_classic(bpf_prog))EMIT1(0x5B); /* get rid of tail_call_cnt */EMIT2(0x41, 0x5F); /* pop r15 */EMIT2(0x41, 0x5E); /* pop r14 */EMIT2(0x41, 0x5D); /* pop r13 */EMIT1(0x5B); /* pop rbx */EMIT1(0xC9); /* leave */EMIT1(0xC3); /* ret */break;
5. 如果涉及到尾调用的情况:
case BPF_JMP | BPF_TAIL_CALL:if (imm32)emit_bpf_tail_call_direct(&bpf_prog->aux->poke_tab[imm32 - 1],&prog, addrs[i], image);elseemit_bpf_tail_call_indirect(&prog);break;
当imm修正好,深度允许时(小于MAX_TAIL_CALL_CNT),可以直接跳转到callee上(ip+adj_off)
static void emit_bpf_tail_call_direct(struct bpf_jit_poke_descriptor *poke,u8 **pprog, int addr, u8 *image){u8 *prog = *pprog;int cnt = 0;/** if (tail_call_cnt > MAX_TAIL_CALL_CNT)* goto out;*/EMIT2_off32(0x8B, 0x85, -36 - MAX_BPF_STACK); /* mov eax, dword ptr [rbp - 548] */EMIT3(0x83, 0xF8, MAX_TAIL_CALL_CNT); /* cmp eax, MAX_TAIL_CALL_CNT */EMIT2(X86_JA, 14); /* ja out */EMIT3(0x83, 0xC0, 0x01); /* add eax, 1 */EMIT2_off32(0x89, 0x85, -36 - MAX_BPF_STACK); /* mov dword ptr [rbp -548], eax */poke->ip = image + (addr - X86_PATCH_SIZE);poke->adj_off = PROLOGUE_SIZE;memcpy(prog, ideal_nops[NOP_ATOMIC5], X86_PATCH_SIZE);prog += X86_PATCH_SIZE;/* out: */*pprog = prog;}
否则,可以通过emit_bpf_tail_call_indirect ,通过indirect的一些检查后,可以实现goto *(prog->bpf_func + prologue_size); ,进而jmp到另外的bpf prog上。
....../* goto *(prog->bpf_func + prologue_size); */EMIT4(0x48, 0x8B, 0x40, /* mov rax, qword ptr [rax + 32] */offsetof(struct bpf_prog, bpf_func));EMIT4(0x48, 0x83, 0xC0, PROLOGUE_SIZE); /* add rax, prologue_size *//** Wow we're ready to jump into next BPF program* rdi == ctx (1st arg)* rax == prog->bpf_func + prologue_size*/RETPOLINE_RAX_BPF_JIT();
6. 最终在 prog->bpf_func 存放编译后的可执行代码。
unsigned int(*bpf_func)(const void *ctx, const struct bpf_insn *insn);
而在jit阶段很多指令都是基于EMIT来做转换的。
#define EMIT(bytes, len) \do { prog = emit_code(prog, bytes, len); cnt += len; } while (0)#define EMIT1(b1) EMIT(b1, 1)#define EMIT2(b1, b2) EMIT((b1) + ((b2) << 8), 2)#define EMIT3(b1, b2, b3) EMIT((b1) + ((b2) << 8) + ((b3) << 16), 3)#define EMIT4(b1, b2, b3, b4) EMIT((b1) + ((b2) << 8) + ((b3) << 16) + ((b4) << 24), 4)
举个例子。
/* mov r11, src_reg */EMIT_mov(AUX_REG, src_reg);/* mov dst, src */#define EMIT_mov(DST, SRC)
在EMIT_mov中首先校验了DST不等于SRC。之后调用了:
EMIT3(add_2mod(0x48, DST, SRC), 0x89, add_2reg(0xC0, DST, SRC));
在add_2mod中,根据DST,SRC的的值对于byte(指令字节码)做了编码修正。返回修正后的指令编码。
在add_2reg中基于如下的寄存器映射表继续编码修正传递的byte指令。
/* Encode 'dst_reg' and 'src_reg' registers into x86-64 opcode 'byte' */static u8 add_2reg(u8 byte, u32 dst_reg, u32 src_reg){return byte + reg2hex[dst_reg] + (reg2hex[src_reg] << 3);}
/** The following table maps BPF registers to x86-64 registers.** x86-64 register R12 is unused, since if used as base address* register in load/store instructions, it always needs an* extra byte of encoding and is callee saved.** x86-64 register R9 is not used by BPF programs, but can be used by BPF* trampoline. x86-64 register R10 is used for blinding (if enabled).*/static const int reg2hex[] = {[BPF_REG_0] = 0, /* RAX */[BPF_REG_1] = 7, /* RDI */[BPF_REG_2] = 6, /* RSI */[BPF_REG_3] = 2, /* RDX */[BPF_REG_4] = 1, /* RCX */[BPF_REG_5] = 0, /* R8 */[BPF_REG_6] = 3, /* RBX callee saved */[BPF_REG_7] = 5, /* R13 callee saved */[BPF_REG_8] = 6, /* R14 callee saved */[BPF_REG_9] = 7, /* R15 callee saved */[BPF_REG_FP] = 5, /* RBP readonly */[BPF_REG_AX] = 2, /* R10 temp register */[AUX_REG] = 3, /* R11 temp register */[X86_REG_R9] = 1, /* R9 register, 6th function argument */};
当 EMIT3 的三条指令编码全部修正完毕后,EMIT((b1) + ((b2) << 8) + ((b3) << 16), 3) 通过位移操作将三条指令整合起来作为参数。
最终调用 emit_code(prog, bytes, len); 直接将对应编码写入对应prog的内存中。
static u8 *emit_code(u8 *ptr, u32 bytes, unsigned int len){if (len == 1)*ptr = bytes;else if (len == 2)*(u16 *)ptr = bytes;else {*(u32 *)ptr = bytes;barrier();}return ptr + len;}
bpf_int_jit_compile
1. 首先申请addrs数组用来存储BPF指令翻译后的x64指令地址
addrs = kmalloc_array(prog->len + 1, sizeof(*addrs), GFP_KERNEL);if (!addrs) {prog = orig_prog;goto out_addrs;}/** Before first pass, make a rough estimation of addrs[]* each BPF instruction is translated to less than 64 bytes*/for (proglen = 0, i = 0; i <= prog->len; i++) {proglen += 64;addrs[i] = proglen;}
2. 对一个函数进行多轮pass,每轮pass都做jit,这是因为我们一开始jit的时候,很多后面的指令都没有生成,从而导致jmp跳转无法捕捉到最准确的距离,只能是按照上一步,先预留64bytes(偏大)。第一轮pass过后,addr中会储存每一条指令的偏移地址,但是由于jmp指令不准确,所以此时的地址不是完全正确的,指令长度(jmp)可能也有问题,而通过多轮pass来jit,指令长度不断收敛,直到 (proglen == oldproglen) 才得到准确的位置信息
/** JITed image shrinks with every pass and the loop iterates* until the image stops shrinking. Very large BPF programs* may converge on the last pass. In such case do one more* pass to emit the final image.*/for (pass = 0; pass < 20 || image; pass++) {proglen = do_jit(prog, addrs, image, oldproglen, &ctx);......if (proglen == oldproglen) {/** The number of entries in extable is the number of BPF_LDX* insns that access kernel memory via "pointer to BTF type".* The verifier changed their opcode from LDX|MEM|size* to LDX|PROBE_MEM|size to make JITing easier.*/u32 align = __alignof__(struct exception_table_entry);u32 extable_size = prog->aux->num_exentries *sizeof(struct exception_table_entry);/* allocate module memory for x86 insns and extable */header = bpf_jit_binary_alloc(roundup(proglen, align) + extable_size,&image, align, jit_fill_hole);if (!header) {prog = orig_prog;goto out_addrs;}prog->aux->extable = (void *) image + roundup(proglen, align);}oldproglen = proglen;cond_resched();}
3.当正确收敛之后,我们会分配空间保存再过最后一轮pass收敛后的jit结果。至此,jit完成。
ref
https://blog.csdn.net/m0_37921080/article/details/82530191
https://blog.csdn.net/liukuan73/article/details/102705963
https://www.cnblogs.com/LittleHann/p/4134939.html
https://www.cnblogs.com/bsauce/p/11583304.html
https://blog.csdn.net/s2603898260/article/details/79371024
https://blog.csdn.net/hjkfcz/article/details/104916719
本文为郭子仪同学原创文章,欢迎更多同学投稿。

