




上一篇已经分析过kube-proxy的任务、工作原理已经iptables模式的具体实现细节
本篇着重分析ipvs模式的实现细节
各种代理模式,唯一的区别就是proxier具体实现的区别
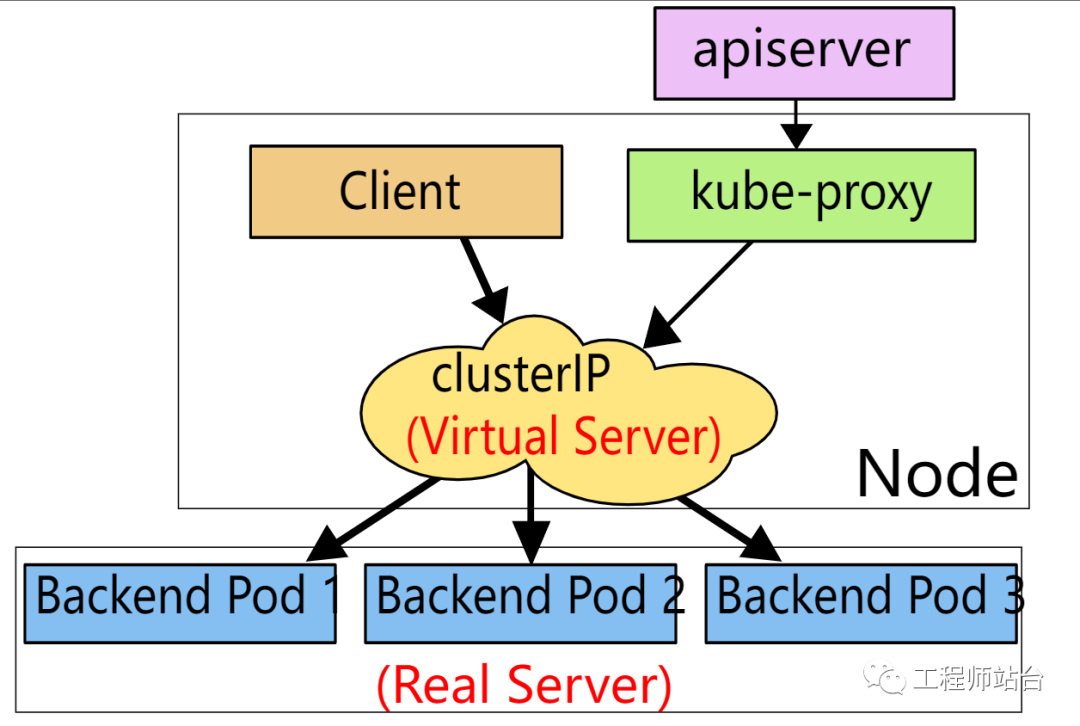
ipvs syncProxyRules流程
首先, 会和iptables模式一样,清空本地内存中的chain、rules信息并且在系统的默认chains上挂上kube相关的chain。在ipvs模式下,kube-proxy会把所有的SVC IP配置到`kube-ipvs0`这个dummy接口上,因为此模式下,不是依靠iptables的DNAT进行转化,所以需要让内核协议栈有这么这个dummy的IP存在,这样ipvs才能正常工作
// pkg/proxy/ipvs/proxier.go// make sure dummy interface exists in the system where ipvs Proxier will bind service address on it_, err = proxier.netlinkHandle.EnsureDummyDevice(DefaultDummyDevice)
其次, 对每个SVC建立ipvs的规则
// pkg/proxy/ipvs/proxier.go// Build IPVS rules for each service.for svcName, svc := range proxier.serviceMap {
1. 处理local的endpoints 设置KUBE-LOOP-BACK的ipset // Handle traffic that loops back to the originator with SNAT.
2. 处理svc对应的KUBE-CLUSTER-IP的ipset
3. 调用ipvs库对每个SVC进行ipvs server的配置(ADD/UPDATE)
4. 调用ipvs库对每个SVC的ENDPOINT进行ipvs server的配置(ADD/gracefuldelete)
5. 处理nodePort
1. 起socket bind nodePort(占坑)
2. 根据协议分别更新KUBE-NODE-PORT-TCP、KUBE-NODE-PORT-UDP、KUBE-NODE-PORT-SCTP的ipset
3. 和普通的SVC一样,调用ipvs库设置virtual-sever和real-server(virtual server直接指向nodeIP)
6. 同步所有的ipset(删除老的entry,添加新的entry)
7. 更新iptables(和iptables模式相同,主要是处理SNAT的规则, nodePort的引流)
8. 清理现场(清除UDP的conntrack状态)
ipvs vs iptables
个人理解的ipvs的优势主要有两点:
1. 引入了ipvs,使得k8s SVC的负载均衡策略可以根据需求进行设置(iptables模式下,只能采用随机策略)
2. 前端引流以及SNAT仍然需要iptables的帮助,但是ipvs模式下的iptables引入了ipset来帮助优化规则的数量,即规则数量是恒定的,SVC或者Endpoints的变化,只会影响到ipset集合里的配置已经ipvs的配置。
对于第二点,本质上iptables模式也可以进行同样的优化,但是意义不大,因为它只能优化SVC的条目,而没办法优化SEP的条目,因为iptables模式下需要依靠iptables的随机命中来完成“负载均衡”
calico官方对这两种模式有过比较详细的测试,结论是:
当SVC数量超过1000的时候,ipvs在性能上会有比较大的提升
If you aren’t sure whether IPVS will be a win for you then stick with kube-proxy in iptables mode. It’s had a ton more in-production hardening, and while it isn’t perfect, you could argue it is the default for a reason.
https://www.tigera.io/blog/comparing-kube-proxy-modes-iptables-or-ipvs/
https://kubernetes.io/docs/concepts/services-networking/service/
