




想入群的加我好友哈,公众号里面有我的联系方式~
作为最成功的第三方DL分布式训练插件,Horovod社区一直处于较为活跃的状态。从产品角度看,就仅仅是数据并行这一简单到不能再简单的切入点,Horovod依然能够源源不断地做出花来,用法简单,性能也好,确实是蛮厉害的。
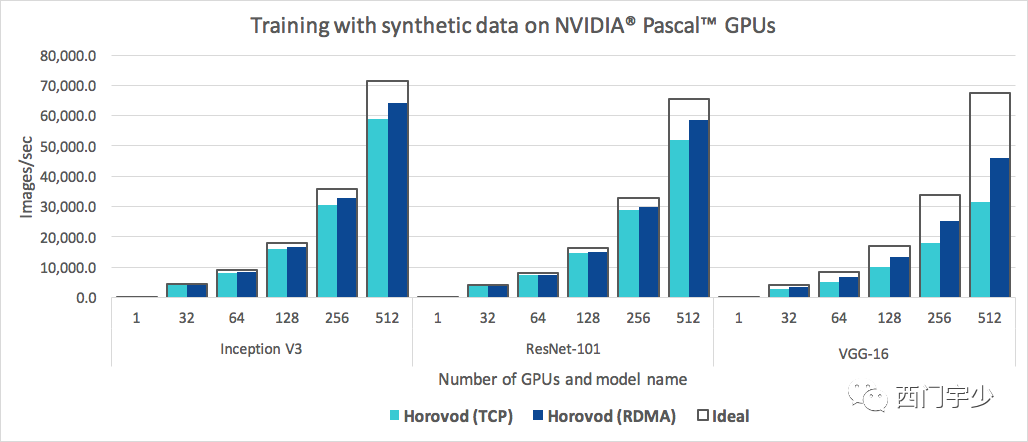
下面是Horovod的分布式伸缩性,现在哪一款DL分布式训练框架,在如此简单易用的情况下还能达到这么高的扩展性?
严格来说,我接触Horovod的时间也并不算长,更不算早。也是因为业务需要和技术调研,在2018年年底改过一次源码。如今再回看Horovod源码,发现多了很多新的功能和优化点。
今天做一个不够全面的梳理吧~
1
回顾一下用法
以使用TensorFlow做gradients的all reduce为例哈~
我把代码流程简化一下,一个使用Horovod的程序应该包含以下几块内容。
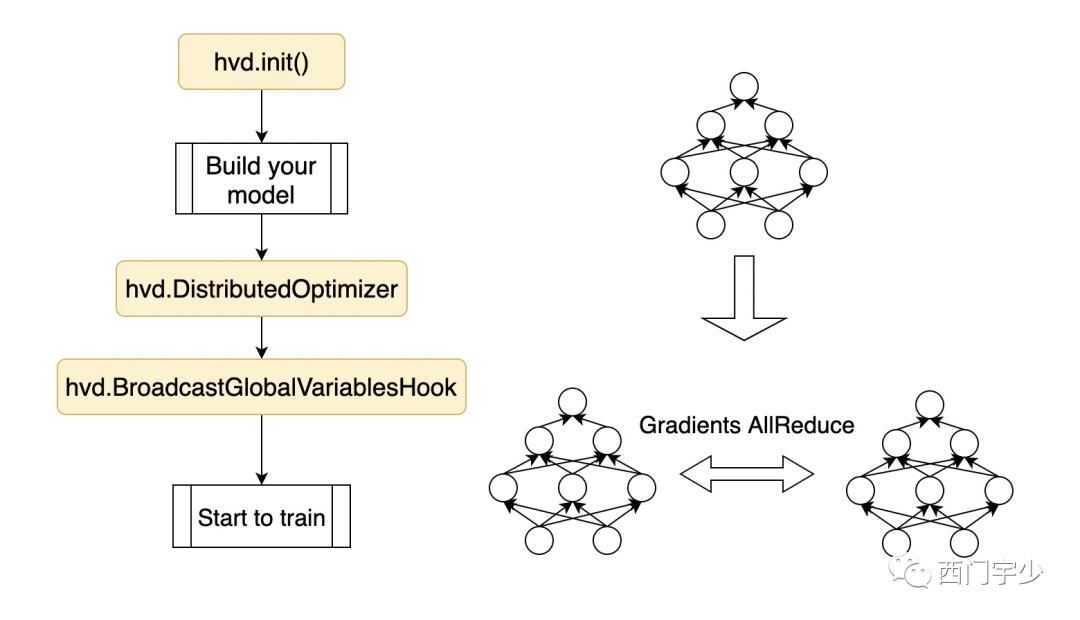
Horovod的设计宗旨并不是完全用户无感知,但力求以尽可能小的代码侵入性。具体地,在用户已经构建的代码上,只需要插入三段很短的代码即可:
hvd.init()
创建horovod的优化器,即DistributedOptimizer,将旧的优化器封装起来
创建horovod的初始化hook,即BroadcastGlobalVariablesHook,将master的初始化值广播给其他worker
虽然不是用户完全无感知,但Horovod易用性甚好。因为只要用户的代码没问题,Horovod这三段植入不会让你的程序break,这一点和其他若干Data Parallel产品不同(我就不点名了)。
2
在设计上避免死锁
在进入Horovod源码结构剖析之前,我们需要先注意下死锁的问题。如果你没在TensorFlow上设计过这种分布式工具,你可能会有一种先入为止的错觉,以至于认为这是一个非常简单的事~
这个坑就是——当backward产生一份gradients时,马上对其调用Collective AllReduce不就行了?
非也。这里有两点需要注意:
AllReduce这种调用可能是阻塞式的(MPI阻塞Host,NCCL阻塞Device),除非所有参与者做完,否则所占用的资源不会释放
TensorFlow的调度是动态的。这一次先执行A,下一轮可能先执行B
在这种情况下,如果遇到下面的case,你就死锁没跑了~
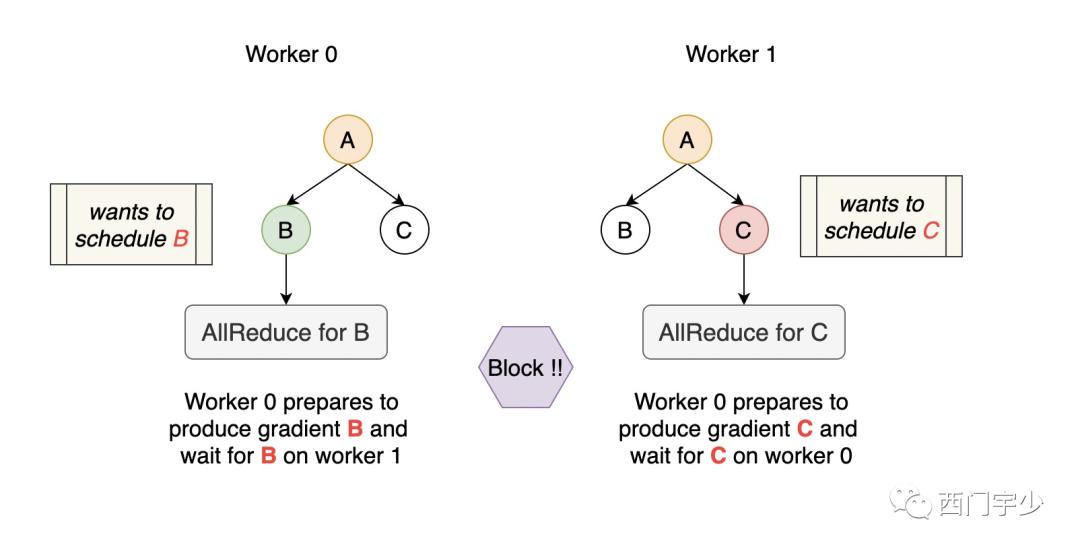
作为第三方轻量级插件,Horovod显然是不能限制具体框架的调度顺序的。所以只能直接解决这种case,这是Horovod框架中最复杂部分了。
3
复杂的启动流程
这里主要说的就是hvd.init()这个函数。用户的这一句话,启动了Horovod的所有轮询进程及资源管理过程,下图描述了hvd.init()的宏观调用栈,核心就是background thread上启动的BackgroundThreadLoop()函数,它将常驻在进程中并不断轮询,直到程序完全结束。
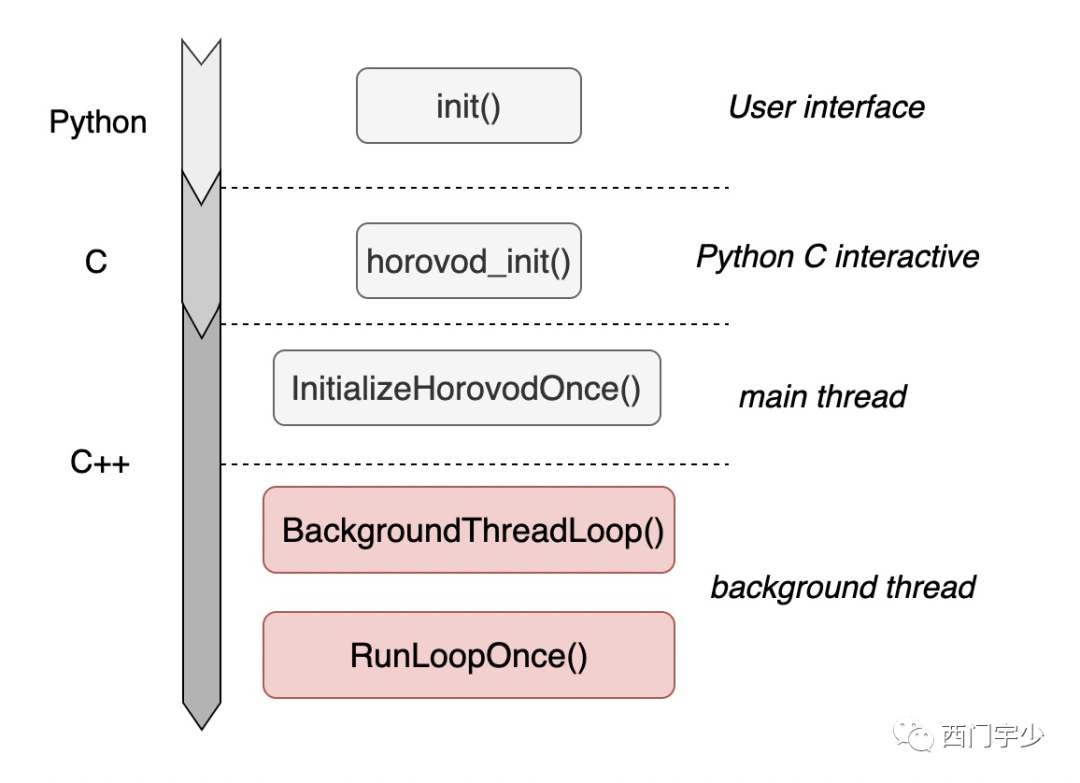
Horovod借助BackgroundThreadLoop()函数对RunLoopOnce()函数做无限循环调用。
4
防死锁?需协商
为什么需要BackgroundThreadLoop过程?这就是为了解决上一节中死锁问题而设计的解决方案。为此,我们需要重新思考一个重要的问题:
“若某份gradients已经产生,何时做AllReduce才能不死锁?”
显然,不可能见到一份gradients就马上做,因为这有概率会陷入死锁。正确答案应该是:
“当该份gradients在所有的worker上均已经产出时,才能统一发动AllReduce”
此时,不会有worker因为在等待其他某个worker没有产出该份gradients而进入无限等待的情况。那么就需要有一种机制,能够观察每份gradients在每个worker上的产出情况。
最简单的方式就是向rank 0发送报告,并计数。每个worker在产生某个gradients后(无论产生的是哪一份gradients),立即马上通知rank 0主节点,报告该份gradients已经产生。而rank 0接收到报告后马上令该gradients的计数器自增1,当该gradients的计数已经达到总worker数时,说明每个worker上都已经产生了该份gradients,此时rank 0向所有worker发送消息,令大家此时此刻一起发动该gradients的AllReduce过程即可。
从精神层面上,这个过程可以用下图表示。
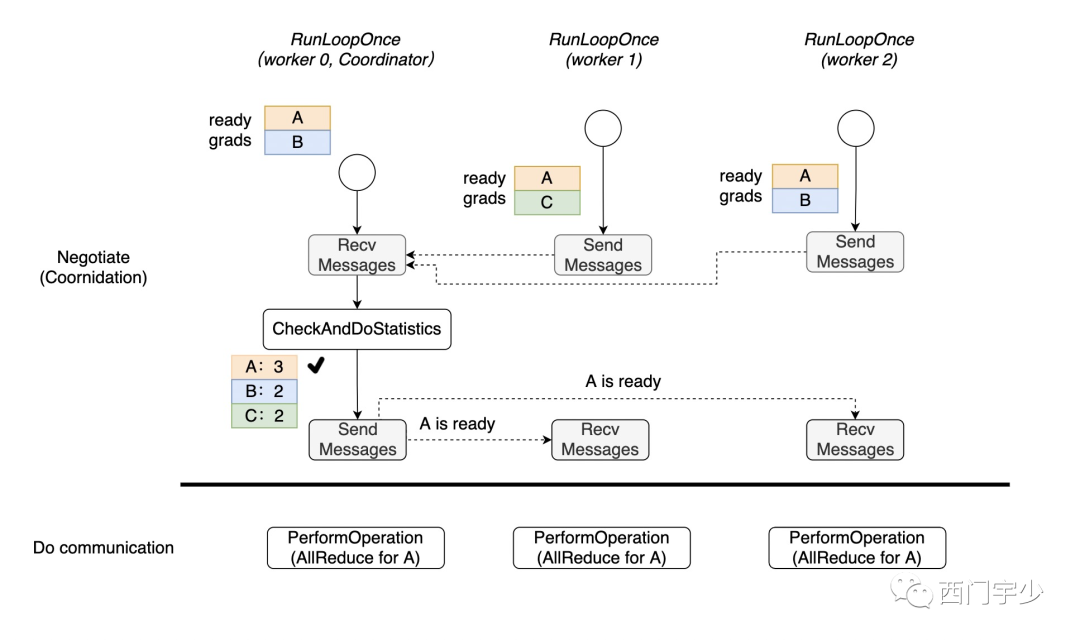
实际上,上述过程其实就是Horovod的做法。BackgroundThreadLoop为什么一直要轮询?就是要不断地做通知,计数等管理工作。因此,rank 0又被称为——Coordinator。等到真正需要做AllReduce时,RunLoopOnce会调用PerformOperation发动通信过程。
5
通信与Controller
为了防死锁,引入了协商机制,并将协商机制和真正的Collective通信分离开来。无论是协商,还是真正的Collective通信都需要发送接收消息。在架构上把他们区分开,将负责协商管控的通信handler称作controller,而真正的Collective通信则直接由PerformOperation调用即可。
目前看,Horovod有两种Controller,分别是MPI和Gloo。Horovod项目初始时只有MPI这个库作为Controller,但MPI这个库较重,并且Coordinator只用到其中非常有限的功能,所以直接依赖如此繁重的库不是非常合适,所以后期又加入了Gloo。
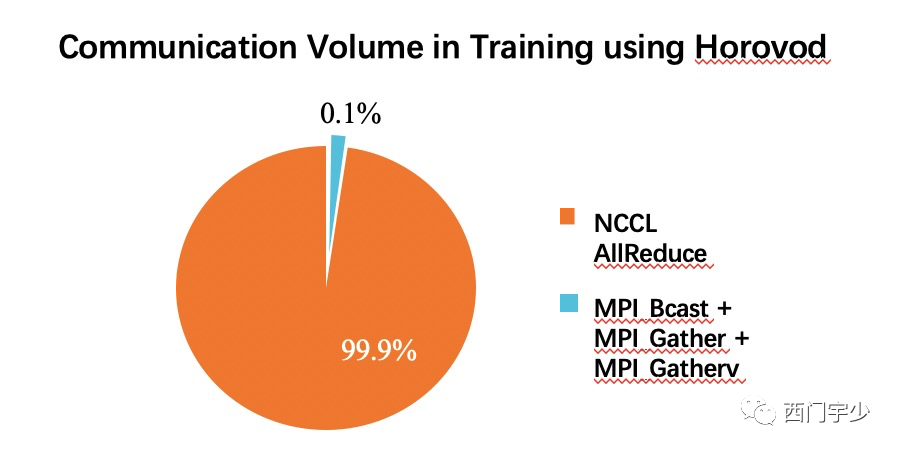
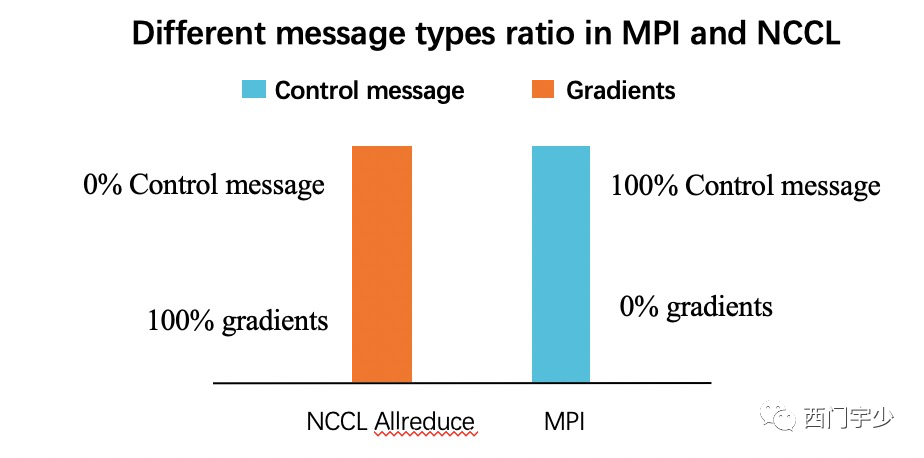
那么作为Coordinator的通信和真正的Collective通信相比,占比究竟有多少下图是我很久之前做的统计,可以看出Coordinator全部管控的通信非常小,几乎可以忽略不计。
6
整体代码架构
这里我偷个懒,直接转载知乎@文辉kimmy画好的图。这是原文链接,有兴趣的同学可以直接跳转过去:
Horovod源码分析
https://zhuanlan.zhihu.com/p/332825987
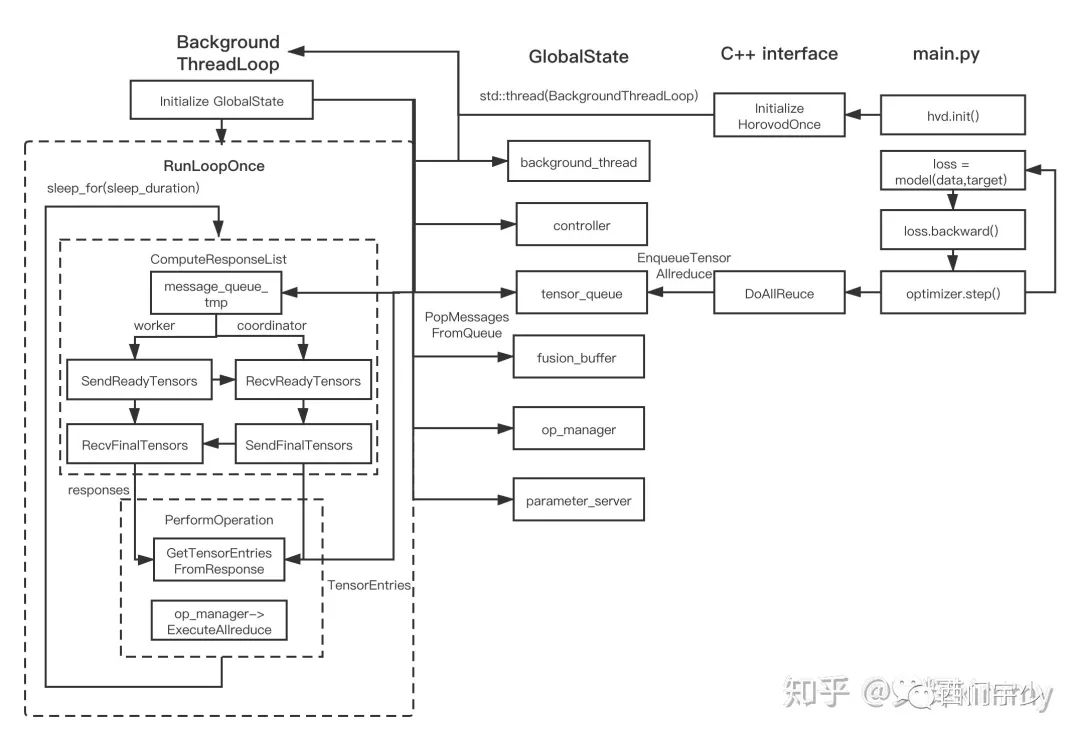
这张图是Horovod真正的流程图,有几个新朋友需要认识下。
GlobalState:其实是HorovodGlobalState。这是保存全局状态的结构。记得BackGroundThreadLoop所归属的线程由谁持有吗?就是此结构;
OpManager:在上图中,处于RunLoopOnce的PerformOperation函数中。是AllReduce的执行主体,可以是nccl,也可以是mpi等其他的通信库;
request和response:这些都是封装Coordinator消息的结构;
queue:这是维持生产者和消费者的桥梁。生产者是产生gradients的HorovodAllReduceOp,消费者就是BackgroundThread。
细心的朋友可能会发现,Horovod注册的Op都是Asynchronous的。而其ComputeAsync函数的作用就是将产生的gradients全部塞入上面提到的queue中。所以HorovodAllReduce等OP被launch,并不代表实际的通信已经被执行。
7
其他方面
一些可能影响性能的模块我也列入下面。
TensorFusion:实践表明,Tensor通信能否打满带宽和其size有关。太小的tensor被latency所牵连,所以将不同gradients做fusion一起通信可以提高性能。当然,也不能全fuse在一起通信,否则完全阻断计算通信的overlap;
BackgroundThread的轮询时间间隔:太频繁会增加Coordinator的压力,并且Tensor刚产出就被通信,也无法做Fusion;
AutoTuning功能:上面两个参数都决定了通信效率,人去调整太难,引入AutoTuning机制可以在运行时逐步调整。模块就是optim目录,原理是通过贝叶斯调参,在线调整。
Coordinator的Cache机制:主要解决Coordinator机制带来的中心化问题。有人测评当worker数量达到1024以上时,默认的协商机制会有明显的中心瓶颈,于是有人做了这个优化,具体的原理我还没有来得及看。
今天就到这里。你们还想了解什么,欢迎给我留言。
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
