




上回讲到了Naive Data Parallelism的使用场景,以及一些提升分布式训练效率的简单手段,这回简单说下PS Worker模式的相关内容。
1
训练场景回顾
回顾下PS Worker分布式训练的场景及必要性。同样,我们假设训练过程中使用了GPU。
对搜、广、推这种含有大规模稀疏Embedding层的模型,工业界中基本都是使用分布式训练,原因可归纳两点:
训练数据量很大,需要并行计算
模型参数量巨大,单卡可能承载不了
上述第二点,基本排除了Naive Data Parallelism的并行方式(每张卡不能完整存放一个模型),PS Worker模式就可以胜任这种case。
下图是PS Worker训练模式的经典原理图,两个部分:
PS模型分片部分:存放模型参数,且参数均摊存放到各个PS Server(内存)节点上
Worker数据并行部分:Worker真正的gradients计算,每个worker读取训练一部分数据
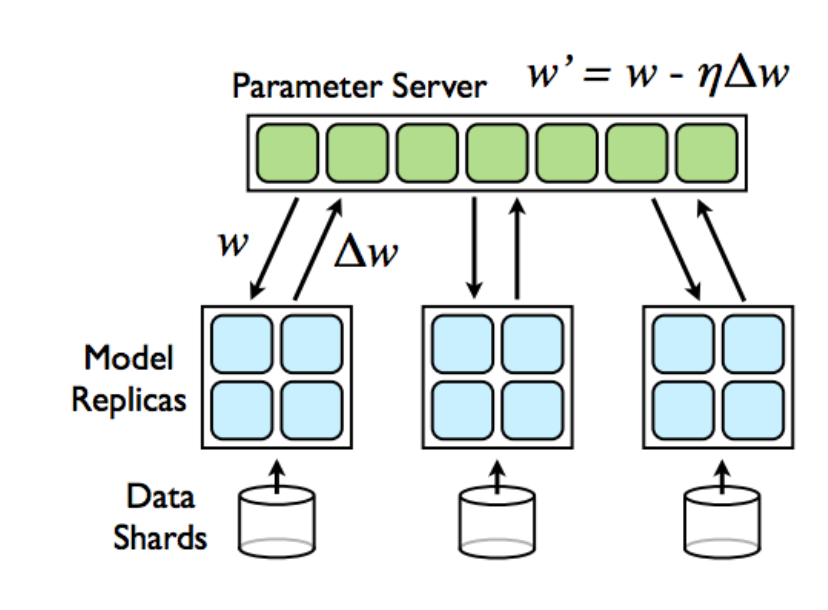
所以训练过程是,每个Worker都要从PS所有节点上拉取模型参数,经过本地计算之后,再把gradients上推给各个PS Server进行Apply Gradients。
当然,如果每个Worker要从PS上拉取全部的模型参数到本地才能计算,那么即使有Parameter Server帮你在PS端分摊存储,拉取到Worker时也必然会爆显存(OOM)。
所以,只有那些存在稀疏特性的大模型,才会从PS Worker这样的架构中收益。具体到模型中,就是具有大规模Embedding层的模型。
当发生embedding_lookup或gather操作时,只需要将ids发送到PS上做查询,然后将结果返回给Worker即可,这就避免了将巨大的embedding拉取到本地的过程。
两种过程对比如下图所示。

由于ids比embedding variable小的多,所以情况b虽然比情况a多了几次通信,但通信的代价是非常小的。
2
Placement与性能
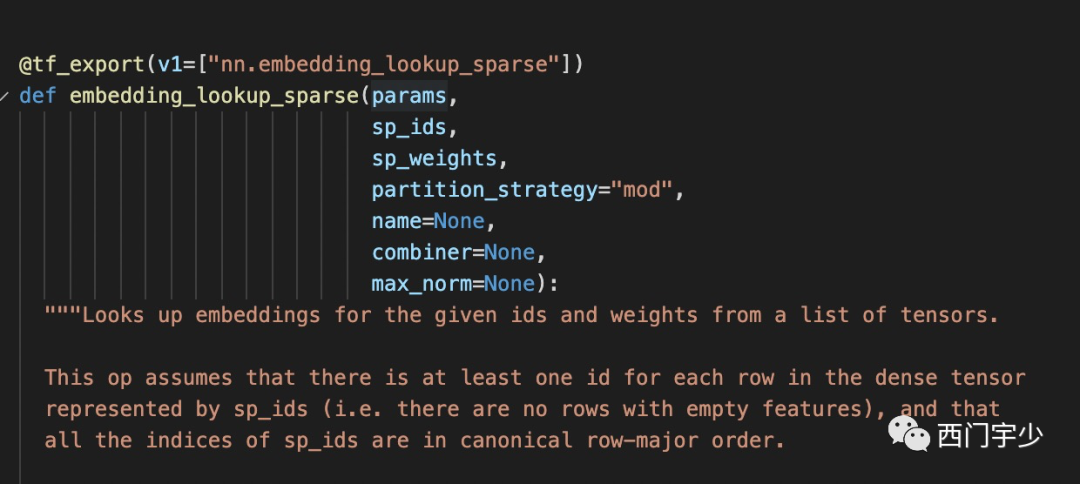
1. 尽量使用tf.nn.embedding_lookup代替tf.gather
PS Worker模式的Placement也会影响性能,其实上面已经见到了其中的一种,那就是——gather或embedding_lookup这个op的位置,它直接影响了显存的使用和通信的性能。
情况1——如果gather或embedding_lookup固定死放在worker上,那么势必会引起PS上的embedding variable拉取到Worker,这就是上图中的情况a。此情况不但通信量大(embedding拉取很昂贵),而且还容易在Worker发生OOM;
情况2——如果gather或embedding_lookup固定死放在PS上,那么势必引起ids发送到PS上,这就是上图中的情况b。
进一步分析,如果ids总是比embedding_lookup小很多,那么情况2总是优于情况1的。因此,我们只需要规定一种策略——让gather或者embedding_lookup总是和对应的variable放在一起就可以实现自动化。
事实上,TensorFlow的源码里也确实是这么做的,下图来自TensorFlow源码中embedding_ops.py。
红框内的colocate_with是TF控制placement的一种API,它表示with中的语句,其placement应该与params[0](即embedding variable)一致。因此tf.nn.embedding_lookup确实能够让gather与params[0]放在一起。
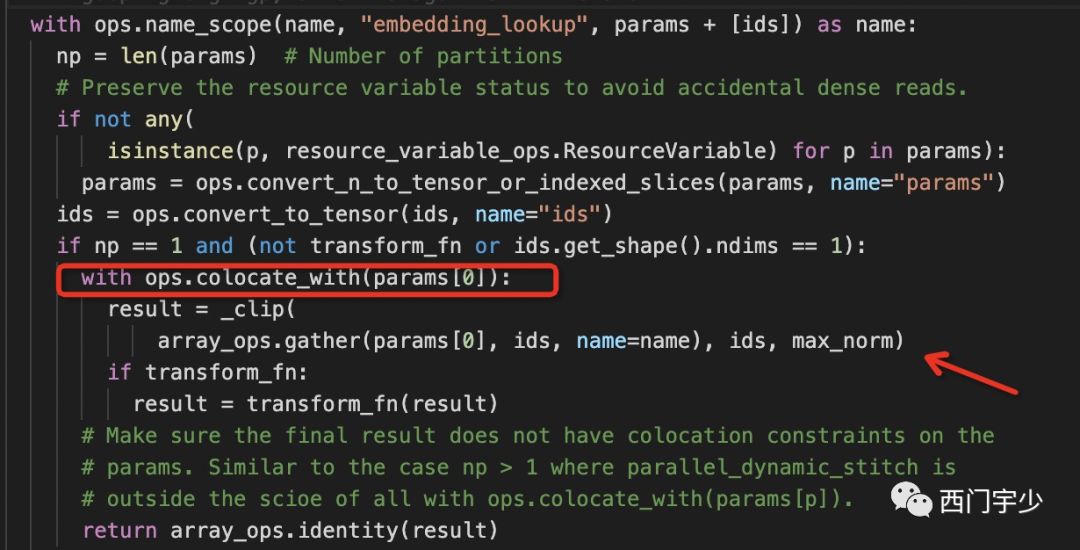
但如果你是用tf.gather这个API,那么就没有上面这种placement控制了,需要自己手动添加约束。
2. Embedding分片与Placement
巨大的Embedding variable如何负载均衡的放在各个PS上?其实是两个过程,分别是切片和Load ballance placement。
切片

一般情况下,num_shards设置成PS个数即可。在声明embedding_variable时,将此对象传入,即可生成切片后的variable。
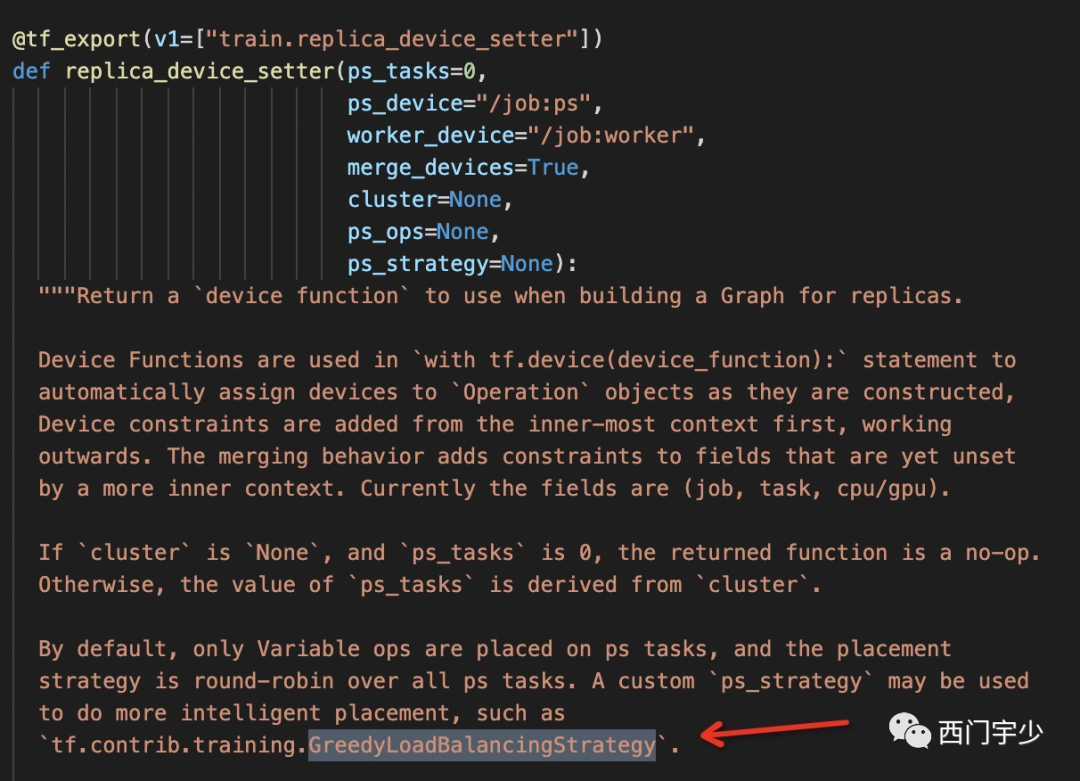
Load ballance placement
这是由另一种API控制的,它叫做device_setter,在使用PS策略时会使用round-robin的策略。当你的Embedding variable分片到与PS数目相同时,round-robin策略能够让每个PS Server放置其中一个shard。
如果某些Variable分片了,其他Variable没有分片怎么办?由于未分片的Variable粒度较大,此时round-robin确实会将整个Variable放到某一个PS Server上,造成各个PS Server负载不均衡,那么GreedLoadBalancingStrategy会帮你解决这个问题。
3
过度分片性能陷阱
分片是必要的,但过度分片就会引来其他问题了。
当Dense层分片时,Worker需要从PS上请求将所有Variable分片拉取到本地,待完整之后才可使用。拉取请求确实是按顺序发送给各个PS Server上,但Worker接受的顺序是随机的(取决于当时的网络拥塞程度,分片的大小等因素)。
下面Layer 1和Layer 2都实现了分片,但两种不同的下载顺序,决定了Layer 1开始计算的时机。
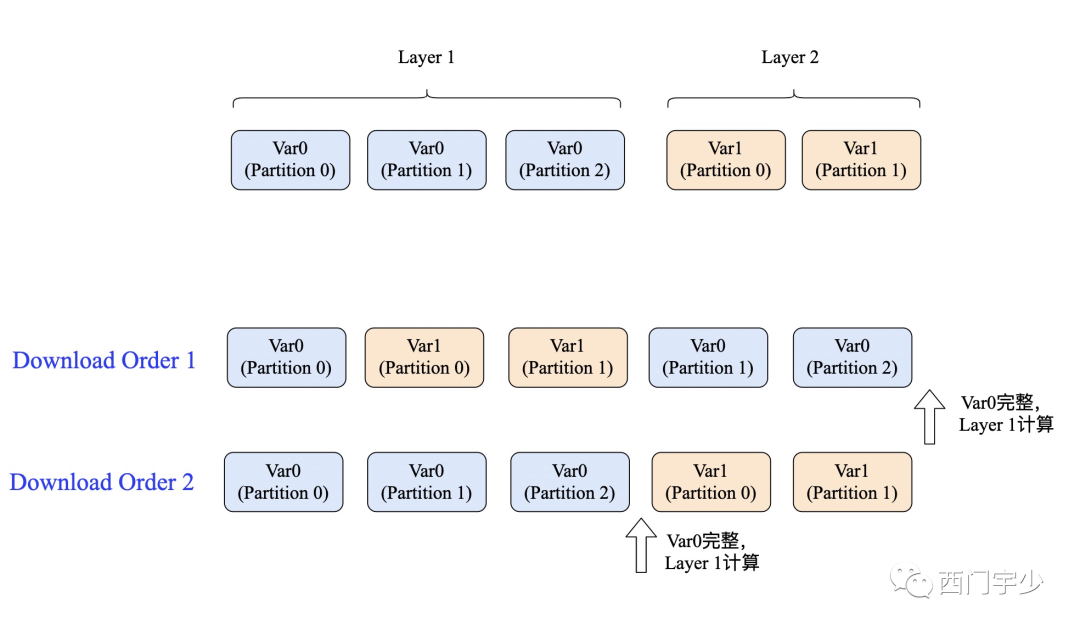
分片的粒度越细,此种情况发生的概率就越大。也可以通过调度控制来解决,但实现起来并不容易,且容易给框架增加更大overhead。
4
其他tricks
1. 使用Embedding_lookup_sparse
当我们扩大每个worker的batch size时,一个batch内的ids数量会增加,从而使发送到PS上的数据变大,通信变慢。
但我们统计后就可以发现,一个batch内部的ids还是非常稀疏的,即使batch增加很多,实际ids的种类增加很少。
Embedding_lookup_sparse中有去重的逻辑,这可以帮助我们进一步压缩通信量。
2. 异步代替同步
虽然SyncReplicasOptimizer提供了PS Worker模式下同步训练的机制,但该实现方式效率很差,并且TF2.0中已经将该API标记为deprecate。之后会不会有新的同步机制,我们只能拭目以待。
但对于稀疏场景,尤其是Embedding很大的情况,通过Learning rate调整,并使用异步训练做大规模训练一般是可以得到很好效果的。
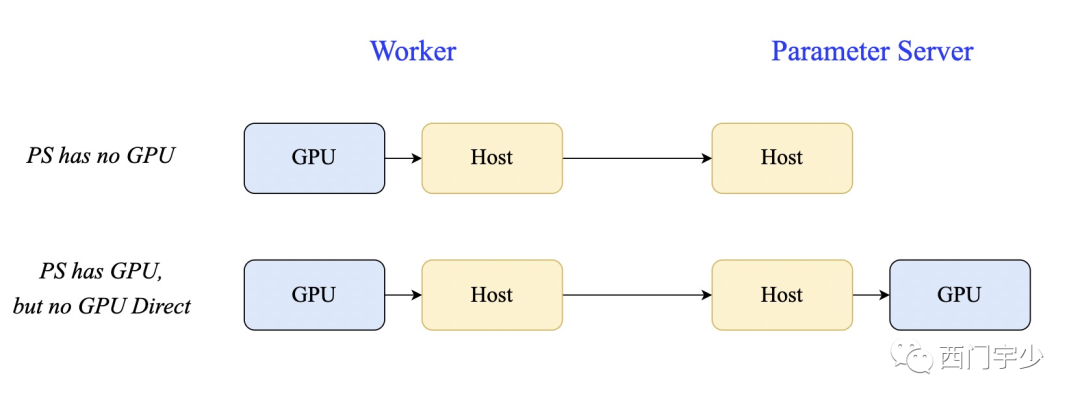
3. 一般情况下PS不需要GPU
这和通信效率有关。GPU利于面向计算密集型的任务。而对于搜、广、推业务中大多数的稀疏模型,PS上只有embedding_lookup以及apply gradients这两种操作,他们都是访存密集型。
何况,PS上引入GPU后,Worker向PS上发送数据将多一次Host->GPU的拷贝,有损于于通信性能。
4. 调整PS Worker的配比
理论上,Dense模型分片后,调整PS和Worker的配比为1:1就达到最优值了。而Sparse模型中,将ids发送到各个PS的均匀程度取决于ids的分布情况,因此只能通过实践去调整。一般情况下,PS:Worker的数量在1:3或者1:5较为理想。
5. 单卡能放下的模型
以TF为例,此时我建议你使用基于Ring AllReduce的数据并行方式。因为单卡能放下的模型可以使用NCCL这样的通信库,它能够自适应GPU连接拓扑,选择高效的通信方式。而对于PS Worker架构,通信只能使用gRPC等库,其发送前,接受后的序列化过程只会让通信带宽更低。
以上的trick都比较简单且容易实现,当我们在不改框架的情况下,优先尝试上述所有的经验后再做进一步地性能优化。
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
