





学习 探索 分享数据库知识和技术 共建数据库技术交流圈
8.1 概述
(1) AI4DB就是指用AI使能数据库,从而获得数据库更好的执行表现、实现数据库系统的自治、免运维等。主要包括自调优、自诊断、自安全、自运维、自愈等子领域。
(2) DB4AI就是指打通数据库到人工智能应用的端到端流程,统一人工智能技术栈,达到AI应用的开箱即用、高性能、低成本等目的。例如通过类SQL语句使用推荐系统、图像检索、时序预测等功能,充分发挥openGauss高并行、列存储等优势,提高机器学习任务的执行效率。同时,在数据侧实现AI计算,还可以降低数据的网络传输成本,实现本地化计算、节省人力、降低成本。
8.2 自调优
8.2.1 参数自调优的使用场景
(1) DBA要花费大量时间,在测试环境中对所要部署的业务进行调优;而每次上线新业务,调优过程需要重新来一遍,对于企业来说,人力成本巨大。
(2) DBA通常仅关注少部分关键调优参数,使得调优过程不能完全匹配业务,而且资源利用率及数据库性能并不一定是最优的。而且,其他次优参数与数据库表现的隐式关系也没有被充分挖掘出来。
(3) DBA通常只精通某一个特定的数据库调优,譬如擅长调优A数据库的DBA很可能不擅长调优B数据库,因为二者的底层实现存在很大差异,不可以使用同一套经验进行调优。同时,当硬件环境发生了变化,DBA的经验不一定能发挥作用。多业务混合负载场景下,也是如此。
8.2.2 现有的参数调优技术
1. 基于规则
2. 基于搜索算法
3. 基于监督学习
4. 基于强化学习
8.2.3 X-Tuner的调优策略
(1) 离线参数调优是指在数据库脱离生产环境的基础上进行调优的,一般是在上线真实业务前进行压力测试,并通过压力测试的反馈结果进行参数调优。
(2) 在线参数调优是指不阻塞数据库的正常运行,在数据库运行中进行参数调优或推荐的过程。
(1) recommend:获取当前正在运行的workload特征信息,根据上述特征信息生成参数推荐报告。报告当前数据库中不合理的参数配置和潜在风险等;输出当前正在运行的workload行为和特征;输出推荐的参数配置。该模式是秒级的,不涉及数据库的重启操作,其他模式可能需要反复重启数据库。
(2) train:通过用户提供的benchmark信息,迭代地进行参数修改和benchmark(一种用于测量硬件或软件性能的测试程序)执行过程,训练强化学习模型。通过反复的迭代过程,训练强化学习模型,以便用户在后面通过tune模式加载该模型进行调优。
(3) tune:使用优化算法进行数据库参数的调优,当前支持两大类算法,一种是深度强化学习,另一种是全局搜索算法(全局优化算法)。深度强化学习模式要求先运行train模式,生成训练后的调优模型,而使用全局搜索算法则不需要提前进行训练,可以直接进行搜索调优。如果在tune模式下,使用深度强化学习算法,要求必须有一个训练好的模型,且训练该模型时的参数与进行调优时的参数列表(包括max与min)必须一致。
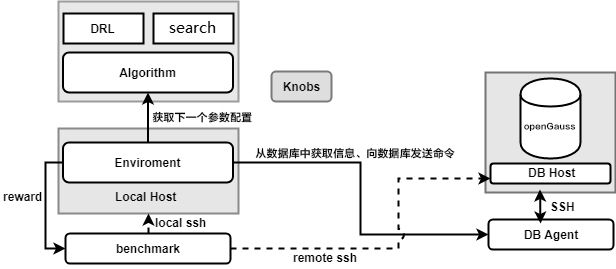
DB侧 | 通过DB_Agent模块对数据库实例进行抽象,通过该模块可以获取数据库内部的状态信息、当前数据库参数、以及设置数据库参数等。DB侧包括登录数据库环境使用的SSH连接 |
算法侧 | 用于调优的算法包,包括全局搜索算法(如贝叶斯优化、粒子群算法等)和深度强化学习(如DDPG) |
X-Tuner主体逻辑模块 | 通过Enviroment模块进行封装,每一个step就是一次调优过程。整个调优过程通过多个step进行迭代 |
benchmark | 由用户指定的benchmark性能测试脚本,用于运行benchmark作业,通过跑分结果反映数据库系统性能优劣 |
……(本节内容未完)
为提升您的阅读体验,完整版内容已运用专业格式发布到CSDN·Gauss松鼠会专栏,请扫码下方二维码,“关注”后进行内容阅读或点击文末“阅读原文”进入博客进行学习~





文章转载自Gauss松鼠会,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
