






引言
近日,南大周志华等人首次提出使用深度森林方法解决多标签学习任务。该方法在 9 个基准数据集、6 个多标签度量指标上实现了最优性能。
在这一讲中,你将会:
什么是决策树
如果我们在意模型的可解释性,那么决策树(decision tree)分类器绝对是上佳的选择。如同名字的字面意思,我们可以把决策树理解为基于一系列问题对数据做出的分割选择。
举一个简单的例子,我们使用决策树决定去不去见相亲对象
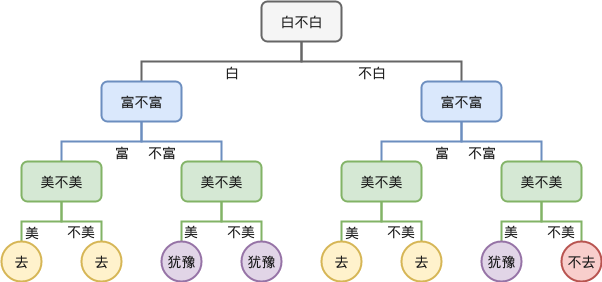
这就是决策树,每一层我们都提出一个问题,根据问题的回答来走向不同的子树,最终到达叶子节点时,做出决策(去还是不去)。
再比如我们可以用一个决策树来判断一个西瓜好瓜还是坏瓜:
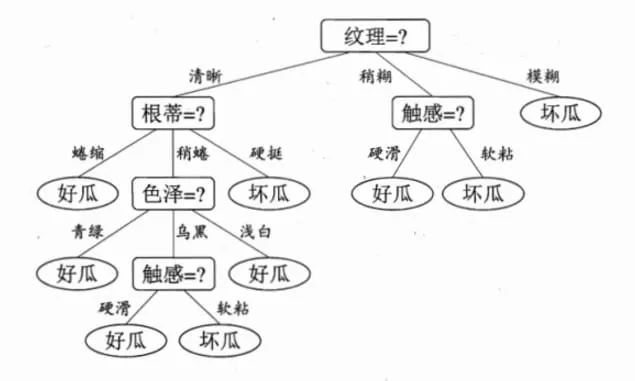
在上面的两个例子中,方框子树为特征,比如是“美不美”或者“触感”;
而分支的条件为特征下的数据,比如西瓜例子中触感:硬滑或者软粘。虽然上图中做出的每个决策都是根据离散变量,但也可以用于连续型变量,比如,对于Iris中sepal width这一取值为实数的特征,我们可以问“sepal width是否大于2.8cm
当一颗决策树的节点以及判断条件都被确定的时候,我们就可以带入数据进行决策。
如何训练决策树
对于一颗决策树,我们可以改变的东西有很多,比如改变节点的次序,改变判断条件,都会对整颗树带来改变。因此我们需要借助已经结果的数据,对决策树进行训练,来确定什么样的树可以帮助我们对分类问题有一个很好的解法。
我们介绍其中一个训练标准:最大信息增益。由此可以作为训练的目标函数:
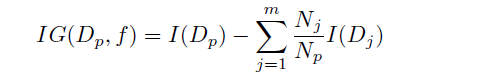
其中,f是具体的特征,Dp Dj是当前数据集和用特征f分割后第j个子节点的数据集,I是某种度量,Np是当前数据集样本个数,Nj是第j个子节点的数据集中样本个数。
常用的度量I包括基尼指数(Gini index)、熵(Entropy, )和分类错误(classification error)。
总结一下决策树的优点:
易于理解和解释 人们很容易理解决策树的意义。
既可以处理数值型数据也可以处理类别型 数据。其他技术往往只能处理一种数据类型。例如关联规则只能处理类别型的而神经网络只能处理数值型的数据。
使用白箱模型. 输出结果容易通过模型的结构来解释。而神经网络是黑箱模型,很难解释输出的结果。
可以很好的处理大规模数据 。
缺点:
训练一棵最优的决策树是一个完全NP问题 因此, 实际应用时决策树的训练采用启发式搜索算法例如贪心算法 来达到局部最优。这样的算法没办法得到最优的决策树。
决策树创建的过度复杂会导致无法很好的预测训练集之外的数据。这称作过拟合.剪枝机制可以避免这种问题。
决策树通过将特征空间分割为矩形,所以其决策界很复杂。但是要知道过大的树深度会导致过拟合,所以决策界并不是越复杂越好。我们调用sklearn,使用熵作为度量,训练一颗最大深度为3的决策树。还有一点,对于决策树算法来说,特征缩放并不是必须的。代码如下:
我们分成两个部分,第一个部分是定义一个画图函数:
from matplotlib.colors import ListedColormapimport matplotlib.pyplot as pltimport warningsdef versiontuple(v):return tuple(map(int, (v.split("."))))def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):# setup marker generator and color mapmarkers = ('s', 'x', 'o', '^', 'v')colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')cmap = ListedColormap(colors[:len(np.unique(y))])# plot the decision surfacex1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),np.arange(x2_min, x2_max, resolution))Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)Z = Z.reshape(xx1.shape)plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)plt.xlim(xx1.min(), xx1.max())plt.ylim(xx2.min(), xx2.max())for idx, cl in enumerate(np.unique(y)):plt.scatter(x=X[y == cl, 0],y=X[y == cl, 1],alpha=0.6,c=cmap(idx),edgecolor='black',marker=markers[idx],label=cl)# highlight test samplesif test_idx:# plot all samplesif not versiontuple(np.__version__) >= versiontuple('1.9.0'):X_test, y_test = X[list(test_idx), :], y[list(test_idx)]warnings.warn('Please update to NumPy 1.9.0 or newer')else:X_test, y_test = X[test_idx, :], y[test_idx]plt.scatter(X_test[:, 0],X_test[:, 1],c='',alpha=1.0,edgecolor='black',linewidths=1,marker='o',s=55, label='test set')
第二部分是用决策树学习数据:
from sklearn import datasetsimport numpy as npiris = datasets.load_iris()X = iris.data[:, [2, 3]]y = iris.targetfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=0)tree.fit(X_train, y_train)X_combined = np.vstack((X_train, X_test))y_combined = np.hstack((y_train, y_test))plot_decision_regions(X_combined, y_combined,classifier=tree, test_idx=range(105, 150))plt.xlabel('petal length [cm]')plt.ylabel('petal width [cm]')plt.legend(loc='upper left')plt.tight_layout()# plt.savefig('./figures/decision_tree_decision.png', dpi=300)plt.show()
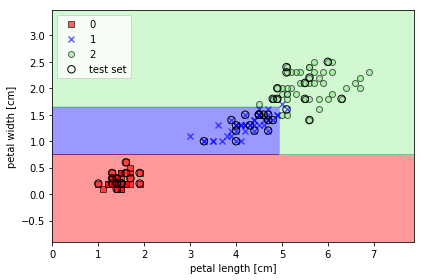
执行上面的代码,我们得到如下结果,决策界和坐标轴平行:
sklearn的一大优点是可以将训练好的决策树模型输出,保存在.dot文件:
from sklearn.tree import export_graphvizexport_graphviz(tree,out_file='tree.dot',feature_names=['petal length', 'petal width'])
然后利用GraphViz程序将tree.dot转为PNG图片:
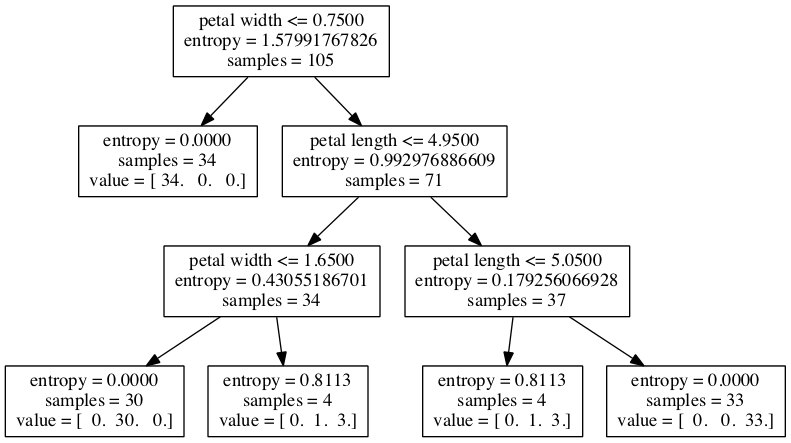
现在我们可以查看决策树在构建树时的过程:根节点105个样本,使用 petal_width <=0.75分割为两个子节点。经过第一个分割,我们可以发现左节点中样本都是同一类型,所以停止此节点的分割,右节点继续分割,注意一点,在构建决策树时两个特征各使用了两次。
参考资料:
https://lotabout.me/2018/decision-tree/
https://zhuanlan.zhihu.com/p/30059442
Python机器学习 Sebastian Raschka
前面的课程:
Python快速实战机器学习(1) 教材准备
Python快速实战机器学习(2) 数据预处理
·END·
可获得Python电子书
掌握机器学习
学会数据分析

