




上篇文章提出了云原生OLAP数据引擎,本文进一步描述配套的存储层设计,项目名叫ThinkBase。
由前文所述,OLAP数据引擎要达到真正云原生,在存储层需要解决2个问题:
如何利用好S3存储
如何设计好Disk Cache
为什么一定要S3存储,最显然的答案在于价格。然而一个额外的问题是,假设全部都用云盘,可以不可以?
这个问题,在开始设计的时候,我们一度认为是可以的,而且好处似乎很明显,就是不要做任何高可用了,反正云盘提供高可靠存储,只要计算节点可以任意编排,短暂的宕机对于OLAP数据分析来说是可以忍受的 。一个想当然的设计是,由K8S直接编排容器,并挂载Persistent Volume,当出现宕机的时候,由K8S重新启动一个容器,然后继续挂载到该PV(Persistent Volume)。然而实际上,这是不可行的:一方面,持久化数据卷,不能随意的跟容器挂载和卸载,另一方面,节点宕机,K8S的设计并不是编排新节点,而是等待人工介入,毕竟,持久化容器编排的复杂度要远远超过无状态容器。因此,云盘,或者块存储,即使去除价格因素,也不能作为主存储。
下一个问题就是,如何避免"副本on副本"的尴尬场景。前文中提到了RockSet公司开源的RocksDB-Cloud项目,提出了一种可以借鉴的可行方案:
RocksDB的LSM Tree生成sstable文件后,上传到远程S3存储
通过RocksDB内置的缓存机制,主要是Block缓存,统一管理本地硬盘和远端S3之上的数据缓存
数据写入到RocksDB-Cloud之前,首先写入到全局的WAL,例如全局的Kafka消息队列。WAL除数据之外,还包含各种元信息,例如sstable的合并记录
以上方案大体可行,但并不全面,因为:
RocksDB-Cloud来自于RocksDB Key-Value引擎,它本身并不适合作为OLAP的底层引擎,因为一个合理的OLAP数据引擎,其底层将依赖于列存,或者倒排索引结构。固然RockSet公司拿RocksDB-Cloud服务它的创业分析型数据库产品,但由于底层基于Key-Value抽象导致的开销,使得整体性能损耗严重
高可用机制。假定一个RocksDB-Cloud实例宕机,另外一个实例从全局WAL读取状态,然后继续提供写入请求,当数据达到一定程度,将sstable同步到S3存储,这时如果原来的RockDB-Cloud恢复,它也无法再处理写入请求了,否则将有2个RocksDB-Cloud实例同步数据到S3引起冲突。因此管理高可用,需要额外的协调工作
全局WAL是个麻烦的存在,如果依托于公有云的高可靠消息队列,这会增加成本和部署的复杂性,如果采用自己的方案,例如Apache Pulsar或者Kafka,不仅增加系统部署的复杂性,Pulsar/Kafka本身的维护也需要投入精力
ThinkBase解决以上问题的手段是依赖于自身研发的BeeHive分布式存储库[1]。BeeHive是一个Library,而不是进程,它来自于我们之前借鉴TiKV研发的Redis兼容分布式NoSQL引擎ElastiCell[2]。在开发ElastiCell的过程中,我们发现,基于Multi-Raft多组复制状态机协议管理分布式存储,几乎可以作为一种分布式存储的标准设计,其核心包含:
如何利用Multi-Raft协议管理多组的数据副本
如何以Raft组为单元对数据分布做Auto Rebalance。进一步的,如果没有Raft协议,该问题可以进一步扩展为,如何以组为单元,对数据分布做Auto Rebalance,这个逻辑对应TiDB系统的PD组件
基于以上两点,如果我们把这些功能抽象出来,并且做到方便部署,那么我们就可以提供多种一站式全栈框架,例如快速实现一个消息队列等等。在这里,尽管BeeHive的最初学习对象来自于TiKV,但在方便部署这方面,进一步借鉴了CockroachDB的设计思路:在整个集群中,不存在类似PD的角色,而是在集群中任选择3个节点承担类似角色,这样整个集群所需要的最小进程数就从6减少为3,大大方便了部署。一个极端的例子里,我们设计了一个支撑上亿个工作流的非典型工作流编排引擎[3],采用单一进程嵌入了消息队列,高可用工作流引擎,高可靠键值存储,极大地节省了部署和维护的开销:仅仅在3个节点上各启动一个进程即可完成全部部署。另一个例子,我们需要针对人工智能的向量检索提供高可用方案,采用BeeHive包装向量检索引擎,可以很方便的实现配套功能[4]。正是由于BeeHive库的存在,我们可以很方便的管理ThinkBase的底层存储:全局WAL由BeeHive自身承担;BeeHive搭配不同引擎管理ThinkBase的列存或者倒排索引;BeeHive在计算节点的本地硬盘上提供Raft-Based状态复制和高可用,但S3部分数据共享。有了BeeHive的存在,我们就可以提供高可用的Disk Cache,和共享的S3存储结合的方案,为各种云端引擎提供基础支撑。
需要指出的是,这种结构,并不是纯粹的计算存储分离,这主要是由于完全的存算分离,导致计算节点对于数据分布缺乏感知,因此网络开销较高。当然存算分离做为一种选项,在未来提供并不是一件难事,对于DBaaS类应用来说,完全的存算分离,可以方便的进行多租户计费管理。
在Disk Cache这个问题解决之后,我们来看一下进一步支撑OLAP分析型需求,存储上可以如何考虑。首先再次回到RockSet,我们来看看它的方案,如下图所示,它引入了一种称为Coveraged Indexing的技术:给定一条记录,要存3份数据:行存,列存,倒排索引,但是3者在底层都共用Key-Value接口,如下图所示:
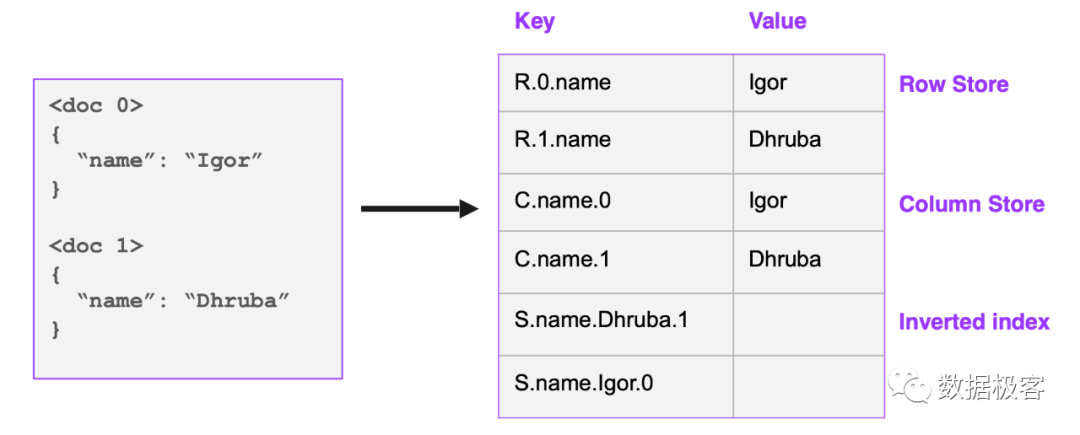
之所以这么任性,是因为S3太便宜了,因此多存几份数据,也不是什么大问题。在这里,行存服务类似于大规模Serving的点查询,列存服务大多数查询,而倒排索引则服务部分纯选择型查询,或者全文搜索。注意这里,按照Key Value接口抽象的列存,导致巨大的序列化开销,比优秀的列存实现(如ClickHouse)等慢10倍以上。而倒排索引,也是一种比较另类的设计。下图是典型的倒排索引结构:
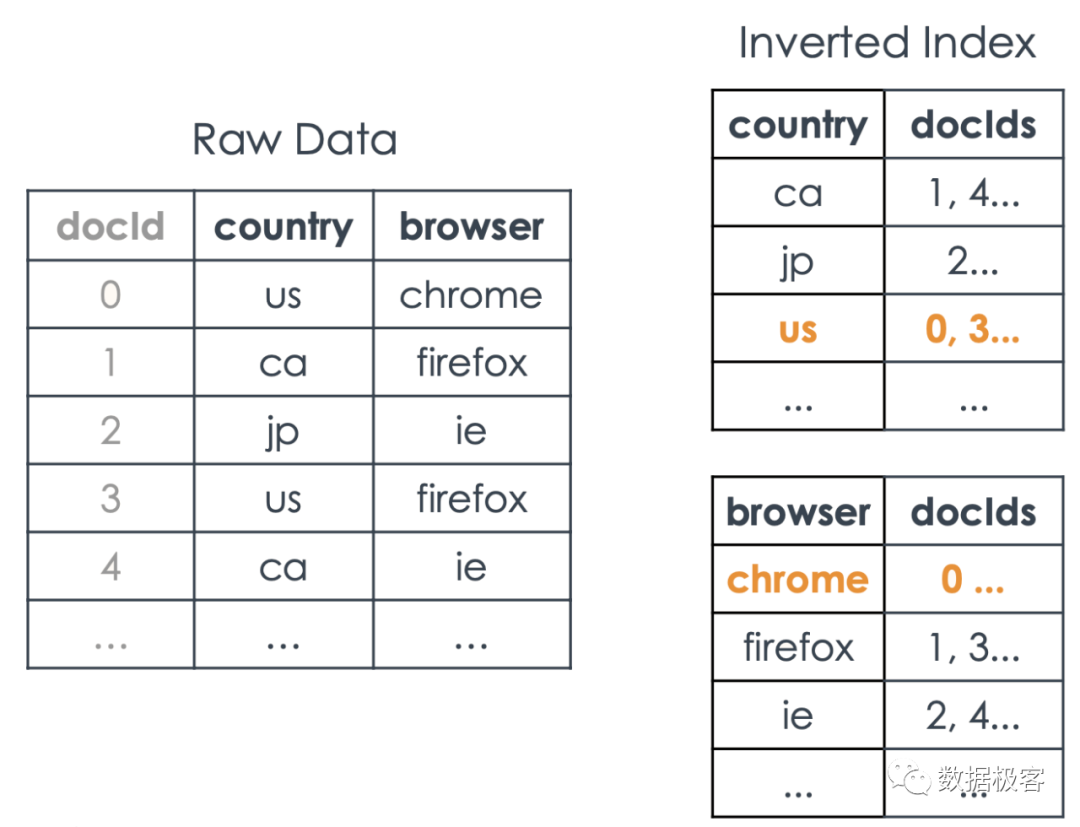
它由两部分组成,左列用来存放列值,右列则用来存放该列值在哪些行中出现过,因此用行号来表示。右列在学术上称作Posting List。假定某列数据不同的数值(称为基数Cardinality)较少,倒排索引显然具有更好的选择性。然 而,倒排索引本身在构建时会存在一些技术问题,例如:
如果将Posting List作为一个值存放到Key Value存储当中,会导致该值频繁更新,引起很大开销。
Posting List包含的是行号ID列表,通常会要求ID排序,否则对多个Posting List求交或者求并都很难处理。而这也导致Posting List本身的更新开销很大。
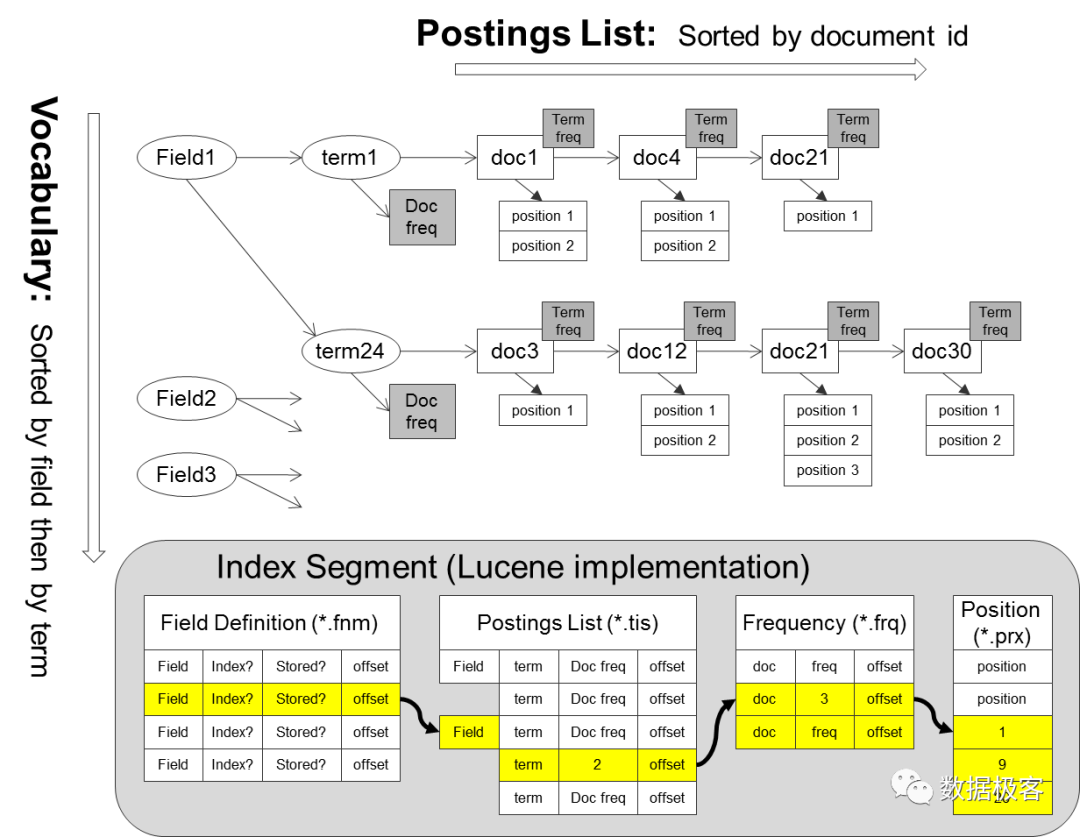
因此,倒排索引本身的构建,就是一个需要各种折衷和权衡的设计。常见的搜索引擎都会采用将Posting List整块存放的方式,以确保在查询时消耗的IO尽可能少。为规避Posting List更新的问题,搜索引擎通常选择将数据按块构建,块内Posting List避免更新。块的数量越多,查询性能越低,因此搜索引擎会内置各种Merge策略,在后台合并各种块的Posting List。RockSet对待倒排索引的方式,则是走了另一种通道:不将Posting List一起存放,仍然拆成多个单元。例如一个Posting List内容为:1,2,3,4,5,对应的列值 为"Hello",那么一个Posting List则拆分成5个Key 存放到Key Value存储当中:"Hello.1","Hello.2",...,"Hello.5"。这样,Posting List本身不会存在更新的问题,但在查询的时候会导致严重的性能瓶颈,因为任何一次查询, 都需要在Key Value数据库中做一次范围扫描,才能取出所有行号列表,而不像前文所述格式中的一次IO即可。在设计到多个Posting List的交并差等运算时,开销更大。互联网上公开的倒排索引查询性能测试对比网 页[5],包含多种流行的搜索引擎,如上的两种倒排索引方式都有对应产品,如Lucene采用前者,Bleve则 采用后者,两者性能平均差距在50倍以上,以至于Bleve目前已经从该对比网页被取下。后者这种倒排索引的做法,在一些支持全文搜索的数据库是这样做的,例如百度的BaikalDB等,这样处理,更多是因为方便用 单一Key Value引擎统一管理所有底层存储,同时照顾到更新性能,而非查询性能考虑。因此RockSet的存储 引擎设计,也是这样权衡的,这导致RockSet对于查询性能非常不友好,事实上,在RockSet的数据库解决方案中,倒排索引仅起到非常有限的用途。
跟RockSet类似,ThinkBase同样是一款基于S3构建的数据分析引擎,因此它也完全可以参照一份数据多份存储的路子,满足不同的需求。除去简单的大规模Serving依赖的点查询不提,剩下的关键,在于如何设计。对于列存格式来说,完全没有必要拘泥于RocksDB的Key Value格式,可以直接引入最好的MPP列存ClickHouse的方案。如下图所示,ClickHouse选择将列数据堆叠在一起,确保IO扫描时可以效率最大化,而非RockSet在列存外表下的本质上行存的数据组织。由于ThinkBase以及核心存储库BeeHive等均基于Golang语言开发,因此为方便计,ThinkBase嵌入了Golang的ClickHouse克隆版引擎VictoriaMetrics提供列存计算逻辑。
至于倒排索引,ThinkBase采用将Posting List一体化存放的搜索引擎路线。然而,ThinkBase并没有引用任何搜索引擎的开源库例如Lucene,这是因为搜索引擎在数据格式中引入了大量跟OLAP数据库无关的数据,通常用来做全文检索的排序因子,例如文本中的词频,位置信息等,如下图所示意,这些元素在数据库查询中都是无意义的,仅仅是行号列表ID List本身有意义。另一方面,由于在OLAP查询中涉及到大量Posting List的交并差操作,因此需要 确保Posting List的行号列表有序,所以ThinkBase直接采用Bitmap格式来表示Posting List。然而Bitmap在表示大整数和稀疏数据的时候,空间浪费过大,因此必须引入压缩技术。ThinkBase采用了基于Roaring Bitmap技术存放压缩过的Bitmap数据。
Roaring Bitmap本身是一个查询数据结构,支持非常快速的更新和随机访问,在求交操作中是最快的技术[6]。ThinkBase团队在2014年Roaring Bitmap技术刚出现的时候,就首先实现了其C++版本将其嵌入到某些特化的垂直搜索引擎中。而如今,Roaring Bitmap已经在不少的数据库,搜索引擎,乃至OLAP数据库中得到应用,在其官网都可以看到。然而,真正以Roaring Bitmap为存储核心来构建数据库,是非常少的, 在官网给出的采用Roaring Bitmap的列表中,绝大多数都是拿它作为辅助措施。例如:
流行的搜索引擎ElasticSearch也采用了Roaring Bitmap,但这并不是它索引的主格式,只是用来服务某些查询下的过滤操作
一些大数据引擎如Hive,Spark,Doris,Kylin也引用了RoaringBitmap,但这些引擎只用RoaringBitmap 解决查询中的去重问题
ClickHouse数据库的Roaring Bitmap正好是ThinkBase团队参与实现并完善,并且已经服务数据中台的建设。它在ClickHouse数据库中的角色是函数形式,无法跟存储引擎无缝对接,因此并不能参与到查询本身。而且,在增量实时情况下,Bitmap的数据需要重建,这会在部分场景下引起较大的开销和限制
类似Druid,Pinot这样的OLAP引擎,确实将 Roaring Bitmap 放到了重要的角色。事实上,它们的并发性能相比其他OLAP,确实有很大提升。然而,Druid和Pinot,主要用来服务仪表盘这样的简单 查询,对于复杂分析能力的提供,对于全面SQL能力的支持,还有很长的路要走
Pilosa是目前唯一一个以Roaring Bitmap为核心打造的数据查询引擎,它是一个仅有几个人的创业 公司,也是给了ThinkBase设计很多灵感的项目。它在能够提供的查询中提供了远超其他方案的并发性 能。然而,Pilosa本身是个较为简易的项目,在分布式架构,SQL能力上欠缺很多,因此能够支撑的场景非常有限
因此,ThinkBase几乎可以看作是一个完全以Roaring Bitmap为核心构建的开源OLAP引擎,这跟RockSet的设计理念相差很大:RockSet由于其倒排索引的选型,实际上在查询中绝大多数都以列存为主,而ThinkBase则在查询中,只要能够用到倒排索引,就一定会采用,因此这会导致两者在性能的差距很大。
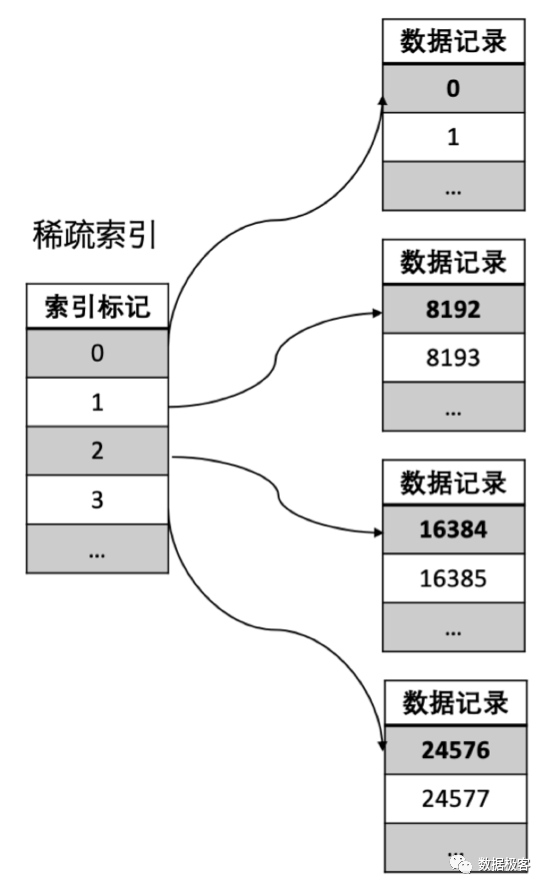
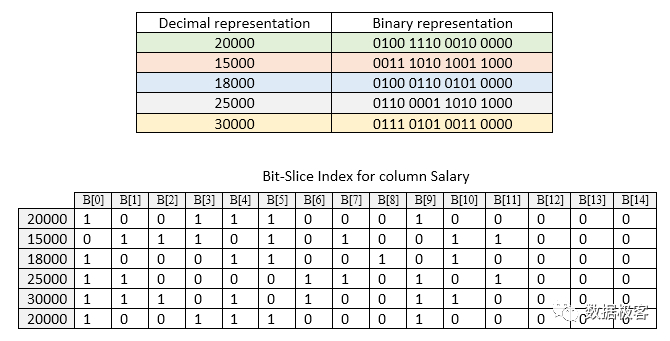
常规的倒排索引构建,通常围绕字符串文本类型。然而在OLAP数据库中,存在大量的数值类型列, 如果倒排索引无法对它们处理,那么能够满足的场景将会非常受限。针对数值类型,包括整数和浮点数,ThinkBase同样建立倒排索引,具体理念来自于BSI(Bit Sliced Index)[7]。其大概做法为:将选定的列值转换为二进制表示,并将其垂直切为Bitmap位图(位向量)。举例来说,在下图的employee表中,假设我们需要对工资这一列建立倒排索引。
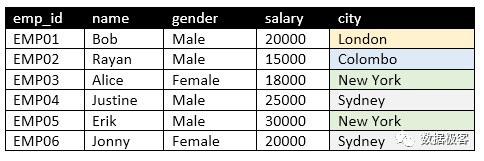
BSI对应的例子如下图所示。根据这个例子,我们只需要使用15个位图就可以表示 从0到30000的值。浮点数的处理需要我们自行应对,但其理念跟整数类似。有了BSI索引,意味着不论是字符串列,还是数值列,包括时间类型,地理位置,我们都可以建立配套的倒排索引,并且采用Roaring Bitmap压缩存放。这样,就大大扩展了倒排索引可以服务的范围,对于OLAP分析所需要的聚合查询,也可以快速通过若干位图操作得到结果,避免了列存引擎的大范围扫描。
倒排索引数据对接BeeHive的时候,同样不依赖RocksDB的Key Value接口,主要是避免RocksDB触发不必要的Merge开销。
即使Bitmap倒排索引功能强大,在遇到部分场景的时候,它仍然避免不了涉及到列存的操作,例如多列排序等。有一种设计思路可以把列存全部拿掉,跟倒排索引合二为一。这就是把倒排索引的Vocabulary部分(参见上面的倒排索引格式图),全局排序,这样就Vocabulary本身可以作为列存服务排序操作。然而,这导致数据插入开销过大,这方面是否存在更优的设计,还是个工程上值得考虑的问题。
跟RockSet的起步类似,ThinkBase在一开始的SQL引擎选择了借鉴CockroachDB。目前,提供分析查询能力的开源数据库的SQL引擎并不算多,主要包含如下几大类:
独立的SQL引擎如Apache Calcite,Google ZetaSQL。前者包含完整的SQL Parsing,查询计划,基于代价的查询优化等,已经在诸多大数据项目上采用,例如Hive,Flink,Drill等等,后者仅是个实验项目,缺乏完整的查询计划等关键组件。这些项目并不适合ThinkBase采纳,主要是语言限制(Java VS Golang)
大数据体系的Presto,Impala,Spark选择了自研SQL引擎,最快的列存数据库ClickHouse也选择了手写SQL引擎,企业级OLAP GreenPlum也有开源的ORCA,或许是最好的代价计算查询优化器。这些项目也不适合,除语言限制之外,部分SQL引擎能力相对较弱,例如ClickHouse,在处理多表JOIN方面的查询能力偏弱
定位于HTAP的数据库如TiDB和CockroachDB均在SQL引擎上取得了较好进展,ThinkBase 选择采用 CockroachDB 的SQL引擎进行修改,主要基于如下考虑:
选择已有开源SQL引擎修改可以大大加速实现进程
CockroachDB的SQL引擎完整度良好,模块更加清晰
CockroachDB实现了向量化加速引擎,避免了传统SQL计划火山模型导致的逐行扫描执行开销。TiDB的向量化引擎是在3.0之后才开始逐渐推出,在ThinkBase启动的时候,TiDB进度上略慢一些
TiDB的查询计划包含诸多下推操作,而下推操作跟TiKV整合过多,从架构上对ThinkBase友好度不如CockroachDB
尽管从CockroachDB入手,节省了大量时间,包含SQL Parsing,查询计划,向量化Pipeline执行,但由于ThinkBase的存储引擎特殊—主要基于倒排索引构建,因此对SQL引擎的修改工作很多:标准的SQL引擎, 即使实现了向量化Pipeline,也仍然是以传统行列存为基准抽象接口,采用倒排索引之后,关键SQL查询 如JOIN,Group By,Order By,聚合等执行逻辑,均有所不同。除此之外,ThinkBase还借鉴RockSet的理念提供配套的Smart Schema功能[8],这需要将SQL查询中的关键类型信息擦除,因此这也需要配套的修改。下面简要介绍ThinkBase部分SQL执行。
ThinkBase执行SQL的第一步是将SQL转义为关系代数的表达式,比如存在以下SQL:
select a, b from R where a > 1 and b < 3复制
则转义后的关系代数为π{a, b}σ{a > 1 ∧ b < 3}R。接下来ThinkBase会拆分限制的条件,比如上面的例子σ{a > 1 ∧ b < 3}R,会被拆分为a > 1和b < 3。对于该关系代数,因为属性a和属性b皆为数字,所以ThinkBase会从BSI索引中过滤得到位图m0和m1,然后计算m{0} ∧m{1}得到最终的位图。又比如σ{a > 1 ∧ c > "a" }R,首先需要拆分为a > 1和c > "a"。因为属性a为数字,所以ThinkBase会从BSI中过滤得到位图m0,属性c为字符串,此时首先需要通过统计值计算属性c的x = count / cardinal,根据x的值,ThinkBase会选择列存还是索引构建位图m1,然后计算m{0} ∧m{1}得到最终的位图。
下边以一个复杂的雪花SQL查询为例,简要描述SQL的执行逻辑:
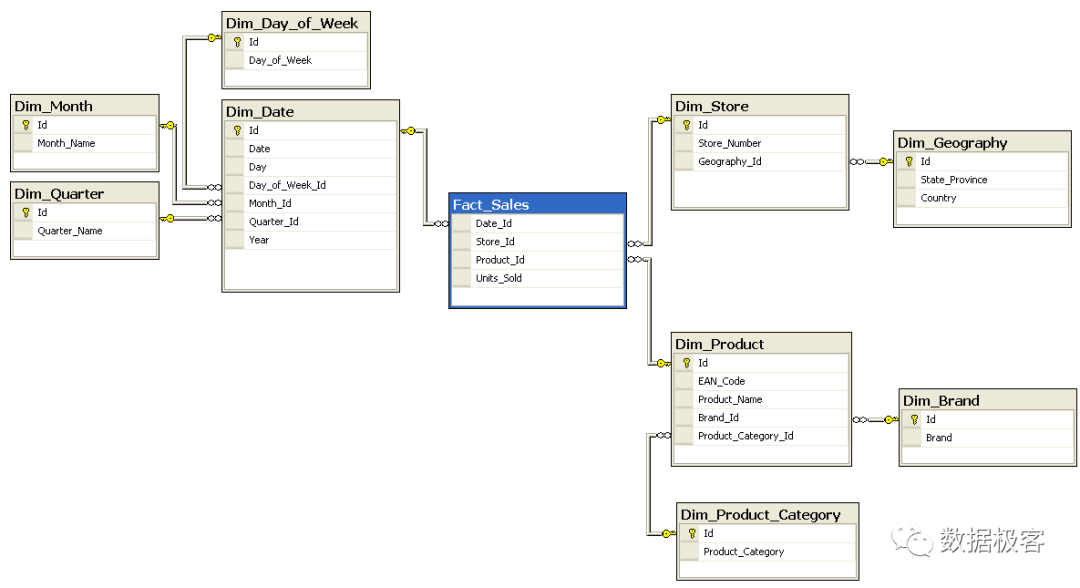
示例SQL:
SELECT
G.Country,
SUM(F.Units_Sold)
FROM Fact_Sales F
INNER JOIN Dim_Date D ON F.Date_Id = D.Id
INNER JOIN Dim_Store S ON F.Store_Id = S.Id
INNER JOIN Dim_Geography G ON S.Geography_Id = G.Id
INNER JOIN Dim_Product P ON F.Product_Id = P.Id
INNER JOIN Dim_Brand B ON P.Brand_Id = B.Id
INNER JOIN Dim_Product_Category C ON P.Product_Category_Id = C.Id
WHERE
D.Year = 1997 AND
C.Product_Category = 'tv'
GROUP BY
G.Country
对于上述sql,不考虑分组的话存在以下执行流程:
根据σ{D.year = 1997 }D得到位图m0
根据σ{C.Product_Category = tv }C得到位图m1
得到以下最基本的JOIN链路 S ⨝ G, S.Geography_Id = G.Id
(P ⨝ B, P.Brand_Id = B.Id) ⨝ C, P.Product_Categroy_Id = C.Id
((F ⨝ D, F.Data_Id = D.Id) ⨝ S, F.Store_Id = S.Id) ⨝ P, F.Product_Id = P.Id
我们首先考虑P, B, C的JOIN顺序,原始的顺序如下: (P ⨝ B, P.Brand_Id = B.Id) ⨝ C, P.Product_Categroy_Id = C.Id
除了上述顺序,还存在以下顺序:(P ⨝ C, P.Product_Categroy_Id = C.Id) ⨝ B, P.Brand_Id = B.Id
ThinkBase首先需要根据代价挑选采用哪种顺序,选择的原则为基数。假设此处P.Brand_Id的基数为100,P.Product_Category_Id的基数为100000, B.Id的基数为1000,C.Id的基数为10000 ( ( (位图m_1过滤))),则此处选择原始顺序为连接顺序。
接下来,我们考虑S,G的JOIN顺序,S ⨝ G仅仅是两个表的join所以无需考虑顺序,跳过
接下来,我们考虑F, D, S, P的JOIN,此处选择顺序的原则依旧是基数,ThinkBase会根据统计消息将(F.Data_Id, D.Id), (F.Store_Id, S.Id), (F.product_Id, P.Id)排序,然后得出基数从小到大的JOIN顺序。
此时只要根据得到的位图列表,依次输出结果即可 ( ( (根据位图的count选择行存或者列存输出)))
ThinkBase目前开发处于暂停当中。ThinkBase依赖的存储库BeeHive等处于生产可用状态,目前,为完善ThinkBase,还需要如下工作:
完成基于BeeHive的Disk Cache封装
将单机ThinkBase执行引擎跟分布式存储对接
探讨更优质的列存跟倒排索引合并方案
参考资料
[1] BeeHive https://github.com/deepfabric/beehive
[2] ElastiCell https://github.com/deepfabric/elasticell
[3] BusyBee https://github.com/deepfabric/busybee
[4] BeeVector https://github.com/deepfabric/beevector
[5] Search Benchmarks. https://tantivy-search.github.io/bench/
[6] Jianguo Wang, Chunbin Lin, Yannis Papakonstantinou, and Steven Swanson. An experimental study of bitmap compression vs. inverted list compression. In Proceedings of the 2017 ACM International Conference on Management of Data, pages 993–1008, 2017.
[7] Denis Rinfret, Patrick O’Neil, and Elizabeth O’Neil. Bit-sliced index arithmetic. In Proceedings of the 2001 ACM SIGMOD international conference on Management of data, pages 47–57, 2001.
[8] Using Smart Schema to Accelerate Insights from Nested JSON.https://rockset.com/blog/using-smart-schema-to-accelerate-insights-from-nested-json/.
