




在本号先前的文章中提到了若干用于深度学习的分布式框架,其中有一个工作叫GeePS,专门服务GPU集群的参数服务器,本文对该工作做个进一步介绍,这是因为相应的开源实现在不久之前刚刚公开[2],因此感兴趣的朋友也可以直接阅读原始论文[1]。
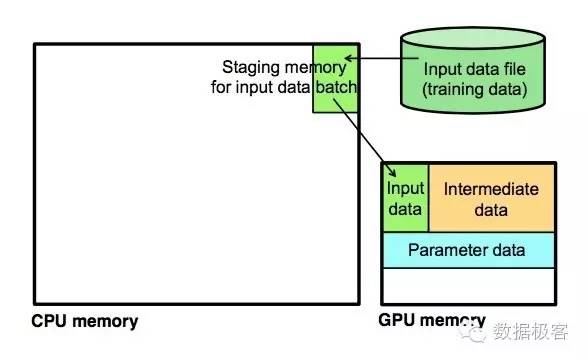
GPU设备的特性之一是拥有本地内存,任何数据都要首先加载到GPU本地内存后才可以进行计算。通常流程是:CPU从文件中读取一个mini-batch的训练数据,移动到GPU内存,然后由一个单线程worker调用cuBLAS以及cuDNN库,以及NVIDIA的其他库来进行GPU运算。这个过程如下图所示。
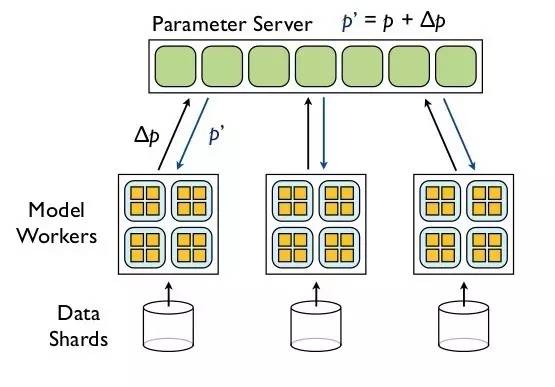
参数服务器是分布式机器学习的重要架构模式,在参数服务器中,模型参数存放在一个共享的分布式Key-Value中,它就是参数服务器本身。运行机器学习程序的Worker节点采用Read和Update两个接口跟参数服务器通信,由参数服务器本身来控制通信开销和一致性收敛。
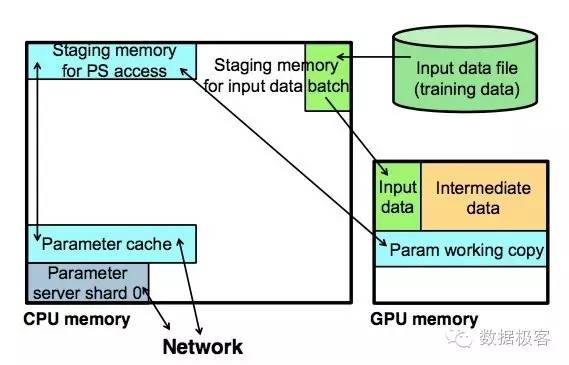
然而,通用的参数服务器设计都是围绕着以CPU为中心的体系结构来设计的,由于前图中所示的操作GPU的限制,如果没有把这部分因素考虑到参数服务器本身的设计中,会引起更高的通信开销。例如下图所示:参数服务器的参数sharding,存放在CPU内存中,而在运行在GPU内部的模型参数,在CPU中也有一个本地拷贝。因此,数据需要在三者之间双向移动。
GeePS就是针对GPU访问的特点专门提出的参数服务器架构。在GeePS中,参数sharding直接存放在GPU中,因此把前述架构中的三方数据双向复制减少为双向,如下图所示;同时,GeePS把GPU和CPU之间的数据搬迁还放到了后台执行。
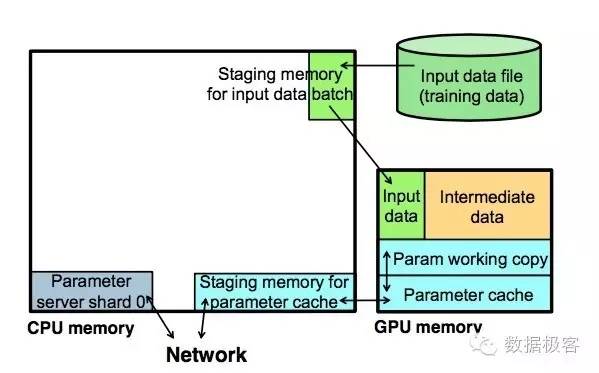
单纯把参数Key-Value存放的地点从CPU移动到GPU并不能完全解决问题,这是因为GPU的数据读取会非常缓慢,因此放到通用的参数服务器架构之下,这会由于每个Key-Value的同步读取大大降低吞吐量。因此,GeePS所做的进一步工作是引入批量参数操作,管理GPU内存,把模型当前不需要的参数通过后台线程迁移到CPU,从而最小化因为等待数据传输而造成的同步开销。
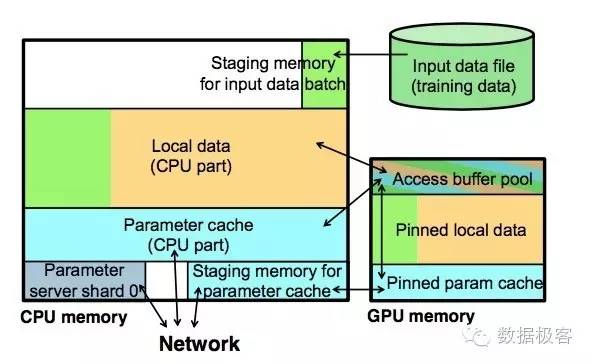
具体来说,相比于通用参数服务器的Read和Update接口,GeePS额外提供了PostRead和PreUpdate两个接口,当应用需要读取参数时,参数服务器在GPU内存中分配一块缓冲区,并返回指针,读取结束后,由PostRead负责释放缓冲区,该接口是非阻塞操作;当应用需要更新参数时,首先通过PreUpdate获得缓冲区,而非阻塞的Update接口负责更新参数和释放缓冲区。因此,思路很简单,利用非阻塞IO在不同内存之间交换数据,提升吞吐量,避免单条记录读取的同步开销引起的性能问题。GeePS的这种缓冲区设计,实际上也管理起了整个GPU内存,因为GPU的内存尺寸总是有限的,把参数服务器的Key-Value都放到GPU内存中显然并不现实,通过在后台不停歇的在CPU和GPU之间进行数据交换,从而实现了在少量GPU内存存放巨大模型参数的可能。这种基于缓冲区的数据交换设计可以在下图中更清晰地看出来。
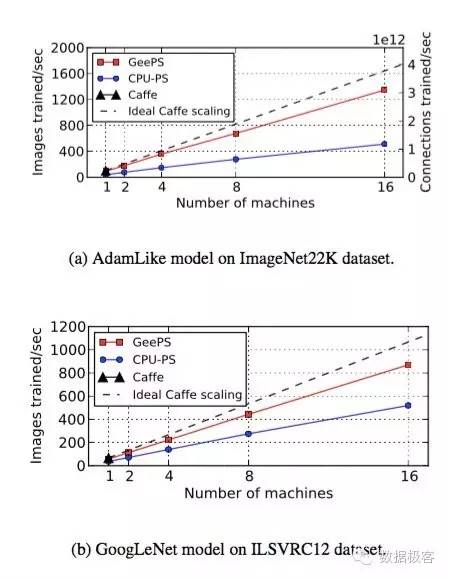
由此可见,GeePS的思想和实现并不复杂,就是利用GPU数据访问的特点引入分布式参数缓存。根据作者进行的试验,GeePS在中小型GPU集群上取得了近乎线性的性能提升:16台节点的集群相对于单个机器提升了13倍,相对于基于通用CPU的参数服务器设计则获得了2倍左右的吞吐量。
[1] Henggang Cui, Hao Zhang, Gregory R. Ganger, Phillip B. Gibbons, and Eric P. Xing. GeePS: Scalable Deep Learning on Distributed GPUs with a GPU-Specialized Parameter Server. In ACM European Conference on Computer Systems, 2016 (EuroSys'16)
[2] https://github.com/cuihenggang/geeps
