




传统的TCP/IP协议栈都是运行在内核态的,然而,近年来已经越来越多的高性能项目采用了用户态TCP/IP协议栈,这是为什么呢?
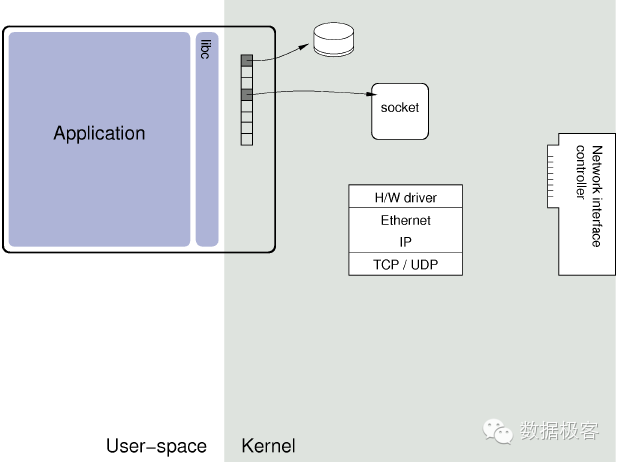
传统的协议栈工作如下图所示:
用户态的协议栈工作如下:
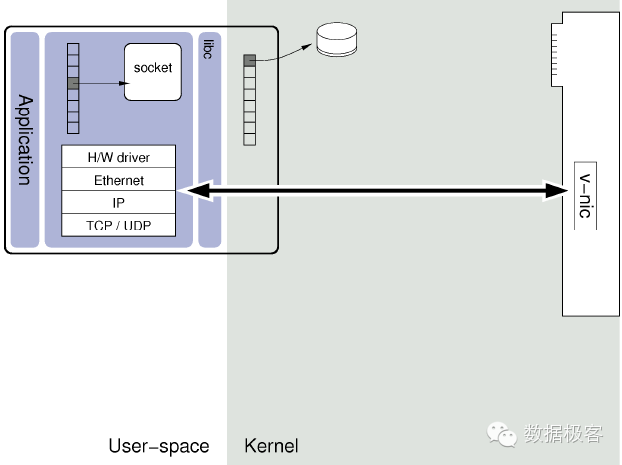
海量的数据请求下,Linux内核在TCP/IP网络处理方面,已经成为瓶颈,这是因为:一个完整的TCP连接,中断发生在一个CPU核上,但应用数据处理可能会在另外一个核上,不同CPU核心处理,带来了锁竞争和cache miss。比如新浪在某台HAProxy服务器上取样,90%的CPU时间被内核占用,应用程序只能够分配到较少的CPU时钟周期的资源,经过Haproxy系统详尽分析后,发现大部分CPU资源消耗在kernel里,并且在多核平台下,kernel在网络协议栈处理过程中存在着大量同步开销。类似的分析在其他报告中也有看到,例如mTCP的研究者通过profiling lighthttpd也发现超过80%的时间花在内核态,开销主要在锁竞争,缓冲区管理,以及频繁的上下文切换。这幅图形象的展示了用户态协议栈的线程模型跟内核态的区别:

采用用户态协议栈后,可以通过几个方面的工作提升性能:
1) 系统调用以及处理数据包的时间花费减少,不需要像内核态协议栈那样依靠中断来唤醒内核处理数据包。用户态协议栈,将不存在Socket IO这样的系统调用,取之以普通的库函数调用。
2) 不需要进行数据包的内存分配:采用数据包池,当有数据到达后,直接从数据包池中取出一个数据包,然后将数据放入此数据包中,再将数据包的描述符放入接收环中。
3) 数据拷贝次数少:内核中的数据包采用mmap技术映射到用户态。所以数据包在到达用户态时,不需要进行数据包的拷贝。
4) 内核只操作个别CPU,应用程序管理其余的CPU,这样中断就不会发生在不允许的CPU上。
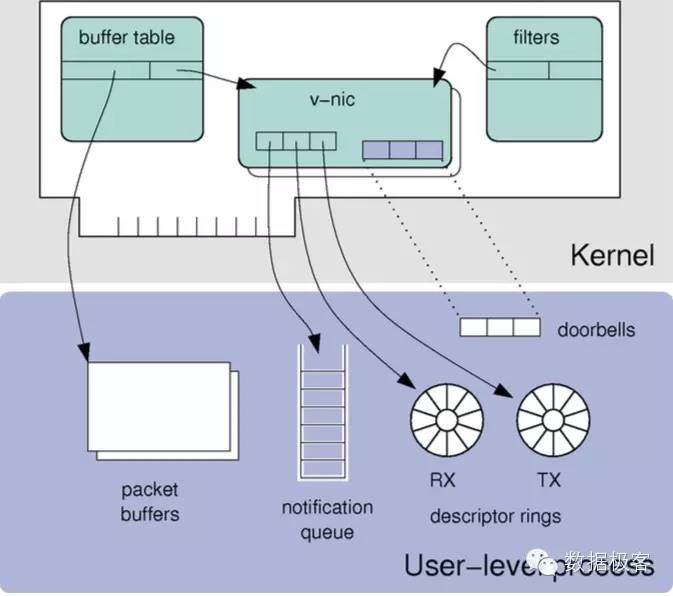
网络并发程序设计在过去的十多年中解决的是C10K问题,既通过异步处理避免线程式的编程模型,可以让单个服务器支撑10K级的并发连接。然而,在接下来,系统所面临的挑战则从C10K升级成为了C10M(不要真觉得这样毫无必要,未来万物互联的时代,一切都是可能的),既如何让单个服务器支撑千万的并发连接。传统的做法仍然是在调整内核参数,提高文件数,降低每个连接的内存消耗等方面做文章,然而用户态协议栈则给了更好选择的可能。
实现用户态协议栈,需要注意针对每个cpu设定独立的数据结构,确保无锁冲突,并设定cpu亲和性以及引入cache友好的数据结构。用户态网络层的工作有很多,主要分为两类,一类是完整的TCP/IP协议栈,例如韩国人的工作mTCP等,另一类是包转发引擎,例如Intel DPDK,剑桥的CamIO(就是那个孵化了Firmament集群调度器的CamSas项目),Netmap(用于BSD)等,其中DPDK是最广泛使用的一种。完整的TCP/IP协议栈往往利用后者作为核心引擎实现,除此之外,DPDK也已经有一些其他的成功应用:
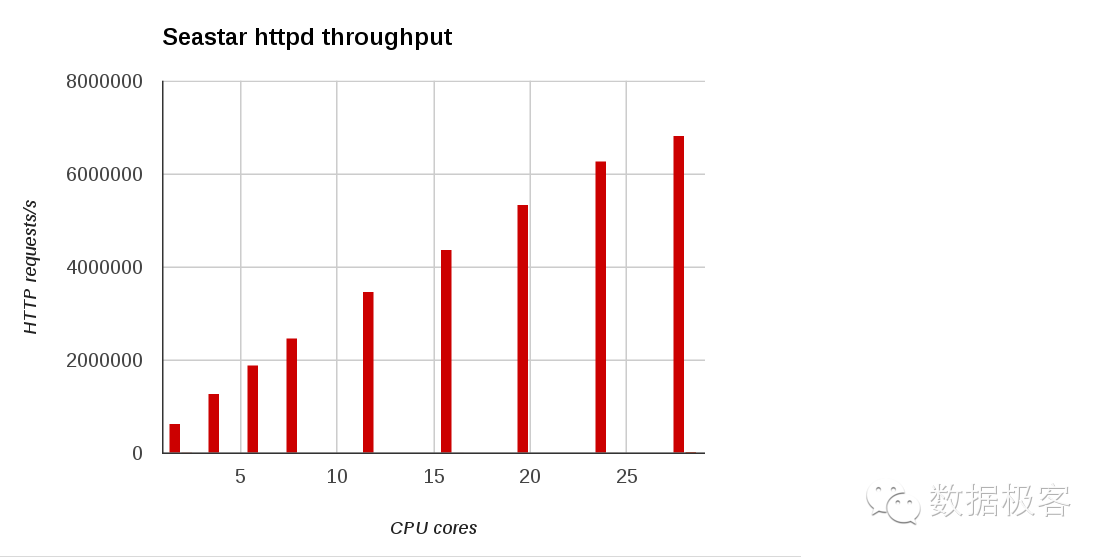
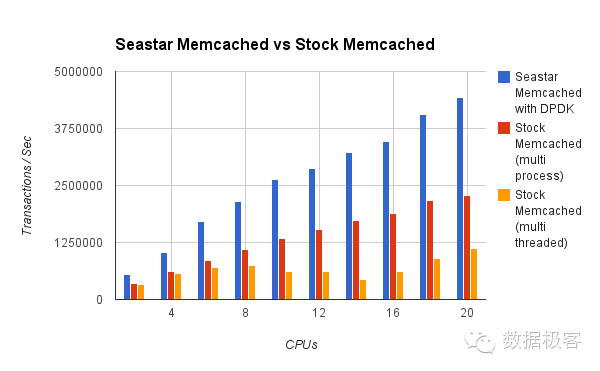
第一个是SeaStar网络框架。在数月之前,来自KVM核心的研发团队推出了一款数据库叫做ScyllaDB,声称拿C++重新实现了Cassandra数据库,单机可以达到百万TPS。坦率说,ScyllaDB如此宣传有些过于哗众取宠,任何了解基础架构底层的人都不会轻易相信该结论在任何场景都能成立。然而,ScyllaDB所真正为人称道的地方并不在于数据库核心存储引擎,而在于其SeaStar网络框架,因为这是首个在常规应用程序中引入用户态协议栈的网络框架,也让其核心Intel DPDK在常规应用开发中为世人所知,看看利用Seastar加速的http和memcached并发可以达到多少级别,并且随着cpu核数增加线性增长,就能感受用户态网络的巨大威力了。SeaStar是目前可用性最好的用户态网络编程框架,在基于DPDK实现了socket语义之后,进一步提供了线程乃至协程的语义封装,便于上层应用使用。
第二个来自OVS(OpenVSwitch),根据多家云解决方案提供商的实践经验,OVS的最佳实践方案是搭配DPDK协同使用,有测试证明采用用户态网络栈的OVS针对小数据包的转发效率比独立的OVS高十倍,这对于数据中心的网络延迟性能是个重要改进。
最后提及一下新浪和清华大学联合研究的Fastsocket,这个工作已经在很多商业网站得到运用,例如新浪等,其主要方法是将网络协议栈处理的关键数据结构做CPU核心间的隔离,使得每个核心有完全本地的访问数据,从而消除了执行路径上核心间的同步开销;并使任意某TCP连接的全部处理,都在一个核心上完成,这样可以最大化的提高CPU cache利用率,从而使应用层程序如nginx的并发连接数提升数倍。Fastsocket是很出色的工作,但并不属于用户态协议栈,仍是针对内核态协议栈的改进。
